浅谈压缩感知(九):正交匹配追踪算法OMP
主要内容:
- OMP算法介绍
- OMP的MATLAB实现
- OMP中的数学知识
一、OMP算法介绍
来源:http://blog.csdn.net/scucj/article/details/7467955
1、信号的稀疏表示(sparse representation of signals)
给定一个过完备字典矩阵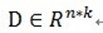 ,其中它的每列表示一种原型信号的原子。给定一个信号y,它可以被表示成这些原子的稀疏线性组合。信号 y 可以被表达为 y = Dx ,或者
,其中它的每列表示一种原型信号的原子。给定一个信号y,它可以被表示成这些原子的稀疏线性组合。信号 y 可以被表达为 y = Dx ,或者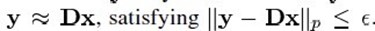 。字典矩阵中所谓过完备性,指的是原子的个数远远大于信号y的长度(其长度很显然是n),即n<<k。
。字典矩阵中所谓过完备性,指的是原子的个数远远大于信号y的长度(其长度很显然是n),即n<<k。
2、MP算法(匹配追踪算法)
2.1 算法描述
作为对信号进行稀疏分解的方法之一,将信号在完备字典库上进行分解。
假定被表示的信号为y,其长度为n。假定H表示Hilbert空间,在这个空间H里,由一组向量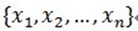 构成字典矩阵D,其中每个向量可以称为原子(atom),其长度与被表示信号 y 的长度n相同,而且这些向量已作为归一化处理,即|
构成字典矩阵D,其中每个向量可以称为原子(atom),其长度与被表示信号 y 的长度n相同,而且这些向量已作为归一化处理,即|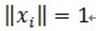 ,也就是单位向量长度为1。MP算法的基本思想:从字典矩阵D(也称为过完备原子库中),选择一个与信号 y 最匹配的原子(也就是某列),构建一个稀疏逼近,并求出信号残差,然后继续选择与信号残差最匹配的原子,反复迭代,信号y可以由这些原子来线性和,再加上最后的残差值来表示。很显然,如果残差值在可以忽略的范围内,则信号y就是这些原子的线性组合。如果选择与信号y最匹配的原子?如何构建稀疏逼近并求残差?如何进行迭代?我们来详细介绍使用MP进行信号分解的步骤:[1] 计算信号 y 与字典矩阵中每列(原子)的内积,选择绝对值最大的一个原子,它就是与信号 y 在本次迭代运算中最匹配的。用专业术语来描述:令信号
,也就是单位向量长度为1。MP算法的基本思想:从字典矩阵D(也称为过完备原子库中),选择一个与信号 y 最匹配的原子(也就是某列),构建一个稀疏逼近,并求出信号残差,然后继续选择与信号残差最匹配的原子,反复迭代,信号y可以由这些原子来线性和,再加上最后的残差值来表示。很显然,如果残差值在可以忽略的范围内,则信号y就是这些原子的线性组合。如果选择与信号y最匹配的原子?如何构建稀疏逼近并求残差?如何进行迭代?我们来详细介绍使用MP进行信号分解的步骤:[1] 计算信号 y 与字典矩阵中每列(原子)的内积,选择绝对值最大的一个原子,它就是与信号 y 在本次迭代运算中最匹配的。用专业术语来描述:令信号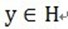 ,从字典矩阵中选择一个最为匹配的原子,满足
,从字典矩阵中选择一个最为匹配的原子,满足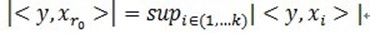 ,r0 表示一个字典矩阵的列索引。这样,信号 y 就被分解为在最匹配原子
,r0 表示一个字典矩阵的列索引。这样,信号 y 就被分解为在最匹配原子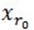 的垂直投影分量和残值两部分,即:
的垂直投影分量和残值两部分,即: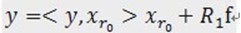 。[2]对残值R1f进行步骤[1]同样的分解,那么第K步可以得到:
。[2]对残值R1f进行步骤[1]同样的分解,那么第K步可以得到:
 , 其中
, 其中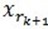 满足
满足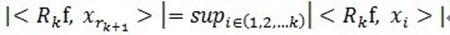 。可见,经过K步分解后,信号 y 被分解为:
。可见,经过K步分解后,信号 y 被分解为: ,其中
,其中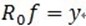 。
。
2.2 继续讨论
(1)为什么要假定在Hilbert空间中?Hilbert空间就是定义了完备的内积空。很显然,MP中的计算使用向量的内积运算,所以在在Hilbert空间中进行信号分解理所当然了。什么是完备的内积空间?篇幅有限就请自己搜索一下吧。
(2)为什么原子要事先被归一化处理了,即上面的描述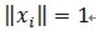 。内积常用于计算一个矢量在一个方向上的投影长度,这时方向的矢量必须是单位矢量。MP中选择最匹配的原子是,是选择内积最大的一个,也就是信号(或是残值)在原子(单位的)垂直投影长度最长的一个,比如第一次分解过程中,投影长度就是
。内积常用于计算一个矢量在一个方向上的投影长度,这时方向的矢量必须是单位矢量。MP中选择最匹配的原子是,是选择内积最大的一个,也就是信号(或是残值)在原子(单位的)垂直投影长度最长的一个,比如第一次分解过程中,投影长度就是 。
。 ,三个向量,构成一个三角形,且
,三个向量,构成一个三角形,且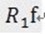 和
和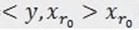 正交(不能说垂直,但是可以想象二维空间这两个矢量是垂直的)。
正交(不能说垂直,但是可以想象二维空间这两个矢量是垂直的)。
(3)MP算法是收敛的,因为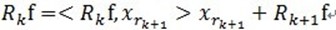 ,
,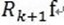 和
和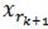 正交,由这两个可以得出
正交,由这两个可以得出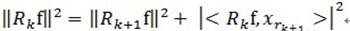 ,得出每一个残值比上一次的小,故而收敛。
,得出每一个残值比上一次的小,故而收敛。
2.3 MP算法的缺点
如上所述,如果信号(残值)在已选择的原子进行垂直投影是非正交性的,这会使得每次迭代的结果并不少最优的而是次最优的,收敛需要很多次迭代。举个例子说明一下:在二维空间上,有一个信号 y 被 D=[x1, x2]来表达,MP算法迭代会发现总是在x1和x2上反复迭代,即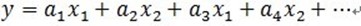 ,这个就是信号(残值)在已选择的原子进行垂直投影的非正交性导致的。再用严谨的方式描述[1]可能容易理解:在Hilbert空间H中,
,这个就是信号(残值)在已选择的原子进行垂直投影的非正交性导致的。再用严谨的方式描述[1]可能容易理解:在Hilbert空间H中,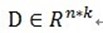 ,
, ,定义
,定义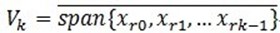 ,就是它是这些向量的张成中的一个,MP构造一种表达形式:
,就是它是这些向量的张成中的一个,MP构造一种表达形式: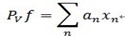 ;这里的Pvf表示 f在V上的一个正交投影操作,那么MP算法的第 k 次迭代的结果可以表示如下(前面描述时信号为y,这里变成f了,请注意):
;这里的Pvf表示 f在V上的一个正交投影操作,那么MP算法的第 k 次迭代的结果可以表示如下(前面描述时信号为y,这里变成f了,请注意):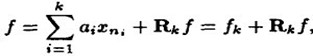
如果  是最优的k项近似值,当且仅当
是最优的k项近似值,当且仅当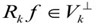 。由于MP仅能保证
。由于MP仅能保证 ,所以
,所以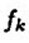 一般情况下是次优的。这是什么意思呢?
一般情况下是次优的。这是什么意思呢? 是k个项的线性表示,这个组合的值作为近似值,只有在第k个残差和
是k个项的线性表示,这个组合的值作为近似值,只有在第k个残差和 正交,才是最优的。如果第k个残值与
正交,才是最优的。如果第k个残值与 正交,意味这个残值与fk的任意一项都线性无关,那么第k个残值在后面的分解过程中,不可能出现fk中已经出现的项,这才是最优的。而一般情况下,不能满足这个条件,MP一般只能满足第k个残差和xk正交,这也就是前面为什么提到"信号(残值)在已选择的原子进行垂直投影是非正交性的"的原因。如果第k个残差和fk不正交,那么后面的迭代还会出现fk中已经出现的项,很显然fk就不是最优的,这也就是为什么说MP收敛就需要更多次迭代的原因。不是说MP一定得到不到最优解,而且其前面描述的特性导致一般得到不到最优解而是次优解。那么,有没有办法让第k个残差与
正交,意味这个残值与fk的任意一项都线性无关,那么第k个残值在后面的分解过程中,不可能出现fk中已经出现的项,这才是最优的。而一般情况下,不能满足这个条件,MP一般只能满足第k个残差和xk正交,这也就是前面为什么提到"信号(残值)在已选择的原子进行垂直投影是非正交性的"的原因。如果第k个残差和fk不正交,那么后面的迭代还会出现fk中已经出现的项,很显然fk就不是最优的,这也就是为什么说MP收敛就需要更多次迭代的原因。不是说MP一定得到不到最优解,而且其前面描述的特性导致一般得到不到最优解而是次优解。那么,有没有办法让第k个残差与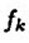 正交,方法是有的,这就是下面要谈到的OMP算法。
正交,方法是有的,这就是下面要谈到的OMP算法。
3、OMP算法
3.1 算法描述
OMP算法的改进之处在于:在分解的每一步对所选择的全部原子进行正交化处理,这使得在精度要求相同的情况下,OMP算法的收敛速度更快。
那么在每一步中如何对所选择的全部原子进行正交化处理呢?在正式描述OMP算法前,先看一点基础思想。
先看一个 k 阶模型,表示信号 f 经过 k 步分解后的情况,似乎很眼熟,但要注意它与MP算法不同之处,它的残值与前面每个分量正交,这就是为什么这个算法多了一个正交的原因,MP中仅与最近选出的的那一项正交。
 (1)
(1)
k + 1 阶模型如下:
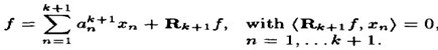 (2)
(2)
应用 k + 1阶模型减去k 阶模型,得到如下:
 (3)
(3)
我们知道,字典矩阵D的原子是非正交的,引入一个辅助模型,它是表示 对前k个项
对前k个项 的依赖,描述如下:
的依赖,描述如下:
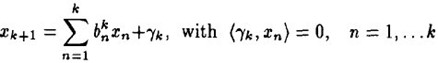 (4)
(4)
和前面描述类似,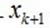 在span(x1, ...xk)之一上的正交投影操作,后面的项是残值。这个关系用数学符号描述:
在span(x1, ...xk)之一上的正交投影操作,后面的项是残值。这个关系用数学符号描述: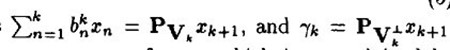
请注意,这里的 a 和 b 的上标表示第 k 步时的取值。
将(4)带入(3)中,有:
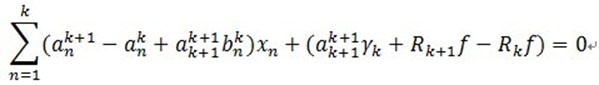 (5)
(5)
如果一下两个式子成立,(5)必然成立。
 (6)
(6)
 (7)
(7)
令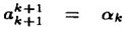 ,有
,有
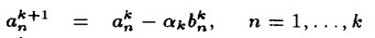
其中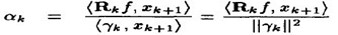 。
。
ak的值是由求法很简单,通过对(7)左右两边添加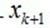 作内积消减得到:
作内积消减得到:

后边的第二项因为它们正交,所以为0,所以可以得出ak的第一部分。对于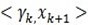 ,在(4)左右两边中与
,在(4)左右两边中与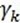 作内积,可以得到ak的第二部分。
作内积,可以得到ak的第二部分。
对于(4),可以求出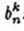 ,求的步骤请参见参考文件的计算细节部分。为什么这里不提,因为后面会介绍更简单的方法来计算。
,求的步骤请参见参考文件的计算细节部分。为什么这里不提,因为后面会介绍更简单的方法来计算。
3.2 收敛性证明
通过(7)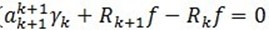 ,由于
,由于 与
与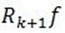 正交,将两个残值移到右边后求二范的平方,并将ak的值代入可以得到:
正交,将两个残值移到右边后求二范的平方,并将ak的值代入可以得到:
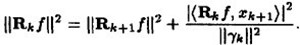
可见每一次残差比上一次残差小,可见是收敛的。
3.3 算法步骤
整个OMP算法的步骤如下:

由于有了上面的来龙去脉,这个算法就相当好理解了。
到这里还不算完,后来OMP的迭代运算用另外一种方法可以计算得知,有位同学的论文[2]描述就非常好,我就直接引用进来:


对比中英文描述,本质都是一样,只是有细微的差别。这里顺便贴出网一哥们写的OMP算法的代码,源出处不得而知,共享给大家。

二、OMP的MATLAB实现
1、一维信号重建
代码:
% -D信号压缩传感的实现(正交匹配追踪法Orthogonal Matching Pursuit)
% 测量数M>=K*log(N/K),K是稀疏度,N信号长度,可以近乎完全重构
% 编程人--香港大学电子工程系 沙威 Email: wsha@eee.hku.hk
% 编程时间:2008年11月18日
% 文档下载: http://www.eee.hku.hk/~wsha/Freecode/freecode.htm
% 参考文献:Joel A. Tropp and Anna C. Gilbert
% Signal Recovery From Random Measurements Via Orthogonal Matching
% Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. , NO. ,
% DECEMBER . clc;clear %% . 时域测试信号生成
K=; % 稀疏度(做FFT可以看出来)
N=; % 信号长度
M=; % 测量数(M>=K*log(N/K),至少40,但有出错的概率)
f1=; % 信号频率1
f2=; % 信号频率2
f3=; % 信号频率3
f4=; % 信号频率4
fs=; % 采样频率
ts=/fs; % 采样间隔
Ts=:N; % 采样序列
x=0.3*cos(*pi*f1*Ts*ts)+0.6*cos(*pi*f2*Ts*ts)+0.1*cos(*pi*f3*Ts*ts)+0.9*cos(*pi*f4*Ts*ts); % 完整信号,由4个信号叠加而来 %% . 时域信号压缩传感
Phi=randn(M,N); % 测量矩阵(高斯分布白噪声)*256的扁矩阵,Phi也就是文中说的D矩阵
s=Phi*x.'; % 获得线性测量 ,s相当于文中的y矩阵 %% . 正交匹配追踪法重构信号(本质上是L_1范数最优化问题)
%匹配追踪:找到一个其标记看上去与收集到的数据相关的小波;在数据中去除这个标记的所有印迹;不断重复直到我们能用小波标记“解释”收集到的所有数据。 m=*K; % 算法迭代次数(m>=K),设x是K-sparse的
Psi=fft(eye(N,N))/sqrt(N); % 傅里叶正变换矩阵
T=Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵) hat_y=zeros(,N); % 待重构的谱域(变换域)向量
Aug_t=[]; % 增量矩阵(初始值为空矩阵)
r_n=s; % 残差值 for times=:m; % 迭代次数(有噪声的情况下,该迭代次数为K)
for col=:N; % 恢复矩阵的所有列向量
product(col)=abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
[val,pos]=max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
Aug_t=[Aug_t,T(:,pos)]; % 矩阵扩充 T(:,pos)=zeros(M,); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; % 最小二乘,使残差最小
r_n=s-Aug_t*aug_y; % 残差
pos_array(times)=pos; % 纪录最大投影系数的位置
end
hat_y(pos_array)=aug_y; % 重构的谱域向量
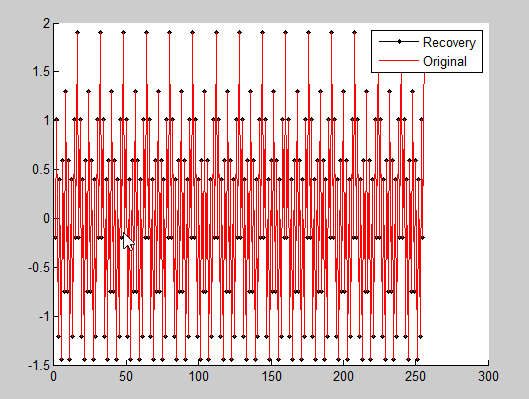
hat_x=real(Psi'*hat_y.'); % 做逆傅里叶变换重构得到时域信号 %% . 恢复信号和原始信号对比
figure();
hold on;
plot(hat_x,'k.-') % 重建信号
plot(x,'r') % 原始信号
legend('Recovery','Original')
norm(hat_x.'-x)/norm(x) % 重构误差
结果:
2、二维信号重建
代码:
% 本程序实现图像LENA的压缩传感
% 程序作者:沙威,香港大学电气电子工程学系,wsha@eee.hku.hk
% 算法采用正交匹配法,参考文献 Joel A. Tropp and Anna C. Gilbert
% Signal Recovery From Random Measurements Via Orthogonal Matching
% Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. , NO. ,
% DECEMBER .
% 该程序没有经过任何优化 function Wavelet_OMP clc;clear % 读文件
X=imread('lena256.bmp');
X=double(X);
[a,b]=size(X); % 小波变换矩阵生成
ww=DWT(a); % 小波变换让图像稀疏化(注意该步骤会耗费时间,但是会增大稀疏度)
X1=ww*sparse(X)*ww';
% X1=X;
X1=full(X1); % 随机矩阵生成
M=;
R=randn(M,a);
% R=mapminmax(R,,);
% R=round(R); % 测量值
Y=R*X1; % OMP算法
% 恢复矩阵
X2=zeros(a,b);
% 按列循环
for i=:b
% 通过OMP,返回每一列信号对应的恢复值(小波域)
rec=omp(Y(:,i),R,a);
% 恢复值矩阵,用于反变换
X2(:,i)=rec;
end % 原始图像
figure();
imshow(uint8(X));
title('原始图像'); % 变换图像
figure();
imshow(uint8(X1));
title('小波变换后的图像'); % 压缩传感恢复的图像
figure();
% 小波反变换
X3=ww'*sparse(X2)*ww;
% X3=X2;
X3=full(X3);
imshow(uint8(X3));
title('恢复的图像'); % 误差(PSNR)
% MSE误差
errorx=sum(sum(abs(X3-X).^));
% PSNR
psnr=*log10(*/(errorx/a/b)) % OMP的函数
% s-测量;T-观测矩阵;N-向量大小
function hat_y=omp(s,T,N)
Size=size(T); % 观测矩阵大小
M=Size(); % 测量
hat_y=zeros(,N); % 待重构的谱域(变换域)向量
Aug_t=[]; % 增量矩阵(初始值为空矩阵)
r_n=s; % 残差值 for times=:M; % 迭代次数(稀疏度是测量的1/)
for col=:N; % 恢复矩阵的所有列向量
product(col)=abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
[val,pos]=max(product); % 最大投影系数对应的位置
Aug_t=[Aug_t,T(:,pos)]; % 矩阵扩充
T(:,pos)=zeros(M,); % 选中的列置零(实质上应该去掉,为了简单我把它置零)
aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; % 最小二乘,使残差最小
r_n=s-Aug_t*aug_y; % 残差
pos_array(times)=pos; % 纪录最大投影系数的位置 if (norm(r_n)<0.9) % 残差足够小
break;
end
end
hat_y(pos_array)=aug_y; % 重构的向量
结果:

三、OMP算法中的数学知识
算法会有一些线性代数中的概念和知识,主要是关于子空间、最小二乘、投影矩阵等,详情请参考
最小二乘的几何意义及投影矩阵
浅谈压缩感知(九):正交匹配追踪算法OMP的更多相关文章
- 浅谈压缩感知(二十):OMP与压缩感知
主要内容: OMP在稀疏分解与压缩感知中的异同 压缩感知通过OMP重构信号的唯一性 一.OMP在稀疏分解与压缩感知中的异同 .稀疏分解要解决的问题是在冗余字典(超完备字典)A中选出k列,用这k列的线性 ...
- opencv实现正交匹配追踪算法OMP
//dic: 字典矩阵: //signal :待重构信号(一次只能重构一个信号,即一个向量) //min_residual: 最小残差 //sparsity:稀疏度 //coe:重构系数 //atom ...
- 浅谈压缩感知(二十一):压缩感知重构算法之正交匹配追踪(OMP)
主要内容: OMP的算法流程 OMP的MATLAB实现 一维信号的实验与结果 测量数M与重构成功概率关系的实验与结果 稀疏度K与重构成功概率关系的实验与结果 一.OMP的算法流程 二.OMP的MATL ...
- 浅谈压缩感知(二十八):压缩感知重构算法之广义正交匹配追踪(gOMP)
主要内容: gOMP的算法流程 gOMP的MATLAB实现 一维信号的实验与结果 稀疏度K与重构成功概率关系的实验与结果 一.gOMP的算法流程 广义正交匹配追踪(Generalized OMP, g ...
- 浅谈压缩感知(二十五):压缩感知重构算法之分段正交匹配追踪(StOMP)
主要内容: StOMP的算法流程 StOMP的MATLAB实现 一维信号的实验与结果 门限参数Ts.测量数M与重构成功概率关系的实验与结果 一.StOMP的算法流程 分段正交匹配追踪(Stagewis ...
- 浅谈压缩感知(二十四):压缩感知重构算法之子空间追踪(SP)
主要内容: SP的算法流程 SP的MATLAB实现 一维信号的实验与结果 测量数M与重构成功概率关系的实验与结果 SP与CoSaMP的性能比较 一.SP的算法流程 压缩采样匹配追踪(CoSaMP)与子 ...
- 浅谈压缩感知(二十六):压缩感知重构算法之分段弱正交匹配追踪(SWOMP)
主要内容: SWOMP的算法流程 SWOMP的MATLAB实现 一维信号的实验与结果 门限参数a.测量数M与重构成功概率关系的实验与结果 SWOMP与StOMP性能比较 一.SWOMP的算法流程 分段 ...
- 浅谈压缩感知(二十二):压缩感知重构算法之正则化正交匹配追踪(ROMP)
主要内容: ROMP的算法流程 ROMP的MATLAB实现 一维信号的实验与结果 测量数M与重构成功概率关系的实验与结果 一.ROMP的算法流程 正则化正交匹配追踪ROMP算法流程与OMP的最大不同之 ...
- 浅谈压缩感知(十九):MP、OMP与施密特正交化
关于MP.OMP的相关算法与收敛证明,可以参考:http://www.cnblogs.com/AndyJee/p/5047174.html,这里仅简单陈述算法流程及二者的不同之处. 主要内容: MP的 ...
随机推荐
- a标签连接空标签的方法
在写页面时,想把a标签设置成空链接,方便后面数据的连接可以有几种方法. 1. <a herf=""></a> 这种方法会默认打开本页面,重新刷新一次页面. ...
- 荣耀 6 安装 SD 卡,提示:SD卡已安全移除
先前买了个 荣耀6(购买链接),自带存储只有 16G,用来一段时间后,老是提示存储不足.后来发现是 微信 等软件占用了好多存储(缓存),, 好吧,在京东上买了个 64G 扩展卡(购买链接),安装过程如 ...
- stanford CS DB 课程 数据库系统实现
http://infolab.stanford.edu/db_pages/classes.html CS145: Introduction to Databases CS245: Databa ...
- OFbiz--简单介绍
一.简单介绍 OFBiz是一个很著名的电子商务平台,是一个很著名的开源项目,提供了创建基于最新J2EE/XML规范和技术标准,构建大中型企业级.跨平台.跨数据库.跨应用server的多层.分布式电子商 ...
- 国内打不开onedrive,怎么办?
Onedrive不能正常连接使用是由于DNS遭到污染闹的,其上传和下载文件慢也是DNS遭到污染闹的. 方法/步骤 在C盘windows/system32/drivers/etc/hosts下,用记 ...
- 在Visual Studio中使用用例图描述参与者与用例的关系
在"在Visual Studio中使用用例图描述系统与参与者间的关系"中,使用用例图表示参与者与系统的关系,本篇体验参与者与用例(参与者要做的事情)的关系. 首先创建有关Custo ...
- C# 连接Oracle数据库,免安装oracle客户端
一.方案1 首先下面的内容,有待我的进一步测试和证实.18.12.20 被证实了,还需要安装Oracle客户端,或者本机上安装oracle数据库软件. 18.12.20 1.下载Oracle.Mana ...
- ADB环境变量的配置
第一步,打开环境变量配置窗口.右击计算机,属性-高级系统设置-环境变量. 第二步,添加android系统环境变量.在系统变量下点击新建按钮,输入环境变量名ADB(自己随便写) 变 ...
- 《Linux系统编程(第2版)》
<Linux系统编程(第2版)> 基本信息 作者: (美)Robert Love 译者: 祝洪凯 李妹芳 付途 出版社:人民邮电出版社 ISBN:9787115346353 上架时间:20 ...
- java通过Stream对list集合分组
java通过Stream对list集合分组 现在有一个List集合,想对该集合中的数据分组处理,想到java8中的stream,就搞来试试,非常给力!例子如下 1 2 3 4 5 6 7 8 9 10 ...