HA 高可用mysql集群
注意问题:
1.保持mysql用户和组的ID号是一致的;
2.filesystem 共享存储必须要有写入权限;
3.删除资源必须先删除约束,在删除资源;
1.安装数据库,这里使用maridb数据库;
node1节点配置:
tar -xf maridb-xx.tar.gz -C /usr/local
ln -sv maridb-xx mysql
cd /usr/local/mysql
初始化数据库,第二台node2不需要在进行初始化直接copy相关配置文件即可
2.配置filesystem NFS共享存储;
新建一个文件夹,挂着磁盘为ext4格式的盘到mydata,此盘应该创建为lvm分区进行挂载;
vim /etc/exports
/mydata 192.168.254.0/24(rw,no_root_squash)
3.新建资源如下:
myip设置ip为192.168.254.21
mystore设置filesystem磁盘挂载路径为 目标挂载:192.168.254.188:/mydata 本地挂着路径:/mydata 使用的服务是:nfs

此时启动myservices进行验证,查看node2节点是否启动mysql端口3306如下:(已经启动)

4.给node1的mysql授权一个用户拥有root权限的用户,然后使用192.168.254.21集群地址登陆效果;如下
MariaDB [(none)]> GRANT ALL ON *.* TO 'root'@'192.168.254.%' IDENTIFIED BY 'izyno';
MariaDB [(none)]> flush privileges
然后在其他装有mysql客户端的机器进行验证如下:
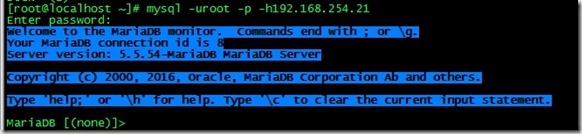
5.进行HA集群切换;
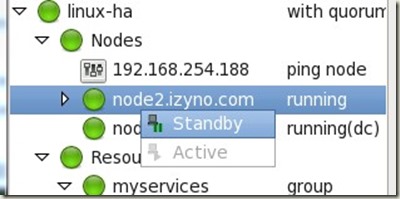
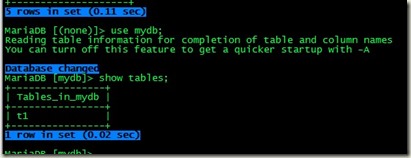
然后在我们已经登陆的客户端查看,我们的登陆还是在线,没有推出:
HA 高可用mysql集群的更多相关文章
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- 高可用mysql集群搭建
对web系统来说,瓶颈大多在数据库和磁盘IO上面,而不是服务器的计算能力.对于系统伸缩性我们一般有2种解决方案,scale-up(纵向扩展)和scale-out(横向扩展).前者如扩内存,增加单机性能 ...
- hadoop3.1.1 HA高可用分布式集群安装部署
1.环境介绍 涉及到软件下载地址:https://pan.baidu.com/s/1hpcXUSJe85EsU9ara48MsQ 服务器:CentOS 6.8 其中:2 台 namenode.3 台 ...
- Haproxy Mysql cluster 高可用Mysql集群
-----client-----------haproxy---------mysql1----------mysql2------192.168.1.250 192.168.1.1 192.168. ...
- docker swarm使用keepalived+haproxy搭建基于percona-xtradb-cluster方案的高可用mysql集群
一.部署环境 序号 hostname ip 备注 1 manager107 10.0.3.107 centos7;3.10.0-957.1.3.el7.x86_64 2 worker68 10.0.3 ...
- Redis高可用复制集群实现
redis简单介绍 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库.Redis 与其他 key - value 缓存产品有以下三个特点: 支持数据的持久化,可以将 ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
- [转]搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- 搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
随机推荐
- 快速切题 poj3026
感受到出题人深深的~恶意 这提醒人们以后...数字后面要用gets~不要getchar 此外..不要相信那个100? Borg Maze Time Limit: 1000MS Memory Lim ...
- .net大型分布式电子商务架构说明
背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 架构演变 基础框架剥 ...
- 跟我一起学习ASP.NET 4.5 MVC4.0(三)
今天我们继续ASP.NET 4.5 MVC 4.0,前两天熟悉了MVC4.0在VS11和win8下的更新,以及MVC中的基础语法和几个关键字的使用.了解了这些就可以对MVC进一步认识,相信很多人都对M ...
- 1011 A+B 和 C
给定区间 [-2^31, 2^31] 内的 3 个整数 A.B 和 C,请判断 A+B 是否大于 C. 输入格式: 输入第 1 行给出正整数 T (≤10),是测试用例的个数.随后给出 T 组测试用 ...
- SharePoint 2010 Ribbon with wrong style in Chrome and Safari
When we add custom ribbon to SharePoint 2010, it may display well in IE but not in Chrome and Safari ...
- iOS项目实现SVN代码管理方法③(Part 三)
内容中包含 base64string 图片造成字符过多,拒绝显示
- H - 【59】Lazier Salesgirl 模拟//lxm
Kochiya Sanae is a lazy girl who makes and sells bread. She is an expert at bread making and selling ...
- HDU 1853
http://acm.hdu.edu.cn/showproblem.php?pid=1853 和下题一模一样,求一个图环的并,此题的题干说的非常之裸露 http://www.cnblogs.com/x ...
- 安装python第三方库
前言 接触python编程很晚,基础语法比较好理解,但是用起来还是需要用心的,特别是可能会用到许多第三方库,本文就介绍一下python第三方库的安装. 环境 系统环境:win7_64; Python版 ...
- CF1096:D. Easy Problem(DP)
Vasya is preparing a contest, and now he has written a statement for an easy problem. The statement ...