SQL Server 最大并行度
一、概念
1.关联掩码(affinitymask)
为了执行多任务,MicrosoftWindows2000和WindowsServer2003有时会在不同的处理器之间移动进程线程。虽然从操作系统方面而言,这种活动是高效的,但是在高系统负荷的情况下,该活动会降低SQLServer的性能,因为每个处理器缓存都会不断地重新加载数据。如果将各个处理器分配给特定线程,则通过消除处理器的重新加载需要以及减少处理器之间的线程迁移(因而减少上下文切换),可以提高在这些条件下的性能;线程与处理器之间的这种关联称为“处理器关联”。
SQLServer通过以下两个关联掩码选项来支持处理器关联:affinitymask(也称为CPUaffinitymask)和affinityI/Omask。对具有33到64个处理器的服务器的CPU和I/O关联支持要求分别使用affinity64mask服务器配置选项和affinity64I/Omask服务器配置选项(这2个服务器配置选项仅在64位操作系统上可用)。http://technet.microsoft.com/zh-cn/library/ms187104.aspx
注意:
SQLServer2012联机手续中提到,后续版本的SQLServer将删除该功能。请不要在新的开发工作中使用该功能,并尽快修改当前还在使用该功能的应用程序。
2.并行的开销阈值(costthresholdforparallelism)
costthresholdforparallelism选项指定SQLServer创建和运行并行查询计划的阈值。仅当运行同一查询的串行计划的估计开销高于在“并行的开销阈值”中设置的值时,SQLServer才创建和运行该查询的并行计划。开销指的是在特定硬件配置中运行串行计划估计需要花费的时间(秒)。“并行的开销阈值”选项可设置为0到32767之间的任何值。默认值为5。
3.最大并行度(maxdegreeofparallelism)
可以使用maxdegreeofparallelism选项来限制并行计划执行时所用的处理器数。SQLServer考虑为查询、索引数据定义语言(DDL)操作、静态的和由键集驱动的游标填充实施并行执行计划。
除了查询和索引操作之外,此选项还控制DBCCCHECKTABLE、DBCCCHECKDB和DBCCCHECKFILEGROUP的并行。使用跟踪标志2528,可以禁用为这些语句所做的并行执行计划。
查询执行计划如何确定最大并行度?一般按照以下准则:
(1)若要使服务器能够确定最大并行度,请将此选项设置为默认值0。
(2)若将maximumdegreeofparallelism设置为0,SQLServer将能够使用至多64个可用的处理器。
(3)若要取消生成并行计划,请将maxdegreeofparallelism设置为1。
(4)将该值设置为1到32,767之间的数值来指定执行单个查询所使用的最大处理器核数。如果指定的值比可用的处理器数大,则使用实际可用数量的处理器。
(5)如果计算机只有一个处理器,将忽略maxdegreeofparallelism值。
4.MAXDOP
您可以通过在查询语句中指定MAXDOP查询提示来覆盖查询中的maxdegreeofparallelism值。
索引操作(如创建或重新生成索引、或删除聚集索引)可能会大量占用资源。您可以通过在索引语句中指定MAXDOP索引选项来覆盖索引操作的maxdegreeofparallelism值。MAXDOP值在执行时应用于语句,但不存储在索引元数据中。http://technet.microsoft.com/zh-cn/library/ms189329.aspx
二、配置服务器配置选项
1.SSMS
在服务器(实例)的“属性”窗口选择“高级”节点。
在“最大并行度”框中,选择执行并行计划时所使用的最大处理器数。
在“并行”下,将“并行的开阀值”选项更改为所需值,键入或选择一个值(介于0到32767之间)。

2.SP_Config
在下例中,将最大并行度设置为8,将并行的开销阀值设置为10秒。
|
USEdb01; EXECsp_configure'costthresholdforparallelism',10; GO |
3.效果
在配置maxdegreeofparallelism和CostThresholdForParallelism选项之后,这些设置将立即生效,无需重新启动服务器。
三、最佳实践建议
使用sp_configure将maxdegreeofparallelism选项设置为8或小于8的值。将此选项设置为大于8的值通常导致不必要的资源消耗和性能下降。
http://support.microsoft.com/kb/329204
请遵循以下准则:
(1)对于使用8个以上的处理器的服务器使用以下配置:MAXDOP=8。
(2)服务器的有8个或更少的处理器,使用下列配置其中N等于处理器数:MAXDOP=0到N。
(3)对于具有NUMA配置的服务器,MAXDOP不应超过分配给每个NUMA节点的cpu数。
(4)超线程已启用的服务器的MAXDOP值不应超过物理处理器的数量。
本文结语:
请根据业务负荷的特点,设置关联掩码和最大并行度。根据最佳实践,最大并行度不要超过8。
注意:
另外一种关于(max degree of parallelism)的推荐设置是根据系统类型(也可以理解为系统负载)来设置,具体建议如下所示:
OLTP系统:
在纯OLTP系统上,它的事务较短,SQL查询时间短,但是非常频繁。设置“Maximum degree of Parallelism”(MAXDOP)为1。这样做可以确保查询永远不必使用并行方式运行,并且不会导致更多的数据库引擎开销。
OLAP系统:
Data-warehousing / Reporting server: 因为查询执行时间一般较长,建议设置“Maximum degree of Parallelism”(MAXDOP)为0。
这样大多数查询将会利用并行处理,执行时间较长的查询也会受益于多处理器而提高性能。
混合系统
Mixed System (OLTP & OLAP):这样环境会是一个挑战,必须找到正确的平衡点。一般采取了非常简单的方法。设置“Maximum degree of
Parallelism”(MAXDOP)为2,这样意味着查询仍会使用并行操作但是仅利用2颗CPU。并且把“并行查询阀值”(cost threshold for parallelism)设置为较高的值,这样的话,不是所有的查询都有资格使用并行,除了那些查询成本较高的查询………
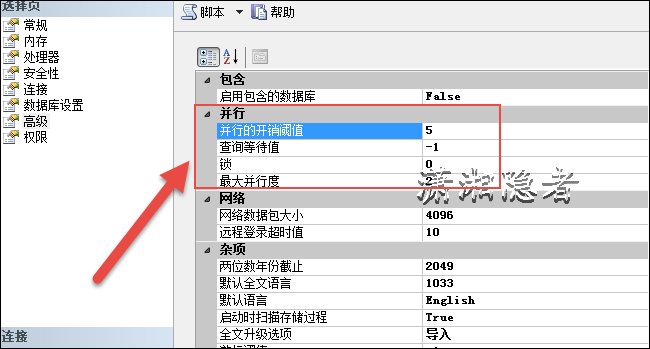
cost threshold for parallelism 选项可设置为 0 到 32767 之间的任何值。默认值为 5。
个人比较倾向于第二种(max degree of parallelism)设置的指导方针,混合系统设置max degree of parallelism,建议结合第一种推荐设置与第二种,然后结合等待事件CXPACKET的情况,作出适当的调整。不要指望一成不变的推荐设置,这样是不合理。只能根据比较大众的推荐设置,然后结合自身系统的具体情况,作出适当的调整、优化。
对于NUMA与SMP不太清楚的地方,可以参考下面资料。
传统的多核运算是使用SMP(Symmetric Multi-Processor )模式:将多个处理器与一个集中的存储器和I/O总线相连。所有处理器只能访问同一个物理存储器,因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,SMP的缺点是可伸缩性有限,因为在存储器和I/O接口达到饱和的时候,增加处理器并不能获得更高的性能。
NUMA模式是一种分布式存储器访问方式,处理器可以同时访问不同的存储器地址,大幅度提高并行性。 NUMA模式下,处理器被划分成多个"节点"(node), 每个节点被分配有的本地存储器空间。 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多。
SQL Server 2005开始支持NUMA,可参考SQL Server 2008的NUMA支持 。需要注意的是,硬件、操作系统、应用软件 三者都要支持 NUMA ,才能充分利用这一特性
SQL Server 最大并行度的更多相关文章
- SQL Server 造成cpu 使用率高的 6 原因
第一种: 编译和重编译执行计划. 第二种: 排序与聚合. 第三种: 表格连接操作. 第四种: max degree of parallelism. 第五种: max worker threads. 第 ...
- SQL Server中的“最大并行度”的配置建议
SQL Server中的最大并行度(max degree of parallelism)如何设置呢? 设置max degree of parallelism有什么好的建议和指导方针呢?在微软官方文档R ...
- SQL Server强制使用特定索引 、并行度、锁
SQL Server强制使用特定索引 .并行度 修改或删除数据前先备份,先备份,先备份(重要事情说三遍) 很多时候你或许为了测试.或许为了规避并发给你SQL带来的一些问题,常常需要强制指定目标sql选 ...
- SQL Server 执行计划缓存
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/内存池/缓冲区 概述 了解执行计划对数据库性能分析很重要,其中涉及到了语句性能分析与存储,这也是写这篇文章的目的,在了解执行计划之 ...
- SQL Server 重新组织生成索引
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引/统计信息 概述 无论何时对基础数据执行插入.更新或删除操作,SQL Server 数据库引擎都会自动维护索引.随着时间的推移 ...
- SQL Server基础之索引
索引用于快速找出在某个列中有某一特定值的行,不使用索引,数据库必须从第一条记录开始读完整个表,直到找出相关的行.表越大,查询数据所花费的时间越多,如果表中查询的列有一个索引,数据库能快速到达一个位置 ...
- 深入解析SQL Server并行执行原理及实践(上)
在成熟领先的企业级数据库系统中,并行查询可以说是一大利器,在某些场景下他可以显著的提升查询的相应时间,提升用户体验.如SQL Server, Oracle等, Mysql目前还未实现,而Postgre ...
- 深入解析SQL Server并行执行原理及实践(下)
谈完并行执行的原理,咱们再来谈谈优化,到底并行执行能给我们带来哪些好处,我们又应该注意什么呢,下面展开. Amdahl’s Law 再谈并行优化前我想有必要谈谈阿姆达尔定律,可惜老爷子去年已经驾鹤先 ...
- SQL SERVER 2014 各个版本支持的功能
转自:https://technet.microsoft.com/library/cc645993 转换箱规模限制 功能名称 Enterprise Business Intelligence Stan ...
随机推荐
- 如何使用 Visual C# .NET 处理 Excel 事件
事件处理概述 Visual C# .NET 使用委派处理来自组件对象模型 (COM) 服务器的事件.委派是 Microsoft Visual Studio .NET 中的一个新概念.对于 COM 事件 ...
- zookeeper 集群部署
参考: https://www.cnblogs.com/linuxprobe/p/5851699.html
- leetcode169
public class Solution { public int MajorityElement(int[] nums) { Dictionary<int, int> dic = ne ...
- Citrix XenApp工作原理
Citrix XenApp™作为一种Windows®应用交付系统,可在数据中心集中管理应用,并将应用按需交付给身处各地.使用各种设备的用户.利用集成的应用虚拟化技术,XenApp克服了传统应用部署方法 ...
- 尚硅谷springboot学习25-嵌入式Servlet容器
SpringBoot默认使用Tomcat作为嵌入式的Servlet容器:
- ceph结构详解
引言 那么问题来了,把一份数据存到一群Server中分几步? Ceph的答案是:两步. 计算PG 计算OSD 计算PG 首先,要明确Ceph的一个规定:在Ceph中,一切皆对象. 不论是视频,文本,照 ...
- Spark 基础之SQL 快速上手
知识点 SQL 基本概念 SQL Context 的生成和使用 1.6 版本新API:Datasets 常用 Spark SQL 数学和统计函数 SQL 语句 Spark DataFrame 文件保存 ...
- Jenkins之定时任务
H的用法: H 10 * * * ,这里H不是小时的意思,符号H(代表“Hash”,后面用“散列”代替) 符号H 在一定范围内可被认为是一个随机值,但实际上它是任务名称的一个散列而不是随机函数,每个 ...
- Teemo's tree problem
题目链接 : https://nanti.jisuanke.com/t/29228 There is an apple tree in Teemo's yard. It contains n node ...
- 【Python深入】Python中继承object和不继承object的区别
python中定义class的时候,有object和没有object的不同?例如: class Solution(object): class Solution(): 这俩的区别在于—————— 在p ...