机器学习理论基础学习4--- SVM(基于结构风险最小化)
一、什么是SVM?
SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型。当然如果进行修改之后也是可以用于多类别问题的分类。支持向量机可以分为线性和非线性两大类。其主要思想为找到空间中的一个更够将所有数据样本划开的超平面,并且使得本集中所有数据到这个超平面的距离最短。
那么,又怎么表示这个“都正确”呢?可以这样考虑:就是让那些“很有可能不正确”的数据点彼此分开得明显一点就可以了。对于其它“不那么可能不正确”或者说“一看就很正确”的数据点,就可以不用管了。这也是SVM名称的由来,模型是由那些支持向量(Support Vector)决定的。这也是为什么SVM对outlier不敏感。SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
二、有几种SVM?
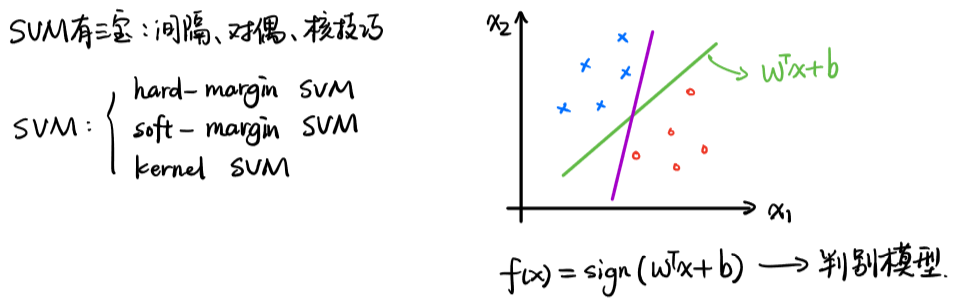
| 硬间隔SVM | 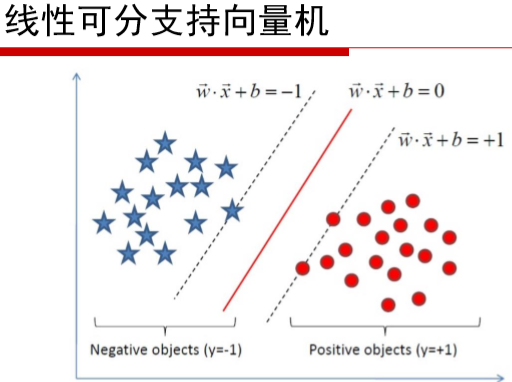 |
| 软间隔SVM | 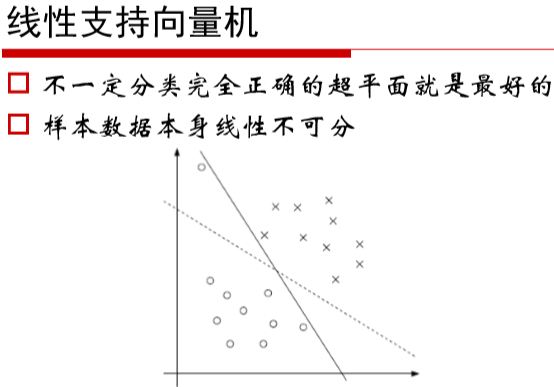 |
| kernel SVM |  |
三、几何形式>>>>>>最大间隔分类器的数学形式


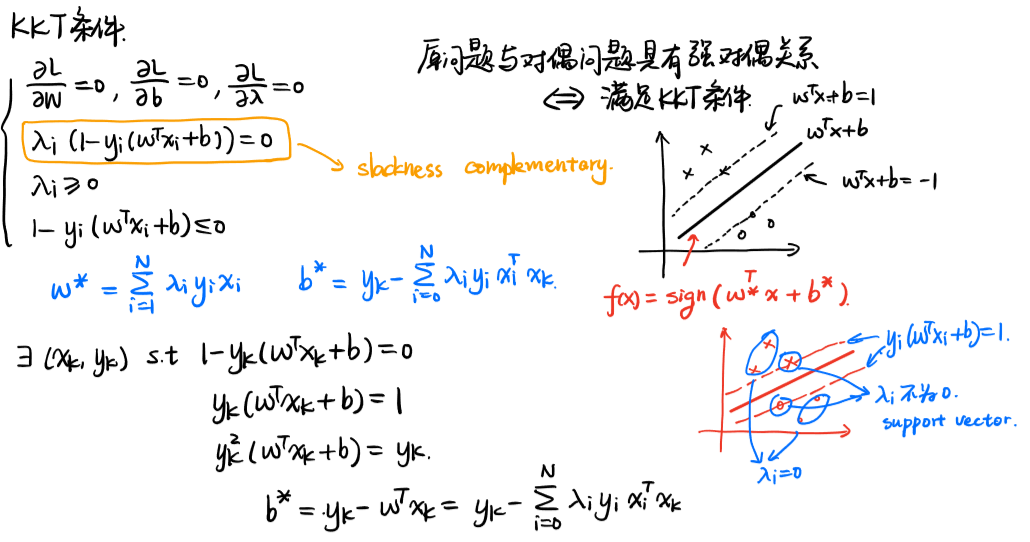
四、硬间隔SVM的推导
利用拉格朗日函数将带约束的原问题转换为无约束的问题,再利用强对偶性,得到无约束问题的等价形式,从而得到硬间隔SVM的数学形式

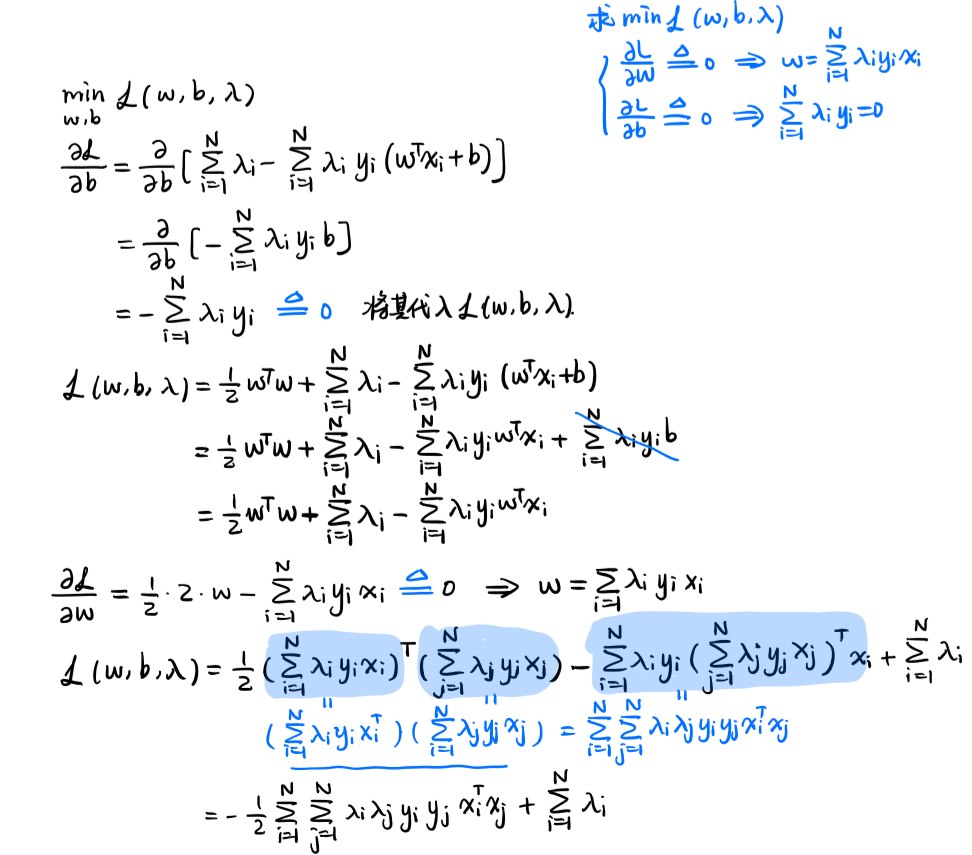
为什么将原问题转为对偶问题?
- 对偶问题将原始问题中的约束转为了对偶问题中的等式约束(KKT)
- 方便核函数的引入
- 改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关。
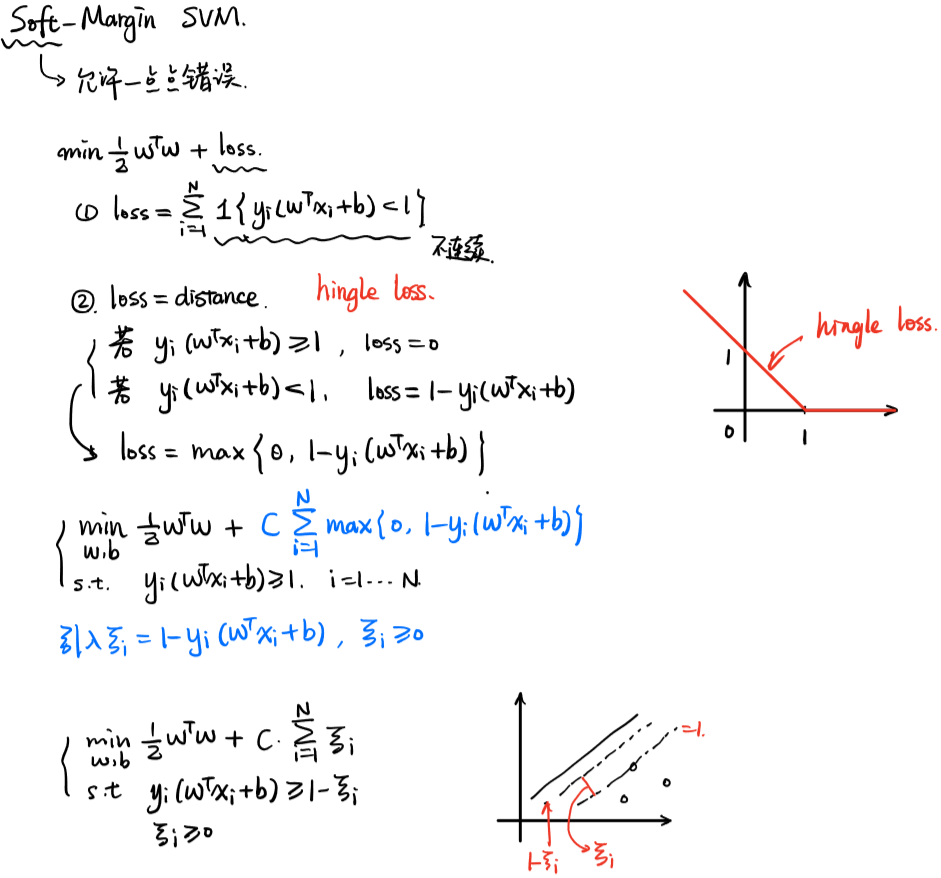
五、软间隔SVM的推导
六、核函数的选择
1、线性核函数
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的
2、多项式核函数
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
3、高斯(RBF)核函数
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。

4、sigmoid核函数
采用sigmoid核函数,支持向量机实现的就是一种多层神经网络。
因此,在选用核函数的时候,如果我们对我们的数据有一定的先验知识,就利用先验来选择符合数据分布的核函数;如果不知道的话,通常使用交叉验证的方法,来试用不同的核函数,误差最小的即为效果最好的核函数,或者也可以将多个核函数结合起来,形成混合核函数。选择核函数的技巧:
- 如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
- 如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
- 如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
七、SVM总结
- 非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
- 对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;
- 支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
- SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。
- SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
- 少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在:
①增、删非支持向量样本对模型没有影响;
②支持向量样本集具有一定的鲁棒性;
③有些成功的应用中,SVM 方法对核的选取不敏感
- SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
- SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
- SVM在小样本训练集上能够得到比其它算法好很多的结果。支持向量机之所以成为目前最常用,效果最好的分类器之一,在于其优秀的泛化能力,这是是因为其本身的优化目标是结构化风险最小,而不是经验风险最小,因此,通过margin的概念,得到对数据分布的结构化描述,因此减低了对数据规模和数据分布的要求。SVM也并不是在任何场景都比其他算法好,对于每种应用,最好尝试多种算法,然后评估结果。如SVM在邮件分类上,还不如逻辑回归、KNN、bayes的效果好。
- 它基于结构风险最小化原则,这样就避免了过学习问题,泛化能力强。
- 它是一个凸优化问题,因此局部最优解一定是全局最优解的优点。
- 泛华错误率低,分类速度快,结果易解释
补充:约束优化问题和对偶问题


参考文献:
机器学习理论基础学习4--- SVM(基于结构风险最小化)的更多相关文章
- 机器学习理论基础学习3.3--- Linear classification 线性分类之logistic regression(基于经验风险最小化)
一.逻辑回归是什么? 1.逻辑回归 逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的. logistic回归也称为逻辑回归,与线性回归这样输出 ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- 【转载】VC维,结构风险最小化
以下文章转载自http://blog.sina.com.cn/s/blog_7103b28a0102w9tr.html 如有侵权,请留言,立即删除. 1 VC维的描述和理解 给定一个集合S={x1,x ...
- 机器学习理论基础学习12---MCMC
作为一种随机采样方法,马尔科夫链蒙特卡罗(Markov Chain Monte Carlo,以下简称MCMC)在机器学习,深度学习以及自然语言处理等领域都有广泛的应用,是很多复杂算法求解的基础.比如分 ...
- svm、经验风险最小化、vc维
原文:http://blog.csdn.net/keith0812/article/details/8901113 “支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上” 结构化 ...
- 机器学习理论基础学习3.1--- Linear classification 线性分类之感知机PLA(Percetron Learning Algorithm)
一.感知机(Perception) 1.1 原理: 感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型. 假设训练数据集是线性可分的,感知机学习的目标 ...
- 机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题 ...
- 机器学习理论基础学习5--- PCA
一.预备知识 减少过拟合的方法有:(1)增加数据 (2)正则化(3)降维 维度灾难:从几何角度看会导致数据的稀疏性 举例1:正方形中有一个内切圆,当维度D趋近于无穷大时,圆内的数据几乎为0,所有的数据 ...
- 机器学习理论基础学习13--- 隐马尔科夫模型 (HMM)
隐含马尔可夫模型并不是俄罗斯数学家马尔可夫发明的,而是美国数学家鲍姆提出的,隐含马尔可夫模型的训练方法(鲍姆-韦尔奇算法)也是以他名字命名的.隐含马尔可夫模型一直被认为是解决大多数自然语言处理问题最为 ...
随机推荐
- Makefile Demo案例
# Comments can be written like this. # File should be named Makefile and then can be run as `make &l ...
- hbuilder在android手机里用chrome调试,只显示了设备名称,却没有inspect按钮
stark 通过“菜单”->“工具”->“检查设备”打开设备检查页面,只显示了设备名称,却没有inspect按钮,要怎么办 1 赞2014-10-09 22:00 ============ ...
- Windows平台编译memcached 1.2.6
两个项目libevent.memcached,Platform Toolset使用Visual Studio 2013 - Windows XP (v120_xp).在编译memcached时会提示& ...
- Rails 添加新的运行环境
Rails自带了development.test和production三个environments 我们可以添加Staging database.yml staging: adapter: mysql ...
- Android加载asset的db
extends:http://blog.csdn.net/lihenair/article/details/21232887 项目需要将预先处理的db文件加载到数据库中,然后读取其中的信息并显示 加载 ...
- 9.11 Django视图 view和路由
2018-9-11 16:34:16 2018-9-11 19:00:24 越努力,.越幸运! Django框架参考: https://www.cnblogs.com/liwenzhou/p/8296 ...
- RestTemplate异常no suitable HttpMessageConverter found for request type [java.lang.Integer]
GET方式,参数必须放在URL后面,http://xxx/list?name={name}&age={age} package com.chelizi.xiruo.xframework.uti ...
- CodeForces - 665D Simple Subset 想法题
//题意:给你n个数(可能有重复),问你最多可以取出多少个数使得任意两个数之和为质数.//题解:以为是个C(2,n)复杂度,结果手摸几组,发现从奇偶性考虑,只有两种情况:有1,可以取出所有的1,并可以 ...
- 经典的DOS小命令 for 网络 nbtstat
--网络scanner · 1.最基本,最常用的,测试物理网络的 ping 192.168.10.59 -t ,参数-t是等待用户去中断测试 2.查看DNS(对猫用户),还是比较有用处的 A.Win9 ...
- HTML 标签大全及属性
基本结构标签: <HTML>,表示该文件为HTML文件 <HEAD>,包含文件的标题,使用的脚本,样式定义等 <TITLE>---</TITLE>,包含 ...