Hadoop集群安装-CDH5(5台服务器集群)
CDH5包下载:http://archive.cloudera.com/cdh5/
架构设计:

主机规划:
|
IP |
Host |
部署模块 |
进程 |
|
192.168.254.151 |
Hadoop-NN-01 |
NameNode ResourceManager |
NameNode DFSZKFailoverController ResourceManager |
|
192.168.254.152 |
Hadoop-NN-02 |
NameNode ResourceManager |
NameNode DFSZKFailoverController ResourceManager |
|
192.168.254.153 |
Hadoop-DN-01 Zookeeper-01 |
DataNode NodeManager Zookeeper |
DataNode NodeManager JournalNode QuorumPeerMain |
|
192.168.254.154 |
Hadoop-DN-02 Zookeeper-02 |
DataNode NodeManager Zookeeper |
DataNode NodeManager JournalNode QuorumPeerMain |
|
192.168.254.155 |
Hadoop-DN-03 Zookeeper-03 |
DataNode NodeManager Zookeeper |
DataNode NodeManager JournalNode QuorumPeerMain |
各个进程解释:
- NameNode
- ResourceManager
- DFSZKFC:DFS Zookeeper Failover Controller 激活Standby NameNode
- DataNode
- NodeManager
- JournalNode:NameNode共享editlog结点服务(如果使用NFS共享,则该进程和所有启动相关配置接可省略)。
- QuorumPeerMain:Zookeeper主进程
目录规划:
|
名称 |
路径 |
|
$HADOOP_HOME |
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0 |
|
Data |
$ HADOOP_HOME/data |
|
Log |
$ HADOOP_HOME/logs |
集群安装:
一、关闭防火墙(防火墙可以以后配置)
二、安装JDK(略)
三、修改HostName并配置Host(5台)
[root@Linux01 ~]# vim /etc/sysconfig/network
[root@Linux01 ~]# vim /etc/hosts
192.168.254.151 Hadoop-NN-01
192.168.254.152 Hadoop-NN-02
192.168.254.153 Hadoop-DN-01 Zookeeper-01
192.168.254.154 Hadoop-DN-02 Zookeeper-02
192.168.254.155 Hadoop-DN-03 Zookeeper-03
四、为了安全,创建Hadoop专门登录的用户(5台)
[root@Linux01 ~]# useradd hadoopuser
[root@Linux01 ~]# passwd hadoopuser
[root@Linux01 ~]# su – hadoopuser #切换用户
五、配置SSH免密码登录(2台NameNode)
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ ssh-keygen --生成公私钥
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoopuser@Hadoop-NN-01
-I 表示 input
~/.ssh/id_rsa.pub 表示哪个公钥组
或者省略为:
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ ssh-copy-id Hadoop-NN-01(或写IP:10.10.51.231) #将公钥扔到对方服务器
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ ssh-copy-id ”-p 6000 Hadoop-NN-01” #如果带端口则这样写
注意修改Hadoop的配置文件
vi Hadoop-env.sh
export HADOOP_SSH_OPTS=”-p 6000” [hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ ssh Hadoop-NN-01 #验证(退出当前连接命令:exit、logout)
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ ssh Hadoop-NN-01 –p 6000 #如果带端口这样写
六、配置环境变量:vi ~/.bashrc 然后 source ~/.bashrc(5台)
[hadoopuser@Linux01 ~]$ vi ~/.bashrc
# hadoop cdh5
export HADOOP_HOME=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin [hadoopuser@Linux01 ~]$ source ~/.bashrc #生效
七、安装zookeeper(3台DataNode)
安装文档:http://www.cnblogs.com/hunttown/p/5807383.html
八、安装Hadoop,并配置(只装1台配置完成后分发给其它节点)
1、解压
2、修改配置文件
|
配置名称 |
类型 |
说明 |
|
hadoop-env.sh |
Bash脚本 |
Hadoop运行环境变量设置 |
|
core-site.xml |
xml |
配置Hadoop core,如IO |
|
hdfs-site.xml |
xml |
配置HDFS守护进程:NN、JN、DN |
|
yarn-env.sh |
Bash脚本 |
Yarn运行环境变量设置 |
|
yarn-site.xml |
xml |
Yarn框架配置环境 |
|
mapred-site.xml |
xml |
MR属性设置 |
|
capacity-scheduler.xml |
xml |
Yarn调度属性设置 |
|
container-executor.cfg |
Cfg |
Yarn Container配置 |
|
mapred-queues.xml |
xml |
MR队列设置 |
|
hadoop-metrics.properties |
Java属性 |
Hadoop Metrics配置 |
|
hadoop-metrics2.properties |
Java属性 |
Hadoop Metrics配置 |
|
slaves |
Plain Text |
DN节点配置 |
|
exclude |
Plain Text |
移除DN节点配置文件 |
|
log4j.properties |
系统日志设置 |
|
|
configuration.xsl |
(1)修改 $HADOOP_HOME/etc/hadoop/hadoop-env.sh
#--------------------Java Env------------------------------
export JAVA_HOME="/usr/java/jdk1.8.0_73" #--------------------Hadoop Env----------------------------
#export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_PREFIX="/home/hadoopuser/hadoop-2.6.0-cdh5.6.0" #--------------------Hadoop Daemon Options-----------------
# export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
# export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" #--------------------Hadoop Logs---------------------------
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER #--------------------SSH PORT-------------------------------
export HADOOP_SSH_OPTS="-p 6000" #如果你修改了SSH登录端口,一定要修改此配置。
(2)修改 $HADOOP_HOME/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--Yarn 需要使用 fs.defaultFS 指定NameNode URI -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
<description>该值来自于hdfs-site.xml中的配置</description>
</property>
<!--HDFS超级用户 -->
<property>
<name>dfs.permissions.superusergroup</name>
<value>zero</value>
</property>
<!--==============================Trash机制======================================= -->
<property>
<!--多长时间创建CheckPoint NameNode截点上运行的CheckPointer 从Current文件夹创建CheckPoint;默认:0 由fs.trash.interval项指定 -->
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
<property>
<!--多少分钟.Trash下的CheckPoint目录会被删除,该配置服务器设置优先级大于客户端,默认:0 不删除 -->
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
(3)修改 $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--开启web hdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/data/dfs/name</value>
<description> namenode 存放name table(fsimage)本地目录(需要修改)</description>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>${dfs.namenode.name.dir}</value>
<description>namenode存放 transaction file(edits)本地目录(需要修改)</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/data/dfs/data</value>
<description>datanode存放block本地目录(需要修改)</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>文件副本个数,默认为3</description>
</property>
<!-- 块大小 (默认) -->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
< description>块大小256M</description>
</property>
<!--======================================================================= -->
<!--HDFS高可用配置 -->
<!--nameservices逻辑名 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!--设置NameNode IDs 此版本最大只支持两个NameNode -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- Hdfs HA: dfs.namenode.rpc-address.[nameservice ID] rpc 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>Hadoop-NN-01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>Hadoop-NN-02:8020</value>
</property>
<!-- Hdfs HA: dfs.namenode.http-address.[nameservice ID] http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>Hadoop-NN-01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>Hadoop-NN-02:50070</value>
</property> <!--==================Namenode editlog同步 ============================================ -->
<!--保证数据恢复 -->
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<!--设置JournalNode服务器地址,QuorumJournalManager 用于存储editlog -->
<!--格式:qjournal://<host1:port1>;<host2:port2>;<host3:port3>/<journalId> 端口同journalnode.rpc-address -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Hadoop-DN-01:8485;Hadoop-DN-02:8485;Hadoop-DN-03:8485/mycluster</value>
</property>
<property>
<!--JournalNode存放数据地址 -->
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/data/dfs/jn</value>
</property>
<!--==================DataNode editlog同步 ============================================ -->
<property>
<!--DataNode,Client连接Namenode识别选择Active NameNode策略 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--==================Namenode fencing:=============================================== -->
<!--Failover后防止停掉的Namenode启动,造成两个服务 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoopuser/.ssh/id_rsa</value>
</property>
<property>
<!--多少milliseconds 认为fencing失败 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property> <!--==================NameNode auto failover base ZKFC and Zookeeper====================== -->
<!--开启基于Zookeeper及ZKFC进程的自动备援设置,监视进程是否死掉 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<!--<value>Zookeeper-01:2181,Zookeeper-02:2181,Zookeeper-03:2181</value>-->
<value>Hadoop-DN-01:2181,Hadoop-DN-02:2181,Hadoop-DN-03:2181</value>
</property>
<property>
<!--指定ZooKeeper超时间隔,单位毫秒 -->
<name>ha.zookeeper.session-timeout.ms</name>
<value>2000</value>
</property>
</configuration>
(4)修改 $HADOOP_HOME/etc/hadoop/yarn-env.sh
#Yarn Daemon Options
#export YARN_RESOURCEMANAGER_OPTS
#export YARN_NODEMANAGER_OPTS
#export YARN_PROXYSERVER_OPTS
#export HADOOP_JOB_HISTORYSERVER_OPTS #Yarn Logs
export YARN_LOG_DIR="/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/logs"
(5)修改 $HADOOP_HOEM/etc/hadoop/mapred-site.xml
<configuration>
<!-- 配置JVM大小 -->
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1000m</value>
<final>true</final>
<description>final=true表示禁止用户修改JVM大小</description>
</property>
<!-- 配置 MapReduce Applications -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- JobHistory Server ============================================================== -->
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
HBase的配置:
<!-- HBase使用 start -->
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/etc/hadoop,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/common/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/common/lib/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/hdfs/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/hdfs/lib/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce/lib/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/yarn/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/yarn/lib/*,
/usr/local/hbase/lib/*
</value>
</property>
<!-- HBase使用 end -->
另:JVM配置也可以这么写:
<property>
<name>mapred.task.java.opts</name>
<value>-Xmx2000m</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>${mapred.task.java.opts} -Xmx1000m</value>
<final>true</final>
<description>相同的jvm arg写在一起,比如"-Xmx2000m -Xmx1000m",后面的会覆盖前面的,也就是说最终“-Xmx1000m”才会生效。</description>
</property>
另:如果要分别配置map和reduce的JVM大小,可以这么写
<property>
<name>mapred.map.child.java.opts</name>
<value>-Xmx512M</value>
</property>
<property>
<name>mapred.reduce.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
(6)修改 $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- nodemanager 配置 ================================================= -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property> <!-- HA 配置 =============================================================== -->
<!-- Resource Manager Configs -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 使嵌入式自动故障转移。HA环境启动,与 ZKRMStateStore 配合 处理fencing -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<!-- 集群名称,确保HA选举时对应的集群 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--这里RM主备结点需要单独指定,(可选)
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
-->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- ZKRMStateStore 配置 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<!--<value>Zookeeper-01:2181,Zookeeper-02:2181,Zookeeper-03:2181</value>-->
<value>Hadoop-DN-01:2181,Hadoop-DN-02:2181,Hadoop-DN-03:2181</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<!--<value>Zookeeper-01:2181,Zookeeper-02:2181,Zookeeper-03:2181</value>-->
<value>Hadoop-DN-01:2181,Hadoop-DN-02:2181,Hadoop-DN-03:2181</value>
</property>
<!-- Client访问RM的RPC地址 (applications manager interface) -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>Hadoop-NN-01:23140</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>Hadoop-NN-02:23140</value>
</property>
<!-- AM访问RM的RPC地址(scheduler interface) -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>Hadoop-NN-01:23130</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>Hadoop-NN-02:23130</value>
</property>
<!-- RM admin interface -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>Hadoop-NN-01:23141</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>Hadoop-NN-02:23141</value>
</property>
<!--NM访问RM的RPC端口 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>Hadoop-NN-01:23125</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>Hadoop-NN-02:23125</value>
</property>
<!-- RM web application 地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>Hadoop-NN-01:23188</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>Hadoop-NN-02:23188</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>Hadoop-NN-01:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>Hadoop-NN-02:23189</value>
</property>
</configuration>
HBase的配置:
<!-- HBase使用 start -->
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/etc/hadoop,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/common/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/common/lib/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/hdfs/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/hdfs/lib/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce/lib/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/yarn/*,
/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/yarn/lib/*,
/usr/local/hbase/lib/*
</value>
</property>
<!-- HBase使用 end -->
(7)修改 $HADOOP_HOME/etc/hadoop/slaves
Hadoop-DN-01
Hadoop-DN-02
Hadoop-DN-03
3、分发程序
#因为我的SSH登录修改了端口,所以使用了 -P 6000
scp -P 6000 -r /home/hadoopuser/hadoop-2.6.0-cdh5.6.0 hadoopuser@Hadoop-NN-02:/home/hadoopuser
scp -P 6000 -r /home/hadoopuser/hadoop-2.6.0-cdh5.6.0 hadoopuser@Hadoop-DN-01:/home/hadoopuser
scp -P 6000 -r /home/hadoopuser/hadoop-2.6.0-cdh5.6.0 hadoopuser@Hadoop-DN-02:/home/hadoopuser
scp -P 6000 -r /home/hadoopuser/hadoop-2.6.0-cdh5.6.0 hadoopuser@Hadoop-DN-03:/home/hadoopuser
4、启动HDFS
(1)启动JournalNode:
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ hadoop-daemon.sh start journalnode starting journalnode, logging to /home/hadoopuser/hadoop-2.6.0-cdh5.6.0/logs/hadoop-puppet-journalnode-BigData-03.out
验证JournalNode:
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ jps 5652 QuorumPeerMain
9076 Jps
9029 JournalNode
停止JournalNode:
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ hadoop-daemon.sh stop journalnode stoping journalnode
(2)NameNode 格式化:
结点Hadoop-NN-01:hdfs namenode -format
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ hdfs namenode -format
(3)同步NameNode元数据:
同步Hadoop-NN-01元数据到Hadoop-NN-02
主要是:dfs.namenode.name.dir,dfs.namenode.edits.dir还应该确保共享存储目录下(dfs.namenode.shared.edits.dir ) 包含NameNode 所有的元数据。
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ scp -P 6000 -r data/ hadoopuser@Hadoop-NN-02:/home/hadoopuser/hadoop-2.6.0-cdh5.6.0
(4)初始化ZFCK:
创建ZNode,记录状态信息。
结点Hadoop-NN-01:hdfs zkfc -formatZK
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ hdfs zkfc -formatZK
(5)启动
集群启动法:Hadoop-NN-01: start-dfs.sh
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ start-dfs.sh
单进程启动法:
<1>NameNode(Hadoop-NN-01,Hadoop-NN-02):hadoop-daemon.sh start namenode
<2>DataNode(Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03):hadoop-daemon.sh start datanode
<3>JournalNode(Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03):hadoop-daemon.sh start journalnode
<4>ZKFC(Hadoop-NN-01,Hadoop-NN-02):hadoop-daemon.sh start zkfc
(6)验证
<1>进程
NameNode:jps
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ jps 9329 JournalNode
9875 NameNode
10155 DFSZKFailoverController
10223 Jps
DataNode:jps
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ jps 9498 Jps
9019 JournalNode
9389 DataNode
5613 QuorumPeerMain
<2>页面:
Active结点:http://192.168.254.151:50070
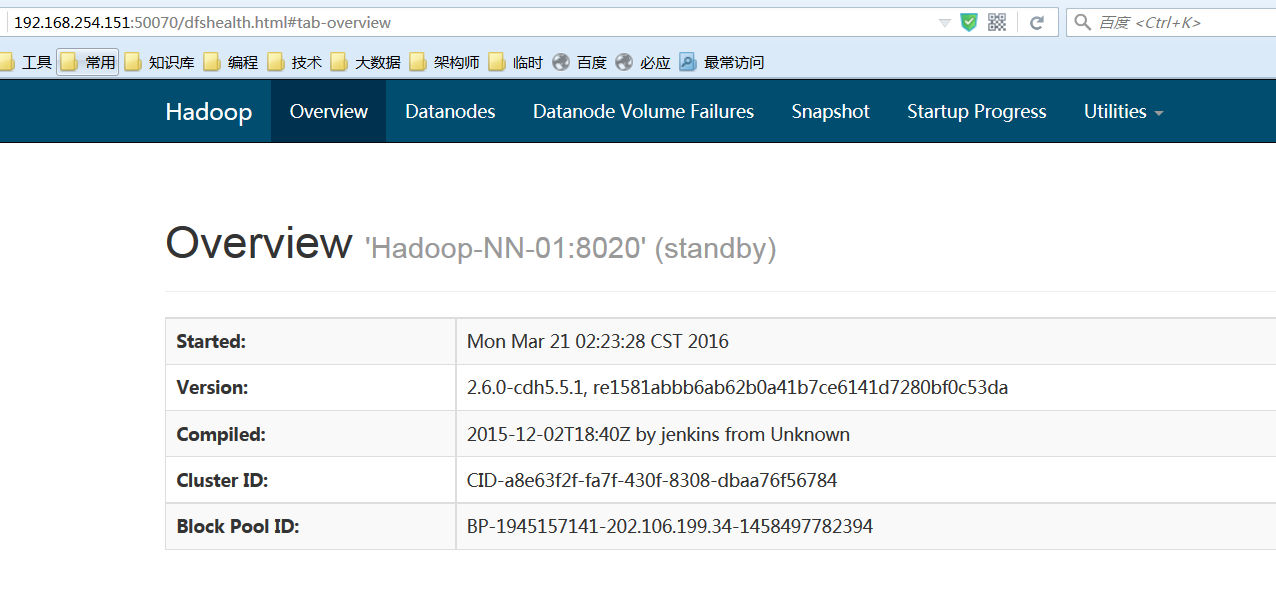

(7)停止:stop-dfs.sh
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ stop-dfs.sh
5、启动Yarn
(1)启动
<1>集群启动
Hadoop-NN-01启动Yarn,命令所在目录:$HADOOP_HOME/sbin
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ start-yarn.sh
Hadoop-NN-02备机启动RM:
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ yarn-daemon.sh start resourcemanager
<2>单进程启动
ResourceManager(Hadoop-NN-01,Hadoop-NN-02):yarn-daemon.sh start resourcemanager
DataNode(Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03):yarn-daemon.sh start nodemanager
(2)验证
<1>进程:
JobTracker:Hadoop-NN-01,Hadoop-NN-02
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ jps 9329 JournalNode
9875 NameNode
10355 ResourceManager
10646 Jps
10155 DFSZKFailoverController
TaskTracker:Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03
[hadoopuser@Linux05 hadoop-2.6.0-cdh5.6.0]$ jps 9552 NodeManager
9680 Jps
9019 JournalNode
9389 DataNode
5613 QuorumPeerMain
<2>页面
ResourceManger(Active):192.168.254.151:23188

ResourceManager(Standby):192.168.254.152:23188


(3)停止
Hadoop-NN-01:stop-yarn.sh
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ stop-yarn.sh
Hadoop-NN-02:yarn-daemon.sh stop resourcemanager
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ yarn-daeman.sh stop resourcemanager
附:Hadoop常用命令总结
#第1步 启动zookeeper
[hadoopuser@Linux01 ~]$ zkServer.sh start
[hadoopuser@Linux01 ~]$ zkServer.sh stop #停止 #第2步 启动JournalNode:
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ hadoop-daemon.sh start journalnode starting journalnode, logging to /home/hadoopuser/hadoop-dir/hadoop-2.6.0-cdh5.6.0/logs/hadoop-puppet-journalnode-BigData-03.out #两个namenode
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ hadoop-daemon.sh stop journalnode stoping journalnode #停止 #第3步 启动DFS:
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ start-dfs.sh
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ stop-dfs.sh #停止 #第4步 启动Yarn:
#Hadoop-NN-01启动Yarn
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ start-yarn.sh
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ stop-yarn.sh #停止
#Hadoop-NN-02备机启动RM
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ yarn-daemon.sh start resourcemanager
[hadoopuser@Linux01 hadoop-2.6.0-cdh5.6.0]$ yarn-daemon.sh stop resourcemanager #停止 #如果安装了HBase
#Hadoop-NN-01启动HBase的Thrift Server:
[hadoopuser@Linux01 bin]$ hbase-daemon.sh start thrift
[hadoopuser@Linux01 bin]$ hbase-daemon.sh stop thrift #停止 #Hadoop-NN-01启动HBase:
[hadoopuser@Linux01 bin]$ hbase/bin/start-hbase.sh
[hadoopuser@Linux01 bin]$ hbase/bin/stop-hbase.sh #停止 #如果安装了RHive
#Hadoop-NN-01启动Rserve:
[hadoopuser@Linux01 ~]$ Rserve --RS-conf /usr/local/lib64/R/Rserv.conf #停止 直接kill #Hadoop-NN-01启动hive远程服务(rhive是通过thrift连接hiveserver的,需要要启动后台thrift服务):
[hadoopuser@Linux01 ~]$ nohup hive --service hiveserver2 & #注意这里是hiveserver2
附:Hadoop常用环境变量配置
# JAVA
export JAVA_HOME=/usr/java/jdk1.8.0_73
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # MYSQL
export PATH=/usr/local/mysql/bin:/usr/local/mysql/lib:$PATH # Hive
export HIVE_HOME=/home/hadoopuser/hive
export PATH=$PATH:$HIVE_HOME/bin # Hadoop
export HADOOP_HOME=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0
export HADOOP_CONF_DIR=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/etc/hadoop
export HADOOP_CMD=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/bin/hadoop
export HADOOP_STREAMING=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/share/hadoop/tools/lib/hadoop-streaming-2.6.0-cdh5.6.0.jar
export JAVA_LIBRARY_PATH=/home/hadoopuser/hadoop-2.6.0-cdh5.6.0/lib/native/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # R
export R_HOME=/usr/local/lib64/R
export PATH=$PATH:$R_HOME/bin
export RHIVE_DATA=/usr/local/lib64/R/rhive/data
export CLASSPATH=.:/usr/local/lib64/R/library/rJava/jri
export LD_LIBRARY_PATH=/usr/local/lib64/R/library/rJava/jri
export RServe_HOME=/usr/local/lib64/R/library/Rserve # thrift
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig/ # HBase
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin # Zookeeper
export ZOOKEEPER_HOME=/home/hadoopuser/zookeeper-3.4.5-cdh5.6.0
export PATH=$PATH:$ZOOKEEPER_HOME/bin # Sqoop2
export SQOOP2_HOME=/home/hadoopuser/sqoop2-1.99.5-cdh5.6.0
export CATALINA_BASE=$SQOOP2_HOME/server
export PATH=$PATH:$SQOOP2_HOME/bin # Scala
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:${SCALA_HOME}/bin # Spark
export SPARK_HOME=/home/hadoopuser/spark-1.5.0-cdh5.6.0
export PATH=$PATH:${SPARK_HOME}/bin # Storm
export STORM_HOME=/home/hadoopuser/apache-storm-0.9.6
export PATH=$PATH:$STORM_HOME/bin #kafka
export KAFKA_HOME=/home/hadoopuser/kafka_2.10-0.9.0.1
export PATH=$PATH:$KAFKA_HOME/bin
Hadoop集群安装-CDH5(5台服务器集群)的更多相关文章
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- Dynamics 365 for CRM:CRM与ADFS安装到同一台服务器,需修改ADFS服务端口号
CRM与ADFS安装到同一台服务器时,出现PluginRegistrationTool 及 CRM Outlook Client连接不上,需要修改ADFS的服务端口号,由默认的808修改为809: P ...
- Hadoop集群安装-CDH5(3台服务器集群)
CDH5包下载:http://archive.cloudera.com/cdh5/ 主机规划: IP Host 部署模块 进程 192.168.107.82 Hadoop-NN-01 NameNode ...
- nginx 的安装、优化、服务器集群
一.安装 下载地址:http://nginx.org 找到 stable 稳定版 安装准备:nginx 依赖于pcre(正则)库,如果没有安装pcre先安装 yum install pcre pcr ...
- Dynamics CRM与ADFS安装到同一台服务器后ADFS服务与Dynamics CRM沙盒服务冲突提示808端口占用问题
当我们安装Dynamics CRM的产品时如果是单台服务器部署而且部署了IFD的情况会遇到一个问题就是ADFS服务的监听端口和Dynamics CRM沙盒服务的端口冲突了. 这样会导致两个服务中的一个 ...
- CDH集群安装配置(三)- 集群时间同步(主节点)和 免密码登录
集群时间同步(主节点) 1. 查看是否安装ntp服务,如果没有安装 rpm -qa |grep ntpd查看命令 yum install ntp安装命令 2. 修改配置 vi /etc/ntp.con ...
- CDH集群安装配置(一)-集群规划和NAT网络配置
三台物理机或者虚拟机. cdh1,cdh2,cdh3. 内存要求大于8GB,cdh1的物理磁盘要求多余50G. 每台虚拟机安装centos 7 系统.
- 大数据之Linux服务器集群搭建
之前写过一篇关于Linux服务器系统的安装与网关的配置,那么现在我们要进一步的搭建多台Linux服务器集群. 关于单台服务器的系统搭建配置就不在赘述了,详情见https://www.cnblogs.c ...
- Centos 下 Apache 原生 Hbase + Phoenix 集群安装(转载)
前置条件 各软件版本:hadoop-2.7.7.hbase-2.1.5 .jdk1.8.0_211.zookeeper-3.4.10.apache-phoenix-5.0.0-HBase-2.0-bi ...
随机推荐
- 编译内核时出现__bad_udelay错误
今天编译内核时候遇到了__bad_udelay错误,然后编不过去了,仔细一看发现是udelay函数的参数太大,内核不允许延时这么多.于是换成了mdelay函数,以毫秒为单位延时,问题解决.
- 题目1208:10进制 VS 2进制(进制转换以及大数保存问题)
题目链接:http://ac.jobdu.com/problem.php?pid=1208 详细链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- C# List<T> 泛型
1.简介 所属命名空间:System.Collections.Generic List<T>类是 ArrayList 类的泛型等效类.该类使用大小可按需动态增加的数组实现 IList< ...
- OPENQUERY (Transact-SQL),跨数据库操作。
在指定的链接服务器上执行指定的传递查询. 该服务器是 OLE DB 数据源. OPENQUERY 可以在查询的 FROM 子句中引用,就好象它是一个表名.OPENQUERY 也可以作为 INSERT. ...
- 【CF888E】Maximum Subsequence 折半搜索
[CF888E]Maximum Subsequence 题意:给你一个序列{ai},让你从中选出一个子序列,使得序列和%m最大. n<=35,m<=10^9 题解:不小心瞟了一眼tag就一 ...
- Node学习HTTP模块(HTTP 服务器与客户端)
Node学习HTTP模块(HTTP 服务器与客户端) Node.js 标准库提供了 http 模块,其中封装了一个高效的 HTTP 服务器和一个简易的HTTP 客户端.http.Server 是一个基 ...
- js模拟点击打开超链接
js模拟点击打开超链接,页面上有一些锚文本,如果用 JS 批量在新窗口打开. jquery示例: <div class="link"> <a href=" ...
- Redis 如何保持和MySQL数据一致
1. MySQL持久化数据,Redis只读数据 redis在启动之后,从数据库加载数据. 读请求: 不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取 写请求: 数据首先都写到数 ...
- NuGet 安装EntityFramework5 历程
第一步:VS2012中 (据说VS2010还得安装一下NuGet)工具->库程序包管理器->程序包管理器控制台,打开控制台 Install-Package EntityFramework ...
- MyEclipse无法创建servers视图:Could not create the view: An unexpected exception was thrown
今天上班刚打开MyEclipse,就发现servers视图无法打开了,显示:Could not create the view: An unexpected exception was thrown. ...