K-means算法原理
聚类的基本思想
俗话说"物以类聚,人以群分"
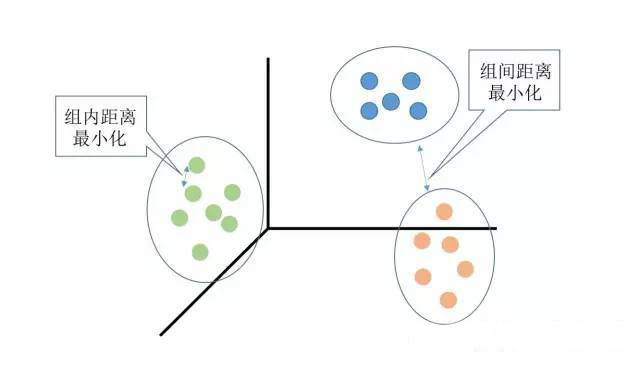
聚类(Clustering)是一种无监督学习(unsupervised learning),简单地说就是把相似的对象归到同一簇中。簇内的对象越相似,聚类的效果越好。
定义:给定一个有个对象的数据集,聚类将数据划分为个簇,而且这个划分满足两个条件:(1)每个簇至少包含一个对象;(2)每个对象属于且仅属于一个簇。
基本思想:对给定的,算法首先给出一个初始的划分方法,以后通过反复迭代的方法改变划分,使得每一次改进之后的划分方案都较前一次更好。
监督学习(supervised learning):是对具有概念标记(分类)的训练样本进行学习,以尽可能对训练样本集外的数据进行标记(分类)预测。【神经网络和决策树】
无监督学习(unsupervised learning):是对没有概念标记(分类)的训练样本进行学习,以发现训练样本集中的结构性知识。【聚类】
K-均值(K-means)聚类算法
聚类分析(cluster analysis)试图将相似对象归入同一簇,将不相似对象归到不同簇。
K-Means: K-均值聚类也称为快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。该算法原理简单并便于处理大量数据。
K-中心点:K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
系统聚类:也称为层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适合在小数据量的时候使用,数据量大的时候速度会非常慢。
K-Means算法
K-Means算法是最为经典的基于划分的聚簇方法,是十大经典数据挖掘算法之一。简单的说K-Means就是在没有任何监督信号的情况下将数据分为K份的一种方法。聚类算法就是无监督学习中最常见的一种,给定一组数据,需要聚类算法去挖掘数据中的隐含信息。聚类算法的应用很广:顾客行为聚类,google新闻聚类等。
K值是聚类结果中类别的数量。简单的说就是我们希望将数据划分的类别数
一、K-Means算法基本思想
在数据集中根据一定策略选择K个点作为每个簇的初始中心,然后观察剩余的数据,将数据划分到距离这K个点最近的簇中,也就是说将数据划分成K个簇完成一次划分,但形成的新簇并不一定是最好的划分,因此生成的新簇中,重新计算每个簇的中心点,然后在重新进行划分,直到每次划分的结果保持不变。在实际应用中往往经过很多次迭代仍然达不到每次划分结果保持不变,甚至因为数据的关系,根本就达不到这个终止条件,实际应用中往往采用变通的方法设置一个最大迭代次数,当达到最大迭代次数时,终止计算。
二、算法实现
具体的算法步骤如下:
- 随机选择K个中心点
- 把每个数据点分配到离它最近的中心点;
- 重新计算每类中的点到该类中心点距离的平均值
- 分配每个数据到它最近的中心点;
- 重复步骤3和4,直到所有的观测值不再被分配或是达到最大的迭代次数(R把10次作为默认迭代次数)。
K-means聚类能处理比层次聚类更大的数据集。另外,观测值不会永远被分到一类中,当我们提高整体解决方案时,聚类方案也会改动。不过不同于层次聚类的是,K-means会要求我们事先确定要提取的聚类个数
适用范围及缺陷
K-Menas算法试图找到使平方误差准则函数最小的簇。当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想。对于处理大数据集合,该算法非常高效,且伸缩性较好。
但该算法除了要事先确定簇数K和对初始聚类中心敏感外,经常以局部最优结束,同时对“噪声”和孤立点敏感,并且该方法不适于发现非凸面形状的簇或大小差别很大的簇。
克服缺点的方法:使用尽量多的数据;使用中位数代替均值来克服outlier的问题。
三、K-Means R语言实战
一般情况下,没有必要自己实现K-Means算法,有很多成熟的软件包实现了K-Means算法,R语言提供了kmeans方法进行聚类分析。
kmeans(x, centers, iter.max = 10, nstart = 1, algorithm = c("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen"), trace=FALSE)
# centers为提取的聚类数目进行K-Means划分时,首先要确定划分簇数K,如果对数据有先验性认知可根据对数据的认知确定K,在对数据没有先验性认知的情况下,通常通过数据可视化方法确定K值。我们以机器学习中常用的iris数据集为例演示如何进行K-Means聚类分析。首先使用主成分分析(PCA)等降维方法将数据将降维投影到二维平面上,通过人工观察确定划分数。
library(ggplot2)
library(ggfortify) #使用ggfortify包进行聚类结果的可视化展示
newiris <- iris;
newiris$Species <- NULL;
autoplot(prcomp(newiris))
通过上面的图形可清晰的看到,数据被划分成两部分,所以K至少大于2,尽管左右两边的数据被清晰的分开,但每部分数据是否还可以进一步划分成小聚簇呢,从图上看不出来。回顾一下K-Means的思想,每个簇内间距尽可能小,我们尝试使用不同划分数K进行K-Means聚类,看看不同划分的簇内间距变化情况。
wss <- c(1:15)
for(i in 1:15) wss[i] <- sum(kmeans(newiris,i)$withinss)
plot(wss)
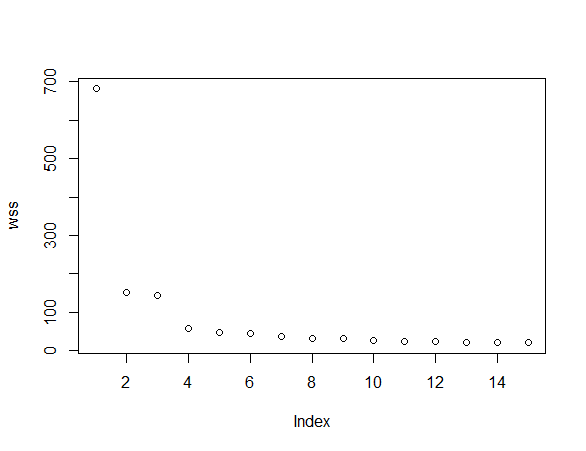
从图中可见,划分数在4-15之间,簇内间距变化很小,基本上是水平直线,因此可以选择K=4(拐点附近位置)作为划分数。聚类计算完成后,我们使用mds方法观察一下聚类结果。
newiris <- iris;
newiris$Species <- NULL;
dist.e <- dist(newiris,method='euclidean') #计算各观测值之间的欧式距离
mds <- cmdscale(dist.e, k=2, eig=T) #cmdscale()计算MDS,为可视化,取前两个主坐标
x <- mds$points[,1]
y <- mds$points[,2]
k <- kmeans(newiris, 4)
ggplot(data.frame(x,y), aes(x,y)) + geom_point(aes(colour = factor(k$cluster))) 
从图中可以观察到,数据被清晰的划分为4个不同的区域。
r语言中使用dist(x, method = "euclidean",diag = FALSE, upper = FALSE, p = 2) 来计算距离。其中x是样本矩阵或者数据框。method表示计算哪种距离。method的取值有:
euclidean 欧几里德距离,就是平方再开方。
maximum 切比雪夫距离
manhattan 绝对值距离
canberra Lance 距离
minkowski 明科夫斯基距离,使用时要指定p值
binary 定性变量距离.
定性变量距离: 记m个项目里面的 0:0配对数为m0 ,1:1配对数为m1,不能配对数为m2,距离=m1/(m1+m2);
diag 为TRUE的时候给出对角线上的距离。upper为TURE的时候给出上三角矩阵上的值。
四、更进一步
从上面的内容中,我们知道K-Means通过数据间距远近来进行划分操作,对于数值型数据而言,很容易通过欧几里得距离计算数据间的距离,对于分类等类型的数据则无法通过欧几里得距离计算数据的距离。韩家炜教授所著的《数据挖掘 概念与技术》2.4 度量数据的相似性和相异性章节中给出了计算数据间距的具体方法,需要时可按照书中方法进行数据间距计算。
需要说明的是,R语言中的kmeans函数只能接受数值型数据,如果需要对分类等类型的数据进行聚类计算,只能自己实现K-Means算法了,先计算数据距离,然后在编写K-Means算法进行聚类计算。值得一提的是在R语言中使用edit(kmeans)可以查看kmeans方法的源代码,可以参照源代码实现定制的K-Means算法。
欧几里德距离矩阵

K-Means的细节问题
K值怎么定?我怎么知道应该几类?
答:这个真的没有确定的做法,分几类主要取决于个人的经验与感觉,通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。或者可以把各种K值算出的SSE做比较,取最小的SSE的K值。初始的K个质心怎么选?
答:最常用的方法是随机选,初始质心的选取对最终聚类结果有影响,因此算法一定要多执行几次,哪个结果更reasonable,就用哪个结果。 当然也有一些优化的方法,第一种是选择彼此距离最远的点,具体来说就是先选第一个点,然后选离第一个点最远的当第二个点,然后选第三个点,第三个点到第一、第二两点的距离之和最小,以此类推。第二种是先根据其他聚类算法(如层次聚类)得到聚类结果,从结果中每个分类选一个点。K-Means会不会陷入一直选质心的过程,永远停不下来?
答:不会,有数学证明K-Means一定会收敛,大致思路是利用SSE的概念(也就是误差平方和),即每个点到自身所归属质心的距离的平方和,这个平方和是一个函数,然后能够证明这个函数是可以最终收敛的函数。判断每个点归属哪个质心的距离怎么算?
答:这个问题必须不得不提一下数学了……
第一种,欧几里德距离(欧几里德这位爷还是很厉害的,《几何原本》被称为古希腊数学的高峰,就是用5个公理推导出了整个平面几何的结论),这个距离就是平时我们理解的距离,如果是两个平面上的点,也就是(X1,Y1),和(X2,Y2),那这俩点距离是多少初中生都会,就是√( (x1-x2)^2+(y1-y2)^2) ,如果是三维空间中呢?√( (x1-x2)^2+(y1-y2)^2+(z1-z2)^2 ;推广到高维空间公式就以此类推。可以看出,欧几里德距离真的是数学加减乘除算出来的距离,因此这就是只能用于连续型变量的原因。
第二种,余弦相似度,余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。下图表示余弦相似度的余弦是哪个角的余弦,A,B是三维空间中的两个向量,这两个点与三维空间原点连线形成的角,如果角度越小,说明这两个向量在方向上越接近,在聚类时就归成一类: cosine
cosine看一个例子(也许不太恰当):歌手大赛,三个评委给三个歌手打分,第一个评委的打分(10,8,9) 第二个评委的打分(4,3,2),第三个评委的打分(8,9,10)
如果采用余弦相似度来看每个评委的差异,虽然每个评委对同一个选手的评分不一样,但第一、第二两个评委对这四位歌手实力的排序是一样的,只是第二个评委对满分有更高的评判标准,说明第一、第二个评委对音乐的品味上是一致的。
因此,用余弦相似度来看,第一、第二个评委为一类人,第三个评委为另外一类。
如果采用欧氏距离, 第一和第三个评委的欧氏距离更近,就分成一类人了,但其实不太合理,因为他们对于四位选手的排名都是完全颠倒的。
总之,如果注重数值本身的差异,就应该用欧氏距离,如果注重的是上例中的这种的差异(我概括不出来到底是一种什么差异……),就要用余弦相似度来计算。
还有其他的一些计算距离的方法,但是都是欧氏距离和余弦相似度的衍生,简单罗列如下:明可夫斯基距离、切比雪夫距离、曼哈顿距离、马哈拉诺比斯距离、调整后的余弦相似度、Jaccard相似系数……还有一个重要的问题是,大家的单位要一致!
比如X的单位是米,Y也是米,那么距离算出来的单位还是米,是有意义的
但是如果X是米,Y是吨,用距离公式计算就会出现“米的平方”加上“吨的平方”再开平方,最后算出的东西没有数学意义,这就有问题了。
还有,即使X和Y单位一致,但是如果数据中X整体都比较小,比如都是1到10之间的数,Y很大,比如都是1000以上的数,那么,在计算距离的时候Y起到的作用就比X大很多,X对于距离的影响几乎可以忽略,这也有问题。
因此,如果K-Means聚类中选择欧几里德距离计算距离,数据集又出现了上面所述的情况,就一定要进行数据的标准化(normalization),即将数据按比例缩放,使之落入一个小的特定区间。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行计算和比较。
标准化方法最常用的有两种:- min-max标准化(离差标准化):对原始数据进行线性变换,是结果落到【0,1】区间,转换方法为 X'=(X-min)/(max-min),其中max为样本数据最大值,min为样本数据最小值。
- z-score标准化(标准差标准化):处理后的数据符合标准正态分布(均值为0,方差为1),转换公式:X减去均值,再除以标准差
每一轮迭代如何选出新的质心?
答:各个维度的算术平均,比如(X1,Y1,Z1)、(X2,Y2,Z2)、(X3,Y3,Z3),那就新质心就是【(X1+X2+X3)/3,(Y1+Y2+Y3)/3,(Z1,Z2,Z3)/3】,这里要注意,新质心不一定是实际的一个数据点。关于离群值?
答:离群值就是远离整体的,非常异常、非常特殊的数据点,在聚类之前应该将这些“极大”“极小”之类的离群数据都去掉,否则会对于聚类的结果有影响。但是,离群值往往自身就很有分析的价值,可以把离群值单独作为一类来分析。用SPSS作出的K-Means聚类结果,包含ANOVA(单因素方差分析),是什么意思?
答:答简单说就是判断用于聚类的变量是否对于聚类结果有贡献,方差分析检验结果越显著的变量,说明对聚类结果越有影响。对于不显著的变量,可以考虑从模型中剔除。

参考:https://my.oschina.net/polaris16/blog/801889
http://blog.csdn.net/yucan1001/article/details/23123043
http://www.jianshu.com/p/fc91fed8c77b
K-means算法原理的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- K临近算法
K临近算法原理 K临近算法(K-Nearest Neighbor, KNN)是最简单的监督学习分类算法之一.(有之一吗?) 对于一个应用样本点,K临近算法寻找距它最近的k个训练样本点即K个Neares ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- kmeans算法原理以及实践操作(多种k值确定以及如何选取初始点方法)
kmeans一般在数据分析前期使用,选取适当的k,将数据聚类后,然后研究不同聚类下数据的特点. 算法原理: (1) 随机选取k个中心点: (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为 ...
- LruCache算法原理及实现
LruCache算法原理及实现 LruCache算法原理 LRU为Least Recently Used的缩写,意思也就是近期最少使用算法.LruCache将LinkedHashMap的顺序设置为LR ...
- OpenGL学习进程(13)第十课:基本图形的底层实现及算法原理
本节介绍OpenGL中绘制直线.圆.椭圆,多边形的算法原理. (1)绘制任意方向(任意斜率)的直线: 1)中点画线法: 中点画线法的算法原理不做介绍,但这里用到最基本的画0<=k ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
随机推荐
- 爬虫之 案列1补充(pipelines优化)
1. 先打开settings.py文件将 'ITEM_PIPELINES'启动(取消注释即可) 2. spider代码 # -*- coding: utf-8 -*- import scrapy im ...
- Fire! -两次dfs
题目描述: Joe works in a maze. Unfortunately, portions of the maze have caught on fire, and the owner of ...
- 一种表达式语言的解析引擎JEXL简单使用
Jexl 是一个 Expression Language 的解析引擎, 是为了方便嵌入你的系统或者程序框架的开发中, 他算是实现了 JSTL 中 EL 的延伸版本. 不过也采用了一些 Velocity ...
- tar 打包压缩
tar命令详解 -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用 ...
- ubantu 执行sudo apt-get update 出现校验不符问题
一直被这个问题困扰,今天安装mongodb时,看了别人博客暂时解决了,不知道会不会出什么问题. 直接打开软件更新器: 然后点击其他软件,去掉两个独立的多选项: 再执行一遍 sudo apt-get u ...
- Java笔记(十九) 反射
反射 反射是在运行时获取类型的信息,再根据这些信息进行操作. 一.Class类 每个已加载的类在内存中都有一份类信息,每个对象都有指向它的类信息的引用. 在Java中,类信息对应的类就是java.la ...
- [USACO07NOV]牛栏Cow Hurdles
OJ题号:洛谷2888 思路:修改Floyd,把边权和改为边权最大值.另外注意是有向图. #include<cstdio> #include<algorithm> using ...
- 考前停课集训 Day5 累
Day 5 今天不考试 因此自己订正+刷题 我就当日记来写吧 昨天棕名了…… 所以借了同学的号打题 NOIP前的崩心态啊QAQ 希望一切安好
- Making the Grade [POJ3666] [DP]
题意: 给定一个序列,以最小代价将其变成单调不增或单调不减序列,代价为Σabs(i变化后-i变化前),序列长度<=2000,单个数字<=1e9 输入:(第一行表示序列长度,之后一行一个表示 ...
- 分金币 [CQOI 2011] [BZOJ 3293]
Description 圆桌上坐着n个人,每人有一定数量的金币,金币总数能被n整除.每个人可以给他左右相邻的人一些金币,最终使得每个人的金币数目相等.你的任务是求出被转手的金币数量的最小值. Inpu ...