常用增强学习实验环境 II (ViZDoom, Roboschool, TensorFlow Agents, ELF, Coach等) (转载)
原文链接:http://blog.csdn.net/jinzhuojun/article/details/78508203
前段时间Nature上发表的升级版Alpha Go - AlphaGo Zero再一次成为热点话题。作为其核心技术之一的Deep reinforcement learning(深度增强学习,或深度强化学习)也再一次引发关注。Alpha Zero最有意义的地方之一是它去除了从人类经验(棋谱)中学习的过程,而是完全通过“左右互博”式的学习击败了自己的“前辈”。这也很能体现强化学习的特点,就是在弱监督信息下通过”Trial and error”来自我学习。
这两年DRL随着深度学习的大热也是火得不行。于是各种新的强化学习研究平台如雨后春芛冒出来,而且趋势也是从简单的toy场景慢慢扩展到3D迷宫,第一人称射击游戏,即时策略类游戏和复杂机器人控制场景等。之前曾写文介绍了一些流行的强化学习实验环境(常用强化学习实验环境 I (MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2))。本文是第二弹。 ps: 真羡慕现在研究强化学习的孩子,各种五花八门的实验环境,算法参考实现也可以随便挑。。。
在第一篇中介绍过的本文就不重复累述了,这里把本文涉及的项目大致分为两类:
1. 实验场景类: 像OpenAI Gym,MuJoCo这些。
| 名称 | github链接 | 类型 | 语言 | 平台 | 官方介绍 |
|---|
| ViZDoom | 代码 | FPS | C++, Lua, Java, Python | Linux,Windows,Mac OS |
| Roboschool | 代码 | Physical simulation | Python | Linux, Mac OS |
| Multi-Agent Particle Environment | 代码 | Multi-agent | Python | Linux |
2. 研究框架类: 一般会整合多个实验场景并提供方便统一的接口,方便其它场景的接入,并提供一些高级功能(如并行化),同时可能附带一些算法参考实现。
| 名称 | github链接 | 场景 | 语言 | 实现算法 | 相关机构 |
官方介绍 |
|---|---|---|---|---|---|---|
| TensorFlow Models | 代码 |
OpenAI Gym, MuJoCo |
Python |
Actor Critic,TRPO, PCL,Unified PCL, Trust-PCL, PCL + Constraint Trust Region, REINFORCE,UREX |
Community |
N/A |
| TensorFlow Agents | 代码 | OpenAI Gym | Python | BatchPPO | 论文 | |
|
Universe/ universe-starter-agent |
Atari, CarPole, Flashgames, Browser task, etc. |
Python | A3C | OpenAI | 博客 | |
|
ELF |
MiniRTS, Atari, Go |
Python | PG, AC | |||
|
Coach |
OpenAI Gym, ViZDoom, Roboschool, GymExtensions, PyBullet |
Python |
DQN, DDQN, Dueling Q Network, MMC, PAL, Distributional DQN, Bootstrapped DQN, NEC Distributed: N-Step Q Learning, NAF, PG, A3C, DDPG, PPO, Clipped PPO, DFP |
Intel | ||
|
Unity Machine Learning Agents |
3D Balance Ball, GridWorld |
Python |
PPO |
Unity |
下面介绍下它们的环境搭建。基础环境Ubuntu 16.04,Cuda 8.0(cuDNN 6.0),TensorFlow 1.2.1,Anaconda 4.4.0, Python 2.7/3.5。
ViZDoom
提供了用AI玩毁灭战士游戏的环境。主要用于机器学习研究,尤其是DRL算法研究。环境搭建可以参见官方文档:https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md
依赖中其它还好,比较麻烦的是需要Torch 7 。安装方法参考Getting started with Torch。
安装过程中会下载freedoom-0.11.3.zip,但我这网速渣下载非常慢,可以先从http://freedoom.github.io/download.html上下好放在项目的根目录 。如果你网速快请忽略。
安装完成后运行examples/python/basic.py,会起一个图形界面,其中智能体(agent)采取的动作是随机的。
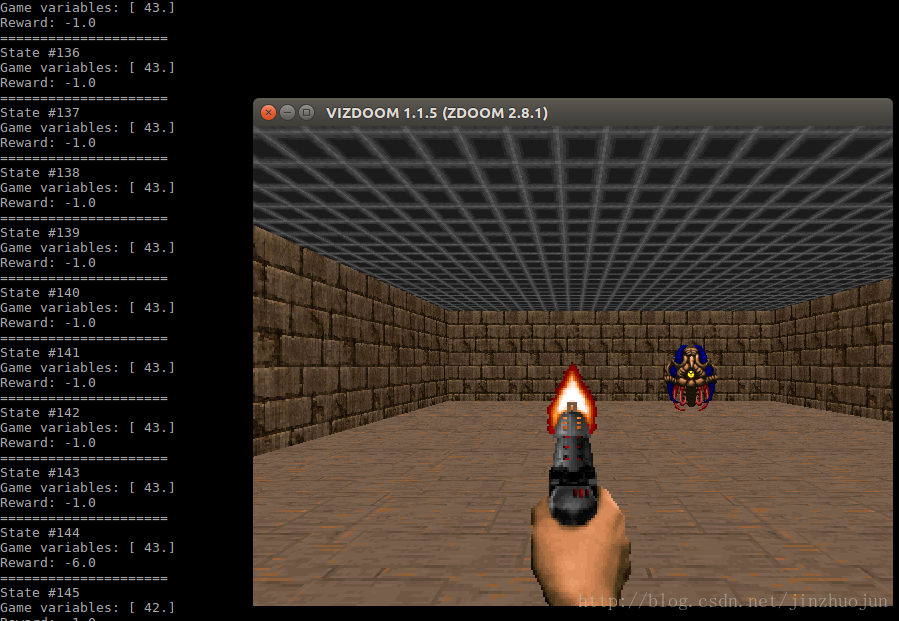
它还用多种语言实现了DQN算法,位于examples目录下。
Roboschool
MuJoCo在许多的DRL论文中被用于经典的控制场景实验。但它有个缺点是要钱(除了30天免费版及学生版)。而这个缺点对于我们穷人来说可以说是致命的。作为MuJoCo实现的替代品,OpenAI开发了基于Bullet物理引擎的Roboschool。它提供了OpenAI Gym形式的接口用于模拟机器人控制。目前包含了12个环境。其中除了传统的类似MuJoCo的场景,还有交互控制,及多智能体控制场景。
安装方法比较简单,基本按github上readme即可。比如运行下面例子:
python $ROBOSCHOOL_PATH/agent_zoo/demo_race2.py- 后的效果:
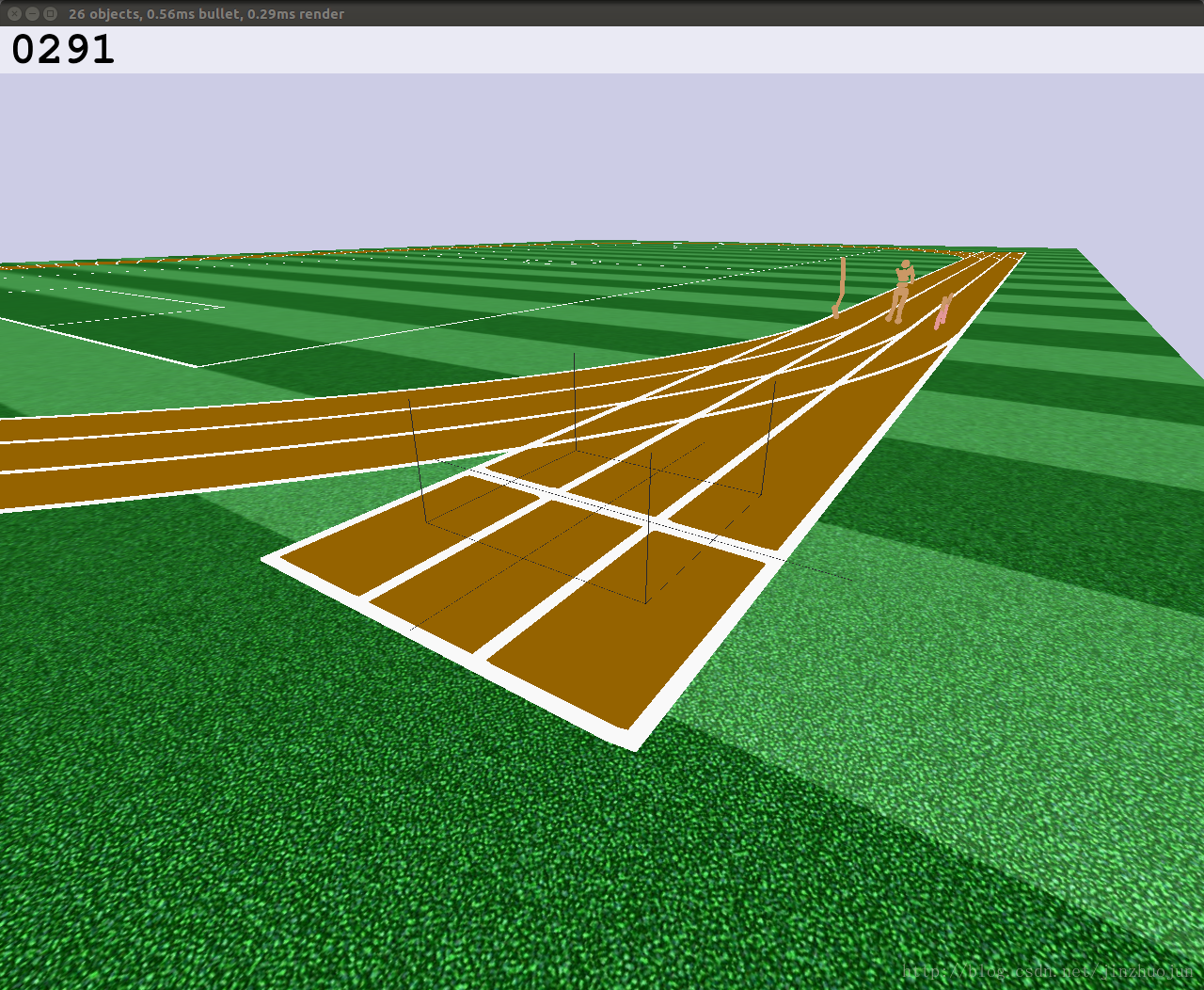
- 如果你不幸遇到下面的问题:
jzj@jlocal:~/source/roboschool$ python $ROBOSCHOOL_PATH/agent_zoo/RoboschoolHumanoidFlagrun_v0_2017may.py [2017-10-28 21:56:26,100] Making new env: RoboschoolHumanoidFlagrun-v1 QGLShaderProgram: could not create shader program bool QGLShaderPrivate::create(): Could not create shader of type 2. python3: render-simple.cpp:250: void SimpleRender::Context::initGL(): Assertion `r0' failed.
Aborted (core dumped)
根据https://github.com/openai/roboschool/issues/15中描述是一个已知bug,有个WR是在脚本前面加上from OpenGL import GLU。
Multi-Agent Particle Environment
多智能体粒子世界。主要用于多智能体场景下的DRL相关研究。项目不大,依赖也比较简单,基本只要OpenAI gym。安装方法:
pip3 install -e . --user
然后就可以运行了:
bin/interactive.py --scenario <env>
其中<env>在其readme中有列。比如:
bin/interactive.py --scenario simple_push.py

TensorFlow Models
这是TensorFlow models中提供的强化学习算法集。环境搭建比较简单,如果已经装了OpenAI Gym和MuJoCo,基本装完了TensorFlow就可以跑。建议拿python 2.7跑,拿3.x要改些东西,比较麻烦。
装完后跑个readme中的例子试下:
- python trainer.py --logtostderr --batch_size= --env=DuplicatedInput-v0 \ --validation_frequency= --tau=0.1 --clip_norm= \ --num_samples= --objective=urex
看到下面这样的输出就是在训练了:
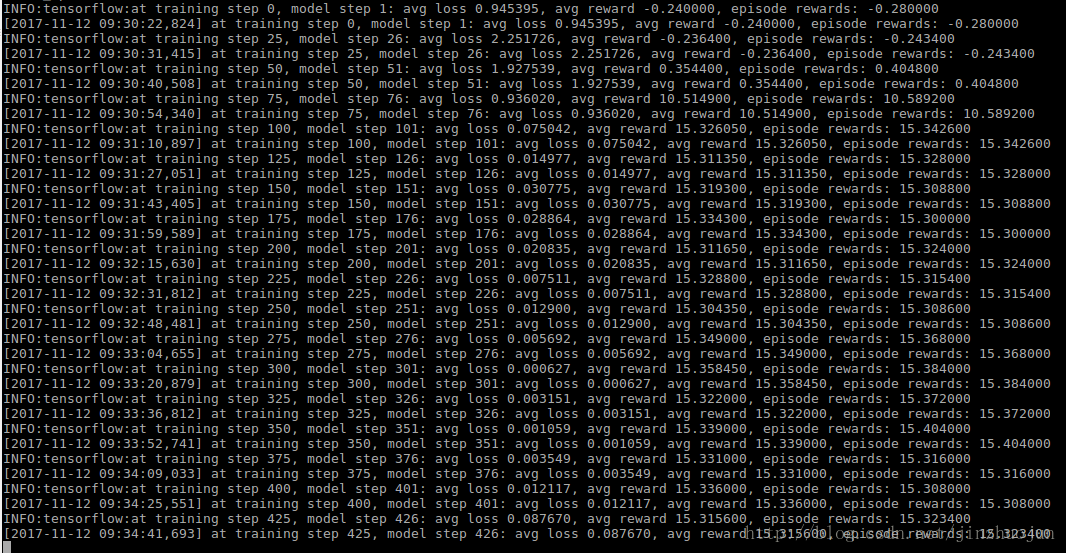
TensorFlow Agents
由Google两位研究员研发,用于在TensorFlow中构建并行强化学习算法。比较大的特点是容易开发并行强化学习算法。除了TensorFlow和OpenAI Gym,还需要安装ruamel.yaml:
pip install ruamel.yaml
按readme可以运行下例子:
- $ python3 -m agents.scripts.train --logdir=./log --config=pendulum
- $ tensorboard --logdir=./ --port=
利用TensorFlow的tensorboard可以看到训练过程数据的图形化显示:
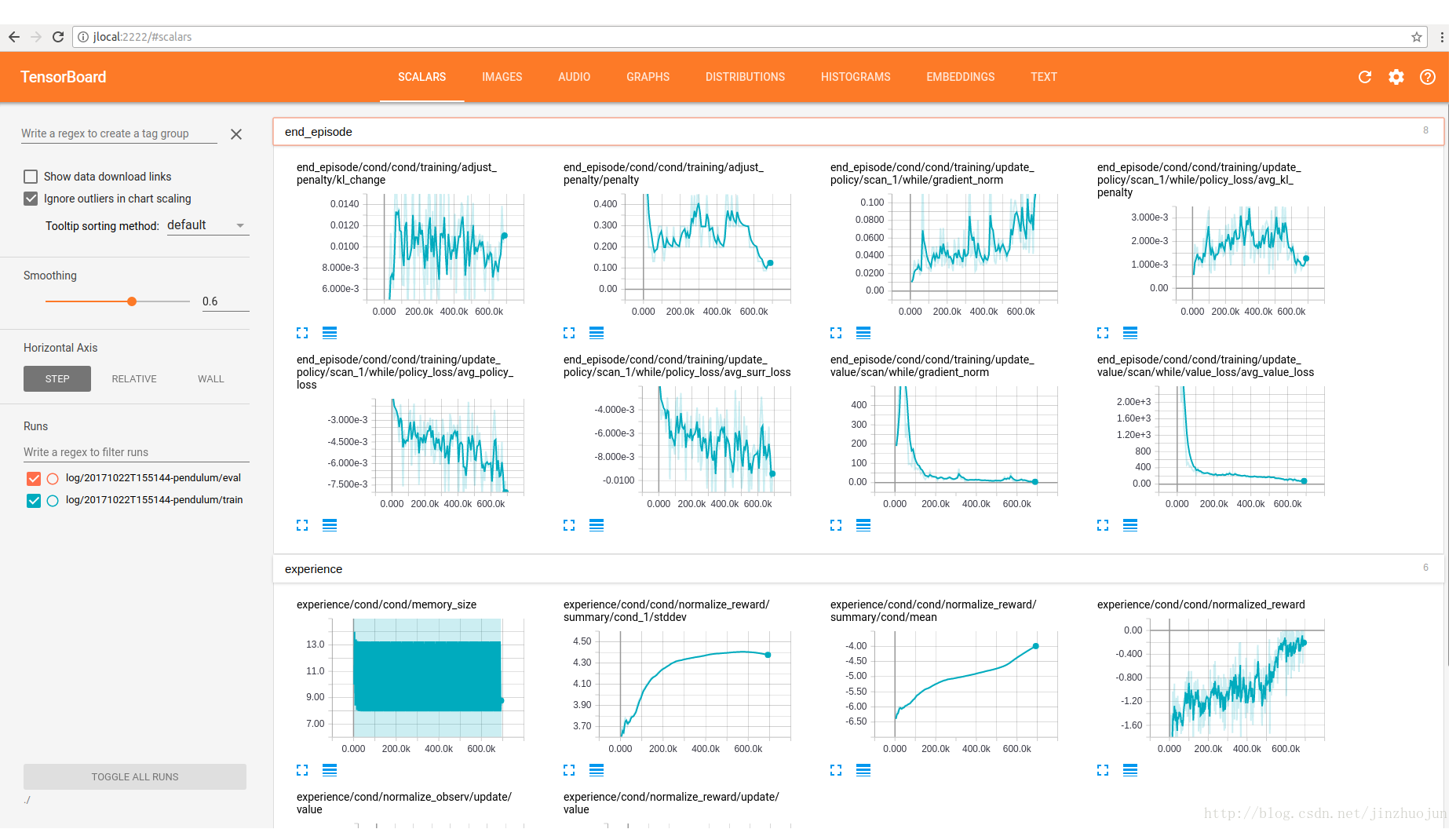
Universe
OpenAI出品,用于衡量和训练游戏中的AI的软件平台。特点之一是可以让一个现有的程序变为OpenAI Gym环境,而且不用改动程序的内部代码和API。它将程序封装成docker容器,然后以人类的使用接口(键盘鼠标,屏幕输出)提供给AI学习模块。目前已经包含了1000+环境 。
该框架可以运行在Linux和OSX上,支持Python 2.7和3.5。官方readme里说内部用的3.5,所以python 3.5的支持应该会好些。注意它会用到docker(比如那些游戏会run在container中,然后通过VNC显示),所以需要先安装docker。docker安装可参见:
https://docs.docker.com/engine/installation/linux/docker-ce/ubuntu/
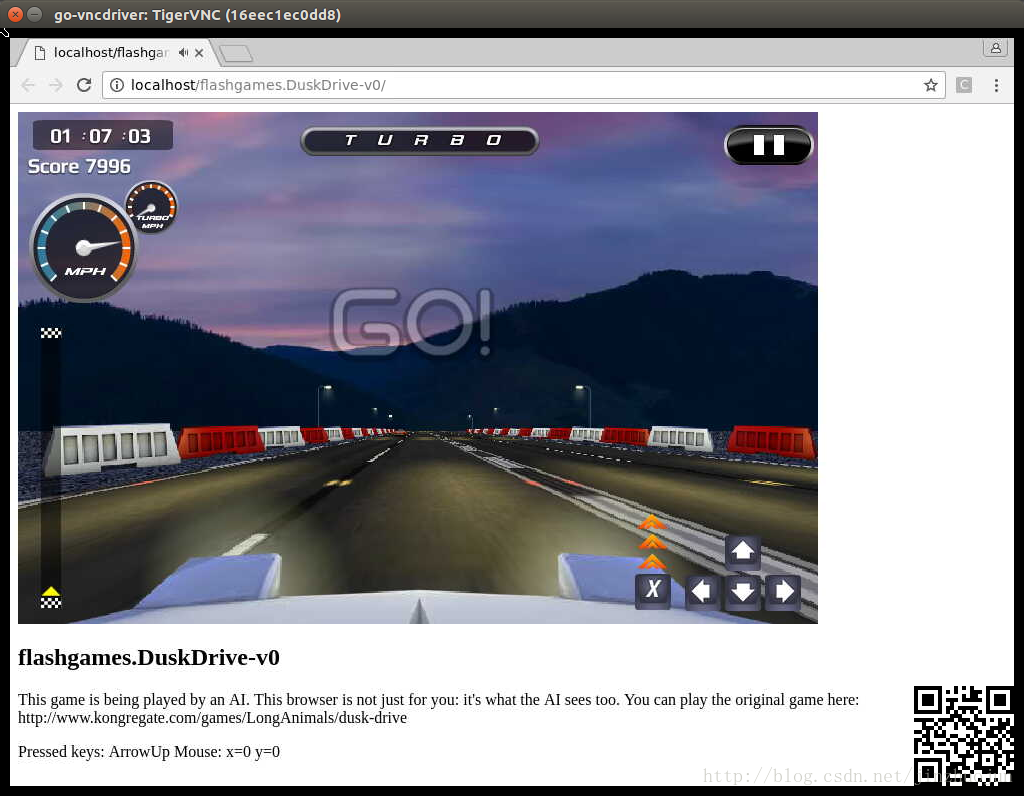
另外universe-starter-agent项目实现了一个用于universe环境中的agent,包含了A3C算法的实现。
ELF
其特点如其名字,可扩展(Extensive),轻量(Lightweight)和灵活(Flexible)。它特点之一是可以让多个游戏实例并行执行。另外任何C++接口的游戏都可以通过wrapper接入到该框架中。目前支持MiniRTS(一个简化版即时策略游戏)及其扩展、Atari和围棋。引擎部分用C++部分实现,接口为python。
环境搭建只要运行readme中的install脚本即可。此外注意还需要用到tbb(Intel的并行编程库):
sudo apt-get install libtbb-dev
比较特殊的是需要依赖PyTorch。可能由于我的网络非常之渣,用conda命令安装非常之慢:
conda install pytorch cuda80 -c soumith
建议你也可以选择在http://pytorch.org/上选择你的环境和想要的安装方式,比如:
pip3 install http://download.pytorch.org/whl/cu80/torch-0.2.0.post3-cp35-cp35m-manylinux1_x86_64.whlpip3 install torchvision
安装完后,根据readme,可以运行下几个例子试下:
sh ./train_minirts.sh --gpu 0 # 训练MiniRTS
训练过程很吃资源,其它事就别干了,换台电脑或者去喝杯咖啡吧。训练过程产生的模型文件会存为save-xxx.bin的形式。假设为save-2245.bin。然后可以用下面的脚本做模型的evaluation:
sh eval_minirts.sh ./save-2245.bin 20
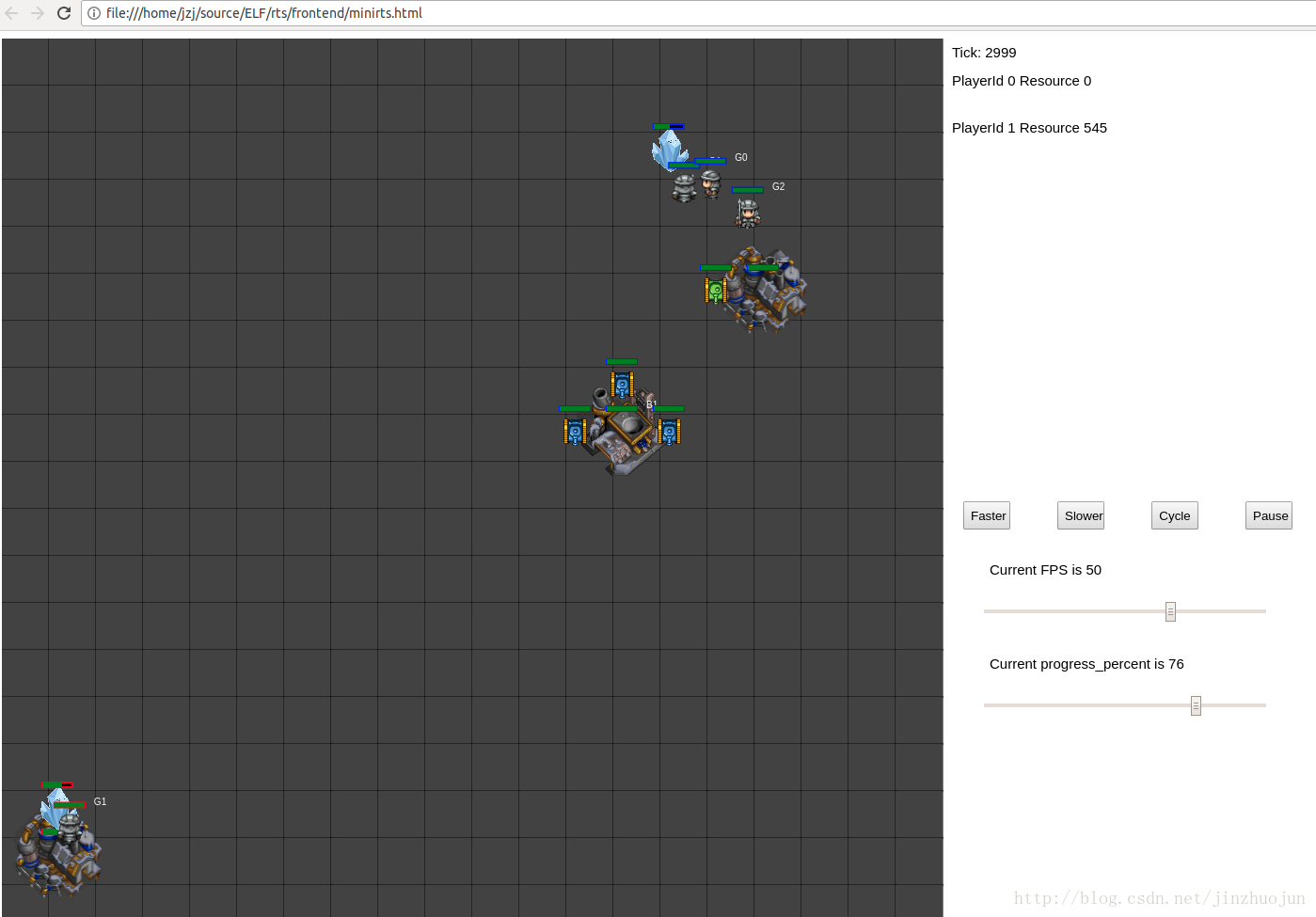
如果要进行self-play(机器人自己和自己玩)可以执行下面的脚本:
sh ./selfplay_minirts.sh ./save-2245.bin
如果在运行eval或者self-play脚本时加上参数–save_replay_prefix replay,会生成一坨replayXXX-X.rep的重放文件。它们类似于以前玩的星际或者帝国中存档文件,可以用于重放。
下面是运行中可能碰到的问题及可以一试的解决方法:
Q: RuntimeError: cuda runtime error (10) : invalid device ordinal at torch/csrc/cuda/Module.cpp:87
A:这是因为selfplay_minirts.sh中默认整了多块GPU(–gpu 2)。我只有一块,改为–gpu 0即可。
Q: 在执行eval_minirts.sh时出错错误:
ValueError: Batch[actor1-5].copy_from: Reply[V] is not assigned
A: 在eval_minirts.sh中加参数–keys_in_reply V
Coach
由Intel收购的Nervana公司推出。该公司主要产品 是深度学习框架neon(不是arm上并行指令那个。。。)。Coach是一个基于Python语言的强化学习研究框架,并且包含了许多先进算法实现。该框架基于OpenAI Gym。其特色之一是可以方便地实现并行算法,充分利用CPU多核。另外有图形化工具可以方便地看训练过程中各项指标的曲线。它支持双后端,一个是当前大热的TensorFlow,一个是Intel自家的neon。该项目结合了Intel优化版本的TensorFlow和自家的神经网络加速库mkl-dnn,相信高性能是它的一个目标。
该框架要求Python 3.5。首先运行自带安装脚本:
./install.sh
这个脚本会让输入一系列选项,其中如果选了要安装neon的话会去下mkl-dnn的库,我这下载巨慢。因为这是其中backend之一,不是必选的,因此如果网络和我一样渣的可以选择不装这个。
装完后可以运行几个例子:
python3 coach.py -p CartPole_DQN -r
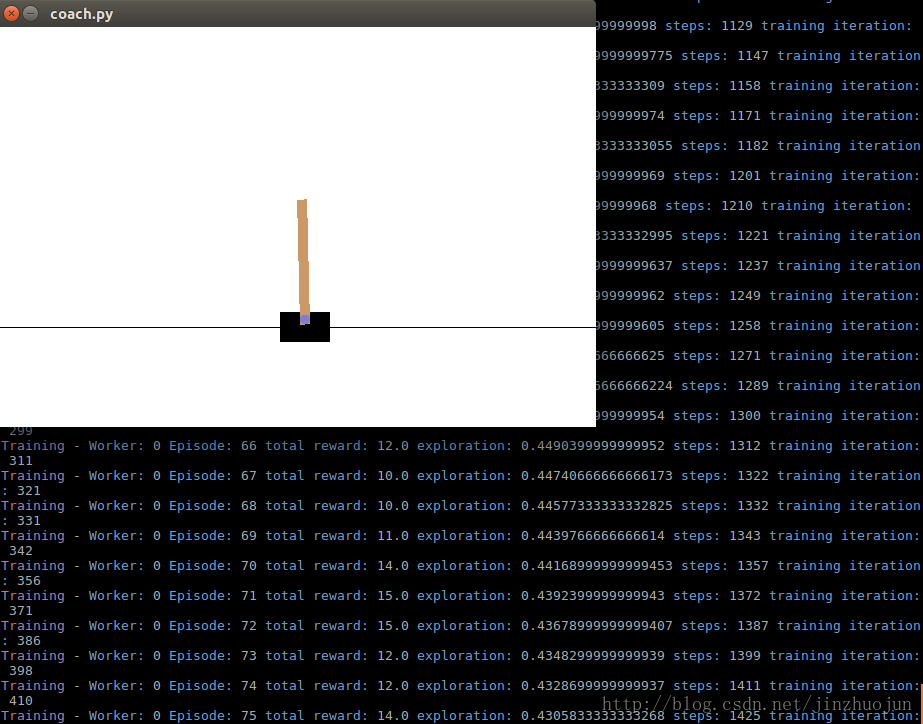
python3 coach.py -r -p Pendulum_ClippedPPO -n 8
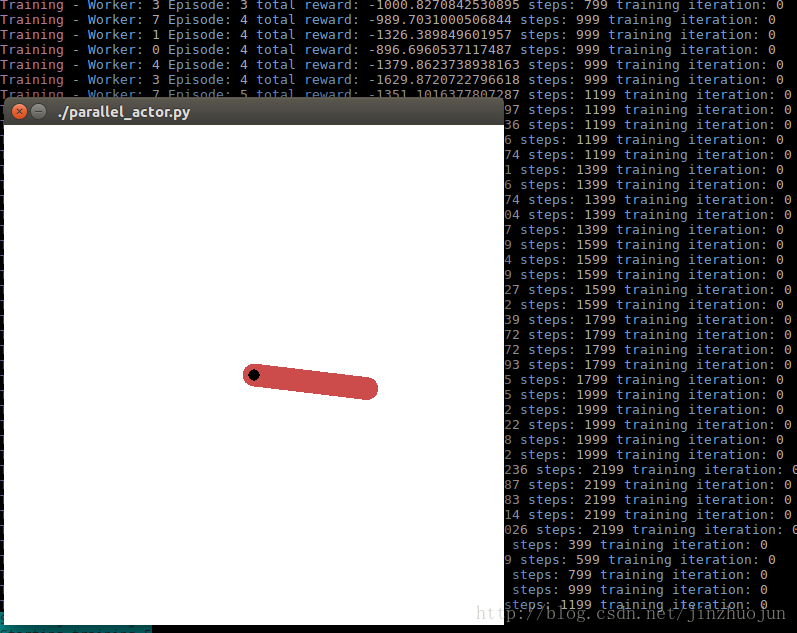
python3 coach.py -r -p MountainCar_A3C -n 8
然后可以通过下面的脚本将训练过程图形化:
python3 dashboard.py
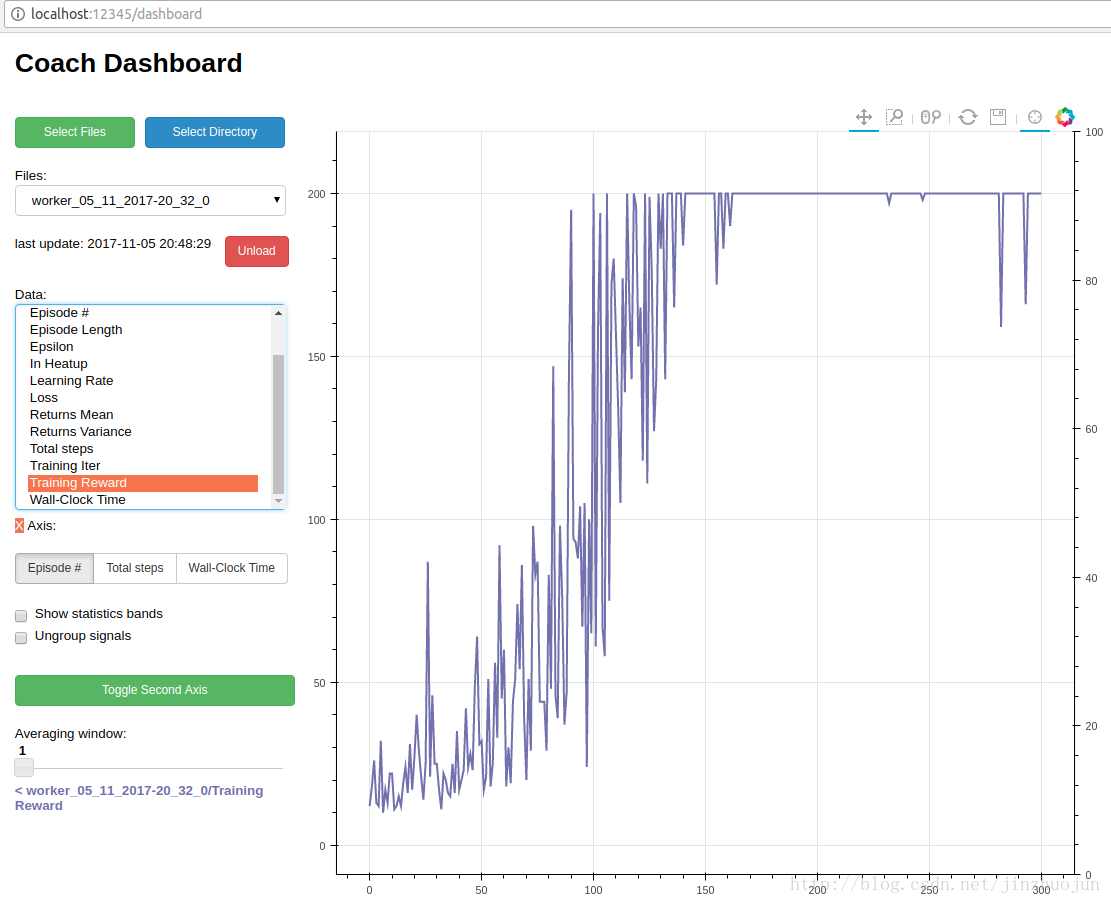
{kind=link}
如果过程中发现少annoy模块,可以用下面命令安装下。
Q:ModuleNotFoundError: No module named ‘annoy’
A:pip3 install annoy
Unity Machine Learning Agents
大名鼎鼎的Unity公司出的。手机上的游戏很多就是基于Unity 3D引擎的。这次推出强化学习框架,它主打的是实验环境。亮点是可以结合Unity Editor来创建自定义的强化学习实验场景(详见
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Making-a-new-Unity-Environment.md)。可能也是看准了现在游戏中越来越多用到AI的趋势。它主要特点是可以支持多个观察输入,多智能体支持,并行环境计算等 。python 2和3都支持。目前支持的场景有3D Balance Ball,GridWorld
和Tennis(https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Example-Environments.md)。
算法部分就实现了PPO。因为主打是实验场景框架,算法意思一下就行。
因为我的工作环境基本都是Linux下的,而这个框架依赖的Unity SDK只支持Windows和Mac OS X。木有钱买水果,也实在打不起精神在Windows下搭环境,所以这个平台我没试过。大家有兴趣可以搭起来玩下。各种DRL的论文里都是Gym, MuJoCo,Torcs,DeepMind Lab这些,要是整些这个项目里的几个场景上去,或者自定义个场景,应该也挺让人新鲜的。
常用增强学习实验环境 II (ViZDoom, Roboschool, TensorFlow Agents, ELF, Coach等) (转载)的更多相关文章
- 常用增强学习实验环境 I (MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2) (转载)
原文地址:http://blog.csdn.net/jinzhuojun/article/details/77144590 和其它的机器学习方向一样,强化学习(Reinforcement Learni ...
- Ubuntu下常用强化学习实验环境搭建(MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
http://lib.csdn.net/article/aimachinelearning/68113 原文地址:http://blog.csdn.net/jinzhuojun/article/det ...
- 【MySQL】MySQL无基础学习和入门之一:数据库基础概述和实验环境搭建
数据库基础概述 大部分互联网公司都选择MySQL作为业务数据存储数据库,除了MySQL目前还有很多公司使用Oracle(甲骨文).SQLserver(微软).MongoDB等. 从使用成本来区分可以 ...
- 包含深度学习常用框架的Docker环境
相关的代码都在Github上,请参见我的Github,https://github.com/lijingpeng/deep-learning-notes 敬请多多关注哈~~~ All in one d ...
- 常用深度学习框——Caffe/ TensorFlow / Keras/ PyTorch/MXNet
常用深度学习框--Caffe/ TensorFlow / Keras/ PyTorch/MXNet 一.概述 近几年来,深度学习的研究和应用的热潮持续高涨,各种开源深度学习框架层出不穷,包括Tenso ...
- 马里奥AI实现方式探索 ——神经网络+增强学习
[TOC] 马里奥AI实现方式探索 --神经网络+增强学习 儿时我们都曾有过一个经典游戏的体验,就是马里奥(顶蘑菇^v^),这次里约奥运会闭幕式,日本作为2020年东京奥运会的东道主,安倍最后也已经典 ...
- 增强学习 | Q-Learning
"价值不是由一次成功决定的,而是在长期的进取中体现" 上文介绍了描述能力更强的多臂赌博机模型,即通过多台机器的方式对环境变量建模,选择动作策略时考虑时序累积奖赏的影响.虽然多臂赌博 ...
- Nginx配置多个基于域名的虚拟主机+实验环境搭建+测试
标签:Linux 域名 Nginx 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://xpleaf.blog.51cto.com/9 ...
- 增强学习(三)----- MDP的动态规划解法
上一篇我们已经说到了,增强学习的目的就是求解马尔可夫决策过程(MDP)的最优策略,使其在任意初始状态下,都能获得最大的Vπ值.(本文不考虑非马尔可夫环境和不完全可观测马尔可夫决策过程(POMDP)中的 ...
随机推荐
- Linux 常用的压缩命令有 gzip 和 zip
Linux 常用的压缩命令有 gzip 和 zip,两种压缩包的结尾不同:zip 压缩的后文件是 *.zip ,而 gzip 压缩后的文件 *.gz 相应的解压缩命令则是 gunzip 和 unzip ...
- grep -v grep
ps -ef|grep /usr/local/tomcat_coachqa/ |grep -v grep |awk '{print $2}'|xargs kill -9 grep -v grep gr ...
- Java 密码扩展无限制权限策略文件[转]
因为某些国家的进口管制限制,Java发布的运行环境包中的加解密有一定的限制.比如默认不允许256位密钥的AES加解密,解决方法就是修改策略文件. 官方网站提供了JCE无限制权限策略文件的下载: JDK ...
- Shell需注意的语法问题
1.文件头声明别漏掉#和! #!/bin/bash 2.赋值语句①=号两端不能有空格(判断语句=号两端必须有空格)②使用变量必须使用符号$ var1=valecho $var1 3.if语句写错下面任 ...
- URAL 2072 Kirill the Gardener 3
URAL 2072 思路: dp+离散化 由于湿度的范围很大,所以将湿度离散化 可以证明,先到一种湿度的最左端或者最右端,然后结束于最右端或最左端最优,因为如果结束于中间,肯定有重复走的路 状态:dp ...
- 我理解的NODE
简介:NODE不是我们想象中的后台语言,它不是一门语言,它是一个和浏览器类似的工具或者平台,在NODE平台中,可以把我们写的JS代码解析出来,而且NODE和谷歌浏览器一样都是采用V8引擎渲染解析的. ...
- Educational Codeforces Round 57题解
A.Find Divisible 沙比题 显然l和2*l可以直接满足条件. 代码 #include<iostream> #include<cctype> #include< ...
- Java中HashMap的实现原理
最近面试中被问及Java中HashMap的原理,瞬间无言以对,因此痛定思痛觉得研究一番. 一.Java中的hashCode和equals 1.关于hashCode hashCode的存在主要是用于查找 ...
- python-day47--mysql数据备份与恢复
一.IDE工具介绍 掌握: #1. 测试+链接数据库 #2. 新建库 #3. 新建表,新增字段+类型+约束 #4. 设计表:外键 #5. 新建查询 #6. 备份库/表 #注意: 批量加注释:ctrl+ ...
- python-day46--前端基础之html
一.html是什么? 超文本标记语言(Hypertext Markup Language,HTML)通过标签语言来标记要显示的网页中的各个部分.一套规则,浏览器认识的规则 浏览器按顺序渲染网页文件,然 ...