第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
bool查询说明
filter:[],字段的过滤,不参与打分
must:[],如果有多个查询,都必须满足【并且】
should:[],如果有多个查询,满足一个或者多个都匹配【或者】
must_not:[],相反查询词一个都不满足的就匹配【取反,非】
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#}
建立测试数据
#建立测试数据
POST jobbole/job/_bulk
{"index":{"_id":1}}
{"salary":10,"title":"python"}
{"index":{"_id":2}}
{"salary":20,"title":"Scrapy"}
{"index":{"_id":3}}
{"salary":30,"title":"Django"}
{"index":{"_id":4}}
{"salary":40,"title":"Elasticsearch"}
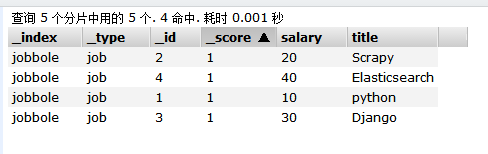
bool组合查询——最简单的filter过滤查询之term查询,相当于等于
过滤查询到salary字段等于20的数据
可以看出执行两个两个步骤,先查到所有数据,然后在查到的所有数据过滤查询到salary字段等于20的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足
# "should":[], 如果有多个查询,满足一个或者多个都匹配
# "must_not":[], 相反查询词一个都不满足的就匹配
#} #简单过滤查询
#最简单的filter过滤查询
#如果我们要查salary字段等于20的数据
GET jobbole/job/_search
{
"query": {
"bool": { #bool组合查询
"must":{ #如果有多个查询词,都必须满足
"match_all":{} #查询所有字段
},
"filter": { #filter过滤
"term": { #term查询,不会将我们的搜索词进行分词,将搜索词完全匹配的查询
"salary": 20 #查询salary字段值为20
}
}
}
}
} #简单过滤查询
#最简单的filter过滤查询
#如果我们要查salary字段等于20的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"must":{
"match_all":{}
},
"filter": {
"term": {
"salary": 20
}
}
}
}
}

bool组合查询——最简单的filter过滤查询之terms查询,相当于或
过滤查询到salary字段等于10或20的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足
# "should":[], 如果有多个查询,满足一个或者多个都匹配
# "must_not":[], 相反查询词一个都不满足的就匹配
#} #简单过滤查询
#最简单的filter过滤查询
#如果我们要查salary字段等于20的数据
#过滤salary字段值为10或者20的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"must":{
"match_all":{}
},
"filter": {
"terms": {
"salary":[10,20]
}
}
}
}
}
注意:filter过滤里也可以用其他基本查询的
_analyze测试查看分词器解析的结果
analyzer设置分词器类型ik_max_word精细化分词,ik_smart非精细化分词
text设置词
#_analyze测试查看分词器解析的结果
#analyzer设置分词器类型ik_max_word精细化分词,ik_smart非精细化分词
#text设置词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "Python网络开发工程师"
} GET _analyze
{
"analyzer": "ik_smart",
"text": "Python网络开发工程师"
}

bool组合查询——组合复杂查询1
查询salary字段等于20或者title字段等于python、salary字段不等于30、并且salary字段不等于10的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} # 查询salary字段等于20或者title字段等于python、salary字段不等于30、并且salary字段不等于10的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"should": [
{"term":{"salary":20}},
{"term":{"title":"python"}}
],
"must_not": [
{"term": {"salary":30}},
{"term": {"salary":10}}]
}
}
}
bool组合查询——组合复杂查询2
查询salary字段等于20或者title字段等于python、salary字段不等于30、并且salary字段不等于10的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} # 查询title字段等于python、或者、(title字段等于elasticsearch并且salary等于30)的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"should":[
{"term":{"title":"python"}},
{"bool": {
"must": [
{"term": {"title":"elasticsearch"}},
{"term":{"salary":30}}
]
}}
]
}
}
}
bool组合查询——过滤空和非空
#建立数据
POST bbole/jo/_bulk
{"index":{"_id":""}}
{"tags":["search"]}
{"index":{"_id":""}}
{"tags":["search","python"]}
{"index":{"_id":""}}
{"other_field":["some data"]}
{"index":{"_id":""}}
{"tags":null}
{"index":{"_id":""}}
{"tags":["search",null]}
处理null空值的方法
获取tags字段,值不为空并且值不为null的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} #处理null空值的方法
#获取tags字段,值不为空并且值不为null的数据
GET bbole/jo/_search
{
"query": {
"bool": {
"filter": {
"exists": {
"field": "tags"
}
}
}
}
}
获取tags字段值为空或者为null的数据,如果数据没有tags字段也会获取
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} #获取tags字段值为空或者为null的数据,如果数据没有tags字段也会获取
GET bbole/jo/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "tags"
}
}
}
}
}
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询的更多相关文章
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
随机推荐
- iOS-图片浏览器
// // ViewController.m // 19-图片浏览器 // // Created by hongqiangli on 2017/7/31. // Copyright © 201 ...
- Ubuntu 16.04 64位安装arm-linux-gcc交叉编译器以及samba服务器
交叉编译器是嵌入式开发的必要工具,但是由于目前大多数人使用64位ubuntu,在照着很多教程做的时候,就会失败,失败原因是64位ubuntu需要额外安装32位的兼容包.以arm-linux-gcc-3 ...
- hdu1102(最小生成树水题)
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> us ...
- Android实例-调用GOOGLE的TTS实现文字转语音(XE7+小米2)(XE10.1+小米5)
相关资料: 注意:在手机上必须选安装文字转语音引擎“google Text To Speech”地址:http://www.shouji56.com/soft/GoogleWenZiZhuanYuYi ...
- C#学习笔记(11)——深入事件,热水器案例
说明(2017-6-14 15:04:13): 1. 热水器案例,为了便于理解,采用了蹩脚但直观的英文命名,哼哼. heater类,加热,声明一个委托,定义一个委托事件: using System; ...
- Eigen教程(6)
整理下Eigen库的教程,参考:http://eigen.tuxfamily.org/dox/index.html 高级初始化方法 本篇介绍几种高级的矩阵初始化方法,重点介绍逗号初始化和特殊矩阵(单位 ...
- iOS App中第一次运行添加半透明新手指引
实现方式: 在当前View上一个蒙层,然后找出需要标记的地方圈为白色,那些箭头和提示文字都是UI做出来的图上自带的. 代码: 判断是第一次运行APP后进入页面调用 -(void)newGuide { ...
- Winsock解析
一.基本知识 1.Winsock,一种标准API,一种网络编程接口,用于两个或多个应用程序(或进程)之间通过网络进行数据通信.具有两个版本: Winsock 1: Windows CE平台支持. 头文 ...
- JAVA传入一个字符串,返回一个字符串中的大写字母
/** * * @param 传入一个字符串 * @return 返回一个字符串中的大写字母 */ private static String str ...
- Android——开源框架Universal-Image-Loader + Fragment使用+轮播广告
原文地址: Android 开源框架Universal-Image-Loader完全解析(一)--- 基本介绍及使用 Android 开源框架Universal-Image-Loader完全解析(二) ...