Spark(Hive) SQL中UDF的使用(Python)【转】
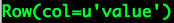
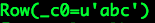
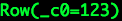





Spark(Hive) SQL中UDF的使用(Python)【转】的更多相关文章
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
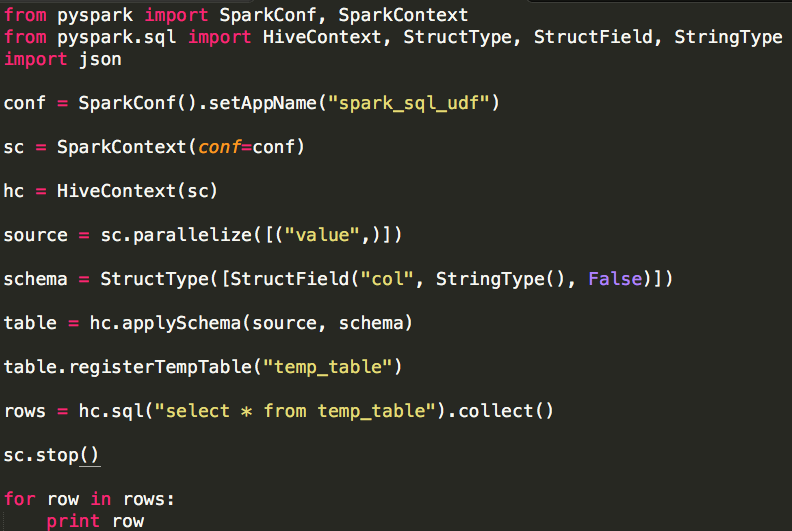
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
- Spark SQL中UDF和UDAF
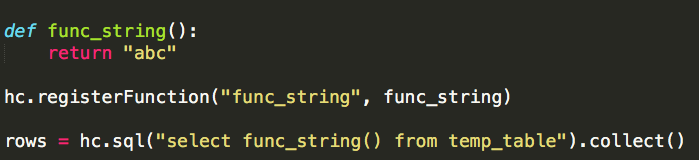
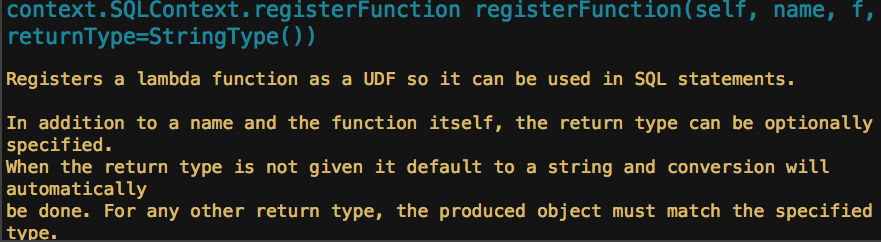
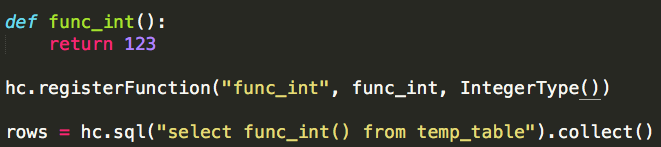
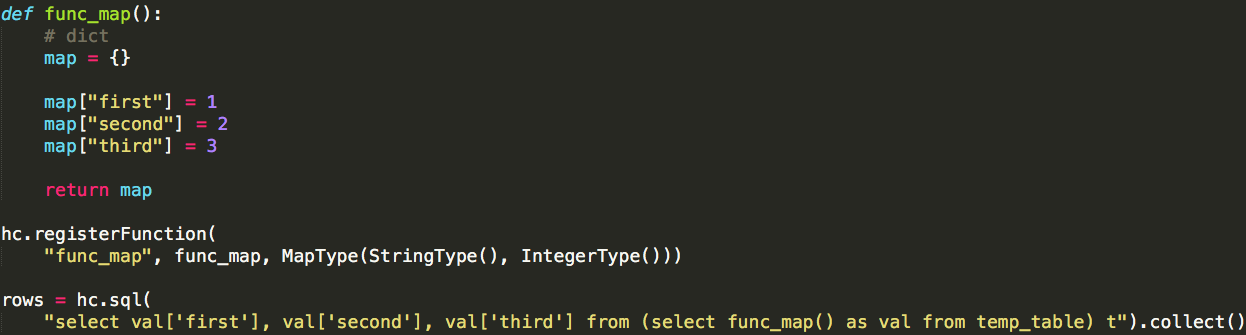
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- 两种方式— 在hive SQL中传入参数
第一种: sql = sql.format(dt=dt) 第二种: item_third_cate_cd_list = " 发发发 " ...... ""&qu ...
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
随机推荐
- hql语句的case when then else end问题
http://www.iteye.com/problems/4499 hibernate count不支持case when?
- Geocoding java调用百度地图API v2.0 图文 实例( 解决102错误)
如何使用? 第一步:申请ak(即获取密钥),若无百度账号则首先需要注册百度账号. 第二步,拼写发送http请求的url,注意需使用第一步申请的ak. 第三步,接收http请求返回的数据(支持json和 ...
- Lua协程学习
按照书上码了下,但运行有问题,暂时不知道原因: function send (x) coroutine.yield(x) end function producer() return coroutin ...
- Linux按照CPU、内存、磁盘IO、网络性能监测【转载】
本文转载地址:https://my.oschina.net/chape/blog/159640 系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监 ...
- 怎样看待IT界业务,技术,管理的各自比重
怎样看待IT界业务,技术,管理的各自比重 技术是根本,业务是个人能力的体现,管理一般随意,追求简单,眼光向IBM等有优秀管理经验的大公司看齐 重点从个人的喜好.性格方面来考虑分配比重,可以加上 ...
- Fedora 20 安装搜狗拼音输入法
1.卸载ibus sudo yum remove ibus gsettings set org.gnome.settings-daemon.plugins.keyboard active fal ...
- 【MAVEN】如何在Eclipse中创建MAVEN项目
目录结构: contents structure [+] 1,Maven简介 2,Maven安装 2.1,下载Maven 2.2,配置环境变量 2.3,测试 3,Maven仓库 3.1,Maven仓库 ...
- 【java】自定义异常类
目录结构: contents structure [+] 为什么需要自定义异常类 自定义异常的方式 实例 日常日志 一,为什么需要自定义异常类 当java中的异常类型没有能够满足我们所需的异常的时候就 ...
- iOS 一个小动画效果-b
近期工作不忙,来一个需求感觉棒棒的,是一个比较简单的页面,如下图(图1) 图1 应该很简单吧,没什么大的功能,就是一个展示,一个拨打电话,拨打电话不需要说,几行代码搞定,基本UI也不用说了,刚培训完的 ...
- [企业化NET]Window Server 2008 R2[2]-SVN 服务端 和 客户端 安装
1. 服务器基本安装即问题解决记录 √ 2. SVN环境搭建和客户端使用 2.1 服务端 和 客户端 安装 √ 2.2 项目建立与基本使用 √ 2.3 基本冲突解决, ...