java基础(十)-----Java 序列化的高级认识
将 Java 对象序列化为二进制文件的 Java 序列化技术是 Java 系列技术中一个较为重要的技术点,在大部分情况下,开发人员只需要了解被序列化的类需要实现 Serializable 接口,使用 ObjectInputStream 和 ObjectOutputStream 进行对象的读写。然而在有些情况下,光知道这些还远远不够,文章列举了笔者遇到的一些真实情境,它们与 Java 序列化相关,通过分析情境出现的原因,使读者轻松牢记 Java 序列化中的一些高级认识。
序列化 ID 问题
情境:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C。
问题:C 对象的全类路径假设为 com.inout.Test,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。
解决:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
清单 1. 相同功能代码不同序列化 ID 的类对比
package com.inout;
import java.io.Serializable;
public class A implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
} package com.inout;
import java.io.Serializable;
public class A implements Serializable {
private static final long serialVersionUID = 2L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
序列化 ID 在 Eclipse 下提供了两种生成策略,一个是固定的 1L,一个是随机生成一个不重复的 long 类型数据(实际上是使用 JDK 工具生成),在这里有一个建议,如果没有特殊需求,就是用默认的 1L 就可以,这样可以确保代码一致时反序列化成功。那么随机生成的序列化 ID 有什么作用呢,有些时候,通过改变序列化 ID 可以用来限制某些用户的使用。
静态变量序列化
清单 2. 静态变量序列化问题代码
public class Test implements Serializable {
private static final long serialVersionUID = 1L;
public static int staticVar = ;
public static void main(String[] args) {
try {
//初始时staticVar为5
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
out.writeObject(new Test());
out.close();
//序列化后修改为10
Test.staticVar = ;
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t = (Test) oin.readObject();
oin.close();
//再读取,通过t.staticVar打印新的值
System.out.println(t.staticVar);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
清单 2 中的 main 方法,将对象序列化后,修改静态变量的数值,再将序列化对象读取出来,然后通过读取出来的对象获得静态变量的数值并打印出来。依照清单 2,这个 System.out.println(t.staticVar) 语句输出的是 10 还是 5 呢?
最后的输出是 10,对于无法理解的读者认为,打印的 staticVar 是从读取的对象里获得的,应该是保存时的状态才对。之所以打印 10 的原因在于序列化时,并不保存静态变量,这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量。
对敏感字段加密
情境:服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
解决:在序列化过程中,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作,清单 3 展示了这个过程。
清单 3. 静态变量序列化问题代码
private static final long serialVersionUID = 1L;
private String password = "pass";
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
private void writeObject(ObjectOutputStream out) {
try {
PutField putFields = out.putFields();
System.out.println("原密码:" + password);
password = "encryption";//模拟加密
putFields.put("password", password);
System.out.println("加密后的密码" + password);
out.writeFields();
} catch (IOException e) {
e.printStackTrace();
}
}
private void readObject(ObjectInputStream in) {
try {
GetField readFields = in.readFields();
Object object = readFields.get("password", "");
System.out.println("要解密的字符串:" + object.toString());
password = "pass";//模拟解密,需要获得本地的密钥
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
out.writeObject(new Test());
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t = (Test) oin.readObject();
System.out.println("解密后的字符串:" + t.getPassword());
oin.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
在清单 3 的 writeObject 方法中,对密码进行了加密,在 readObject 中则对 password 进行解密,只有拥有密钥的客户端,才可以正确的解析出密码,确保了数据的安全。执行控制台输出如图所示。
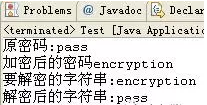
特性使用案例
RMI 技术是完全基于 Java 序列化技术的,服务器端接口调用所需要的参数对象来至于客户端,它们通过网络相互传输。这就涉及 RMI 的安全传输的问题。一些敏感的字段,如用户名密码(用户登录时需要对密码进行传输),我们希望对其进行加密,这时,就可以采用本节介绍的方法在客户端对密码进行加密,服务器端进行解密,确保数据传输的安全性。
序列化存储规则
清单 4. 存储规则问题代码
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
Test test = new Test();
//试图将对象两次写入文件
out.writeObject(test);
out.flush();
System.out.println(new File("result.obj").length());
out.writeObject(test);
out.close();
System.out.println(new File("result.obj").length());
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
//从文件依次读出两个文件
Test t1 = (Test) oin.readObject();
Test t2 = (Test) oin.readObject();
oin.close();
//判断两个引用是否指向同一个对象
System.out.println(t1 == t2);
清单 3 中对同一对象两次写入文件,打印出写入一次对象后的存储大小和写入两次后的存储大小,然后从文件中反序列化出两个对象,比较这两个对象是否为同一对象。一般的思维是,两次写入对象,文件大小会变为两倍的大小,反序列化时,由于从文件读取,生成了两个对象,判断相等时应该是输入 false 才对,但是最后结果输出如图所示。
true
我们看到,第二次写入对象时文件只增加了 5 字节,并且两个对象是相等的,这是为什么呢?
解答:Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的 5 字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,使得清单 3 中的 t1 和 t2 指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
特性案例分析
清单 5. 案例代码
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj"));
Test test = new Test();
test.i = ;
out.writeObject(test);
out.flush();
test.i = ;
out.writeObject(test);
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t1 = (Test) oin.readObject();
Test t2 = (Test) oin.readObject();
System.out.println(t1.i);
System.out.println(t2.i);
本案例的目的是希望将 test 对象两次保存到 result.obj 文件中,写入一次以后修改对象属性值再次保存第二次,然后从 result.obj 中再依次读出两个对象,输出这两个对象的 i 属性值。案例代码的目的原本是希望一次性传输对象修改前后的状态。
结果两个输出的都是 1, 原因就是第一次写入对象以后,第二次再试图写的时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。读者在使用一个文件多次 writeObject 需要特别注意这个问题。
小结
本文通过几个具体的情景,介绍了 Java 序列化的一些高级知识,虽说高级,并不是说读者们都不了解,希望用笔者介绍的情景让读者加深印象,能够更加合理的利用 Java 序列化技术,在未来开发之路上遇到序列化问题时,可以及时的解决。由于本人知识水平有限,文章中倘若有错误的地方,欢迎联系我批评指正。
java基础(十)-----Java 序列化的高级认识的更多相关文章
- Java基础十二--多态是成员的特点
Java基础十二--多态是成员的特点 一.特点 1,成员变量. 编译和运行都参考等号的左边. 覆盖只发生在函数上,和变量没关系. Fu f = new Zi();System.out.println( ...
- Java基础十--接口
Java基础十--接口 一.接口的定义和实例 /* abstract class AbsDemo { abstract void show1(); abstract void show2(); } 8 ...
- 黑马程序员:Java基础总结----java注解
黑马程序员:Java基础总结 java注解 ASP.Net+Android+IO开发 . .Net培训 .期待与您交流! java注解 lang包中的基本注解 @SuppressWarnings ...
- Java基础:Java的四种引用
在Java基础:java虚拟机(JVM)中,我们提到了Java的四种引用.包括:强引用,软引用,弱引用,虚引用.这篇博客将详细的讲解一下这四种引用. 1. 强引用 2. 软引用 3. 弱引用 4. 虚 ...
- java基础-学java util类库总结
JAVA基础 Util包介绍 学Java基础的工具类库java.util包.在这个包中,Java提供了一些实用的方法和数据结构.本章介绍Java的实用工具类库java.util包.在这个包中,Java ...
- java基础(二)-----java的三大特性之继承
在<Think in java>中有这样一句话:复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对加以改变是不够的,它还必须能够做更多的事情.在这句 ...
- Java基础-使用JAVA代码剖析MD5算法实现过程
Java基础-使用JAVA代码剖析MD5算法实现过程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Java基础技术-Java其他主题【面试】
Java基础技术-Java其他主题[面试] Java基础技术IO与队列 Java BIO.NIO.AIO Java 中 BIO.NIO.AIO 的区别是什么? 含义不同: BIO(Blocking I ...
- java基础八 [序列化和文件的输入/输出](阅读Head First Java记录)
对象具有状态和行为两种属性.行为存在类中的方法中,想要保存状态有多种方法,这里介绍两种: 一是保存整个当前对象本身(通过序列化):一是将对象中各个状态值保存到文件中(这种方式可以给其他非JAVA程序用 ...
随机推荐
- [NOIP2002]字串变换 T2 双向BFS
题目描述 已知有两个字串 A,B 及一组字串变换的规则(至多6个规则): A1−>B1 A2−>B2 规则的含义为:在 A$中的子串 A1可以变换为可以变换为B1.A2可以变换为可 ...
- XSS SQL CSRF
XSS(Cross Site Script,跨站脚本攻击)是向网页中注入恶意脚本在用户浏览网页时在用户浏览器中执行恶意脚本的攻击方式.跨站脚本攻击分有两种形式:反射型攻击(诱使用户点击一个嵌入恶意脚本 ...
- CTF中常见的加解密(经典)
今天一早起来,就要去做早操,心里苦呀! 但是不影响我为未来的学弟学妹整理资料的心情呀!希望我的一些拙见能够帮助到学弟学妹! 永远爱你们的 ---- 新宝宝 ASCII编码 ASCII 码使用指定的7 ...
- TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客<TensorFlow之DNN(一):构建“裸机版”全连接神经网络>中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦) ...
- [Inside HotSpot] C1编译器HIR的构造
1. 简介 这篇文章可以说是Christian Wimmer硕士论文Linear Scan Register Allocation for the Java HotSpot™ Client Compi ...
- 浅析vue2.0的diff算法
一.前言 如果不了解virtual dom,要理解diff的过程是比较困难的. 虚拟dom对应的是真实dom, 使用document.CreateElement 和 document.CreateTe ...
- 『性能』测试一下 MSSqlHelper 的性能
本文没啥技术含量,就是测试一下 MSSqlHelper 在 使用反射.不使用反射 的性能对比. 之后,不要问为什么不用 ORM 这类的东西 —— 会有另外的文章 介绍 自己这些年 自己的ORM 升级历 ...
- 阿里云重磅发布DMS数据库实验室 免费体验数据库引擎
2月27日,阿里云数据管理DMS发布年度巨献——数据库实验室,用户可在该实验室环境下免费体验数据库引擎.以及DMS各项产品功能.数据库实验室是DMS所提供的体验空间,免费赠送数据库引擎资源. 用户只需 ...
- PowerDesigner制作UMI图
首先我们要下载一个PowerDesigner,自己上百度下载哈!嘻嘻!!! 我这个是汉化版的 然后点这个,再到空白的地方点一下就创建好了. 然后单击右边箭头然后双击 不管是制作的图还是代码生成的图都可 ...
- java.lang.ClassNotFoundException: org.I0Itec.zkclient.IZkStateListener异常解决
在启动Dubbo项目时,出现该异常 java.lang.ClassNotFoundException: org.I0Itec.zkclient.IZkStateListener 解决,引入 <d ...