RNN - LSTM - GRU
循环神经网络 (Recurrent Neural Network,RNN) 是一类具有短期记忆能力的神经网络,因而常用于序列建模。本篇先总结 RNN 的基本概念,以及其训练中时常遇到梯度爆炸和梯度消失问题,再引出 RNN 的两个主流变种 —— LSTM 和 GRU。
Vanilla RNN
Vanilla RNN 的主体结构:
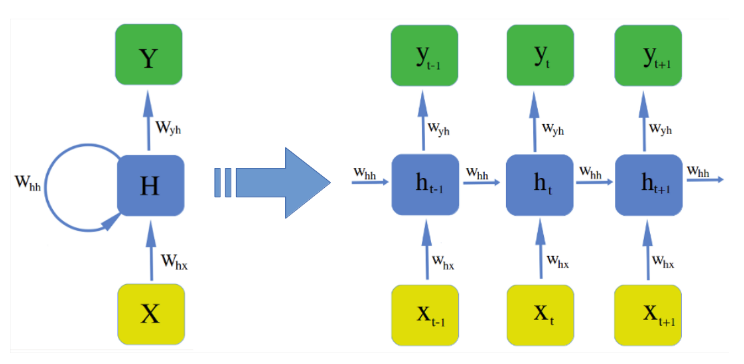
上图中 \(\bf{X, h, y}\) 都是向量,公式如下:
\[
% <![CDATA[
\begin{align}
\textbf{h}_{t} &= f_{\textbf{W}}\left(\textbf{h}_{t-1}, \textbf{x}_{t} \right) \tag{1} \\
\textbf{h}_{t} &= f\left(\textbf{W}_{hx}\textbf{x}_{t} + \textbf{W}_{hh}\textbf{h}_{t-1} + \textbf{b}_{h}\right) \tag{2a} \\
\textbf{h}_{t} &= \textbf{tanh}\left(\textbf{W}_{hx}\textbf{x}_{t} + \textbf{W}_{hh}\textbf{h}_{t-1} + \textbf{b}_{h}\right) \tag{2b} \\
\hat{\textbf{y}}_{t} &= \textbf{softmax}\left(\textbf{W}_{yh}\textbf{h}_{t} + \textbf{b}_{y}\right) \tag{3}
\end{align} %]]>
\]
其中 \(\textbf{W}_{hx} \in \mathbb{R}^{h \times x}, \; \textbf{W}_{hh} \in \mathbb{R}^{h \times h}, \; \textbf{W}_{yh} \in \mathbb{R}^{y \times h}, \; \textbf{b}_{h} \in \mathbb{R}^{h}, \; \textbf{b}_{y} \in \mathbb{R}^{y}\)
\((2a)\) 式中的两个矩阵 \(\mathbf{W}\) 可以合并:
\[
\begin{align*}
\textbf{h}_{t} &= f\left(\textbf{W}_{hx}\textbf{x}_{t} + \textbf{W}_{hh}\textbf{h}_{t-1} + \textbf{b}_{h}\right) \\
& = f\left(\left(\textbf{W}_{hx}, \textbf{W}_{hh}\right)
\begin{pmatrix}
\textbf{x}_t \\
\textbf{h}_{t-1}
\end{pmatrix}
+ \textbf{b}_{h}\right) \\
& = f\left(\textbf{W}
\begin{pmatrix}
\textbf{x}_t \\
\textbf{h}_{t-1}
\end{pmatrix}
+ \textbf{b}_{h}\right)
\end{align*}
\]
注意到在计算时,每一 time step 中使用的参数 \(\textbf{W}, \; \textbf{b}\) 是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点。
和普通的全连接层相比,RNN 除了输入 \(\textbf{x}_t\) 外,还有输入隐藏层上一节点 \(\mathbf{h}_{t-1}\) ,RNN 每一层的输出就是这两个输入用矩阵 \(\textbf{W}_{hx}\),\(\textbf{W}_{hh}\)和激活函数进行组合的结果。从 \((2a)\) 式可以看出 \(\textbf{x}_t\) 和 \(\mathbf{h}_{t-1}\) 都是与 \(\textbf{h}_t\) 全连接的,下图形象展示了各个时间节点 RNN 隐藏层记忆的变化。随着时间流逝,最初的蓝色结点保留地越来越少,这意味着RNN对于长时记忆的困难。
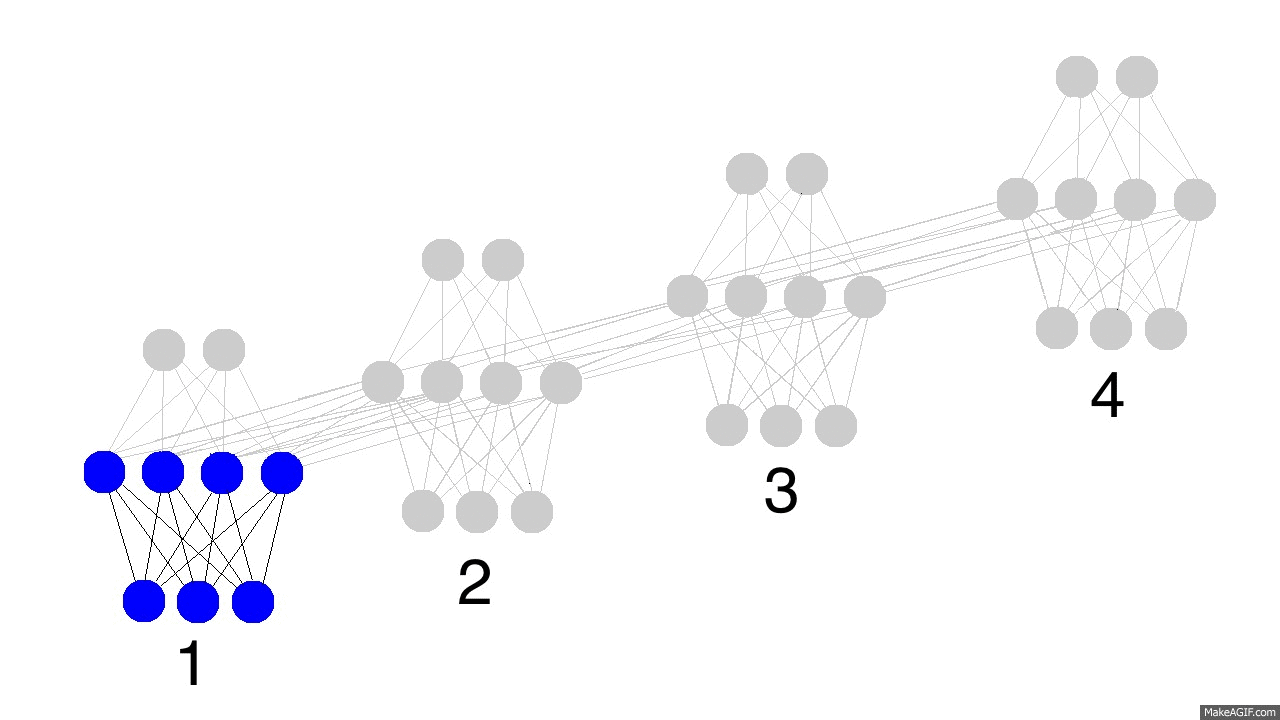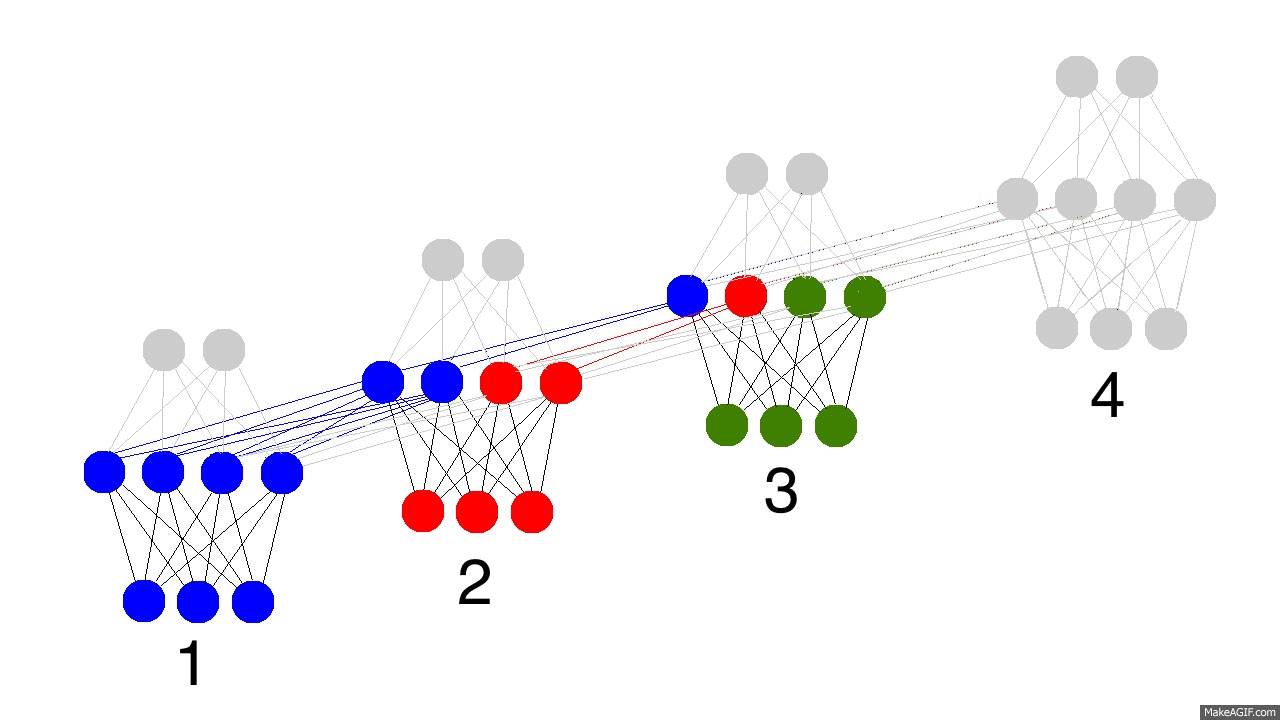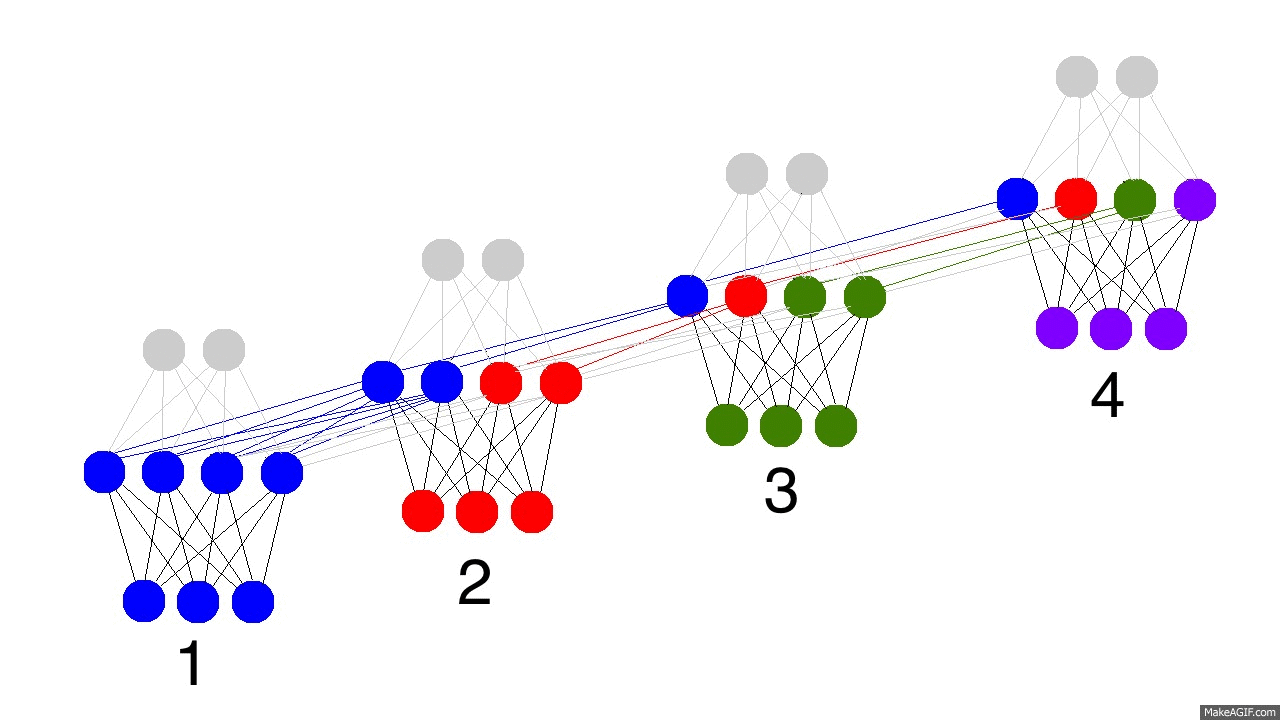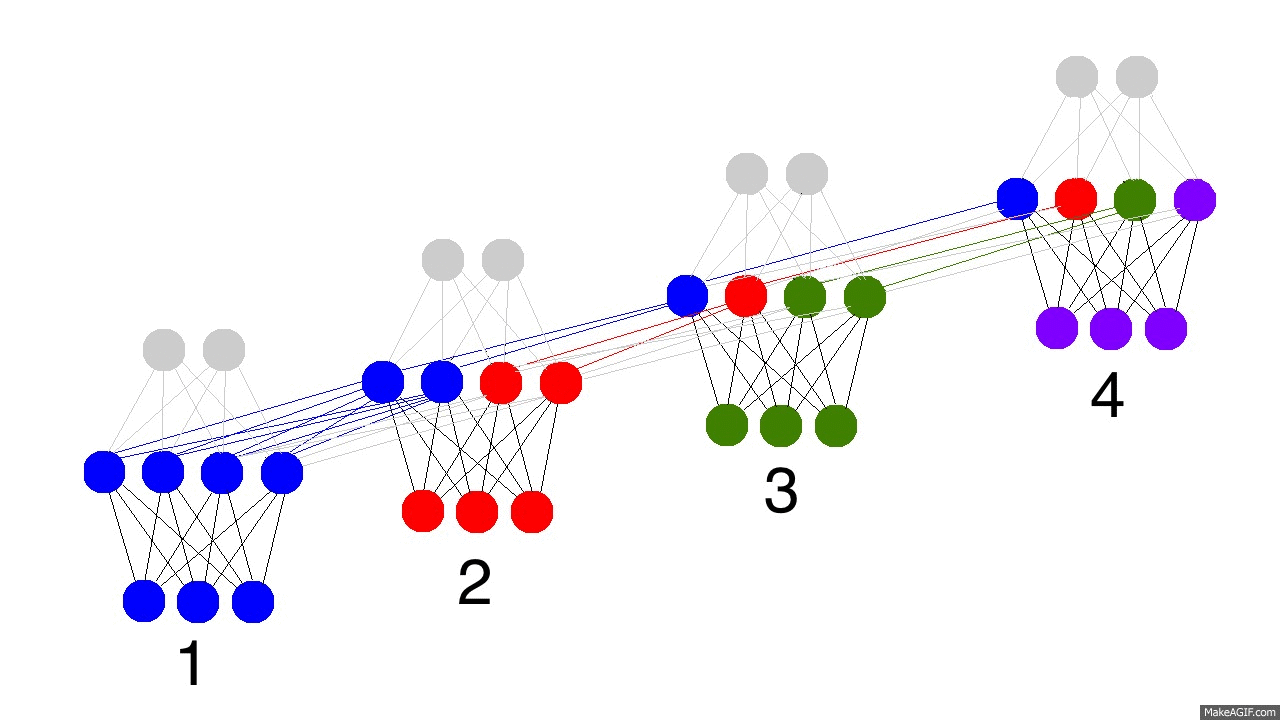
Vanishing & Exploding Gradient Problems
RNN 对于长时记忆的困难主要来源于梯度爆炸 / 消失问题,下面进行说明。RNN 中 Loss 的计算图示例:
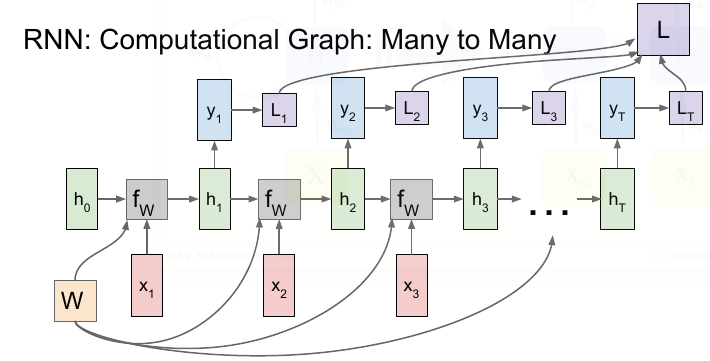
总的 Loss 是每个 time step 的加和 : \(\mathcal{\large{L}} (\hat{\textbf{y}}, \textbf{y}) = \sum_{t = 1}^{T} \mathcal{ \large{L} }(\hat{\textbf{y}_t}, \textbf{y}_{t})\)
由 backpropagation through time (BPTT) 算法,参数的梯度为:
\[
\frac{\partial \boldsymbol{\mathcal{L}}}{\partial \textbf{W}} = \sum_{t=1}^{T} \frac{\partial \boldsymbol{\mathcal{L}}_{t}}{\partial \textbf{W}} = \sum_{t=1}^{T} \frac{\partial \boldsymbol{\mathcal{L}}_t}{\partial \textbf{y}_{t}} \frac{\partial \textbf{y}_{t}}{\partial \textbf{h}_{t}} \overbrace{\frac{\partial \textbf{h}_{t}}{\partial \textbf{h}_{k}}}^{ \bigstar } \frac{\partial \textbf{h}_{k}}{\partial \textbf{W}}
\]
其中 \(\frac{\partial \textbf{h}_{t}}{\partial \textbf{h}_{k}}\) 包含一系列 \(\text{Jacobian}\) 矩阵,
\[
\frac{\partial \textbf{h}_{t}}{\partial \textbf{h}_{k}} = \frac{\partial \textbf{h}_{t}}{\partial \textbf{h}_{t-1}} \frac{\partial \textbf{h}_{t-1}}{\partial \textbf{h}_{t-2}} \cdots \frac{\partial \textbf{h}_{k+1}}{\partial \textbf{h}_{k}}
= \prod_{i=k+1}^{t} \frac{\partial \textbf{h}_{i}}{\partial \textbf{h}_{i-1}}
\]
由于 RNN 中每个 time step 都是用相同的 \(\textbf{W}\) ,所以由 \((2a)\) 式可得:
\[
\prod_{i=k+1}^{t} \frac{\partial \textbf{h}_{i}}{\partial \textbf{h}_{i-1}} = \prod_{i=k+1}^{t} \textbf{W}^\top \text{diag} \left[ f'\left(\textbf{h}_{i-1}\right) \right]
\]
由于 \(\textbf{W}_{hh} \in \mathbb{R}^{h \times h}\) 为方阵,对其进行特征值分解:
\[
\mathbf{W} = \mathbf{V} \, \text{diag}(\boldsymbol{\lambda}) \, \mathbf{V}^{-1}
\]
由于上式是连乘 \(\text{t}\) 次 \(\mathbf{W}\) :
\[
\mathbf{W}^t = (\mathbf{V} \, \text{diag}(\boldsymbol{\lambda}) \, \mathbf{V}^{-1})^t = \mathbf{V} \, \text{diag}(\boldsymbol{\lambda})^t \, \mathbf{V}^{-1}
\]
连乘的次数多了之后,则若最大的特征值 \(\lambda >1\) ,会产生梯度爆炸; \(\lambda < 1\) ,则会产生梯度消失 。不论哪种情况,都会导致模型难以学到有用的模式。
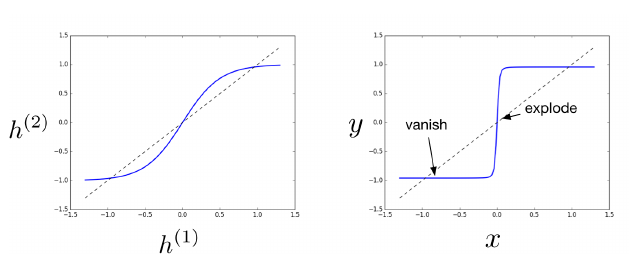
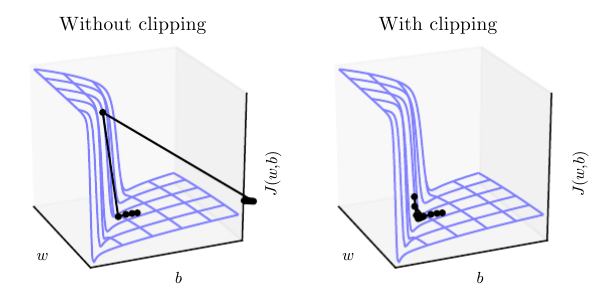
下左图显示一个 time step 中 tanh 函数的计算结果,右图显示整个神经网络的计算结果,可以清楚地看到哪个区域最容易产生梯度爆炸/消失问题。
梯度爆炸的解决办法:
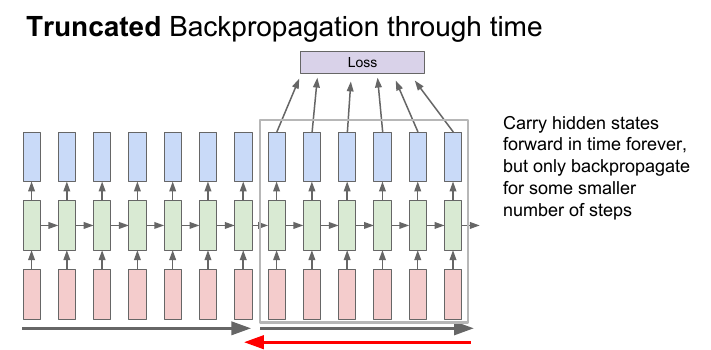
(1) Truncated Backpropagation through time:每次只 BP 固定的 time step 数,类似于 mini-batch SGD。缺点是丧失了长距离记忆的能力。
(2) Clipping Gradients: 当梯度超过一定的 threshold 后,就进行 element-wise 的裁剪,该方法的缺点是又引入了一个新的参数 threshold。同时该方法也可视为一种基于瞬时梯度大小来自适应 learning rate 的方法:
\[
\text{if} \quad \lVert \textbf{g} \rVert \ge \text{threshold} \\[1ex]
\textbf{g} \leftarrow \frac{\text{threshold}}{\lVert \textbf{g} \rVert} \textbf{g}
\]
梯度消失的解决办法
(1) 使用 LSTM、GRU等升级版 RNN,使用各种 gates 控制信息的流通。
(2) 在这篇论文 (https://arxiv.org/pdf/1602.06662.pdf) 中提出将权重矩阵 \(\textbf{W}\) 初始化为正交矩阵。正交矩阵有如下性质:\(A^T A =A A^T = I, \; A^T = A^{-1}\), 正交矩阵的特征值的绝对值为 \(\text{1}\) 。证明如下, 对矩阵 \(A\) 有:
\[
\begin{align*}
& A \mathbf{v} = \lambda \mathbf{v} \\[1ex]
||A \mathbf{v}||^2& = (A \mathbf{v})^\text{T} (A \mathbf{v}) \\
&= \mathbf{v}^\text{T}A ^{\text{T}}A \mathbf{v} \\
& = \mathbf{v}^{\text{T}}\mathbf{v} \\ &
= ||\mathbf{v}||^2 \\ &
= |\lambda|^2 ||\mathbf{v}||^2
\end{align*}
\]
由于 \(\mathbf{v}\) 为特征向量,\(\mathbf{v} \neq 0\) ,所以 \(|\lambda| = 1\) ,这样连乘之后 \(\lambda^t\) 不会出现越来越小的情况。
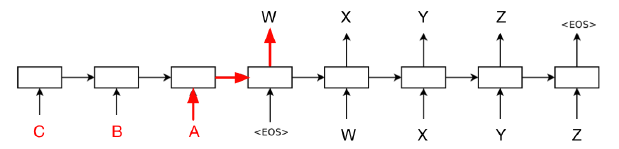
(3) 反转输入序列。像在机器翻译中使用 seq2seq 模型,若使用正常序列输入,则输入序列的第一个词和输出序列的第一个词相距较远,难以学到长期依赖。将输入序列反向后,输入序列的第一个词就会和输出序列的第一个词非常接近,二者的相互关系也就比较容易学习了。这样模型可以先学前几个词的短期依赖,再学后面词的长期依赖关系。见下图正常输入顺序是 \(|\text{ABC}|\),反向是 \(|\text{CBA}|\) ,则 \(\text{A}\) 与第一个输出词 \(\text{W}\) 接近:
LSTM
虽然 Vanilla RNN 理论上可以建立长时间间隔状态之间的依赖关系,但由于梯度爆炸或消失问题,实际上只能学到短期依赖关系。为了学到长期依赖关系,LSTM 中引入了门控机制来控制信息的累计速度,包括有选择地加入新的信息,并有选择地遗忘之前累计的信息,整个 LSTM 单元结构如下图所示:
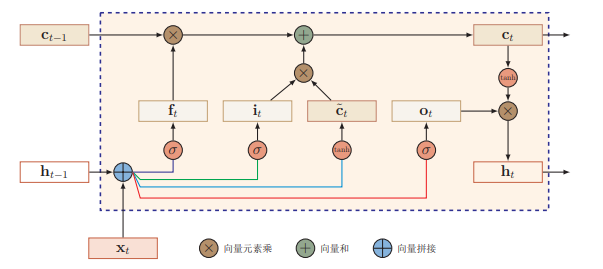
\[
\begin{align}
\text{input gate}&: \quad \textbf{i}_t = \sigma(\textbf{W}_i\textbf{x}_t + \textbf{U}_i\textbf{h}_{t-1} + \textbf{b}_i)\tag{1} \\
\text{forget gate}&: \quad \textbf{f}_t = \sigma(\textbf{W}_f\textbf{x}_t + \textbf{U}_f\textbf{h}_{t-1} + \textbf{b}_f) \tag{2}\\
\text{output gate}&: \quad \textbf{o}_t = \sigma(\textbf{W}_o\textbf{x}_t + \textbf{U}_o\textbf{h}_{t-1} + \textbf{b}_o) \tag{3}\\
\text{new memory cell}&: \quad \tilde{\textbf{c}}_t = \text{tanh}(\textbf{W}_c\textbf{x}_t + \textbf{U}_c\textbf{h}_{t-1} + \textbf{b}_c) \tag{4}\\
\text{final memory cell}& : \quad \textbf{c}_t = \textbf{f}_t \odot \textbf{c}_{t-1} + \textbf{i}_t \odot \tilde{\textbf{c}}_t \tag{5}\\
\text{final hidden state} &: \quad \textbf{h}_t= \textbf{o}_t \odot \text{tanh}(\textbf{c}_t) \tag{6}
\end{align}
\]
式 $(1) \sim (4) $ 的输入都一样,因而可以合并:
\[
\begin{pmatrix}
\textbf{i}_t \\
\textbf{f}_{t} \\
\textbf{o}_t \\
\tilde{\textbf{c}}_t
\end{pmatrix}
=
\begin{pmatrix}
\sigma \\
\sigma \\
\sigma \\
\text{tanh}
\end{pmatrix}
\left(\textbf{W}
\begin{bmatrix}
\textbf{x}_t \\
\textbf{h}_{t-1}
\end{bmatrix} + \textbf{b}
\right)
\]
$\tilde{\textbf{c}}_t $ 为时刻 t 的候选状态,\(\textbf{i}_t\) 控制 \(\tilde{\textbf{c}}_t\) 中有多少新信息需要保存,\(\textbf{f}_{t}\) 控制上一时刻的内部状态 \(\textbf{c}_{t-1}\) 需要遗忘多少信息,\(\textbf{o}_t\) 控制当前时刻的内部状态 \(\textbf{c}_t\) 有多少信息需要输出给外部状态 \(\textbf{h}_t\) 。
下表显示 forget gate 和 input gate 的关系,可以看出 forget gate 其实更应该被称为 “remember gate”, 因为其开启时之前的记忆信息 \(\textbf{c}_{t-1}\) 才会被保留,关闭时则会遗忘所有:
| forget gate | input gate | result |
|---|---|---|
| 1 | 0 | 保留上一时刻的状态 \(\textbf{c}_{t-1}\) |
| 1 | 1 | 保留上一时刻 \(\textbf{c}_{t-1}\) 和添加新信息 \(\tilde{\textbf{c}}_t\) |
| 0 | 1 | 清空历史信息,引入新信息 \(\tilde{\textbf{c}}_t\) |
| 0 | 0 | 清空所有新旧信息 |
对比 Vanilla RNN,可以发现在时刻 t,Vanilla RNN 通过 \(\textbf{h}_t\) 来保存和传递信息,上文已分析了如果时间间隔较大容易产生梯度消失的问题。 LSTM 则通过记忆单元 \(\textbf{c}_t\) 来传递信息,通过 \(\textbf{i}_t\) 和 \(\textbf{f}_{t}\) 的调控,\(\textbf{c}_t\) 可以在 t 时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。
原始的 LSTM 中是没有 forget gate 的,即:
\[
\textbf{c}_t = \textbf{c}_{t-1} + \textbf{i}_t \odot \tilde{\textbf{c}}_t
\]
这样 \(\frac{\partial \textbf{c}_t}{\partial \textbf{c}_{t-1}}\) 恒为 \(\text{1}\) 。但是这样 \(\textbf{c}_t\) 会不断增大,容易饱和从而降低模型性能。后来引入了 forget gate ,则梯度变为 \(\textbf{f}_{t}\) ,事实上连乘多个 \(\textbf{f}_{t} \in (0,1)\) 同样会导致梯度消失,但是 LSTM 的一个初始化技巧就是将 forget gate 的 bias 置为正数(例如 1 或者 5,如 tensorflow 中的默认值就是 \(1.0\) ),这样一来模型刚开始训练时 forget gate 的值都接近 1,不会发生梯度消失 (反之若 forget gate 的初始值过小则意味着前一时刻的大部分信息都丢失了,这样很难捕捉到长距离依赖关系)。 随着训练过程的进行,forget gate 就不再恒为 1 了。不过,一个训好的模型里各个 gate 值往往不是在 [0, 1] 这个区间里,而是要么 0 要么 1,很少有类似 0.5 这样的中间值,其实相当于一个二元的开关。假如在某个序列里,forget gate 全是 1,那么梯度不会消失;某一个 forget gate 是 0,模型选择遗忘上一时刻的信息。
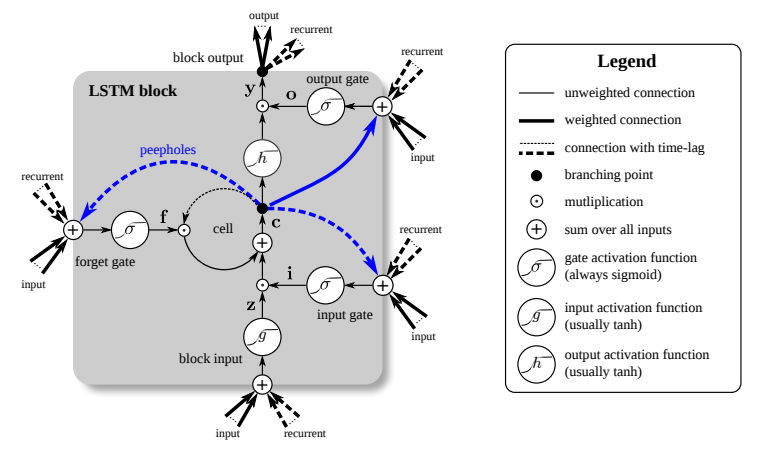
LSTM 的一种变体增加 peephole 连接,这样三个 gate 不仅依赖于 \(\textbf{x}_t\) 和 \(\textbf{h}_{t-1}\),也依赖于记忆单元 \(\textbf{c}\) :
\[
\begin{align*}
\text{input gate}&: \quad \textbf{i}_t = \sigma(\textbf{W}_i\textbf{x}_t + \textbf{U}_i\textbf{h}_{t-1} + \textbf{V}_i\textbf{c}_{t-1} + \textbf{b}_i) \\
\text{forget gate}&: \quad \textbf{f}_t = \sigma(\textbf{W}_f\textbf{x}_t + \textbf{U}_f\textbf{h}_{t-1} + \textbf{V}_f\textbf{c}_{t-1} +\textbf{b}_f) \\
\text{output gate}&: \quad \textbf{o}_t = \sigma(\textbf{W}_o\textbf{x}_t + \textbf{U}_o\textbf{h}_{t-1} + \textbf{V}_o\textbf{c}_{t} +\textbf{b}_o) \\
\end{align*}
\]
注意 input gate 和 forget gate 连接的是 \(\textbf{c}_{t-1}\) ,而 output gate 连接的是 \(\textbf{c}_t\) 。下图来自 《LSTM: A Search Space Odyssey》,标注了 peephole 连接的样貌。
GRU
相比于 Vanilla RNN (每个 time step 有一个输入 \(\textbf{x}_t\) ),从上面的 \((1) \sim (4)\) 式可以看出 一个 LSTM 单元有四个输入 (如下图,不考虑 peephole) ,因而参数是 Vanilla RNN 的四倍,带来的结果是训练起来很慢,因而在2014年 Cho 等人提出了 GRU ,对 LSTM 进行了简化,在不影响效果的前提下加快了训练速度。
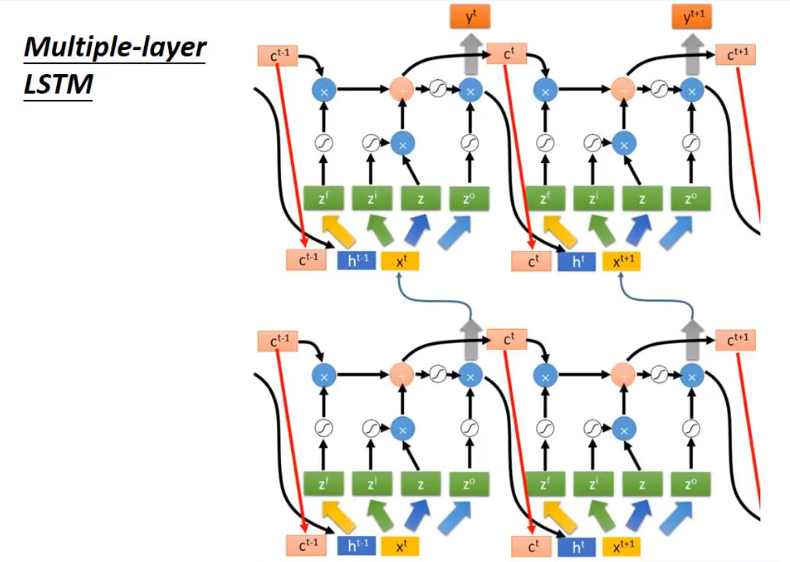
\(\large\scr{LSTM:}\)
\[
\normalsize
\begin{align}
\text{input gate}&: \quad \textbf{i}_t = \sigma(\textbf{W}_i\textbf{x}_t + \textbf{U}_i\textbf{h}_{t-1} + \textbf{b}_i)\tag{1} \\
\text{forget gate}&: \quad \textbf{f}_t = \sigma(\textbf{W}_f\textbf{x}_t + \textbf{U}_f\textbf{h}_{t-1} + \textbf{b}_f) \tag{2}\\
\text{output gate}&: \quad \textbf{o}_t = \sigma(\textbf{W}_o\textbf{x}_t + \textbf{U}_o\textbf{h}_{t-1} + \textbf{b}_o) \tag{3}\\
\text{new memory cell}&: \quad \tilde{\textbf{c}}_t = \text{tanh}(\textbf{W}_c\textbf{x}_t + \textbf{U}_c\textbf{h}_{t-1} + \textbf{b}_c) \tag{4}\\
\text{final memory cell}& : \quad \textbf{c}_t = \textbf{f}_t \odot \textbf{c}_{t-1} + \textbf{i}_t \odot \tilde{\textbf{c}}_t \tag{5}\\
\text{final hidden state} &: \quad \textbf{h}_t= \textbf{o}_t \odot \text{tanh}(\textbf{c}_t) \tag{6}
\end{align}
\]
在式 \((5)\) 中 forget gate 和 input gate 是互补关系,因而比较冗余,GRU 将其合并为一个 update gate。同时 GRU 也不引入额外的记忆单元 (LSTM 中的 \(\textbf{c}\)) ,而是直接在当前状态 \(\textbf{h}_t\) 和历史状态 \(\textbf{h}_{t-1}\) 之间建立线性依赖关系。
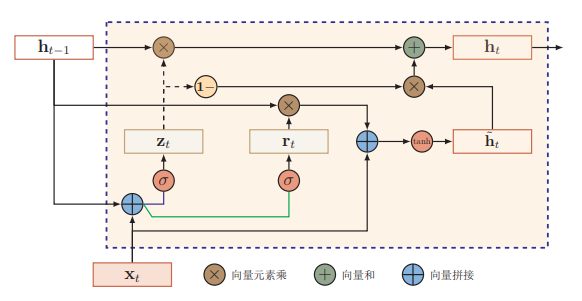
\(\large\scr{GRU:}\)
\[
\normalsize
\begin{align}
\text{reset gate}&: \quad \textbf{r}_t = \sigma(\textbf{W}_r\textbf{x}_t + \textbf{U}_r\textbf{h}_{t-1} + \textbf{b}_r)\tag{7} \\
\text{update gate}&: \quad \textbf{z}_t = \sigma(\textbf{W}_z\textbf{x}_t + \textbf{U}_z\textbf{h}_{t-1} + \textbf{b}_z)\tag{8} \\
\text{new memory cell}&: \quad \tilde{\textbf{h}}_t = \text{tanh}(\textbf{W}_h\textbf{x}_t + \textbf{r}_t \odot (\textbf{U}_h\textbf{h}_{t-1}) + \textbf{b}_h) \tag{9}\\
\text{final hidden state}&: \quad \textbf{h}_t = \textbf{z}_t \odot \textbf{h}_{t-1} + (1 - \textbf{z}_t) \odot \tilde{\textbf{h}}_t \tag{10}
\end{align}
\]
$ \tilde{\textbf{h}}_t $ 为时刻 t 的候选状态,\(\textbf{r}_t\) 控制 $ \tilde{\textbf{h}}_t $ 有多少依赖于上一时刻的状态 \(\textbf{h}_{t-1}\) ,如果 \(\textbf{r}_t = 1\) ,则式 \((9)\) 与 Vanilla RNN 一致,对于短依赖的 GRU 单元,reset gate 通常会更新频繁。\(\textbf{z}_t\) 控制当前的内部状态 \(\textbf{h}_t\) 中有多少来自于上一时刻的 \(\textbf{h}_{t-1}\) 。如果 \(\textbf{z}_t = 1\) ,则会每步都传递同样的信息,和当前输入 \(\textbf{x}_t\) 无关。
另一方面看,\(\textbf{r}_t\) 与 LSTM 中的 \(\textbf{o}_t\) 角色有些类似,因为将上面的 \((6)\) 式代入 \((4)\) 式可以得到:
\[
\begin{align*}
\tilde{\textbf{c}}_t &= \text{tanh}(\textbf{W}_c\textbf{x}_t + \textbf{U}_c\textbf{h}_{t-1} + \textbf{b}_c) \\
\textbf{h}_t &= \textbf{o}_t \odot \text{tanh}(\textbf{c}_t)
\end{align*}
\quad
\Longrightarrow
\quad
\tilde{\textbf{c}}_t = \text{tanh}(\textbf{W}_c\textbf{x}_t + \textbf{U}_c \left(\textbf{o}_{t-1} \odot \text{tanh}(\textbf{c}_{t-1})\right) + \textbf{b}_c)
\]
最后是 cs224n 中提出的 RNN 训练 tips:

/
RNN - LSTM - GRU的更多相关文章
- RNN,LSTM,GRU基本原理的个人理解
记录一下对RNN,LSTM,GRU基本原理(正向过程以及简单的反向过程)的个人理解 RNN Recurrent Neural Networks,循环神经网络 (注意区别于recursive neura ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- RNN & LSTM & GRU 的原理与区别
RNN 循环神经网络,是非线性动态系统,将序列映射到序列,主要参数有五个:[Whv,Whh,Woh,bh,bo,h0][Whv,Whh,Woh,bh,bo,h0],典型的结构图如下: 和普通神经网 ...
- [PyTorch] rnn,lstm,gru中输入输出维度
本文中的RNN泛指LSTM,GRU等等 CNN中和RNN中batchSize的默认位置是不同的. CNN中:batchsize的位置是position 0. RNN中:batchsize的位置是pos ...
- RNN, LSTM, GRU cells
项目需要,先简记cell,有时间再写具体改进原因 RNN cell LSTM cell: GRU cell: reference: 1.https://towardsdatascience.com/a ...
- RNN,GRU,LSTM
2019-08-29 17:17:15 问题描述:比较RNN,GRU,LSTM. 问题求解: 循环神经网络 RNN 传统的RNN是维护了一个隐变量 ht 用来保存序列信息,ht 基于 xt 和 ht- ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- 断开网络连接的dos命令
https://zhidao.baidu.com/question/154994771.html 或者采用服务关闭开启模式,不过没有上面的好用net stop "network connec ...
- phantomjs在win10下的安装
phantomjs只能通过官网下载,下载地址:http://phantomjs.org/download.html. 1.最好下载在英文文件夹下.下载完成后,解压. 2.进入bin文件,右击属性,将p ...
- go 并发
package main import ( "fmt" "time" ) func say(s string) { ; i < ; i++ { time. ...
- Ubuntu 14.04 执行指定用户的命令
#!/bin/bashsudo -u username /home/sco/start_server.sh 或者 #!/bin/bashsu - username -c /etc/init.d/xxx ...
- Jmeter性能测试 对服务器使用资源进行监控之ServerAgent插件使用
百度云盘友情赞助地址如下: 链接:https://pan.baidu.com/s/1cpAeOcfFX8kss1eo79UD9g 密码:b8o7 在windows上或者linux上打开服务 用Jmet ...
- linux 系统调用号表
位于 /usr/include/asm/unistd.h 由于我是64位系统,所以有一些额外的东西.我的这个文件为下文 #ifndef _ASM_X86_UNISTD_H #define _ASM_X ...
- Codeforces 534B - Covered Path
534B - Covered Path 思路:贪心,每一秒取尽可能大并且可以达到的速度. 画张图吧,不解释了: 代码: #include<bits/stdc++.h> using name ...
- 微服务API网关
当你选择采用微服务构建自己的程序,则你需要考虑客户端怎样与后端服务交互.对于一个单体应用,仅有一个服务群提供服务(通过负载均衡器实现).在微服务架构里面,每一个服务都暴漏了一个服务器集群.本篇文章我们 ...
- Linux 下载最新kubectl版本的命令:
ubuntu centos下通用 第一步.下载最新版本的命令: curl -LO https://storage.googleapis.com/kubernetes-release/release/$ ...
- Linux系统中切换用户身份su与sudo的用法与实例
日常操作中为了避免一些误操作,更加安全地管理系统,通常使用的用户身份都为普通用户,而非root.当需要执行一些管理员命令操作时,再切换成root用户身份去执行. 普通用户切换到root用户的方式有:s ...