双向链表-java完全解析
原文:https://blog.csdn.net/nzfxx/article/details/51728516
"双向链表"-数据结构算法-之通俗易懂,完全解析
1.概念的引入
相信大家都使用过各种集合来进行开发,但是较少的人会去研究其内部的存储原理和调用方法,今天我就来带大家一起学习数据结构算法:双向链表
首先我们先来了解什么是缓存,以及数据在内存中的存储方式.
1.缓存是什么
如果cup读取数据时,每次读取都是从内存再到硬盘读取,那么效率就太低了.
所以可以预先把数据存到内存,然后cup下次从内存读取即可.
2.数据在内存中的存储方式
第1种.线性
所谓线性,就是内存是连续的,举例ArrayList或者数组:
我们知道,数组存储数据的时候,当你申请100个大小,但是内存不足的时候就会导致内存不足而失败,或者即使你请求到了100个,但是你只存3个数据,那么就浪费内存了
=>优点:查找数据快(好比几个好朋友乘火车,车票都连在一起就好找了)
缺点:1,内存不足就失败;2.浪费内存(买了10张火车票,但是只有3个人乘车,那么就浪费了7张)
第2种.链接
内存是链接的(用于解决内存不足,解决线性(上面)问题的不足),比如不连续的空间也能存数据,比如买火车票,有火车票就卖给你,要几张卖几张,不连续位置的也卖.
=>优点:解决内存不足,解决内存浪费
缺点:找人比较慢(票不连续,不一定在一个车厢)
节点的属性:
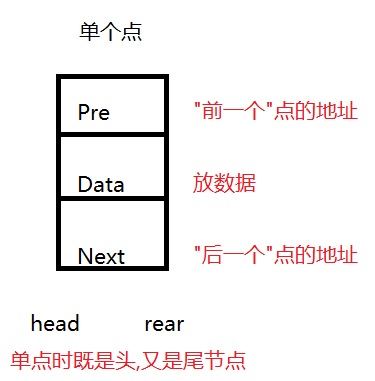
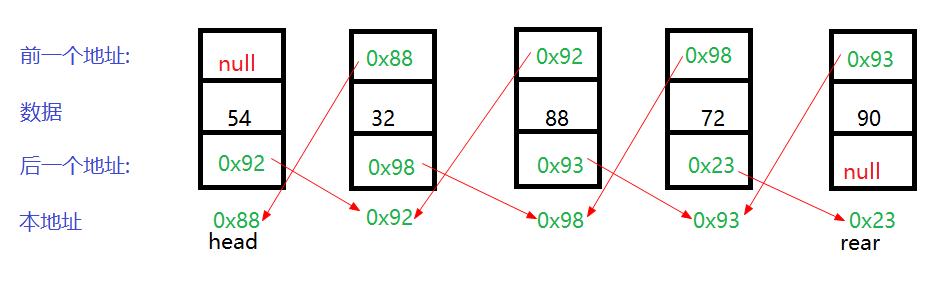
多个节点的内部构造:
代码思路
一.添加节点add(Object obj)
.Node节点属性:
prev:存放前节点(相当于地址,地址就是指针,指针就是地址)
data:Object各种数据
next:存放下节点
.定义head,rear节点,当只有一个节点,那么head和rear同指一个节点
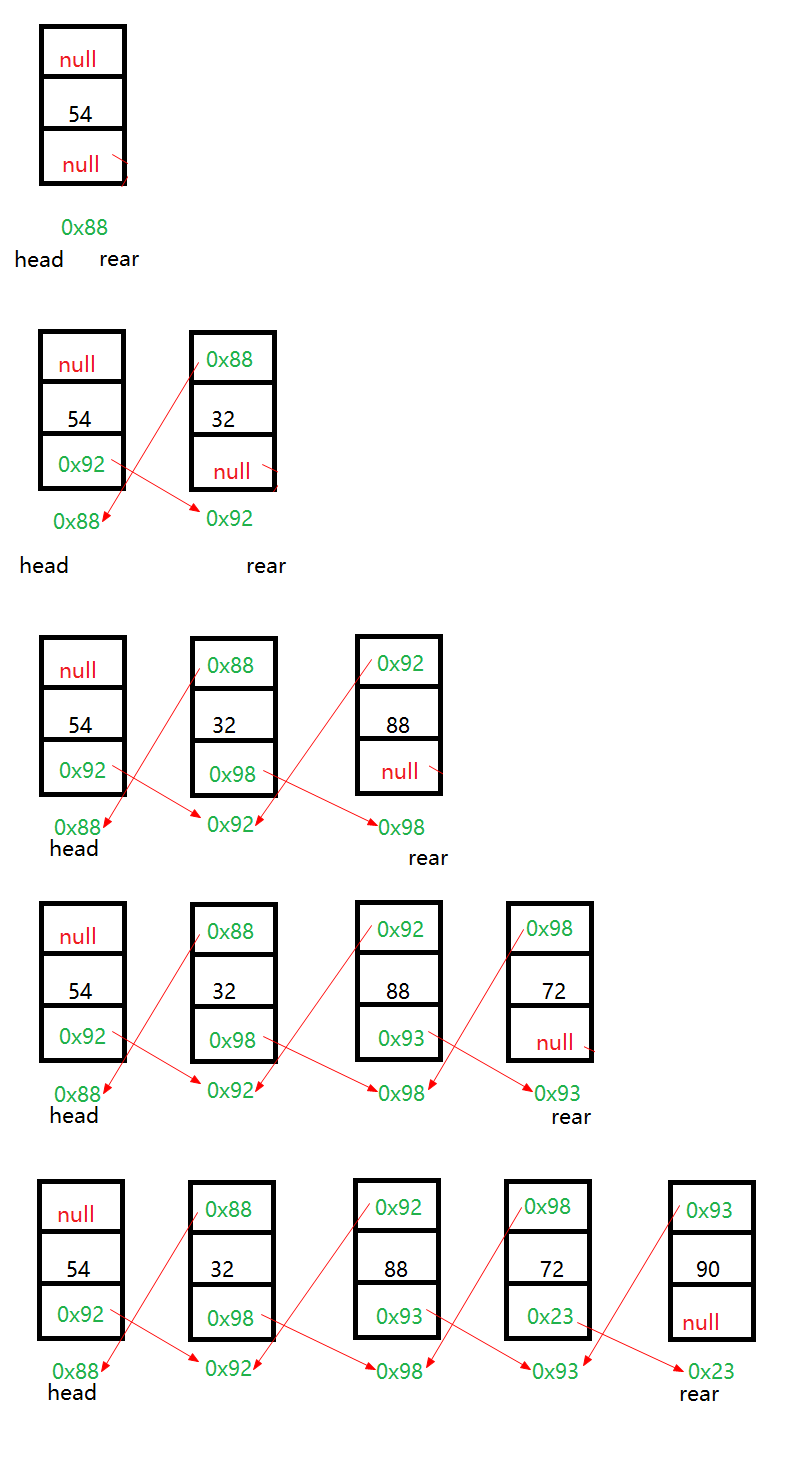
.节点添加的方法add(Object obj)
.创建节点new Node(),即每加一个数据就创一个节点
.放数据
.把节点放入链表中
.如果头结点为空,那么头结点和尾节点都指向该节点
.如果头节点不为空
.往尾部添加
原来的next指向新节点
rear.next = note;
新节点pre指向原节点,新节点也变成尾节点
note.pre = rear
(ps,有需求再设置往头部添加)
.toString方法[元素1,元素2,元素3]
while(head!=null)
if(head!=rear)append(head.data+","),***同temp代替head,否则会破坏head,影响后面的remove时head变才null了
添加节点过程图
二.删除节点数据remove(Object obj)
注意判断该节点:1.是head 2.还是 rear 3.还是中间某值 1.查找数据所在节点find(Object obj)
1.从头结点开始遍历Note temp = head
2.while循环(temp!=null) 如果找到是数据相同就停止
判断数据相同的两标准 equals 和hashCode()
否则temp = temp.next,下一个
3.返回节点
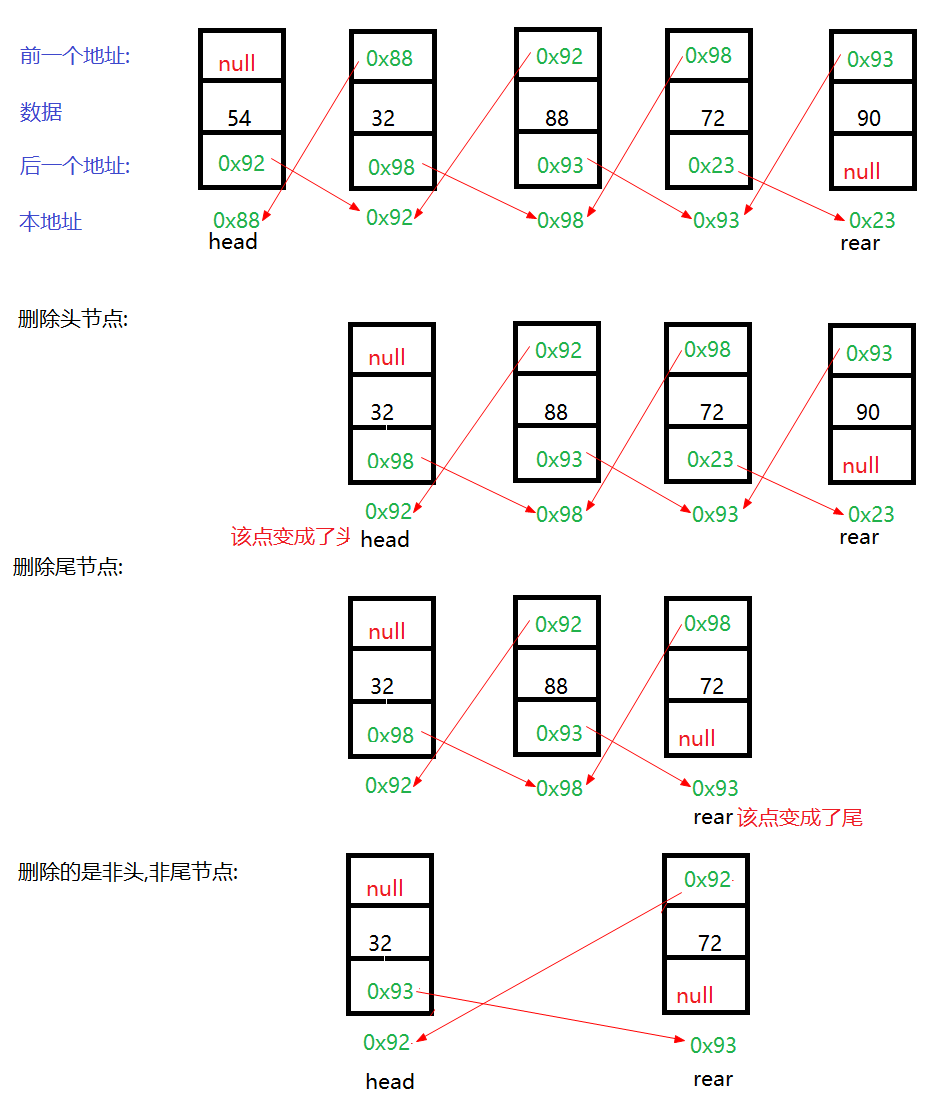
2. 确实找到一个有该数据的节点if(delete!=null),然后有4种情况如果删的是以下的
1.只有一个节点->既是头又是尾=>头尾都设空
2.是头结点=>新节点变头节点,新节点的pre变null
3.是尾节点=>新节点变尾节点,新节点的next变null
4.是其他
=>前一个节点的next=该节点的next
后一个节点的pre = 该节点的pre;
删除节点过程图
三.修改数据update(Object oldData,Object newData)
1.找到data所在的节点find(oldData);
2.如果找到的节点不为空,就把data变成newData.
四.容器中是否包含数据contains(Object data)
1.同理根据find(data)
2.返回 !note==null即可,不为空就是有包含
五.可以改成增强泛型版,把所有的Object改成T,就可以增强为选择和泛型非泛型了
双向链表的迭代器
直接增强for循环或者迭代就报错,因为没实现接口iterable,该接口是所有集合的顶级接口.
1.实现iterable
2.重写iterator方法
1.返回new Iterator()
1.hasNext()方法
返回是否有数据 Note temp = head
temp==null;
2.next()方法
1.返回temp.data
2.temp指向下一个.temp = temp.next
3.remove()方法-不改变
3.ArrayList不给在增强for循环或者迭代器中做增删改,所以自己也可用设置,根据ArrayList的设计方法,同理,设置一个变量modCount.
1.在自己的链表类成员变量定义
2.在增删改的时候++;
3.在迭代器里面设置一个标记=modCount.(此时和前面的链表操作后的情况值的大小相同);
4.迭代过程中,如果再做了增删改的操作,就抛出异常.
写在next()方法的首位,if(标记改变),也抛出concurrentMotificationExaption(不能做增删改)
经过了详细的过程讲解,下面给出详细代码
3.完整代码:
import java.util.ConcurrentModificationException;
import java.util.EmptyStackException;
import java.util.Iterator; public class DoubleLink<T> implements Iterable<T> {
public class Note {
Note prev;
T data;
Note next;
} Note head;
Note rear;
public int modCount; // 默认增在后面,可相同的写个addLast(T data);
public void add(T data) {
Note note = new Note(); // 加数据
note.data = data; // 无数据
if (head == null) {// 等同head == null && rear == null,head没有那rear肯定没有
head = note;
rear = note;
}
// 有数据,加到后面,尾节点并变成新的节点
else {
note.prev = rear;
rear.next = note;
rear = note;
}
modCount++;
} public void addFirst(T data) {
Note note = new Note();
note.data = data;
if (head == null) {
head = note;
rear = note;
} else { // 只改这里即可,note的前面变成null,next变成旧头,旧头的pre变成note,(新头变成了note,***比别把note变成新头要符合)
note.prev = null;
note.next = head;
head.prev = note;
head = note;
}
modCount++;
} // 删
public void remove(T data) {
// 找到所在数据所在节点
Note delete = find(data);
// 如果有该节点
if (delete != null) {
// 1.只有一个节点(那么该节点的pre和next都是null),都置空
if (delete.prev == null && delete.next == null) {// 等同head==rear&&rear!=null;
head = null;
rear = null;
}
// 2.是头 else
if (delete.prev == null) { // 那么原本头结点的下一个的pre就变成null,头节点变成删除节点的后一个;
delete.next.prev = null;
head = delete.next;// 反过来写(delete.next=head)就不能给head赋值了,就会删除失效
}
// 3.是尾
else if (delete.next == null) { // 尾巴的前一个的next变成null,尾巴变成新的尾巴
delete.prev.next = null;
rear = delete.prev;// 同理,不能反过来
}
// 4.是其他
else { // 删除的前面的next指向删除的next
delete.prev.next = delete.next; // 删除后面的pre = 删除的pre
delete.next.prev = delete.prev;
}
modCount++;
}
} // 改 public void update(T oldData, T newData) {
Note note = find(oldData);
note.data = newData;
modCount++;
} // 查 public boolean contains(T data) {
Note note = find(data);
return note != null;
}
// 大小 public int size() {
int count = 0;
Note temp = head;
while (temp != null) {
count++;
temp = temp.next;
}
return count;
} // 获取位置
public T get(int index) {
int size = size();// 防止超出
if (index >= size) {
throw new IndexOutOfBoundsException("没有此角标");
}
T data = null; // 定义成头
Note temp = head;
if (temp != null) {
if (index == 0) {
data = temp.data;
} else {
for (int i = 0; i < index; i++) {// 1的时候是第下一个,2的时候是下一个的下一个;
data = temp.next.data;
}
}
}
return data;
} @Override
public Iterator<T> iterator() {
return new Iterator<T>() {
Note temp = head;
int flag = modCount; @Override
public boolean hasNext() {// 判断是否有值,即判空
return temp != null;
} @Override
public T next() {// 返回具体数据
T data = temp.data;
temp = temp.next;
// 关键:取值后变成下一个节点
// 发现迭代的过程中有改动
if (flag != modCount) {
throw new ConcurrentModificationException("迭代过程不能修改");
}
return data;
} @Override
public void remove() {
} };
} /*--------------自定义堆栈,增加一个push,和poll尾部获取并移除--------------*/ public void push(T data) {
add(data);
} // 获取并从尾部移除 public T poll() {
T data = null;
Note temp = rear;// 从尾部拿;
if (temp != null) {
data = temp.data;
// 移除
if (rear.prev != null) {
// 前面有节点
rear.prev.next = null;
rear = rear.prev;
} else {
// 前面没节点 rear = null;
head = null; }
} else {
throw new EmptyStackException();
}
return data;
} private Note find(T data) {
Note temp = head;
while (temp != null) { // System.out.println("data = " + data);//1234
// System.out.println("temp.data = " + temp.data);//1234
// System.out.println(1234 == 1234);//true
// System.out.println(temp.data == data);//false ,因为data是T泛型
// System.out.println(temp.data.equals(1234));//true
// System.out.println(temp.data.equals(data));//true
// 等于当前,返回当前
if (temp.data.equals(data) && temp.data.hashCode() == data.hashCode()) {
// 判断相同请用equals,发现用==有的数据居然不生效;最正规的方法是用equals+hashCode()==data.hashCode();
return temp;
} else { // 否则往下找,找不到可能为空,即没有下一个
temp = temp.next;
} /*
* ==操作比较的是两个变量的值是否相等,对于引用型变量表示的是两个变量在堆中存储的地址是否相同,即栈中的内容是否相同。
* equals操作表示的两个变量是否是对同一个对象的引用,即堆中的内容是否相同。**==比较的是2个对象的地址,而equals比较的是2个对象的内容。显然,
* 当equals为true时,==不一定为true;
*/
}
return temp;
} @Override
public String toString() {
StringBuilder ms = new StringBuilder("[");
Note temp = head;
while (temp != null) {
if (temp != rear) {
ms.append(temp.data + ",");
} else {
ms.append(temp.data);
}
temp = temp.next;
}
return ms + "]";
}
}
下面我们通过创建测试类来测试代码的各项功能
public class test6 {
public static void main(String[] args) {
Demo07_DoubleLink<Integer> dl = new Demo07_DoubleLink();
/*--------------增后add--------------*/
dl.add(123);
dl.add(12345);
/*--------------增前addFirst--------------*/
dl.addFirst(77);
dl.addFirst(717);
System.out.println(dl);
/*--------------删remvove--------------*/
dl.remove(12345);
dl.remove(717);
System.out.println(dl);
/*--------------改update--------------*/
dl.update(77, 707);
System.out.println(dl);
/*--------------查contains--------------*/
System.out.println("contains 123 ? " + dl.contains(123));
/*--------------获取大小size--------------*/
int size = dl.size();
System.out.println("size = " + size);
/*--------------获取元素get--------------*/
int i0 = dl.get(1);
int i1 = dl.get(0);
// int i7 = dl.get(8);
System.out.println("get : " + i0);
System.out.println("get : " + i1);
/*--------------迭代+增强for循环--------------*/
// System.out.println("get : " + i7);
// 迭代
// for (Integer i : dl) {
// System.out.println(i);
// }
// Iterator<Integer> iterator = dl.iterator();
// while (iterator.hasNext()) {
// Integer data = iterator.next();
// if (data.equals(707)) {
// dl.remove(data);
// }
// System.out.println(data);
// }
/*--------------自定义堆栈--------------*/
System.out.println("----------------------自定义堆栈,并且自己加异常--------------------");
int poll = dl.poll();
System.out.println(poll);
System.out.println(dl);
System.out.println(dl.poll());
System.out.println(dl);
}
}
打印结果:
--------------------往后面添加--------------------
[123,12345]
--------------------往前面增加--------------------
[717,77,123,12345]
--------------------移除方法----------------------
[77,123]
--------------------修改方法----------------------
[707,123]
--------------------判断是否包含方法---------------
contains 123 ? true
--------------------获取大小的方法-----------------
size = 2
--------------------获取元素----------------------
get : 123 get : 707
-------------------迭代和增强for循环--------------
-------------------自定义堆栈,并且自己加异常--------
123
[707]
707
[]
总结
以上就是双链表的相关学习,大家只要记住一下几点即可: 1.节点的3个属性pre,data,next
2.头节点和尾节点head,rear
3.要完成迭代,需要让类继承Iterable,仿制迭代过程不可修改
双向链表-java完全解析的更多相关文章
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- java基础解析系列(十)---ArrayList和LinkedList源码及使用分析
java基础解析系列(十)---ArrayList和LinkedList源码及使用分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder jav ...
- Java Sax解析
一. Java Sax解析是按照xml文件的顺序一步一步的来解析,在解析xml文件之前,我们要先了解xml文件的节点的种类,一种是ElementNode,一种是TextNode.如下面的这段boo ...
- Java XML解析工具 dom4j介绍及使用实例
Java XML解析工具 dom4j介绍及使用实例 dom4j介绍 dom4j的项目地址:http://sourceforge.net/projects/dom4j/?source=directory ...
- Java泛型解析(03):虚拟机运行泛型代码
Java泛型解析(03):虚拟机运行泛型代码 Java虚拟机是不存在泛型类型对象的,全部的对象都属于普通类,甚至在泛型实现的早起版本号中,可以将使用泛型的程序编译为在1.0虚拟机上可以执行的 ...
- java socket解析和发送二进制报文工具(附java和C++转化问题)
解析: 首先是读取字节: /** * 读取输入流中指定字节的长度 * <p/> * 输入流 * * @param length 指定长度 * @return 指定长度的字节数组 */ pu ...
- Java XML解析器
使用Apache Xerces解析XML文档 一.技术概述 在用Java解析XML时候,一般都使用现成XML解析器来完成,自己编码解析是一件很棘手的问题,对程序员要求很高,一般也没有专业厂商或者开源组 ...
- java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别
java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别 目录 java基础解析系列(一)---String.StringBuffer.St ...
- java基础解析系列(六)---深入注解原理及使用
java基础解析系列(六)---注解原理及使用 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)---Integer ja ...
随机推荐
- RESTful API 学习
/********************************************************************************* * RESTful API 学习 ...
- 转:如何解决VC "应用程序无法启动,因为应用程序的并行配置不正确 sxstrace.exe"问题
如何解决VC "应用程序无法启动,因为应用程序的并行配置不正确 sxstrace.exe"问题 引用链接 http://blog.csdn.net/pizi0475/artic ...
- mos如何工作参考地址
https://wenku.baidu.com/view/c118c3fb360cba1aa811da9d.html?qq-pf-to=pcqq.c2c
- 王垠:完全用Linux工作 - imsoft.cnblogs
完全用Linux工作,抛弃windows 我已经半年没有使用 Windows 的方式工作了.Linux 高效的完成了我所有的工作. GNU/Linux 不是每个人都想用的.如果你只需要处理一般的事务, ...
- 30秒让让你的电脑快一倍 - 计算机基础 - 中国红客联盟 - Powered
一.清理垃圾 在Windows在安装和使用过程中都会产生相当多的垃圾文件,包括临时文件(如:*.tmp.*._mp)日志文件(*.log).临时帮助文件(*.gid).磁盘检查文件(*.chk).临时 ...
- CTF之猪圈密码
猪圈密码又称济会密码,朱高密码,是一种简单的替代密码,所以安全性很低
- stenciljs 学习六 组件开发样式指南
组件不是动作,最好使用名词而不是动词, 文件结构 每个文件一个组件. 每个目录一个组件.虽然将类似的组件分组到同一目录中可能是有意义的,但我们发现当每个组件都有自己的目录时,更容易记录组件. 实现(. ...
- PowerCollections
Wintellect 的Power collections 库 BigList<String> str = new BigList<String>(); str.Add(&qu ...
- Cocos2D-X2.2.3学习笔记13(延时动作)
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/q269399361/article/details/28265477 还记得我们上一节讲的瞬时动作吗 ...
- xml时间配置
这些星号由左到右按顺序代表 : * * * * * * * 秒 分 时 日 月 周 年 序号 说明 是否必填 允许填写的值 允许的通配符 秒 是 0-59 , - * / 分 是 0-59 , - * ...