论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
论文题目是STC,即Simple to Complex的一个框架,使用弱标签(image label)来解决密集估计(语义分割)问题。
2014年末以来,半监督的语义分割层出不穷,究其原因还是因为pixel级别的GroundTruth太难标注,因此弱监督成了人们研究的一个热门方向。
作者的核心思想是提出了层层递进的三个DCNN。
具体来讲,作者一共训练了三个网络:Initial DCNN、Enhanced DCNN和Powerful DCNN。分别解释如下:
1 、
Initial DCNN:
其实可以把它当作是一个有显著性检测功能的CNN,但“它”能够知道显著性的物体是什么。
具体实现是由DRFI方法生成Saliency Map,再结合Image level label,来训练网络。
2、
Enhanced DCNN:
这一层主要是用来refine每一个物体的分割模版。由于I-DCNN在训练过程中,使用DRFI会有很大噪声,因此这时候就需要我们的“弱标签”出场了。说白了,这个DCNN就是对上一个DCNN的refine。
3、
Powerful DCNN:
有了上述简单图像的分割之后,我们需要对复杂的多目标的图像进行分割了,这时候,以E-DCNN生成的结果作为P-DCNN的GroundTruth来训练P-DCNN。
这样,我们就得到了最终的网络:P-DCNN。附流程图如下:
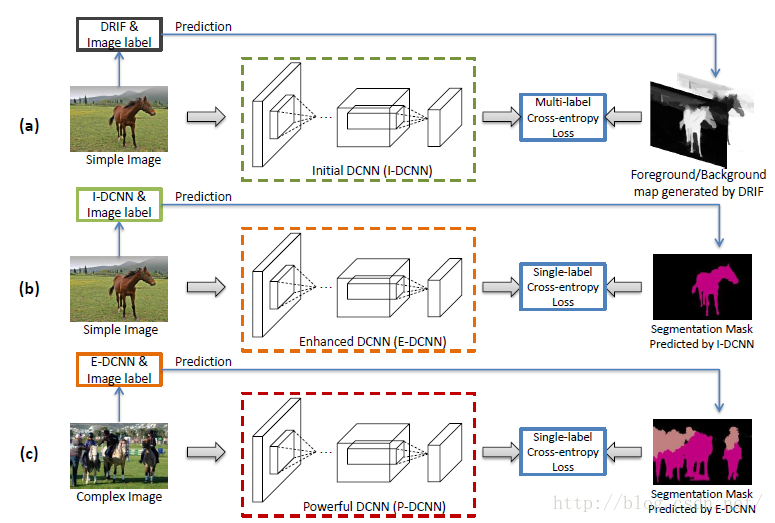
附:
文章中的Simple Images是来自于自建的Flickr Clean数据集。Complex Images是来自于Pascal VOC的train_aug。
参考文献:Wei Y, Liang X, Chen Y, et al. STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation[J]. arXiv preprint arXiv:1509.03150, 2015.
---------------------------------------------------------------------------------------------------------------------------
译文:
摘要:
最近,由于深度卷积神经网络(DCNN)的发展,语义对象分割已经取得了显著的进步。训练这样的DCNN通常依赖于大量的具有像素级分割掩模的图像,并且注解这些图像在财力和人力两方面都是非常昂贵的。在本文中,我们提出了一个简单到复杂(STC)的框架,其中只有图像级别的注释被用来学习DCNN的语义分割。具体而言,我们首先用简单图像的显著图(即,具有单个类别的主要对象和干净背景的那些)的显著图来训练初始分割网络Initial-DCNN。这些显著图可以通过现有的自下而上的显著物体检测技术自动获得,其中不需要监督信息。然后,基于Initial-DCNN以及图像级注释,在预测的简单图像的分割掩模的监督下学习一个称为Enhanced-DCNN的更好的网络。最后,利用Enhanced-DCNN和图像级注释推导出复杂图像(背景杂乱的两类或多类物体)的更多像素级分割掩模作为监督信息学习Powerful-DCNN语义分割。我们的方法利用来自Flickr.com的40K简单图像和来自PASCAL VOC的10K复杂图像来逐步提升分割网络。 PASCAL VOC 2012分段基准的广泛实验结果很好地证明了与其他技术水平相比,STC框架的优越性。
1 INTRODUCTION
近年来,深度卷积神经网络(DCNNs)在图像分类[1] - [4],目标检测[5],[6]和语义分割[7]等各种计算机视觉任务中展示了出色的能力13]。大多数用于这些任务的DCNN依赖于强监督训练,即ground-truth边界框和像素级分割掩模。 但是,与方便的图像级标签相比,收集边界框或像素级掩模的注释要昂贵得多。 特别是对于语义分割任务来说,标注大量的像素级掩模通常需要大量的财务费用以及人力。
为了解决这个问题,相关研究者们已经提出了一些方法[14] - [18],仅仅使用图像级标签作为监督信息进行语义分割。然而,就我们所知,这些方法的性能远不能令人满意,考虑到语义分割问题的复杂性,如类内高度差异(例如多样的外观,观点和尺度)以及不同的类别、对象之间的相互作用(例如,部分可见性和遮挡),具有图像级注释的复杂损失函数(例如,基于多实例学习的损失函数)[14],[15],[18]由于对分割掩模的内在像素级属性的忽略,可能不足以用于弱监督语义分割。
需要指出的是,在过去的几年中,已经提出了许多不需要高级别监督信息的显著物体检测方法[19] - [22]来检测图像中视觉上最明显的显著物体。虽然这些方法对于具有多个对象和杂乱背景的复杂图像可能不适用,但它们通常为具有单个类别和干净背景的对象的图像提供令人满意的显著图。通过自动检索大量的网页图像和检测相对简单的图像的显著对象,我们可能能够以低成本获得大量的用于训练语义分割DCNN的显著图。
在这项工作中,我们基于以下认识(intuition)提出了一个简单到复杂的弱监督分割框架。对于具有嘈杂背景和两类或多类物体的复杂图像,通常只使用图像级标签作为监督信息来推断语义标签和像素之间的关系是很困难的。然而,对于干净背景和单一类别主要对象的简单图像,前景和背景像素很容易根据显着的对象检测技术进行分割[20] - [23]。伴随图像级标签的提示,能够自然地推断出在属于前景的像素中,哪些像素可以被分配相同的语义标签。因此,可以根据前景/背景掩模和图像级标签从简单图像中学习初始分割器。此外,基于初始分割器,可以分割更多来自复杂图像的对象,从而可以不断学习更强大的分割器以进行语义分割。
具体而言,语义标签首先被用作查询以在图像托管网站(例如,Flickr.com)上检索图像。从前几页中检索的图像通常符合简单图像的定义。通过这些简单的图像,高质量的显著性图通过最先进的显著性检测技术生成[22]。基于图像标签的监督信息,我们可以很容易地为每个前景像素指定一个语义标签,并且通过使用多标签交叉熵损失函数来学习由生成的显著图监督的语义分割DCNN,其中每个像素被分类为根据预测概率嵌入在显著图中的前景类别和背景。然后,利用简单到复杂的学习过程逐步提高DCNN的能力,其中通过初始学习的DCNN预测的简单图像的分割掩模反过来被用作学习增强的DCNN的监督。最后,利用增强的DCNN,复杂图像中的更多困难和多类别的掩模被进一步用于学习更强大的DCNN。具体将这项工作所做的贡献总结如下:
(1)我们提出了一个简单到复杂的(STC)框架,能够以弱监督的方式有效地训练分割DCNN(即,仅提供图像级标签)。所提出的框架是通用的,并且可以结合任何最先进的全监督网络结构来学习分割网络。
(2)引入了一个多标签交叉熵损失函数来训练基于显著图的分割网络,其中每个像素能够以不同的概率自适应地归结于前景类别和背景。
(3) 我们在PASCAL VOC 2012分割基准上评估我们的方法[24]。 实验结果很好地证明了STC框架的有效性,达到了最先进的实验结果。
2 RELATED WORK
2.1 弱监督语义分割
为了减轻像素级掩模标注的负担,已经提出了一些用于语义分割的弱监督方法。Dai等人[8]和帕潘德里欧等人[14]提出通过利用带注释的边界框来估计语义分割掩模。例如,通过采用来自Pascal VOC [24]的像素级掩模和来自COCO [25]的带注释的边界框,[8]实现了PASCAL VOC 2012基准的最新结果。为了进一步减少边界框收集的负担,一些工作[14-16]提出仅通过使用图像级标签来训练分割网络。Pathak等人[16]和Pinheiro等[15]提出利用多重实例学习(MIL)[29]框架来训练分割的DCNN。在[14]中,提出了一种基于期望最大化(EM)算法的替代训练过程来动态预测前景(含语义)/背景像素。 Pathak等人[18]引入了约束卷积神经网络的弱监督分割。具体而言,通过利用对象的大小作为额外的监督信息,[18]作出了重大的改进。最近,[28]利用三种损失函数,即seeding,扩张和限制到边界来训练分割网络。 Saleh等人[27]也提出了一个相关的方法,使用前景/背景之前学习分割,这些都能够证明我们框架的有效性。
2.2 自主学习
我们的框架首先从简单的图像中学习,然后将学习到的网络应用到与自主学习有关的复杂网络[30]。 最近,各种基于自主学习的计算机视觉应用已经被提出了[31] - [33]。 具体而言,唐等人 [31]通过从简单的样本开始,从图像学习视频的物体检测器。 江等人 [32]解决了数据的多样性问题。 在文献[33]中,只有很少的样本被用作训练弱对象检测器的seed,然后迭代地累积更多的实例来增强对象检测器,这可以被认为是轻微监督( slightly-supervised)的自主学习的学习方法。然而,与每次迭代自动选择样本进行训练的自我学习不同的是,简单或复杂的样本根据其外观(例如,单个/多个对象或干净/混乱的背景)在训练这一工作之前进行定义。
此外,许多其他工作[17],[34] - [37]也用于解决这个问题。 这些方法通常应用于简单或小规模的数据集,如MSRA [38]和SIFT-flow [39]。 具体来说,刘等人 [35]提出了一种图形传播方法来自动分配图像级别的注释标签到那些上下文导出的语义区域。 徐等人 [34]提出了一个潜在的结构化预测框架,图形模型编码是否存在一个类,以及语义标签的分配超像素。Vezhnevets等 [37]提出了一个最大期望的协议模型选择准则,该模型选择准则从语义分割的结构化模型的参数族评估模型的质量。
3 PROPOSED METHOD
图1展示了所提出的简单到复杂(STC)框架的体系结构。我们利用最先进的显著性检测方法,即区分性区域特征积分(DRFI)[22]来生成简单图像的显著图。 生成的显著图首先用于训练具有多标记交叉熵损失函数的初始DCNN。 然后提出了简单到复杂的框架,逐步提高分割DCNN的能力。
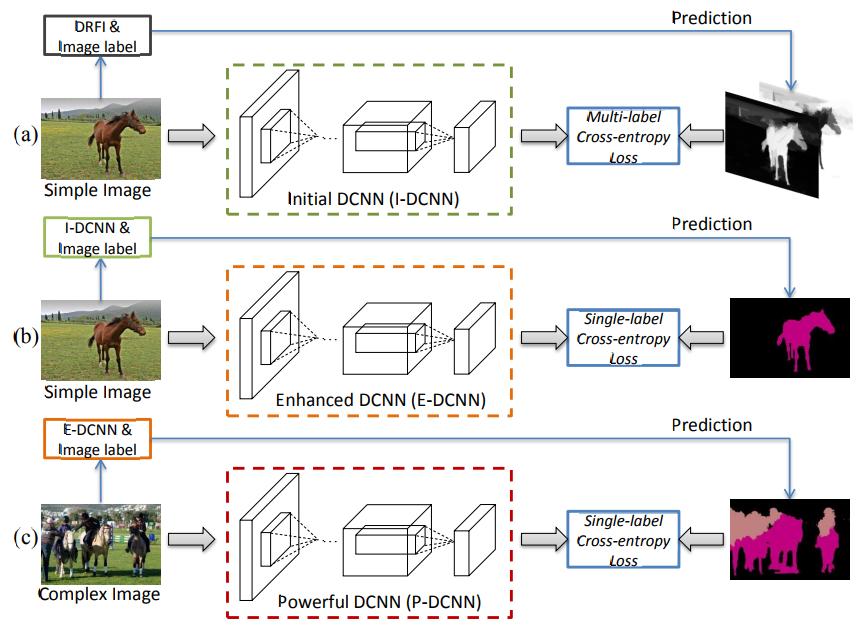
Fig. 1. An illustration of the proposed simple to complex (STC) framework. (a) High quality saliency maps of simple images are first generated by DRFI [22] as the supervised foreground/background masks to train the Initial-DCNN using the proposed loss function. (b) Then, a better Enhanced-DCNN is learned, supervised with the segmentation masks predicted by Initial-DCNN. (c) Finally, more masks of complex images are predicted to train a more powerful network, called Powerful-DCNN.
3.1 Initial-DCNN
对于简单图片,先通过显著图预测出其最显著的区域。对于每个图像生成的显著图,较大像素值意味着这个像素更可能属于前景。图2显示了一些简单的例子图像和相应的显著图由DRFI方法生成。可以观察到,前景像素与语义之间的多个对象存在明显的相关性。由于每个简单的图像伴随着一个语义标签,可以很容易推断出前景候选像素可以分配相应的图像级标签。随后,由一个多标签交叉熵损失函数来训练分割网络,以显著图作为监督信息。

Fig. 2. Examples of simple images and the corresponding saliency maps generated by DRFI on the 20 classes of PASCAL VOC.
假设训练集中有C个类。用OI= {1,2,...,C},OP= {0,1,2,...,C}分别表示图像级和像素级的类别集标签,其中0表示背景类。分割网络由f(•)过滤,其中所有的卷积层过滤给定的图像I。 f(•)产生一个h*w*(c+1)维的激活输出,其中h和w分别表示每个通道的特征图的高度以及宽度。我们利用softmax函数对I中属于第k类的每一个像素进行计算,其表述如下:
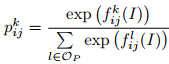 (1)
(1)
其中是fkij(I)第k个特征图中位于(i,j)(1<=i<=h,1<=j<=w)处的激活值,通常情况下,对于在(i,j)处的第l类的显著图,将其定义为:
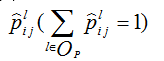 (2)
(2)
然后,多标签交叉熵损失函数被描述如下:
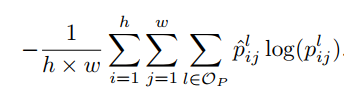 (3)
(3)
特别的,对于每一张简单图片,假定其中只含有一种语义标签,又假设简答图像数据集I属于第C类,那么来自显著图的归一化值被认为是属于类C的每个像素的概率。我们将显著图大小调整为与DCNN的输出特征映射相同的大小。那么公式(3)可以重新表示为:
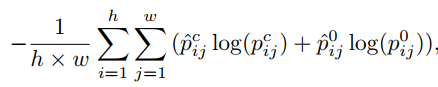 (4)
(4)
poij表示(i,j)处的像素属于背景的概率。将这个阶段学习到的分割网络表示为Initial-DCNN(简称I-DCNN)。
需要指出的是,我们也可以利用SaliencyCut [20]生成基于生成的显著图的前景/背景分割掩模。然后,可以使用单标签交叉熵损失函数进行训练。我们将这个方案与我们提出的方法进行比较,发现VOC 2012的性能将下降3%。原因是一些显著性检测结果是不准确的。因此,直接应用SaliencyCut [20]生成分割掩模将引入许多噪声,这对训练I-DCNN是有害的。然而,基于提出的多标签交叉熵损失,正确的语义标签仍然有助于优化性能,可以减少低质量显著图所带来的负面影响。
3.2 Simple to Complex Framework
在本节中,通过将更复杂的图像与图像级标签相结合来逐步提高的训练策略,提高DCNN的分割能力。 基于训练后的I-DCNN,可以预测图像的分割掩模,进一步提高DCNN的分割能力。类似于3.1节的定义,我们将位置(i,j)处的第k类的预测概率表示为pkij。然后,通过分割DCNN的位置(i,j)处的像素的估计标记gij可以被描述为:
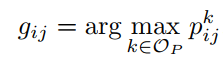 (5)
(5)
3.2.1 Enhanced-DCNN
然而,当用作训的DCNN作监督时,来自I-DCNN的错误预测可能导致语义分割的漂移。 幸运的是,对于训练集中的每个简单图像,给出了图像级标签,可以以此来改进预测的分割掩模。 具体而言,如果简单图像I用c(c∈OI)标记,则可以将像素的估计标签重新表示为:
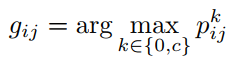 (6)
(6)
其中0表示背景类别。 通过这种方式,可以消除训练集中简单图像的一些错误预测。然后,利用预测的分割掩模作为监督信息,训练出一个更强大的分割DCNN,称为Enhanced-DCNN(简称E-DCNN)。 我们利用单标签交叉熵损失函数对E-DCNN进行训练,这被全监督方案广泛使用[11]。
3.2.2 Powerful-DCNN
在这个阶段,利用图像级标签的复杂图像,其中包含更多的语义对象和杂乱的背景被用来训练分割DCNN。与I-DCNN相比,由于大量的预测分割掩码的使用,E-DCNN具有更强大的语义分割能力。虽然E-DCNN是用简单的图像训练的,但是这些图像中的语义对象在外观,尺度和视角方面有很大的变化,这与它们在复杂图像中的外观变化是一致的。 因此,我们可以应用E-DCNN来预测复杂图像的分割掩模。 与公式(5)类似,为了消除错误预测,将图像I的每个像素的估计标签表示为:
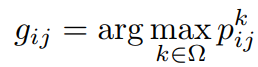 (7)
(7)
其中Ω表示每个图像I的ground-truth语义标签(包括背景)的集合。我们将在这个阶段训练的分割网络表示为更强大的DCNN(简称P-DCNN)。
在这项工作中,利用两种交叉熵损失函数来训练分割网络。具体来说,全卷积神经网络中的交叉熵损失是像素级别的。对于全监督,每个像素只能被分配到一个类,相应的交叉熵是单标签的。这符合E-DCNN和P-DCNN的目标。因此,我们使用单标签损失函数对这两个网络进行训练。对于训练I-DCNN,每个像素的类别信息不能被准确地获得。为了解决这个问题,根据生成的显著图和图像级标签,每个像素与两个类(一个是背景,另一个是20个前景类之一)以不同的概率轻微关联。我们认为这个方案的损失函数是多标签的信噪比损失。为了说明每个步骤的有效性,图3中示出了由I-DCNN,EDCNN和P-DCNN生成的一些分割结果。可以看出,基于所提出的简单到复杂的框架,分割结果逐渐变得更好。

Fig. 3. Examples of segmentation results generated by IDCNN, E-DCNN and P-DCNN on the PASCAL VOC 2012 val set, respectively

论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation的更多相关文章
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- 论文阅读笔记十七:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(CVPR2017)
论文源址:https://arxiv.org/abs/1611.06612 tensorflow代码:https://github.com/eragonruan/refinenet-image-seg ...
- 论文阅读笔记二十:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(CVPR2017)
源文网址:https://arxiv.org/abs/1707.03718 tensorflow代码:https://github.com/luofan18/linknet-tensorflow 基于 ...
- 论文笔记:Parallel Tracking and Verifying: A Framework for Real-Time and High Accuracy Visual Tracking
Parallel Tracking and Verifying: A Framework for Real-Time and High Accuracy Visual Tracking 本文目标在于 ...
- 【CV论文阅读】:Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN总结 不总结就没有积累 R-CNN的全称是 Regions with CNN features.它的主要基础是经典的AlexNet,使用AlexNet来提取每个region特征,而不再是传统 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
随机推荐
- jq自定义多选下拉列表框
多选选择国家插件 https://gitee.com/richard1015/dropDownList
- 使用mybatis插入自增主键ID的数据后返回自增的ID
在开发中碰到用户注册的功能需要用到用户ID,但是用户ID是数据库自增生成的,这种情况上网查询后使用下面的方式配置mybatis的insert语句可以解决: <insert id="in ...
- spring 代码中获取ApplicationContext(@AutoWired,ApplicationListener)
2017年度全网原创IT博主评选活动投票:http://www.itbang.me/goVote/234 学习spring框架时间不长,一点一滴都得亲力亲为.今天忽然觉得老是通过@Autowir ...
- 对于java中的"\"和"/" 区别
"\"在mac系统和类Unix 系统中是识别不出来的,对于java这种跨平台的语言来说不宜使用这个符号 "/"使用这个符号一般 都可以被识别
- 利用vitual构造类的动态多态性
虚函数: 在程序运行过程中调用函数名相同的函数而实现不同功能的函数 利用虚函数这一特性,我们可以在公有继承的基类(父类)中定义虚函数,而在它们的派生类(子类)中通过基类指针来实现派生类中同名函数的调用 ...
- Jupyter 初体验
简介 Jupyter notebook 是一个非常强大的工具,可以创建漂亮的交互式文档. 安装 安装环境:win7专业版32位系统 + python 3.6.4 安装命令:pip install ju ...
- 遇见JMS[1] —— activeMQ的简单使用
1.JMS Java Message Service,提供API,供两个应用程序或者分布式应用之间异步通信,以传送消息. 2.相关概念 提供者:实现JMS规范的消息中间件服务器客户端:发送或接收消息的 ...
- Qt Create or VS 2015 使用 Opencv330 相机静态库链接错误如何解决?
查看链接库,添加 vfw32.lib 即可.
- javascript高级程序设计第三章的一些笔记
[TOC] 1. 语法 1.1 区分大小写 变量.函数名和操作费都区分大小写. 1.2 标识符 标识符指变量.函数.属性的名字,或者函数的参数.标识符按以下规则组合: 第一个字符必须是一个字母,下划线 ...
- gogogo