Programming | 中/ 英文词频统计(MATLAB实现)
中英文词频统计(MATLAB)
1. 英文词频统计
英文词频统计很简单,只需借助split断句,再统计即可。
完整MATLAB代码:
function wordcount
%思路:中文词频统计涉及到对“词语”的判断,需要导入词典或编写判断规则,很复杂。
%最简单的办法是直接统计英文词频,并由空格直接划分词语。然后再翻译即可得到中文词频。
%从官方网站上下载的pdf,转成reportfulltext.txt,存到workspace进行操作 全文共25003个字符。
clc;
clear;
report=fileread('reportfulltext.txt'); %读入全文
report=regexprep(report,'\W',' '); %不是字符的,都转换为空格。主要是去除标点符号
report=lower(report); %变成小写
words=regexp(report,' ','split')'; %根据空格分隔为单词cell
%至此每个单词都拿出来了
rank = tabulate(words); %rank是三列向量,包括名称,出现次数和百分比
ans=sortrows(rank,-2); %只根据第二列进行排序 -2表示降序
xlswrite('results',ans);%输出为excel文件
end
2. 中文词频统计
中文词频统计相对复杂一些。关键在于:
使用合适的语料库
从长到短,匹配词语。比如句中出现了“计算机”三字词,我们应该将三个字视为一个词,而不能把“计算”当做一个词。
function wordcountchinese
clc;
clear;
report=fileread('reportchinese.txt'); %读入中文报告,事先已放在工作区
%% dictionary.mat是一个我事先准备好的列向量
%其中dict是14636*1的字典列向量,从网上下载的官方语料库转换得到的
load dictionary.mat;
Maxlen=max(cellfun(@length,dict)); %最大词长,结果是10
%% 按标点初步分词
cut='[\,\。\、\;\:\!\?\“\”\‘\’\(\)\《\》\<\>\……\·]'; %标点符号的正则表达式
F=regexp(report,cut,'split')'; %转置,变成3131*1的列向量
% 此时,待分析的句集F和词典都已就绪
%% 算法原理
% 首先判断是否为有效句:句长是否大于0。小于0的不操作,相当于跳过
% 若是有效句,计算句长和最大词长Maxlen的最小值maxlen。待选字串长度不能大于该长度
% 从maxlen长度开始,取出待选字串
% 匹配,成功就输出,标记。若成功,平移maxlen个单位;若不成功,平移1个单位
% 选出下一个待选字串再匹配,重复操作,直到移动到句长以外
% 如果上一个长度匹配成功,那么就不用再匹配了,该句跳过;如果meet==0,重复上一步操作
% 长度maxlen减到1,也要匹配,因为词库中有一个字的词;maxlen==0是终止信号。
%% 最大匹配法进一步分词
sentence=[]; %是粗分后F中的每一个元素
word=[];
words={};
k=1;
for i=1:length(F) %遍历F
sentence=cell2mat(F(i,1)); %把cell转换成字符串
sentence_len=length(sentence); %求出句长
meet=0; %更新初始状态
if(sentence_len>0) %有效句
maxlen=min(Maxlen,sentence_len);
while(maxlen>0)
start=1;
while((start+maxlen)<=sentence_len) %索引不能移动到句子外面
word=sentence(start:start+maxlen);
if(ismember(word,dict))%如果匹配成功
meet=1;
words(k)=cellstr(word);
k=k+1;
start=start+maxlen; %移动maxlen个单位再匹配
else
start=start+1; %移动一个单位再匹配
end
end
%已经移动到句子外面了
if(meet==0)
maxlen=maxlen-1;
else
break;
end
end
end
%无效句,句长为0,不处理,直接跳过
end
%% 排序处理
rank = tabulate(words); %rank是三列向量,包括名称,出现次数和百分比
ANS=sortrows(rank,-2); %只根据第二列进行排序 -2表示降序
xlswrite('resultschinese',ANS(1:50,1:3));%输出为excel文件 由于词语将近1777个,因此只输出前100个
end
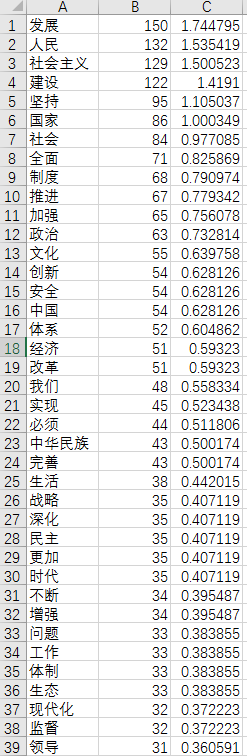
十九大中文版报告统计结果:
Programming | 中/ 英文词频统计(MATLAB实现)的更多相关文章
- 1.字符串操作:& 2.英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. ID = input('请输入十八位身份证号码: ') if len(ID) == 18: print("你的身份证号码是 " ...
- 组合数据类型,英文词频统计 python
练习: 总结列表,元组,字典,集合的联系与区别.列表,元组,字典,集合的遍历. 区别: 一.列表:列表给大家的印象是索引,有了索引就是有序,想要存储有序的项目,用列表是再好不过的选择了.在python ...
- python字符串操作、文件操作,英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 解析身份证号:生日.性别.出生地等 def function3(): print('请输入身份证号') ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- Python——字符串、文件操作,英文词频统计预处理
一.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 2.凯撒密码编码与解码 凯撒加密法的替换方法是通过排列明文和密文字母表,密文字母表示通过将明文字母表向左 ...
- python复合数据类型以及英文词频统计
这个作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753. 1.列表,元组,字典,集合分别如何增删改查及遍历. 列 ...
- 英文词频统计的java实现方法
需求概要 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 分析 1.读取文件可使用BufferedReader ...
- python:Hamlet英文词频统计
#CalHamletV1.py def getText(): #定义函数读取文件 txt = open("hamlet.txt","r").read() txt ...
- 词频统计 in office
ROSTCM6 1. http://www.writewords.org.uk/word_count.asp 2. http://darylkinsman.ca/tools/wordfreq.shtm ...
随机推荐
- [HNOI2012]射箭(计算几何)
设抛物线方程\(y = ax^2 + bx\), 那么对于一个靶子\((x_i,y_{down},y_{up})\)我们需要满足的条件就是 \(\frac{y_{down}}{x_i} \leq ax ...
- SQL Server事务
事务全部是关于原子性的.原子性的概念是指可以把一些事情当做一个单元来看待.从数据库的角度看,它是指应全部执行或全部都不执行的一条或多条语句的最小组合.为了理解事务的概念,需要能够定义非常明确的边界.事 ...
- VS2010 永久配置OpenCv2.4.9 及转换到COFF 期间失败:文件无效或损坏,解决方法
1.下载OpenCv2.4.9(win pack):http://opencv.org/releases.html 下载完成后,进行解压(win7 64位系统) 2.环境配置,配置如下图所示: 找到p ...
- Unable to complete the scan for annotations for web application [/wrs] due to a StackOverflowError. Possible root causes include a too low setting for -Xss and illegal cyclic inheritance dependencies.
tomcat启动报错:Jul 20, 2018 11:48:37 AM org.apache.catalina.core.ContainerBase addChildInternalSEVERE: C ...
- Github使用笔记——创建远程库
系统:CentOS7 一.yum install git 二.配置 git config --global user.name "XXX" git config -global u ...
- ssh服务器配置
使用如下终端命令可以在 Linux 主机中安装 ssh服务器sudo apt-get install openssh-server lin@lin-machine:~$ sudo apt-get in ...
- c#随机生成英文名
private static string GenerateSurname() { string name = string.Empty; string[] currentConson ...
- JVM系列2:垃圾收集器与内存分配策略
垃圾收集是一个很大话题,本文也只是看了深入理解Java虚拟机总结了下垃圾收集的知识. 首先按照惯例,先上思维导图: 垃圾收集简而言之就是JVM帮我们清理掉内存区域不需要的数据.它主要负责清理堆中实例对 ...
- 记账本,C,Github,Dao
package dao; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSe ...
- 数组中出现次数超过一半的数字(python)
题目描述 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字.例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}.由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2. ...