从大数据技术变迁猜一猜AI人工智能的发展

目前大数据已经成为了各家互联网公司的核心资产和竞争力了,其实不仅是互联网公司,包括传统企业也拥有大量的数据,也想把这些数据发挥出作用。在这种环境下,大数据技术的重要性和火爆程度相信没有人去怀疑。
而AI人工智能又是基于大数据技术基础上发展起来的,大数据技术已经很清晰了,但是AI目前还未成熟啊,所以本文就天马行空一下,从大数据的技术变迁历史中来找出一些端倪,猜一猜AI人工智能未来的发展。
最近断断续续的在看《极客时间》中「 从0开始学大数据 」专栏的文章,受益匪浅,学到了很多。尤其是非常喜欢作者李智慧讲的那句话“学习大数据最好的时间是十年前,其次就是现在”,把这句话改到AI也适用,“学习AI最好的时间是十年前,其次就是现在”,任何知识都是这样。下面我们就来详细聊一聊。
一、先聊一聊大数据技术发展史?
我们使用的各种大数据技术,最早起源于Google当年公布的三篇论文,Google FS(2003年)、MapReduce(2004年)、BigTable(2006年),其实Google当时并没有公布其源码,但是已经把这三个项目的原理和实现方式在公布的论文中详细的描述了,这几篇论文面世后,就引爆了行业的大数据学习和研究的浪潮。
随后一个叫 Doug Cutting 的技术大牛(也就是写 Lucene 的那位,做JAVA的同学应该都很熟悉)就开始根据Google公布的论文去开发相关系统,后来慢慢发展成了现在的 Hadoop,包括 MapReduce 和 HDFS。
但是在当时,使用 MapReduce 进行数据分析和应用还是有很大门槛的,毕竟要编写 Map 和 Reduce 程序。只能大数据工程师上马,普通BI分析师还是一脸懵逼。所以那个时候都是些大公司在玩。
既然有这么大门槛,就会有人勇于站出来去解决门槛,比如 Yahoo,他们开发一个叫做 Pig 的东西,Pig是一个脚本语言,按照Pig的语法写出来的脚本可以编译成 MapReduce 程序,然后直接在 Hadoop 上运行了。
这个时候,大数据开发的门槛确实降了一点。
不过,Pig大法虽好,但还是需要编写脚本啊,这还是码农的活儿啊。人们就在想,有没有不用写代码的方法就能做大数据计算呢,还真有,这个世界的进步就是由一群善于思考的“懒人”推动的。
于是,Facebook公司的一群高智商家伙发布了一个叫做 Hive 的东西,这个 Hive 可以支持使用 SQL 语法直接进行大数据计算。原理其实就是,你只需要写一个查询的 SQL,然后 Hive 会自动解析 SQL 的语法,将这个SQL 语句转化成 MapReduce 程序去执行。
这下子就简单了,SQL 是BI/数据分析师们最为常用的工具了,从此他们可以无视码农,开开心心的独立去写Hive,去做大数据分析工作了。Hive从此就火爆了,一般公司的大多数大数据作业都是由Hive完成的,只有极少数较为复杂的需求才需要数据开发工程师去编写代码,这个时候,大数据的门槛才真真的降低了,大数据应用也才真正普及,大大小小的公司都开始在自己的业务上使用了。
但是,人们的追求不止如此,虽然数据分析便利了,但是大家又发现 MapReduce 程序执行效率不够高啊,其中有多种原因,但有一条很关键,就是 MapReduce 主要是以磁盘作为存储介质,磁盘的性能极大的限制了计算的效率。
在这个时候,Spark 出现了,Spark 在运行机制上、存储机制上都要优于 MapReduce ,因此大数据计算的性能上也远远超过了 MapReduce 程序,很多企业又开始慢慢采用 Spark 来替代 MapReduce 做数据计算。
至此,MapReduce 和 Spark 都已成型,这类计算框架一般都是按“天”为单位进行数据计算的,因此我们称它们为“大数据离线计算”。既然有“离线计算”,那就必然也会有非离线计算了,也就是现在称为的“大数据实时计算”。
因为在数据实际的应用场景中,以“天”为颗粒出结果还是太慢了,只适合非常大量的数据和全局的分析,但还有很多业务数据,数据量不一定非常庞大,但它却需要实时的去分析和监控,这个时候就需要“大数据实时计算”框架发挥作用了,这类的代表有:Storm、Spark Streaming、Flink 为主流,也被称为 流式计算,因为它的数据源像水流一样一点点的流入追加的。
当然,除了上面介绍的那些技术,大数据还需要一些相关底层和周边技术来一起支撑的,比如 HDFS 就是分布式文件系统,用于负责存储数据的,HBase 是基于HDFS的NoSQL系统、与 HBase类似的还有 Cassandra也都很热门。
二、再看一看大数据技术架构?
了解大数据相关技术可以先看
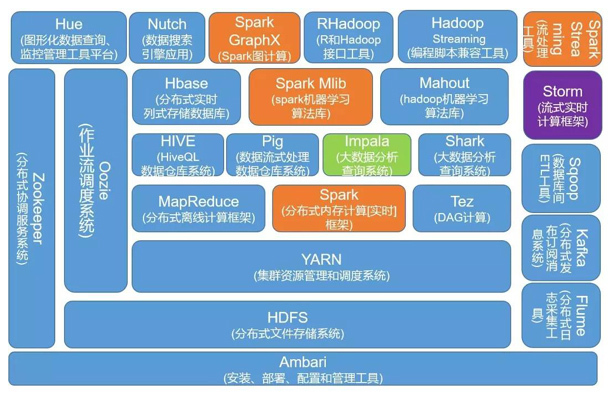 (图片来源网络)
(图片来源网络)
这图基本上很全面的展示了大数据的技术栈,下面将其主要的部分罗列一下,以便有个清晰的认知:
大数据平台基础:
MapReduce,分布式离线计算框架
Spark,分布式离线计算框架
Storm,流式实时计算框架
Spark Streaming,流式实时计算框架
Flink,流式实时计算框架
Yarn,分布式集群资源调度框架
Oozie,大数据调度系统
分布式文件系统:
HDFS,分布式文件系统
GFS,分布式文件系统
SQL引擎:
Spark SQL (Shark),将SQL语句解析成Spark的执行计划在Spark上执行
Pig,Yahoo的发布的脚本语言,编译后会生成MapReduce程序
Hive,是Hadoop大数据仓库工具,支持SQL语法来进行大数据计算,把SQL转化MapReduce程序
Impala,Cloudera发布的运行在HDFS上的SQL引擎
数据导入导出:
Sqoop,专门用将关系数据库中的数据 批量 导入导出到Hadoop
Canal,可以 实时 将关系数据库的数据导入到Hadoop
日志收集:
Flume,大规模日志分布式收集
大数据挖掘与机器学习:
Mahout,Hadoop机器学习算法库
Spark MLlib,Spark机器学习算法库
TensorFlow,开源的机器学习系统
三、猜一猜AI人工智能的发展?
通过上面的回顾,我们知道了,因为大量数据的产生导致大数据计算技术 MapReduce 的出现,又因为 MapReduce 的参与门槛问题,导致了 Pig、Hive的出现,正是因为这类上手容易的工具的出现,才导致大量的非专业化人员也能参与到大数据这个体系,因此导致了大数据相关技术的飞速发展和应用,又从而进一步推动了机器学习技术的出现,有了现在的AI人工智能的发展。
但目前人工智能技术的门槛还比较高,并不是任何企业都能入场的,需要非常专业化的高端技术人才去参与,普通人员只能望而却步,因此AI技术的应用受到了极大的限制,所以也不断的有人提出对人工智能提出质疑。
讲到这里,有没有发现点什么问题?
历史的规律总是那么相似。可以猜测一下,人工智能的门槛有一天也会像 MapReduce 的开发门槛一样被打破,一旦人工智能的参与门槛降低了,各类大小企业都能结合自己的业务场景进入AI领域发挥优势了,那AI就真的进入高速发展的通道了,AI相关实际应用的普及就指日可待了。
恩,一定是这样的,哈哈,现在就可以等着大牛们将AI的基础平台建设好,然后降低参与门槛,进一步就迎来了AI的一片光明,大家从此就可以过上AI服务人类的美好生活了(畅想中…)。
以上,就是从大数据技术变迁想到AI人工智能发展的一些想法,欢迎大家留言交流,多多点击文章右下角的“好看”。
本文原创发布于微信公众号「 不止思考 」,欢迎关注,交流 互联网认知、工作管理、大数据、架构、Web等技术。

从大数据技术变迁猜一猜AI人工智能的发展的更多相关文章
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- 参加2013中国大数据技术大会(BDTC2013)
2013年12月5日-6日参加了为期两天的2013中国大数据技术大会(Big Data Technology Conference, BDTC2013),本期会议主题是:“应用驱动的架构与技术 ”.大 ...
- 大数据技术人年度盛事! BDTC 2016将于12月8-10日在京举行
2016年12月8日-10日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所和CSDN共同协办的2016中国大数据技术大会(Big Data Technology ...
- 大数据技术 vs 数据库一体机[转]
http://blog.sina.com.cn/s/blog_7ca5799101013dtb.html 目前,虽然大数据与数据库一体机都很火热,但相当一部分人却无法对深入了解这两者的本质区别.这里便 ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- 2016中国大数据技术大会( BDTC ) 共商大数据时代发展之计
中国大数据技术大会(BDTC)的前身是Hadoop中国云计算大会(HadoopinChina,HiC).从2008年仅60余人参加的技术沙龙发展到当下数千人的技术盛宴,目前已成为国内最具影响力.规模最 ...
- WOT2016大数据技术峰会——千人技术盛宴
WOT2016大数据技术峰会是一场聚焦大数据领域最前沿的的技术及经验分享.2016年11月25-26日北京粤财JW万豪酒店如约而至,会议规模达到1000人! 由51CTO主办的千人技术盛宴--WOT2 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
随机推荐
- System.out.println()
System是java.lang中的类,out为System中的一个静态数据成员,out是java.io.PrintStream类的对象,而println()是java.io.PrintStream类 ...
- index_levedb.go
) binary.BigEndian.PutUint64(key, fid) return l.db.Delete(key, nil) } //关闭资源 func (l *LevelD ...
- SSH(Spring_SpringMVC_Hibernate)
Users实体类 package com.tao.pojo; public class Users { private int id; private String name; private Str ...
- .net core在网关中统一配置Swagger
最近在做微服务的时候,由于我们是采用前后端分离来开发的,提供给前端的直接是Swagger,如果Swagger分布在各个API中,前端查看Swagger的时候非常不便,因此,我们试着将Swagger集中 ...
- SSIS 调试和故障排除
SSIS内置的调试工具是非常完备的,主要是设置断点和查看变量值,这是在Package的设计阶段可以使用的工具,在Package部署到服务器之后,用户还可以使用事件处理程序以实现Package出错的自我 ...
- .NETCore+EF+MySql+Autofac简单三层架构
前言 其实就是一个简单依赖注入的三层架构.记录一下,大佬们就不用看下去了.重点在最后面,可以直接拖到底去看. 正文 1.贴代码 1.整体的一个结构.大佬们应该一眼就看明白了. 2.MySqlConte ...
- Azure Devops/Tfs 编译的时候自动修改版本号
看到阿迪王那边出品了一个基于Azure Devops自增版本号 链接 http://edi.wang/post/2019/3/1/incremental-build-number-for-net-c ...
- 利用策略模式优化过多 if else 代码
前言 不出意外,这应该是年前最后一次分享,本次来一点实际开发中会用到的小技巧. 比如平时大家是否都会写类似这样的代码: if(a){ //dosomething }else if(b){ //dosh ...
- 『神坑』DotNetty 内存泄漏 解决办法
背景 近来在用 DotNetty 实现一个文件上传下载的同步服务. 其中:客户端下载服务端的文件,客户端多次请求,从服务端将文件分片下载下来,追加到本地磁盘. —— 非常简单的代码,都写了几十次了,驾 ...
- MySQL数据库Inception工具学习与测试 笔记
MySQL语句的审核,在业界都已经基本被认同了,实际上也是对MySQL语句写法的统一化,标准化,而之前的人工审核,针对标准这个问题其实是很吃力的,标准越多,DBA越累,开发也越累. 那么在这个都追求自 ...