104 - kube-scheduler源码分析 - predicate整体流程
(注:从微信公众:CloudGeek复制过来,格式略微错乱,更好阅读体验请移步公众号,二维码在文末)

今天我们来跟一下predicates的整个过程;predicate这个词应该是“断言、断定”的意思,在这里我们姑且翻译为“预选”,虽然不符合这个单词的本意,但是在schedule过程中predicate过程做的事情确实还是叫“预选”比较好理解!
上一讲我们提到predicate过程的入口在findNodesThatFit这个函数,所以今天我们从这个函数入手,看看这里面有哪些玄机。这个函数在:pkg/scheduler/core/generic_scheduler.go:289,声明如下:
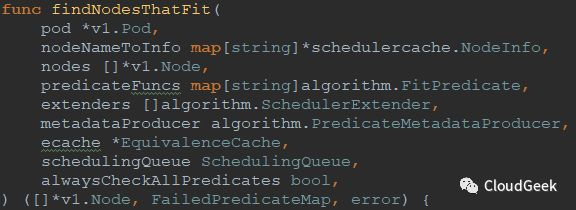
可以看到有不少参数,我们理一下这些参数都是什么:
- pod *v1.Pod,
//表示一个pod - nodeNameToInfo map[string]*schedulercache.NodeInfo,
//NodeInfo是node级别的信息集合,里面包含v1.Node,pods,usedPorts等node上的信息;nodeNameToInfo也就是一个node的name到NodeInfo的映射 - nodes []*v1.Node,
//node列表,可用的node集合 - predicateFuncs map[string]algorithm.FitPredicate,
//predicate函数的别名到具体函数的映射,这里的string类似:PodFitsHostPorts;后面的FitPredicate类型是一个func类型:type FitPredicate func(pod *v1.Pod, meta PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []PredicateFailureReason, error);这个函数类型判断一个pod能否跑在一个node上 - extenders []algorithm.SchedulerExtender,
//SchedulerExtender是一个接口类型,表示的是一个外部的处理过程,主要用于某些资源不是直接由k8s管理的场景下,调度决策需要外部介入时调用 - metadataProducer algorithm.PredicateMetadataProducer,
//PredicateMetadataProducer是一个函数类型,入参是pod和nodeNameToInfo,返回值是PredicateMetadata,PredicateMetadata是一个interface类型,这个类型表示predicate metadata支持的所有access操作,包含3个函数:ShallowCopy()/AddPod()/RemovePod();这个interface的实现是struct:predicateMetadata,这个struct包含pod、podPorts、serviceAffinityInUse等属性 - ecache *EquivalenceCache,
//结构体EquivalenceCache主要包含1:一个以node name为key,AlgorithmCache为value的map;2:一个获取equivalence pod的函数。AlgorithmCache这个结构体存储了一个lru.Cache类型的属性,lru是最近最少使用的意思,groupcache里实现的这个Cache - schedulingQueue SchedulingQueue,
//这个interface保存一个等待被调度的pods队列,有Add()、Pop()等函数 - alwaysCheckAllPredicates bool,
//是否检查所有的predicate
咋看你肯定感觉迷糊,略抓狂,这么多东西咋个理解呢,,,别急,咱再看一下一个关键类型,然后静下心来往后看完,再回过头看是不是理解了这里的所有参数:
1、上面的FitPredicate类型源码里解释如下:
// FitPredicate is a function that indicates(标示) if a pod fits into an existing node. The failure information is given by the error.入参有3个,分别是:
- pod *v1.Pod
- meta PredicateMetadata
- nodeInfo *schedulercache.NodeInfo
返回值是:
- bool
- []PredicateFailureReason
- error
也就是说给定一个pod和一个node,这个函数需要判断这个pod能否跑在这个node上,能否体现在返回值bool类型上;然后如果失败了,也就是不能的情况,需要返回PredicateFailureReason集合,也就是失败的原因们。这个PredicateFailureReason是个interface,看一眼定义就很清晰了,特别简单:

ok,我们接着看findNodesThatFit函数的返回值:
1.[]*v1.Node,
2.FailedPredicateMap,
//这个返回值是map[string][]algorithm.PredicateFailureReason类型,这个类型就是上面截图中那个
3.error
到这里我们可以初步判断findNodesThatFit函数的输入是一个pod和一堆nodes和xxx,返回值是可以跑这个pod的node集合和xxx,xxx先不考虑,我们专注一下这里的一个pod和N个node,返回值是M个node,M<=N.
这个函数的逻辑并不复杂,我们撇开里面主要的子函数podFitsOnNode后过程大致如下图:
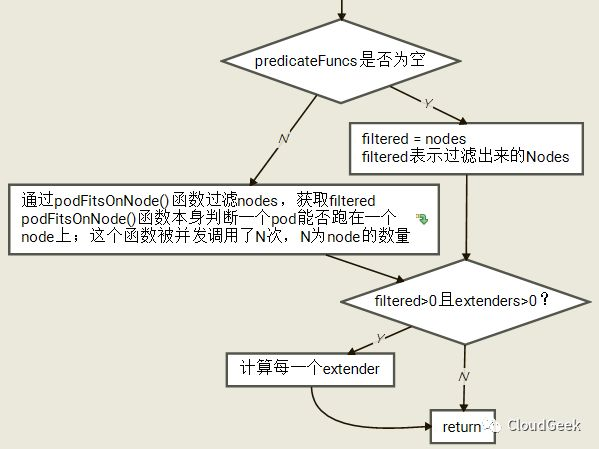
这里我们稍微看一下这里的checkNode函数是怎么被并发调用的:
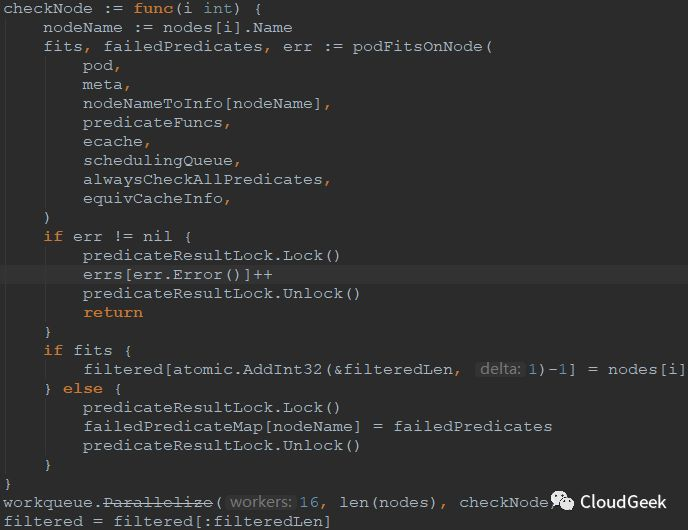
如上图,checkNode是一个函数类型,明显predicateFuncs都在这个内嵌函数中执行了。这个内嵌函数的调用在截图的倒数第二行:workqueue.Parallelize(16, len(nodes), checkNode);这个函数的入参是16,nodes的数量,checkNode这个函数,跟进去看一下可以知道这里的逻辑,不复杂不过挺有意思:
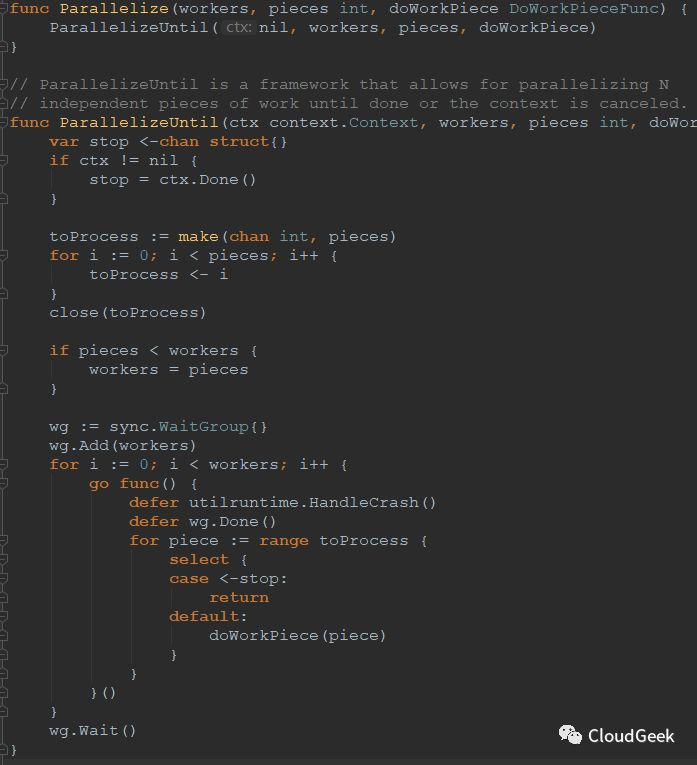
上面的workers是16,pieces是node数量,doWorkPiece就是checkNode这个函数,这个函数的参数还记得吗?是一个int类型的i;ParallelizeUntil这个函数中写入了pieces个数据到toProcess,也就是node的数量,然后就close掉了这个channal,也就是这个channal被读完就废了。然后判断如果node数量少于workers,也就是少于16的话,则workers=16;最后开了workers个goroutines, 也就是最多16个并发来消费toProcess,也就是最多16个并发来计算N个checkNode任务,每个checkNode任务处理一个node上的predicate functions计算过程。
好,下面看podFitsOnNode了,先略看函数声明:
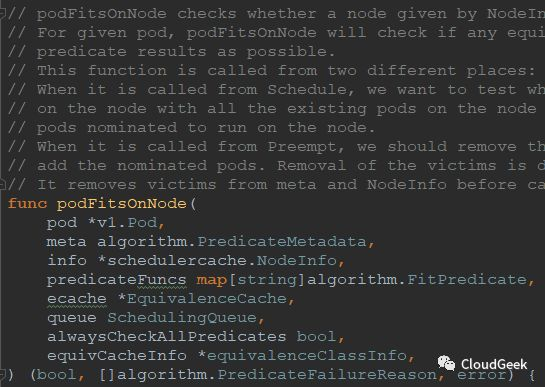
可以看到这里的注释不少,大致翻译过来是这个意思:podFitsOnNode检查一个以NodeInfo形式提供的node是否能够通过给定的predicate functions筛选;对于一个给定的pod,podFitsOnNode会检查node上是否有已经存在的等价的pod,如果存在则尝试尽量重用这个pod缓存的predicate结果信息。这个函数会从2个不同的入口被调用:Schedule and Preempt,当从Schedule进入时,本函数检测一个node在考虑所有已存在pods和被指定将跑到这个node上是所有更高优先级或者相同优先级(和当前要被调度的pod比较)的pod都跑起来的情况下能否跑现在这个被调度的pod.;;;就解释到这里,下面我们还是老规矩,看看入参和返回值:
入参:
- pod *v1.Pod,
- meta algorithm.PredicateMetadata,
- info *schedulercache.NodeInfo,
//上一个函数的nodeNameToInfo[nodeName]获取到的NodeInfo
- predicateFuncs map[string]algorithm.FitPredicate,
- ecache *EquivalenceCache,
- queue SchedulingQueue,
- alwaysCheckAllPredicates bool,
- equivCacheInfo *equivalenceClassInfo,
返回值:
- bool,
- []algorithm.PredicateFailureReason,
//上层函数返回值中的FailedPredicateMap是map[string][]algorithm.PredicateFailureReason类型
- error
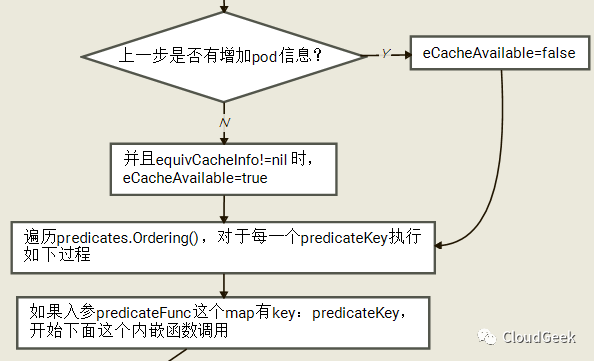
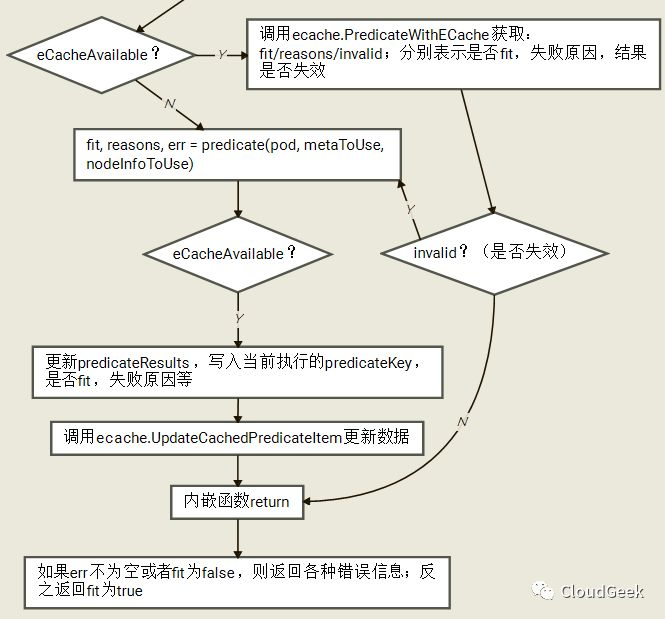
这里没有逐个解释,基本和上层函数的参数对应得上,findNodesThatFit解释哪些nodes能够跑给定的pod,而podFitsOnNode解释给定node能否跑给定pod.我们先看一下这个过程的简要流程图(2次循环考虑第一次的情况):

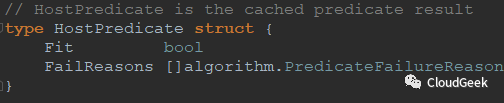
看一下代码:predicateResults := make(map[string]HostPredicate)这一行的string标识predicate名称,HostPredicate类型是:
这个i从0到1只跑2遍的for循环中分歧点只有如下这个if:
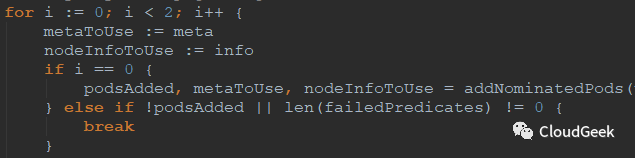
如上,在i为0时调用到了addNominatedPods函数,这个函数把更高或者相同优先级的pod(待运行到本node上的)信息增加到meta和nodeInfo中,也就是对应考虑这些nominated都Running的场景;后面i为1对应的就是不考虑这些pod的场景。对于这个2遍过程,注释里是这样解释的:
如果这个node上“指定”了更高或者相等优先级的pods(也就是优先级不低于本pod的一群pods将要跑在这个node上),我们运行predicates过程当这些pods信息全被加到meta和nodeInfo中的情况。如果所有的predicates过程成功了,我们再次运行这些predicates过程在这些pods信息没有被加到meta和nodeInfo的情况。这样第二次过程可能会因为一些pod间的亲和性策略过不了(因为这些计划要跑的pods没有跑,所以可能亲和性被破坏)。这里其实基于2点考虑:1、有亲和性要求的pod如果认为这些nominated pods在,则在这些nominated pods不在的情况下会异常;2、有反亲和性要求的pod如果认为这些nominated pods不在,则在这些nominated pods在的情况下会异常。
我们接着看predicate函数主要是怎样被调用的:
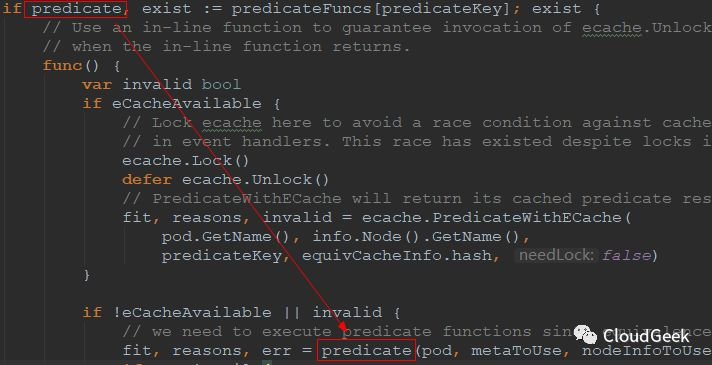
如上,predicate是FitPredicate类型的一个对象,也就是对应具体的predicate函数,所以下面的predicate(pod, metaToUse, nodeInfoToUse)也就对应一个具体的predicate函数的执行。
最后我们瞄一眼具体的predicate函数是怎么定义的:
一个predicate函数类似这样:
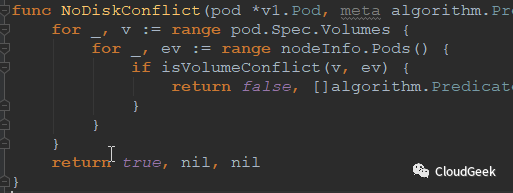
这样被注册:

紫色部分的常量对应一个个字符串描述:
行,剩下的我们下回分解~
104 - kube-scheduler源码分析 - predicate整体流程的更多相关文章
- Duilib源码分析(六)整体流程
在<Duilib源码分析(一)整体框架>.<Duilib源码分析(二)控件构造器—CDialogBuilder>以及<Duilib源码分析(三)XML解析器—CMarku ...
- [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构
[阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 目录 [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x0 ...
- scheduler源码分析——preempt抢占
前言 之前探讨scheduler的调度流程时,提及过preempt抢占机制,它发生在预选调度失败的时候,当时由于篇幅限制就没有展开细说. 回顾一下抢占流程的主要逻辑在DefaultPreemption ...
- nodejs的Express框架源码分析、工作流程分析
nodejs的Express框架源码分析.工作流程分析 1.Express的编写流程 2.Express关键api的使用及其作用分析 app.use(middleware); connect pack ...
- openVswitch(OVS)源码分析之工作流程(哈希桶结构体的解释)
这篇blog是专门解决前篇openVswitch(OVS)源码分析之工作流程(哈希桶结构体的疑惑)中提到的哈希桶结构flex_array结构体成员变量含义的问题. 引用下前篇blog中分析讨论得到的f ...
- Okhttp源码分析--基本使用流程分析
Okhttp源码分析--基本使用流程分析 一. 使用 同步请求 OkHttpClient okHttpClient=new OkHttpClient(); Request request=new Re ...
- Duilib源码分析(一)整体框架
Duilib界面库是一款由杭州月牙儿网络技术有限公司开发的界面开源库,以viksoe项目下的UiLib库的基础上开发(此后也将对UiLib库进行源码分析):通过XML布局界面,将用户界面和处理逻辑彻底 ...
- scheduler源码分析——调度流程
前言 当api-server处理完一个pod的创建请求后,此时可以通过kubectl把pod get出来,但是pod的状态是Pending.在这个Pod能运行在节点上之前,它还需要经过schedule ...
- springmvc源码分析系列-请求处理流程
接上一篇-springmvc源码分析开头片 上一节主要说了一下springmvc与struts2的作为MVC中的C(controller)控制层的一些区别及两者在作为控制层方面的一些优缺点.今天就结合 ...
随机推荐
- 【Unity游戏开发】AssetBundle杂记--AssetBundle的二三事
一.简介 马三在公司大部分时间做的都是游戏业务逻辑和编辑器工具等相关工作,因此对Unity AssetBundle这块的知识点并不是很熟悉,自己也是有打算想了解并熟悉一下AssetBundle,掌握一 ...
- 【爆料】-《布莱顿大学毕业证书》Brighton一模一样原件
布莱顿大学毕业证[微/Q:2544033233◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归&am ...
- java线程同步小结
1.线程同步的目的是为了防止多个线程同时访问一个资源时对资源的破坏 2.线程同步方法是通过锁来实现,每个对象都有切仅有一个锁,这个锁与一个特定的对象关联,线程一旦获取了对象锁,其他访问该对象的线程就无 ...
- HTML——元素
HTML 元素 HTML 文档由 HTML 元素定义. HTML 元素 开始标签 * 元素内容 结束标签 * <p> 这是一个段落 </p> <a href=" ...
- 查询APP Store已发布过的版本记录
1.国内APP使用 酷传 搜索,即可查询到版本记录 2.国外的APP 无法通过国内软件进行搜索,可在App store中直接查询.步骤如下:
- SpringBoot(三)_controller的使用
针对controller 中 如何使用注解进行解析 @RestController 返回数据类型为 Json 字符串,特别适合我们给其他系统提供接口时使用. @RequestMapping (1) 不 ...
- 用Python学分析 - 二项分布
二项分布(Binomial Distribution)对Bernoulli试验序列的n次序列,结局A出现的次数x的概率分布服从二项分布- 两分类变量并非一定会服从二项分布- 模拟伯努利试验中n次独立的 ...
- Linux安装任意版本的dotnet环境
下载地址 https://www.microsoft.com/net/download/dotnet-core/2.1 安装符合服务器CPU架构的二进制包. 如果架构不对,会出现一下错误: -bash ...
- Python练习:哥德巴赫猜想
哥德巴赫猜想 哥德巴赫 1742 年给欧拉的信中哥德巴赫提出了以下猜想:任一大于 2 的偶数都可写成两个质数之和.但是哥德巴赫自己无法证明它,于是就写信请教赫赫有名的大数学家欧拉帮忙证明,但是一直到死 ...
- 系统的讲解 - PHP 接口签名验证
目录 概览 常用验证 单向散列加密 对称加密 非对称加密 密钥安全管理 接口调试工具 在线接口文档 扩展 小结 概览 工作中,我们时刻都会和接口打交道,有的是调取他人的接口,有的是为他人提供接口,在这 ...