【Java】详解java对象的序列化
目录结构:
1.序列化的含义和意义
序列化机制允许将实现序列化的Java对象转化为字节序列,这些字节序列可以保存到磁盘上,或通过网络传输,以备以后重新恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而单独存在。如果需要让某个类支持序列化机制,那么必须实现Serializable或Externalizable接口。在Java库中,已经有许多类实现了Serializable接口,Serializable是一个标记接口,该接口无需实现任何方法,它只是表明该类是可序列化的。所有可能在网络上传输的对象的类都应该是可序列化的,否则程序将会出现异常,比如RMI(Remote Method Invoke,远程方法调用)过程中的参数和返回值;所有需要保持到磁盘里的对象的类都必须是可序列化的。
使用java序列化的时候需要注意:
a.对象的类名,实例变量都会被序列化;方法,类变量,transient实例变量不会被序列化。
b.实现Serializable接口的类如果需要让某个实例变量不会序列化,则可在实例变量前加transient修饰符,而不是static关键字。虽然static关键字可以达到效果,但是static关键字不是这样用的。
c.保证序列化对象的实例变量也是可序列化的,否则需要使用transient关键字来修饰该变量。
d.反序列化对象时,必须有序列化对象的class文件。
e.通过网络、文件来传输序列化的对象时候,必须按照实际写入的顺序读取。
2.使用对象流实现序列化
在上面我们已经了解到,如果需要将某个对象保持到磁盘或通过网络传输,那么该类该类应该实现Serializable接口或Externalizable接口。
为了演示,首先定义一个Person类:
public class Person implements Serializable{
public String name;
public int age;
public Person(){
System.out.println("Person的无参构造器");
}
public Person(String name,int age)
{
this.name=name;
this.age=age;
}
public String toString(){
return "name:"+name+",age:"+age;
}
@Override
protected Object clone() throws CloneNotSupportedException {
System.out.println("Person的clone方法里");
return super.clone();
}
}
下面的代码将Person对象保存到磁盘person.out文件中:
public class WriteObject {
public static void main(String[] args) throws Exception{
Person person=new Person("孙悟空",500);
FileOutputStream fos=new FileOutputStream(new File("person.out"));
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(person);
}
}
接下来的代码将从person.out文件中,反序列化一个Person对象:
public class ReadObject {
public static void main(String[] args) throws Exception{
FileInputStream fis=new FileInputStream(new File("person.out"));
ObjectInputStream ois=new ObjectInputStream(fis);
Object obj=ois.readObject();
System.out.println(obj.getClass().getSimpleName());
}
}
可以看见控制台打印了
Person
观察上面反序列化和Person的代码。可以看出,通过实现Serializable接口序列化后,再反序列化重新构建对象是没有经过Person类的无参构造器和clone方法的。这里可以暂时理解为一种特殊创建对象的方式。
3.对象引用的序列化
在上面的案例中,我们定义的Person类有两个,name和age,分别为String和int类型。通过观察String可以发现String实现了Serializable接口。其实只要一个类里面有引用类型,那么这个引用类型也必须可序列化,否则拥有该类型成员变量的类也不能序列化。
例如,在下面定义了一个Teacher类,并且持有List<Person>的引用:
public class Teacher implements Serializable{
public String name;
public List<Person> students=null;
public Teacher(String name,List<Person> students)
{
this.name=name;
this.students=students;
}
}
上面的类成员变量List<Person> students,其中List、Person和Person类中的引用类型成员变量都实现了Serializable接口,倘若有一个没有实现Serializable接口,那么这个Teacher都不能被成功序列化。
我们创建了三个对象students,teacher,teacher2:
List<Person> students=new ArrayList<Person>();
students.add(new Person("孙悟空",500));
students.add(new Person("猪八戒",400));
students.add(new Person("沙僧",300)); Teacher teacher1=new Teacher("唐僧",students);//引用List<Person>
Teacher teacher2=new Teacher("玄奘",students);//引用List<Person>
在这里需要注意的是,我们依次把这三个对象序列化到本地文件中,那么是否会得到三个不同的List<Person>对象呢,倘若是,那么teacher1和teacher2引用的对象就不是同一个对象了,显然违背了java序列化机制的初衷了。在java中,进行了特殊处理,同一个对象只会被序列化一次。
我们使用如下代码来进行验证:
public class WriteReadTest {
public static void main(String[] args) throws Exception {
List<Person> students=new ArrayList<Person>();
students.add(new Person("孙悟空",500));
students.add(new Person("猪八戒",400));
students.add(new Person("沙僧",300));
Teacher teacher1=new Teacher("唐僧",students);
Teacher teacher2=new Teacher("玄奘",students);
//开始序列化对象
FileOutputStream fos=new FileOutputStream(new File("person.out"));
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(students);
oos.writeObject(teacher1);
oos.writeObject(teacher2);
//开始反序列化对象
FileInputStream fis=new FileInputStream(new File("person.out"));
ObjectInputStream ois=new ObjectInputStream(fis);
List<Person> s=(List<Person>)ois.readObject();
Teacher t1=(Teacher)ois.readObject();
Teacher t2=(Teacher)ois.readObject();
System.out.println(s==t1.students);//true
System.out.println(s==t2.students);//true
System.out.println(t1==t2);//false
}
}
可以看出反序列化出来的三个List<Person>对象都是同一个对象。
java的序列化机制采用了如下的算法:
a.所有保存到磁盘中的对象都有一个序列化编号
b.当程序试图序列化一个对象时,程序将检查该对象是否被序列化过,只有该对象从未被序列化(在本次虚拟机中)过,系统才会将该对象转化为字节序列输出。
c.如果某个对象已经被序列化过了,程序只是输出一个序列化编号,而不是重新序列化该对象。
通过上面的算法,我们可以得出一个结论,倘若有一个对象被多次序列化,那么只有第一次会成功被序列化,其它几次只是输出序列化编号而已,例如:
可以用如下图来进行进一步理解:

4.自定义序列化
实现自定义序列化,可以通过实现Serializable或Externalizable接口。
4.1 采用实现Serializable接口实现序列化
通过实现Serializable接口来实现序列化是比较常用的,Serializable是一个标记性接口,实现该接口不需要做多余的额外工作。
接下来会介绍一些常见的操作和注意事项,
在一些特殊情况下,一个类里包含的实例变量是敏感信息,不希望被序列化到本地,那么可以在此变量上使用transient关键字。
例如:
public class Person implements Serializable{
public transient String name;//transient表明 不允许被序列化到本地
public int age;
public Person(String name,int age)
{
this.name=name;
this.age=age;
}
}
测试:
Person p1=new Person("孙悟空",500);
//开始序列化对象
FileOutputStream fos=new FileOutputStream(new File("person.out"));
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(new Person("孙悟空",500));
//开始反序列化对象
FileInputStream fis=new FileInputStream(new File("person.out"));
ObjectInputStream ois=new ObjectInputStream(fis);
Person person1=(Person)ois.readObject();
System.out.println("name:"+person1.name+",age:"+person1.age);//name:null,age:500
可以在需要被序列化的列中,定义writeReplace()方法。JVM在进行序列化时候,如果未定义该方法,则不会进行序列化,如果定义了该方法,那么该方法在writeObject之后调用。
writeObject方法的完整签名格式为:
Object writeReplace() throws ObjectStreamException
writeReplace在writeObject之后调用,一旦定义了writeReplace方法,那么由writeObject序列化的对象,会完全丢弃,程序被序列化的对象是writeReplace所返回的。
通过这个特点,我们可以把被序列化的对象,替换为我们想要的任意类型:
例如:
public class Person implements Serializable{
public String name;
public int age;
public Person(String name,int age)
{
this.name=name;
this.age=age;
}
Object writeReplace() throws ObjectStreamException
{
List<Object> list=new ArrayList<Object>();
list.add(name);
list.add(age);
return list;//返回了一个List<Object>类型的数据
}
}
我们看到writeReplace方法返回了一个List<Object>类型的数据。
public static void main(String[] args) throws Exception {
Person p1=new Person("孙悟空",500);
//开始序列化对象
FileOutputStream fos=new FileOutputStream(new File("person.out"));
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(p1);
//开始反序列化对象
FileInputStream fis=new FileInputStream(new File("person.out"));
ObjectInputStream ois=new ObjectInputStream(fis);
List<Object> p=(List<Object>)ois.readObject();
for(Object obj : p)
{
System.out.println(obj);
}
}
和writeReplace方法相对的就是readResolve方法,readResolve方法会在readObject()方法之后调用,
readResolve方法的完整签名:
Object readResolve() throws ObjectStreamException
由于readResolve方法会在readObject之后立即调用,该方法的返回值会替代原来反序列化的对象,而原来readObject反序列化的对象将会被立即抛弃。
readResolve方法在序列化单例类、枚举类时尤其有用。如果使用java5提供的枚举,当然没问题,但如果在java5以前,那么在序列化时,就需要注意了
public class Orientation implements Serializable{
public static final Orientation HORIZONTAL=new Orientation(1);
public static final Orientation VERTICAL=new Orientation(2);
private int value;
private Orientation(int value){
this.value=value;
}
}
这样的代码在java5以前经常用来表示枚举,如果使用如下的代码进行序列化:
Orientation o1=Orientation.HORIZONTAL;
//开始序列化对象
FileOutputStream fos=new FileOutputStream(new File("person.out"));
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(o1);
//开始反序列化对象
FileInputStream fis=new FileInputStream(new File("person.out"));
ObjectInputStream ois=new ObjectInputStream(fis);
Orientation o=(Orientation)ois.readObject();
System.out.println(o==o1);//false
会发现结果为false,这显然不是我们想要的。这是因为反序列化的对象时重新构建的对象,我们可以定义readResolve方法来解决这个问题:
public class Orientation implements Serializable{
public static final Orientation HORIZONTAL=new Orientation(1);
public static final Orientation VERTICAL=new Orientation(2);
private int value;
private Orientation(int value){
this.value=value;
}
Object readResolve() throws ObjectStreamException
{
if(value==1){
return HORIZONTAL;
}else if(value==2)
{
return VERTICAL;
}else{
return null;
}
}
}
这样一来,被序列化前后的对象就相等了。这样之所以,是因为序列化不包括静态变量,由于readObject后会立即调用readResolve方法,我们又在readResolve中返回了一个类变量,所以前后得到的是同一个对象。
接下来附张图片,表示writeObject,writeReplace,readObject,readResolve方法间的调用前后顺序:
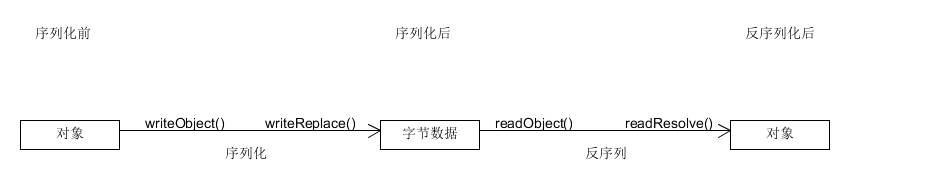
4.2采用实现Externalizable接口实现序列化
采用实现Externalizable的方式和实现Serializable的方式具有相同的效果。在上面介绍Serializable里的常用操作和方法在Externalizable接口里也同样适用,这里就不一一介绍那些操作。
采用实现Externalizable接口的方法,必须重新Externalizable接口里的两个抽象方法writeExternal和readExternal方法。
public class Person implements Externalizable{
public String name;
public int age;
public Person(){
System.out.println("公共无参构造器");
}
public Person(String name,int age)
{
this.name=name;
this.age=age;
}
/**
* 在序列化的时候调用
*/
@Override
public void writeExternal(ObjectOutput out)
throws IOException {
out.writeObject(name);
out.writeInt(age);
}
/**
* 在反序列化的时候调用
*/
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
this.name=(String)in.readObject();
this.age=in.readInt();
}
}
测试代码为:
public static void main(String[] args) throws Exception {
Person p=new Person("孙悟空",500);
//开始序列化对象
FileOutputStream fos=new FileOutputStream(new File("person.out"));
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(p);
//开始反序列化对象
FileInputStream fis=new FileInputStream(new File("person.out"));
ObjectInputStream ois=new ObjectInputStream(fis);
Person p2=(Person)ois.readObject();
System.out.println("name:"+p2.name+",age:"+p2.age);
}
打印结果为:
公共无参构造器
name:孙悟空,age:500
我们可以看到执行了Person的公共无参构造器,这是使用Externalizable和Serializable的不同点;使用Externalizable来反序列化时,是调用反序列化的类的公共无参构造器,然后在readExternal方法中对成员变量赋值,而Serializable是不会调用任何构造器的。
5序列化的版本问题
通过前面的介绍,我们知道了反序列化java对象必须提供该对象的class文件,现在的问题是,顺着项目的升级,系统的class文件也会升级,java如何保证两个class文件的兼容性?
java序列化机制允许为序列化类提供一个private static final 的serialVersionUID值,该类变量的值用于表示该java类的序列化版本,也就是一个类升级后,只要它的serialVersionUID的值不变,序列化机制也会把他们当做同一个序列化版本。
public class Test{
private static final long serialVersionUID=512L;
}
为了在反序列化时确保序列化版本的兼容性,最好在每个要序列化的的类中加入private static final long seriaVersionUID值的类变量,具体数值自己定义。这样,计时在某个类序列化之后,它所对应的类被修改了,该对象也依然可以被正确的反序列化。
可以通过JDK的bin目录下的serialver.exe工具来获得该类的serialVersionUID类变量的值。
serialver Person
【Java】详解java对象的序列化的更多相关文章
- Protocol Buffer技术详解(Java实例)
Protocol Buffer技术详解(Java实例) 该篇Blog和上一篇(C++实例)基本相同,只是面向于我们团队中的Java工程师,毕竟我们项目的前端部分是基于Android开发的,而且我们研发 ...
- 详解Java GC的工作原理+Minor GC、FullGC
详解Java GC的工作原理+Minor GC.FullGC 引用地址:http://www.blogjava.net/ldwblog/archive/2013/07/24/401919.html J ...
- 详解Java中的clone方法
详解Java中的clone方法 参考:http://blog.csdn.net/zhangjg_blog/article/details/18369201/ 所谓的复制对象,首先要分配一个和源对象同样 ...
- java基础(十五)----- Java 最全异常详解 ——Java高级开发必须懂的
本文将详解java中的异常和异常处理机制 异常简介 什么是异常? 程序运行时,发生的不被期望的事件,它阻止了程序按照程序员的预期正常执行,这就是异常. Java异常的分类和类结构图 1.Java中的所 ...
- 异常处理器详解 Java多线程异常处理机制 多线程中篇(四)
在Thread中有异常处理器相关的方法 在ThreadGroup中也有相关的异常处理方法 示例 未检查异常 对于未检查异常,将会直接宕掉,主线程则继续运行,程序会继续运行 在主线程中能不能捕获呢? 我 ...
- Java 详解 JVM 工作原理和流程
Java 详解 JVM 工作原理和流程 作为一名Java使用者,掌握JVM的体系结构也是必须的.说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Java ...
- 第十八节:详解Java抽象类和接口的区别
前言 对于面向对象编程来说,抽象是它的特征之一. 在Java中,实现抽象的机制分两种,一为抽象类,二为接口. 抽象类为abstract class,接口为Interface. 今天来学习一下Java中 ...
- 详解java动态代理机制以及使用场景
详解java动态代理机制以及使用场景 https://blog.csdn.net/u011784767/article/details/78281384 深入理解java动态代理的实现机制 https ...
- 「跬步千里」详解 Java 内存模型与原子性、可见性、有序性
文题 "跬步千里" 主要是为了凸显这篇文章的基础性与重要性(狗头),并发编程这块的知识也确实主要围绕着 JMM 和三大性质来展开. 全文脉络如下: 1)为什么要学习并发编程? 2) ...
- 实例详解 Java 死锁与破解死锁
锁和被保护资源之间的关系 我们把一段需要互斥执行的代码称为临界区.线程在进入临界区之前,首先尝试加锁 lock(),如果成功,则进入临界区,此时我们称这个线程持有锁:否则呢就等待,直到持有锁的线程解锁 ...
随机推荐
- Java开发之富文本编辑器TinyMCE
一.题外话 最近负责了一个cms网站的运维,里面存在很多和编辑器有关的问题,比如编辑一些新闻博客,论文模块.系统采用的是FCKEditor,自我感觉不是很好,如下图 特别是在用户想插入一个图片的话,就 ...
- (转)Esfog_UnityShader教程_UnityShader语法实例浅析
距离上次首篇前言已经有一段时间了,一直比较忙,今天是周末不可以再拖了,经过我一段时间的考虑,我决定这一系列的教程会避免过于深入细节,一来可以避免一些同学被误导,二来会避免文章过于冗长难读, 三来可以让 ...
- 命令行下的html转pdf工具wkhtmltopdf
基于webkit和qt的html转pdf的命令行工具,非常好使 http://code.google.com/p/wkhtmltopdf/ http://www.cnblogs.com/shanyou ...
- [Algorithm] Circular buffer
You run an e-commerce website and want to record the last N order ids in a log. Implement a data str ...
- Ubuntu 突然上不去网了怎么办
到家了也想看看程序.打开WIN8上的虚拟机VM,然后启动Ubuntu.................................... 像往常一样等待着界面,输入password,然后改动程序. ...
- 在webstorm中配置sass环境
最近开始用SASS,LESS等来写CSS,而在Webstorm中,它自带一个File Watchers功能,设置一下,即可实时编译SASS,LESS等. LESS的实时编译很简单,在node平台安装一 ...
- linux下安装与删除软件
linux下安装与删除软件 (2005-07-04 11:24:10) 转载▼ 标签: 杂谈 分类: MSN搬家 现在linuxx下的软件大都是rpm,deb.tar.gz和tar.bz2格式.1.r ...
- Go语言中使用SQLite数据库
Go语言中使用SQLite数据库 1.驱动 Go支持sqlite的驱动也比较多,但是好多都是不支持database/sql接口的 https://github.com/mattn/go-sqlite3 ...
- powx-n 分治实现乘方
题目描述 Implement pow(x, n). AC: class Solution { public: double pow(double x, int n) { && n == ...
- Linux下设置oracle环境变量
Linux设置Oracle环境变量 方法一:直接运行export命令定义变量,该变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新s ...