python学习之RabbitMQ-----消息队列
RabbitMQ队列
首先我们在讲rabbitMQ之前我们要说一下python里的queue:二者干的事情是一样的,都是队列,用于传递消息
在python的queue中有两个一个是线程queue,一个是进程queue(multiprocessing中的queue)。线程queue不能够跨进程,用于多个线程之间进行数据同步交互;进程queue只是用于父进程与子进程,或者同属于同意父进程下的多个子进程 进行交互。也就是说如果是两个完全独立的程序,即使是python程序,也依然不能够用这个进程queue来通信。那如果我们有两个独立的python程序,分属于两个进程,或者是python和其他语言
安装:windows下
安装pika:
之前安装过了pip,直接打开cmd,运行pip install pika
安装完毕之后,实现一个最简单的队列通信:
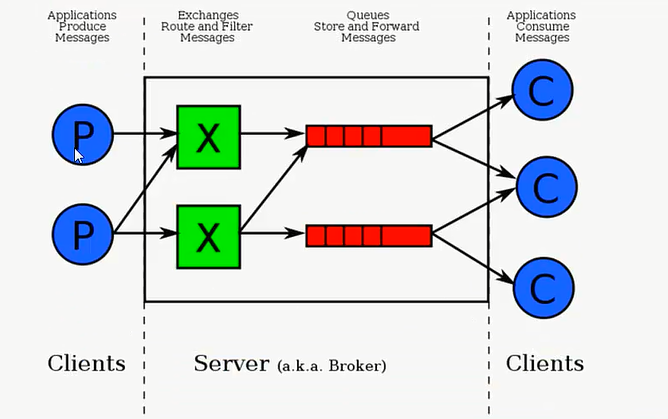
producer:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#声明一个管道
channel = connection.channel()
#声明queue
channel.queue_declare(queue = 'hello')
#routing_key是queue的名字
channel.basic_publish(exchange='',
routing_key='hello',#queue的名字
body='Hello World!',
)
print("[x] Send 'Hello World!'")
connection.close()
先建立一个基本的socket,然后建立一个管道,在管道中发消息,然后声明一个queue,起个队列的名字,之后真正的发消息(basic_publish)
consumer:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body):#回调函数
print("---->",ch,method,properties)
print(" [x] Received %r" % body) channel.basic_consume(callback,#如果收到消息,就调用callback来处理消息
queue='hello',
no_ack=True
) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
start_consuming()只要一启动就一直运行下去,他不止收一条,永远在这里卡住。
在上面不管是produce还是consume,里面都声明了一个queue,这个是为什么呢?因为我们不知道是消费者先开始运行还是生产者先运行,这样如果没有声明的话就会报错。
下面我们来看一下一对多,即一个生产者对应多个消费者:
首先我们运行3个消费者,然后不断的用produce去发送数据,我们可以看到消费者是通过一种轮询的方式进行不断的接受数据,每个消费者消费一个。
那么假如我们消费者收到了消息,然后处理这个消息需要30秒钟,在处理的过程中,消费者断电了宕机了,那消费者还没有处理完,我们设这个任务我们必须处理完,那我们应该有一个确认的信息,说这个任务完成了或者是没有完成,所以我的生产者要确认消费者是否把这个任务处理完了,消费者处理完之后要给这个生产者服务器端发送一个确认信息,生产者才会把这个任务从消息队列中删除。如果没有处理完,消费者宕机了,没有给生产者发送确认信息,那就表示没有处理完,那我们看看rabbitMQ是怎么处理的
我们可以在消费者的callback中添加一个time.sleep()进行模拟宕机。callback是一个回调函数,只要事件一触发就会调用这个函数。函数执行完了就代表消息处理完了,如果函数没有处理完,那就说明。。。。
我们可以看到在消费者代码中的basic_consume()中有一个参数叫no_ack=True,这个意思是这条消息是否被处理完都不会发送确认信息,一般我们不加这个参数,rabbitMQ默认就会给你设置成消息处理完了就自动发送确认,我们现在把这个参数去掉,并且在callback中添加一句话运行:ch.basic_ack(delivery_tag=method.delivery_tag)(手动处理)
def callback(ch, method, properties, body):#回调函数
print("---->",ch,method,properties)
#time.sleep(30)
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
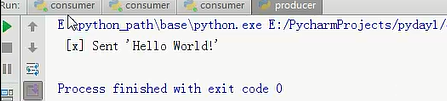
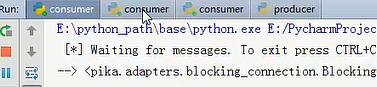
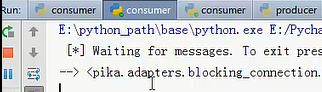
运行的结果就是,我先运行一次生产者,数据被消费者1接收到了,但是我把消费者1宕机,停止运行,那么消费者2就接到了消息,即只要消费者没有发送确认信息,生产者就不会把信息删除。
RabbitMQ消息持久化:
我们可以生成好多的消息队列,那我们怎么查看消息队列的情况呢:rabbitmqctl.bat list_queues

现在的情况是,消息队列中还有消息,但是服务器宕机了,那这个消息就丢了,那我就需要这个消息强制的持久化:
channel.queue_declare(queue='hello2',durable=True)
在每次声明队列的时候加上一个durable参数(客户端和服务器端都要加上这个参数),
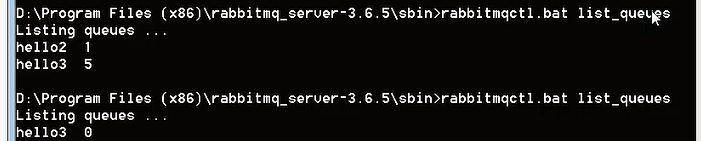
在这个情况下,我们把rabbitMQ服务器重启,发现只有队列名留下了,但是队列中的消息没有了,这样我们还需要在生产者basic_publish中添加一个参数:properties
producer:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#声明一个管道
channel = connection.channel()
#声明queue
channel.queue_declare(queue = 'hello2',durable=True)
#routing_key是queue的名字
channel.basic_publish(exchange='',
routing_key='hello2',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2,#make message persistent
)
)
print("[x] Send 'Hello World!'")
connection.close()
这样就可以使得消息持久化
现在是一个生产者对应三个消费者,很公平的收发收发,但是实际的情况是,我们机器的配置是不一样的,有的配置是单核的有的配置是多核的,可能i7处理器处理4条消息的时候和其他的处理器处理1条消息的时间差不多,那差的处理器那里就会堆积消息,而好的处理器那里就会形成闲置,在现实中做运维的,我们会在负载均衡中设置权重,谁的配置高权重高,任务就多一点,但是在rabbitMQ中,我们只做了一个简单的处理就可以实现公平的消息分发,你有多大的能力就处理多少消息
即:server端给客户端发送消息的时候,先检查现在还有多少消息,如果当前消息没有处理完毕,就不会发送给这个消费者消息。如果当前的消费者没有消息就发送
这个只需要在消费者端进行修改加代码:
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel() channel.queue_declare(queue='hello2',durable=True) def callback(ch, method, properties, body):#回调函数
print("---->",ch,method,properties)
#time.sleep(30)
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,#如果收到消息,就调用callback来处理消息
queue='hello2',
#no_ack=False
) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
我们在生成一个consume2,在callback中sleep20秒来模拟
我先启动两个produce,被consume接受,然后在启动一个,就被consumer2接受,但是因为consumer2中sleep20秒,处理慢,所以这时候在启动produce,就又给了consume进行处理
Publish\Subscrible(消息发布\订阅)
前面都是1对1的发送接收数据,那我想1对多,想广播一样,生产者发送一个消息,所有消费者都收到消息。那我们怎么做呢?这个时候我们就要用到exchange了
exchange在一端收消息,在另一端就把消息放进queue,exchange必须精确的知道收到的消息要干什么,是否应该发到一个特定的queue还是发给许多queue,或者说把他丢弃,这些都被exchange的类型所定义
exchange在定义的时候是有类型的,以决定到底是那些queue符合条件,可以接受消息:
fanout:所有bind到此exchange的queue都可以接受消息
direct:通过rounroutingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey的routingKey所bind的queue可以接受消息
headers:通过headers来决定把消息发给哪些queue
消息publisher:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='log',type = 'fanout') message = ' '.join(sys.argv[1:]) or 'info:Hello World!'
channel.basic_publish(exchange='logs',routing_key='',body=message)
print("[x] Send %r " % message)
connection.close()
这里的exchange之前是空的,现在赋值log;在这里也没有声明queue,广播不需要写queue
消息subscriber:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',exchange_type='fanout') #exclusive唯一的,不指定queue名字,rabbit会随机分配一个名字
#exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue channel.queue_bind(exchange='logs',queue=queue_name) print('[*] Waiting for logs,To exit press CTRL+C') def callback(ch,method,properties,body):
print("[X] %r" % body)
channel.basic_consume(callback,queue = queue_name,no_ack=True)
channel.start_consuming()
在消费者这里我们有定义了一个queue,注意一下注释中的内容。但是我们在发送端没有声明queue,为什么发送端不需要接收端需要呢?在consume里有一个channel.queue_bind()函数,里面绑定了exchange转换器上,当然里面还需要一个queue_name
运行结果:




就相当于收音机一样,实时广播,打开三个消费者,生产者发送一条数据,然后3个消费者同时接收到
有选择的接收消息(exchange_type = direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据关键字判定应该将数据发送到指定的队列
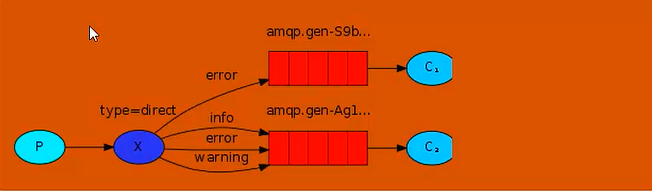
publisher:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',exchange_type='direct') severity = sys.argv[1] if len(sys.argv)>1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',routing_key=severity,body=message) print("[X] Send %r:%r" %(severity,message))
connection.close()
subscriber:
import pika
import sys
connect = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connect.channel() channel.exchange_declare(exchange='direct_logs',exchange_type='direct') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue severities = sys.argv[1:]#
if not severities:
sys.stderr.write("Usage:%s [info] [warning] [error]\n" %sys.argv[0])
sys.exit(1) for severity in severities:
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity) print('[*]Waiting for logs.To exit press CTRL+c') def callback(ch,method,properties,body):
print("[x] %r:%r"%(method.routing_key,body)) channel.basic_consume(callback,queue = queue_name,no_ack=True)
channel.start_consuming()
更加细致的过滤(exchange_type=topic)
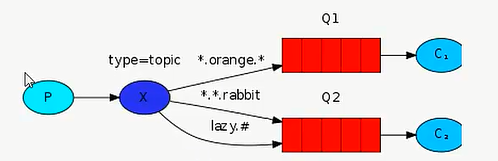
publish:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
exchange_type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
subscriber:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
exchange_type='topic') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1) for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
以上都是服务器端发消息,客户端收消息,消息流是单向的,那如果我们想要发一条命令给远程的客户端去执行,然后想让客户端执行的结果返回,则这种模式叫做rpc
RabbitMQ RPC
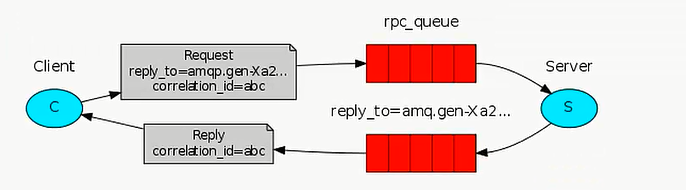
rpc server:
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.queue_declare(queue='rpc_queue')
def fib(n):
if n==0:
return 0
elif n==1:
return 1
else:
return fib(n-1)+fib(n-2) def on_request(ch,method,props,body):
n = int(body)
print("[.] fib(%s)" %n)
response = fib(n) ch.basic_publish(exchange='',routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id=props.correlation_id),
body = str(response))
ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(on_request,queue='rpc_queue') print("[x] Awaiting rpc requests")
channel.start_consuming()
rpc client:
import pika
import uuid,time
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response,#回调函数,只要一收到消息就调用
no_ack=True,queue=self.callback_queue) def on_response(self,ch,method,props,body):
if self.corr_id == props.correlation_id:
self.response = body def call(self,n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id
),
body=str(n),#传的消息,必须是字符串
)
while self.response is None:
self.connection.process_data_events()#非阻塞版的start_consuming
print("no message....")
time.sleep(0.5)
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print("[x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print("[.] Got %r"%response)
之前的start_consuming是进入一个阻塞模式,没有消息就等待消息,有消息就收过来
self.connection.process_data_events()是一个非阻塞版的start_consuming,就是说发了一个东西给客户端,每过一点时间去检查有没有消息,如果没有消息,可以去干别的事情
reply_to = self.callback_queue是用来接收反应队列的名字
corr_id = str(uuid.uuid4()),correlation_id第一在客户端会通过uuid4生成,第二在服务器端返回执行结果的时候也会传过来一个,所以说如果服务器端发过来的correlation_id与自己的id相同 ,那么服务器端发出来的结果就肯定是我刚刚客户端发过去的指令的执行结果。现在就一个服务器端一个客户端,无所谓缺人不确认。现在客户端是非阻塞版的,我们可以不让它打印没有消息,而是执行新的指令,这样就两条消息,不一定按顺序完成,那我们就需要去确认每个返回的结果是哪个命令的执行结果。
总体的模式是这样的:生产者发了一个命令给消费者,不知道客户端什么时候返回,还是要去收结果的,但是它又不想进入阻塞模式,想每过一段时间看这个消息收回来没有,如果消息收回来了,就代表收完了。
运行结果:
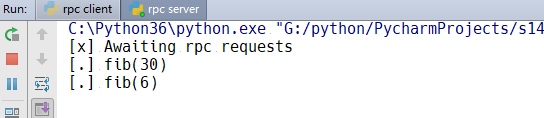
服务器端开启,然后在启动客户端,客户端先是等待消息的发送,然后做出反应,直到算出斐波那契
python学习之RabbitMQ-----消息队列的更多相关文章
- python学习之-- RabbitMQ 消息队列
记录:异步网络框架:twisted学习参考:www.cnblogs.com/alex3714/articles/5248247.html RabbitMQ 模块 <消息队列> 先说明:py ...
- Python并发编程-RabbitMQ消息队列
RabbitMQ队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
- 基于Python语言使用RabbitMQ消息队列(六)
远程过程调用(RPC) 在第二节里我们学会了如何使用工作队列在多个工人中分布时间消耗性任务. 但如果我们想要运行存在于远程计算机上的方法并等待返回结果该如何去做呢?这就不太一样了,这种模式就是常说的远 ...
- 基于Python语言使用RabbitMQ消息队列(三)
发布/订阅 前面的教程中我们已经创建了一个工作队列.在一个工作队列背后的假设是每个任务恰好会传递给一个工人.在这一部分里我们会做一些完全不同的东西——我们会发送消息给多个消费者.这就是所谓的“发布/订 ...
- 基于Python语言使用RabbitMQ消息队列(二)
工作队列 在第一节我们写了程序来向命名队列发送和接收消息 .在本节我们会创建一个工作队列(Work Queue)用来在多个工人(worker)中分发时间消耗型任务(time-consuming tas ...
- 基于Python语言使用RabbitMQ消息队列(一)
介绍 RabbitMQ 是一个消息中间人(broker): 它接收并且发送消息. 你可以把它想象成一个邮局: 当你把想要寄出的信放到邮筒里时, 你可以确定邮递员会把信件送到收信人那里. 在这个比喻中, ...
- 基于Python语言使用RabbitMQ消息队列(五)
Topics 在前面教程中我们改进了日志系统,相比较于使用fanout类型交易所只能傻瓜一样地广播,我们用direct获得了选择性接收日志的能力. 虽然使用direct类型交易所改进了我们的系统,但它 ...
- 基于Python语言使用RabbitMQ消息队列(四)
路由 在上一节我们构建了一个简单的日志系统.我们能够广播消息给很多接收者. 在本节我们将给它添加一些特性——我们让它只订阅所有消息的子集.例如,我们只把严重错误(critical error)导入到日 ...
- RabbitMQ 消息队列 应用
安装参考 详细介绍 学习参考 RabbitMQ 消息队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. M ...
- openresty 学习笔记番外篇:python访问RabbitMQ消息队列
openresty 学习笔记番外篇:python访问RabbitMQ消息队列 python使用pika扩展库操作RabbitMQ的流程梳理. 客户端连接到消息队列服务器,打开一个channel. 客户 ...
随机推荐
- 强大的dfs(用处1——拓扑排序【xdoj1025】,用处二——求强联通分量【ccf高速公路】)当然dfs用处多着咧
xdoj 1025 亮亮最近在玩一款叫做“梦想庄园”的经营游戏.在游戏中,你可以耕种,养羊甚至建造纺织厂. 如果你需要制造衣服,你首先得有布匹和毛线.布匹由棉花纺织而成:毛线由羊毛制成,而羊需要饲料才 ...
- PHP 7.0 升级备注
PHP 7.0.0 beta1 发布了,在带来了引人注目的性能提升的同时,也带来了不少语言特性方面的改变.以下由 LCTT 翻译自对官方的升级备注,虽然目前还不是正式发布版,不过想必距离正式发布的特性 ...
- 基于点线特征的Kinect2实时环境重建(Tracking and Mapping)
前言 个人理解错误的地方还请不吝赐教,转载请标明出处,内容如有改动更新,请看原博:http://www.cnblogs.com/hitcm/ 如有任何问题,feel free to contact m ...
- hasura graphql 集成pipelinedb测试
实际上因为pipelinedb 是原生支持pg的,所以应该不存在太大的问题,以下为测试 使用doker-compose 运行 配置 docker-compose 文件 version: '3.6' s ...
- ASP.NET vNext:微软下一代云环境Web开发框架
作者 郭蕾 发布于 2014年5月16日 在5月12日的TechED大会上,微软首次向外界介绍了下一代ASP.NET框架——ASP.NET vNext.ASP.NET vNext专门针对云环境和服 ...
- sql serve 创建序列
Oracle中有sequence的功能,SQL Server类似的功能使用Identity列实现,但是有很大的局限性. 在2012中,微软终于增加了 sequence 对象,功能和性能都有了很大的提高 ...
- pow 的使用和常见问题
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/menxu_work/article/details/24540045 1.安装: $ curl ge ...
- 罗技 M558 鼠标维修记录
罗技 M558 鼠标维修记录 故障现象 按键不灵敏 拆机内部图 前进键 后退键 左键 右键 中键 自定义功能键 使用的是 OMRON 按键,好东西,质量可以. 但毕竟是机械的东西,还是有老化,用万用表 ...
- python之 数据类型判定与类型转换
一. 判断数据类型 0.type(x)type()可以接收任何东西作为参数――并返回它的数据类型.整型.字符串.列表.字典.元组.函数.类.模块,甚至类型对象都可以作为参数被 type 函数接受. & ...
- vuex、redux、mobx 对比
出处:https://www.w3cplus.com/javascript/talk-about-front-end-state-management.html 其实大部分概念都差不多,只不过VUEX ...