Spark性能优化总结
1. 避免重复加载RDD
比如一份从HDFS中加载的数据 val rdd1 = sc.textFile("hdfs://url:port/test.txt"),这个test.txt只应该在你的程序中被加载一次,避免多次加载造成的性能开销。
2. 重复使用的RDD需要被缓存
Spark有数据持久化的几种策略,可以将RDD中的数据保存到内存或者磁盘中,后续对这个RDD的操作不会根据RDD lineage重新计算,而是直接从缓存中提取。
如果要对一个RDD进行持久化,只需要对这个RDD调用cache()和persist(),cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中,
但是生产环境中处理的数据量往往很难全部存储在内存中,需注意虚拟机OOM;persist()方法表示需要手动选择StorageLevel(持久化级别),并使用指定的方式
进行持久化,如序列化到磁盘等(注意,有时候数据全部序列化到磁盘比重新计算一次更慢!)
3. 警惕shuffle操作性能问题
类似MapReduce中的shuffle过程(MapReduce浅析),同一个父RDD的分区传入到不同的子RDD分区中,shuffle过程往往会造成跨节点数据传输(即官网所说的宽依赖问题):
各个节点上的相同key首先写入本地磁盘文件中,然后其他节点需要通过网络根据路由函数传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合
操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,溢写到磁盘文件中。。
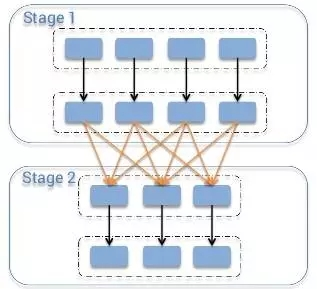
图1.Spark的shuffle过程
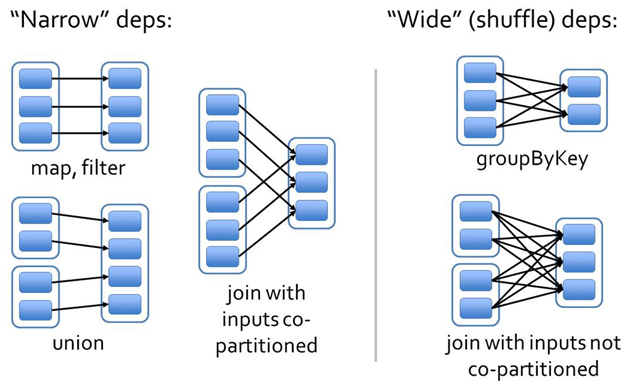
图2. 宽依赖和窄依赖
解决方式有以下两种:
1. 如果可以,先使用filter对RDD先做一定程度的 ‘缩小’
2. 在Map端预先对数据进行聚合,类似传统MapReduce中的Combiner,在Spark中使用reduceByKey或者aggregateByKey会对数据在Map端聚合,
反之,groupByKey会导致全部数据在集群中跨节点传输,性能较差。
4. 广播变量
类似于MapReduce中的DistributeCache。默认情况下Spark会将程序中依赖的变量复制多个副本,分发到各个task中,每个task都有一个副本。如果
变量本身比较大的话,那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。
而Spark中的广播变量作用是一个Executor中的所有task共享一个副本。
5. 序列化
Spark可以使用Kryo优化序列化过程。
Spark性能优化总结的更多相关文章
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
- 【转载】 Spark性能优化指南——基础篇
转自:http://tech.meituan.com/spark-tuning-basic.html?from=timeline 前言 开发调优 调优概述 原则一:避免创建重复的RDD 原则二:尽可能 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- 【转】Spark性能优化指南——基础篇
http://mp.weixin.qq.com/s?__biz=MjM5NDMwNjMzNA==&mid=2651805828&idx=1&sn=2f413828d1fdc6a ...
- Spark性能优化指南——高级篇(转载)
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能优化指南——基础篇(转载)
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark性能优化指南-高级篇
转自https://tech.meituan.com/spark-tuning-pro.html,感谢原作者的贡献 前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作 ...
- Spark性能优化指南——基础篇
本文转自:http://tech.meituan.com/spark-tuning-basic.html 感谢原作者 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一 ...
- Spark性能优化指南——高级篇
本文转载自:https://tech.meituan.com/spark-tuning-pro.html 美团技术点评团队) Spark性能优化指南——高级篇 李雪蕤 ·2016-05-12 14:4 ...
- Spark记录-Spark性能优化解决方案
Spark性能优化的10大问题及其解决方案 问题1:reduce task数目不合适解决方式:需根据实际情况调节默认配置,调整方式是修改参数spark.default.parallelism.通常,r ...
随机推荐
- kafka集群参数解析server.properties
#server.properties配置文件 broker.id=1 port=9092 host.name=url1 zookeeper.connect=url1:2181,url2:2181,ur ...
- 设计模式——中介者模式/调停者模式(C++实现)
#include <iostream> #include <string> using namespace std; class Colleague; class Mediat ...
- php类中双冒号和->的区别
就是为了区分对象的方法和属性,和是访问类的静态方法和静态变量,类的静态方法和静态变量是类公用的,不需要实例化也能访问,而对象的方法和属性是每个对象特有的,因此必须先实例化.其他语言如C++,JAVA等 ...
- Git 初体验
第一次接触git的时候,一直在纳闷git和github的区别,解释下,git是版本管理工具,github是开源共享平台,个人这么理解,理解这么多就行了 先说git吧,下载git客户端,地址:http: ...
- python全栈开发-Day5 集合
python全栈开发-Day5 集合 一.首先按照以下几个点展开对集合的学习 #一:基本使用 1 .用途 2 .定义方式 3 .常用操作+内置的方法 #二:该类型总结 1. 存一个值or存多个值 只能 ...
- 分享基于Qt5开发的一款故障波形模拟软件
背景介绍 这是一款采用Qt5编写的用于生成故障模拟波形的软件.生成的波形数据用于下发到终端机器生成对应的故障类型,用于培训相关设备维护人员的故障排查技能.因此,在这款软件中实现了故障方案管理.故障波形 ...
- reinterpret_cast,static_cast, dynamic_cast,const_cast的运用分析
reinterpret_cast(重新解释类型转换) reinterpret_cast 最famous的特性就是什么都可以,转换任意的类型,包括C++所有通用类型,所以也最不安全 应用 整形和指针之间 ...
- python自学日志--基础篇(1)
从认识python,到学习python,中间经历了挺长一段时间的心理挣扎.人总是对未知的事物有着天生的恐惧感,但是,人又是对未知充斥好奇.所以在最后,还是推开了这扇门,开始学习python. pyth ...
- Javascript面向对象编程(三):非构造函数的继承
转载自:http://www.ruanyifeng.com/blog/2010/05/object-oriented_javascript_inheritance_continued.html 一.什 ...
- java排序算法(四):冒泡排序
java排序算法(四):冒泡排序 冒泡排序是计算机的一种排序方法,它的时间复杂度是o(n^2),虽然不及堆排序.快速排序o(nlogn,底数为2).但是有两个优点 1.编程复杂度很低.很容易写出代码 ...