Hue添加Spark notebook
参考自https://blogs.msdn.microsoft.com/pliu/2016/06/18/run-hue-spark-notebook-on-cloudera/
说明
使用Cloudera Manager部署CDH群集时,可以使用Hue Web UI运行Hive和Impala查询。但Spark笔记本没有开箱即用。在CDH上安装和配置Spark笔记本并不像现有文档中描述的那样简单。在本博客中,我们将提供有关如何在CDH上使用Livy启用Hue Spark笔记本的分步说明。
在撰写本文时,部署的CDH版本为5.9.3,HUE 3.11和Livy 0.3。对于使用Cloudera Manager部署的任何CDH群集,步骤应该类似。请注意,Cloudera尚不支持Livy。
1. 在cloudera manager集群中找到hue服务

2. 添加配置
在Cloudera Manager中,转到Hue - > Configurations,在hue服务高级配置代码段(安全阀)中搜索hue_safety_valve.ini的 “安全” ,添加以下配置,保存更改,然后重新启动Hue:
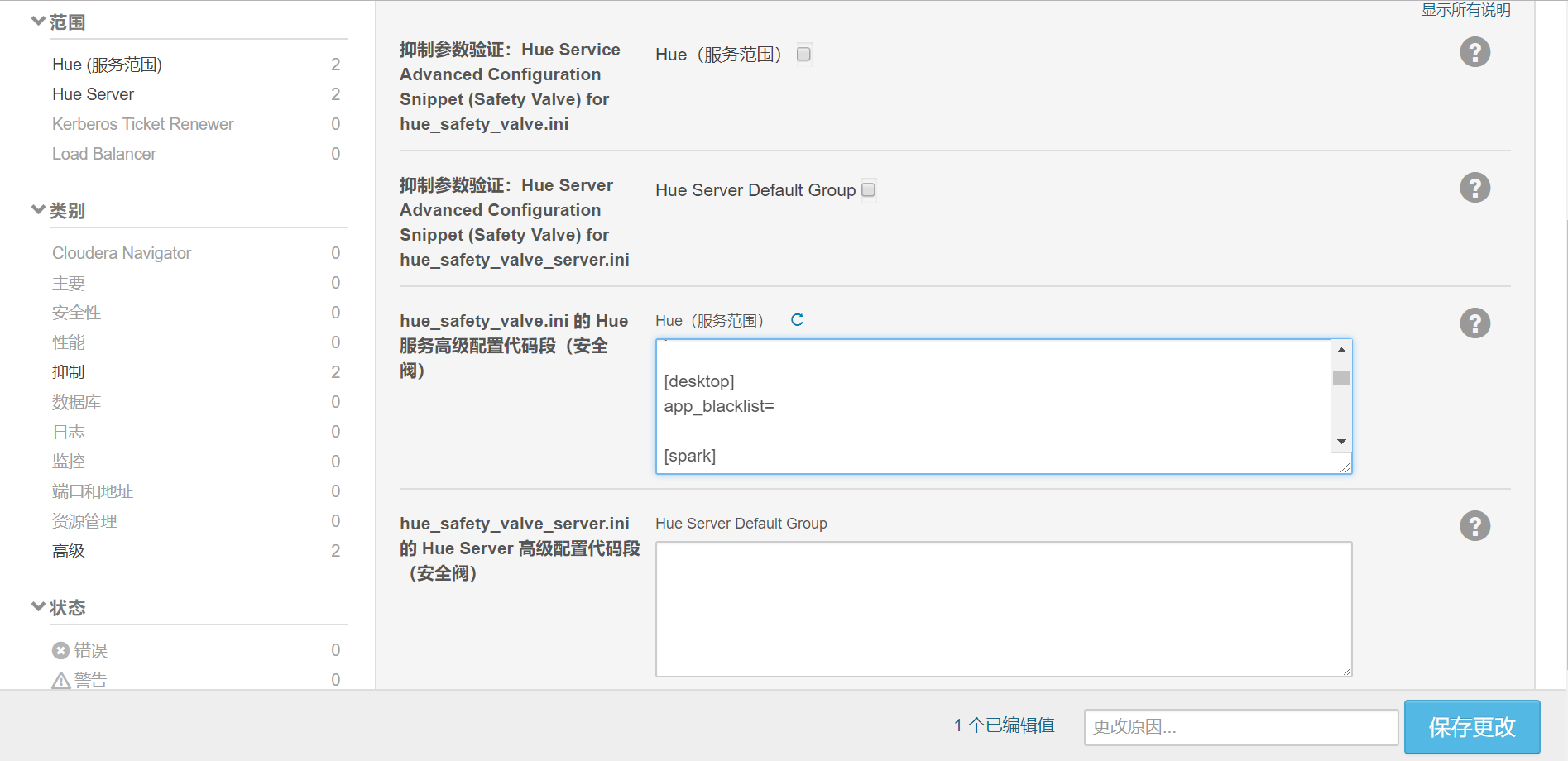
[spark]
server_url=http://fp-01:8998
languages='[{"name": "Scala Shell", "type": "spark"},{"name": "PySpark Shell", "type": "pyspark"},{"name": "R Shell", "type": "r"},{"name": "Jar", "type": "Jar"},{"name": "Python", "type": "py"},{"name": "Impala SQL", "type": "impala"},{"name": "Hive SQL", "type": "hive"},{"name": "Text", "type": "text"}]' [notebook]
show_notebooks=true
enable_batch_execute=true
enable_query_builder=true
enable_query_scheduling=false
[[interpreters]]
[[[hive]]]
# The name of the snippet.
name=Hive
# The backend connection to use to communicate with the server.
interface=hiveserver2 [[[impala]]]
name=Impala
interface=hiveserver2
[[[spark]]]
name=Scala
interface=livy [[[pyspark]]]
name=PySpark
interface=livy
[[[jar]]]
name=Spark Submit Jar
interface=livy-batch [[[py]]]
name=Spark Submit Python
interface=livy-batch
[[[spark2]]]
name=Spark
interface=oozie
添加完成之后重启hue服务。
3. 打开hue web ui界面
Hue Web UI,你应该能够看到Spark笔记本。Spark笔记本使用Livy提交Spark工作,所以没有Livy,它还没有运行。
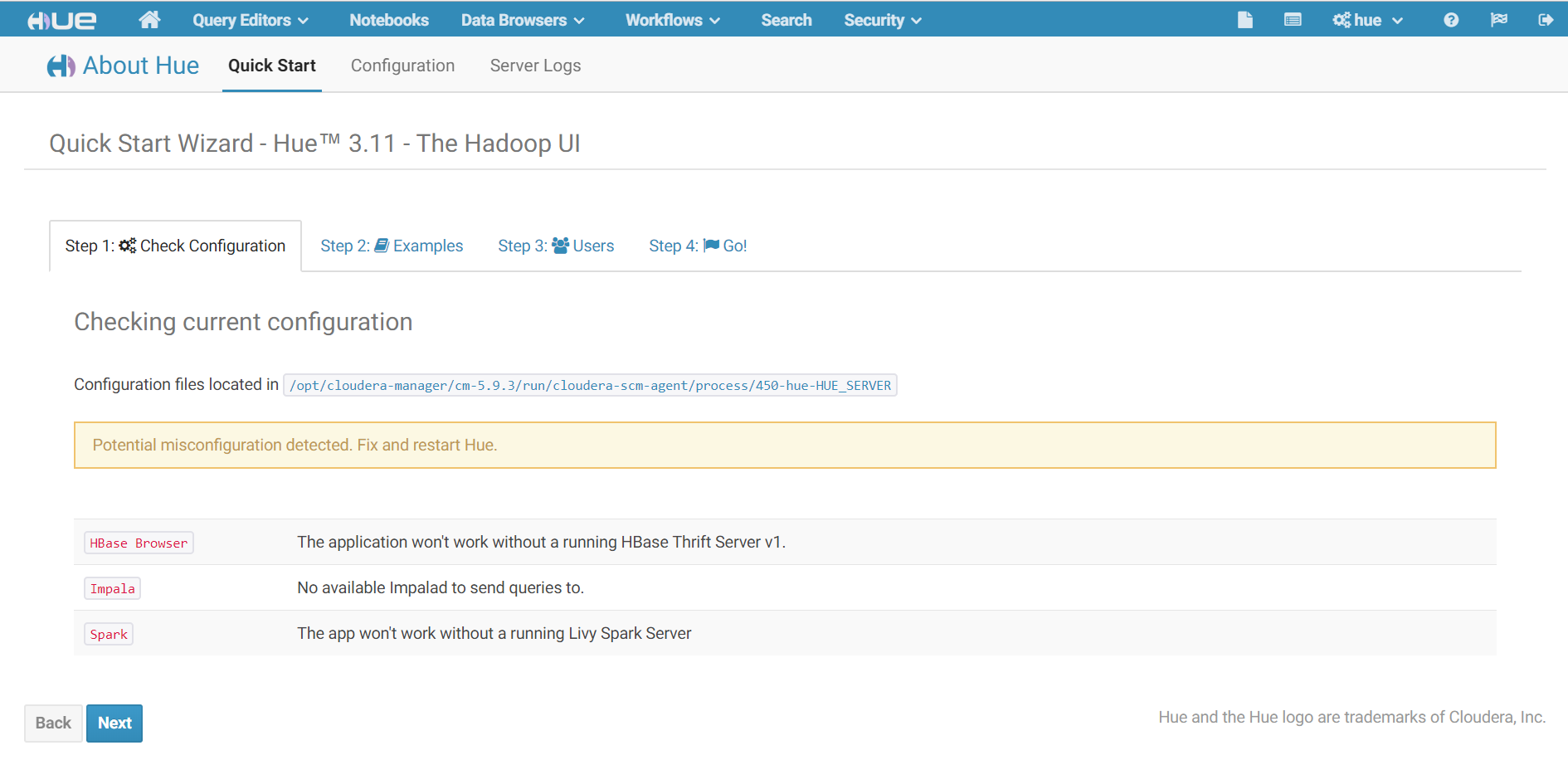
Hbase Browser:警告原因是因为cdh集群没有安装hbase组件。
Impala:警告原因是因为cdh集群没有安装impala组件。
Spark:警告原因是因为没有安装livy服务。
4. 安装Livy服务
4.1 下载地址
https://github.com/cloudera/livy/releases
4.2 上传到服务器并解压
[root@fp- soft]# unzip livy-server-0.3..zip -d /opt/
4.3 修改配置文件
[root@fp- soft]# cd /opt/livy-server-0.3./conf/
[root@fp- conf]# vi livy-env.sh
在文件最后添加以下内容
export JAVA_HOME=/opt/jdk1..0_151
export SPARK_HOME=/opt/cloudera/parcels/CDH-5.9.-.cdh5.9.3.p0./lib/spark/
export SPARK_CONF_DIR=/etc/spark2/conf
export HADOOP_CONF_DIR=/etc/hadoop/conf
4.4 配置环境变量
[root@fp- conf]# vi /etc/profile
#Livy
export LIVY_HOME=/opt/livy-server-0.3.
export PATH=$LIVY_HOME/bin:$PATH
立即生效
[root@fp- conf]# source /etc/profile
4.5 创建日志文件夹
如果没有创建logs,则启动的时候会报错找不到logs文件夹
[root@fp-01 conf]# cd /opt/livy-server-0.3.0
[root@fp-01 livy-server-0.3.0]# mkdir logs
4.6 后台启动livy
[root@fp- conf]# cd /opt/livy-server-0.3./bin/
[root@fp- bin]# nohup ./livy-server > livy.out >& &
4.7 查看启动日志
[root@fp- bin]# cat livy.out
nohup: 忽略输入
// :: WARN LivySparkUtils$: Current Spark (,) is not verified in Livy, please use it carefully
// :: INFO StateStore$: Using BlackholeStateStore for recovery.
// :: INFO BatchSessionManager: Recovered batch sessions. Next session id:
// :: INFO InteractiveSessionManager: Recovered interactive sessions. Next session id:
// :: INFO InteractiveSessionManager: Heartbeat watchdog thread started.
// :: INFO WebServer: Starting server on http://fp-01:8998
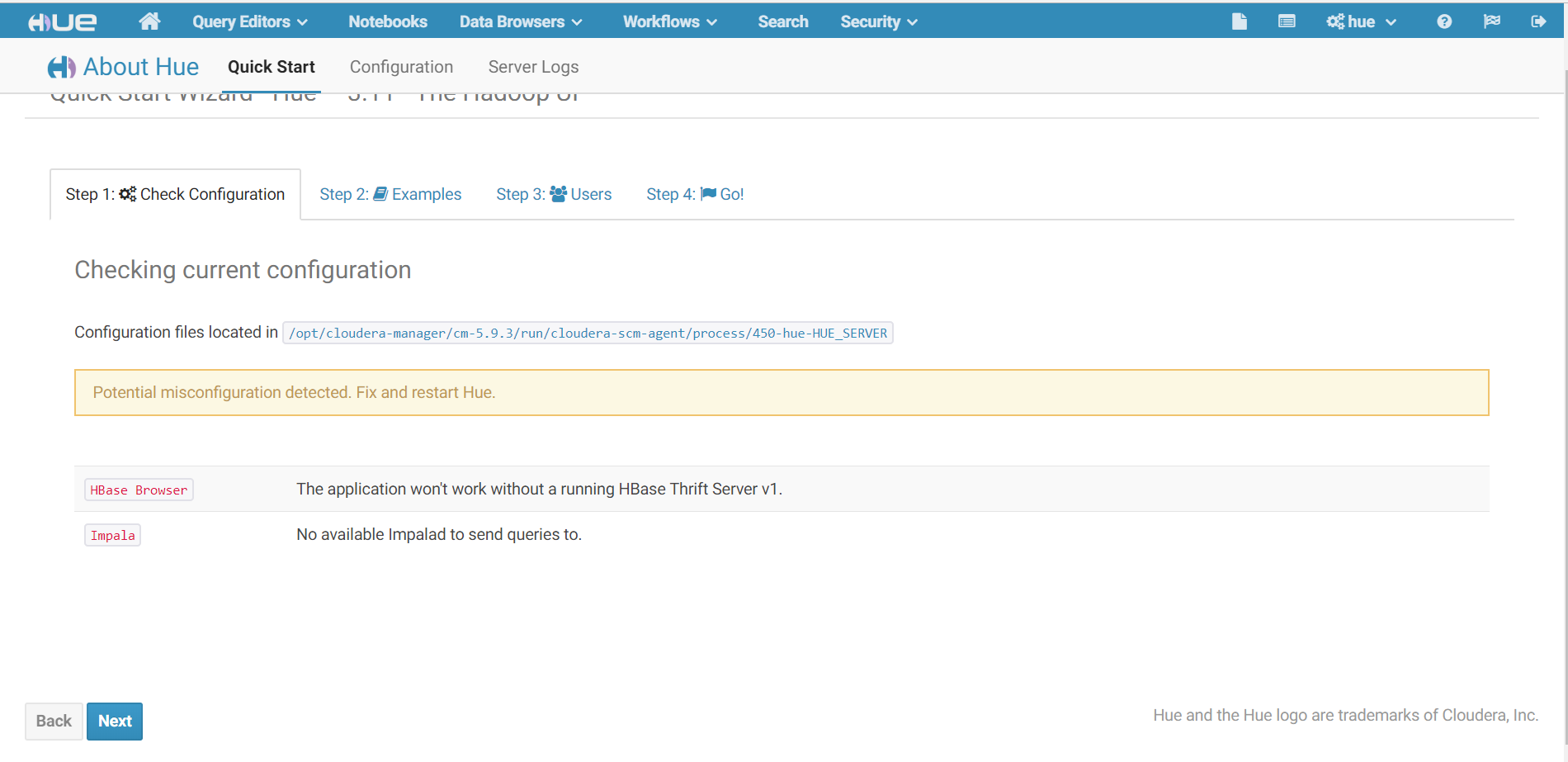
5. 刷新Hue web UI界面
由于已经启动livy服务,spark警告已经消失
6. CDH集群添加hbase和impala组件

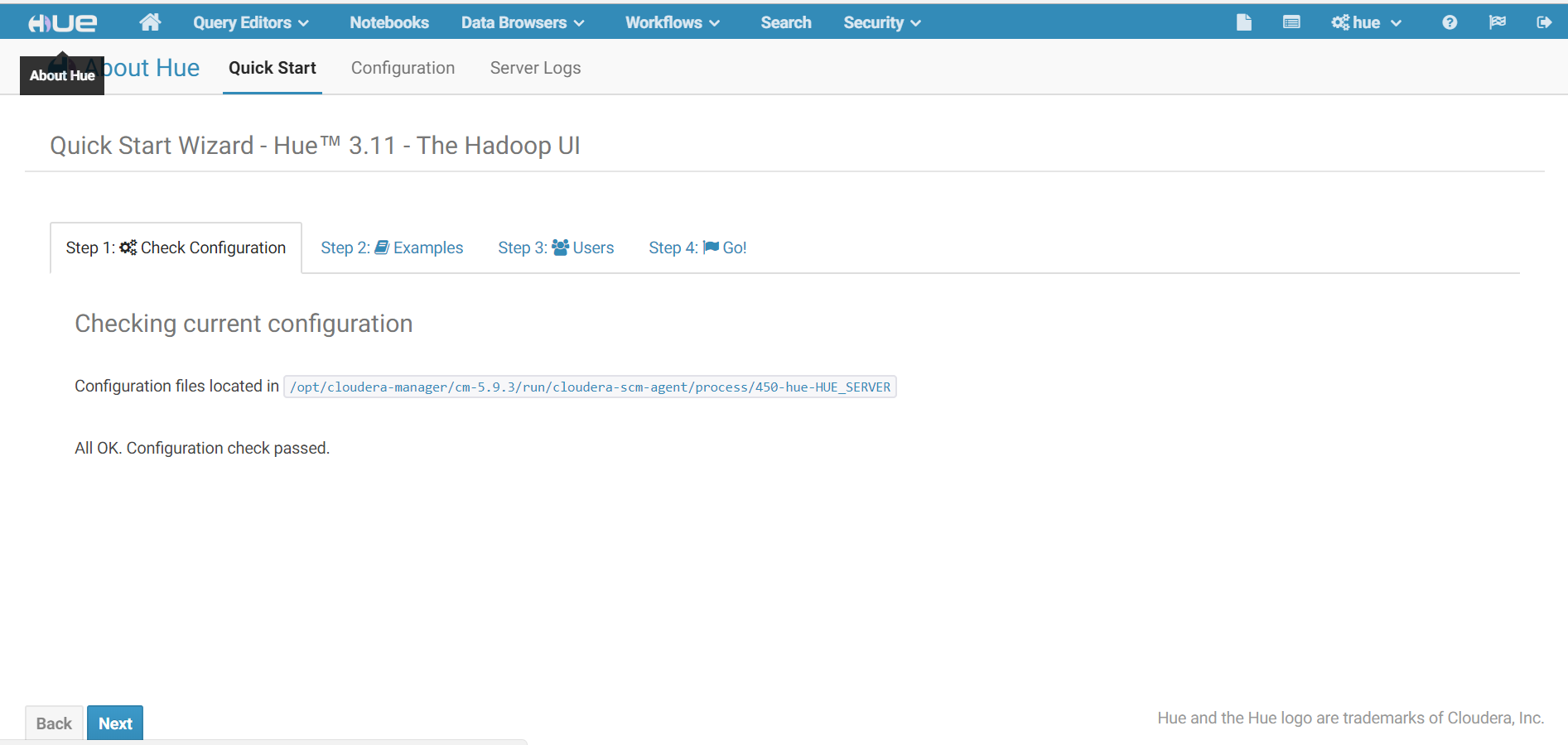
7. 再次刷新Hue web UI界面
此时所有警告已经消失
8. 点击页面顶部的Notebooks
8.1 发现页面报500错误
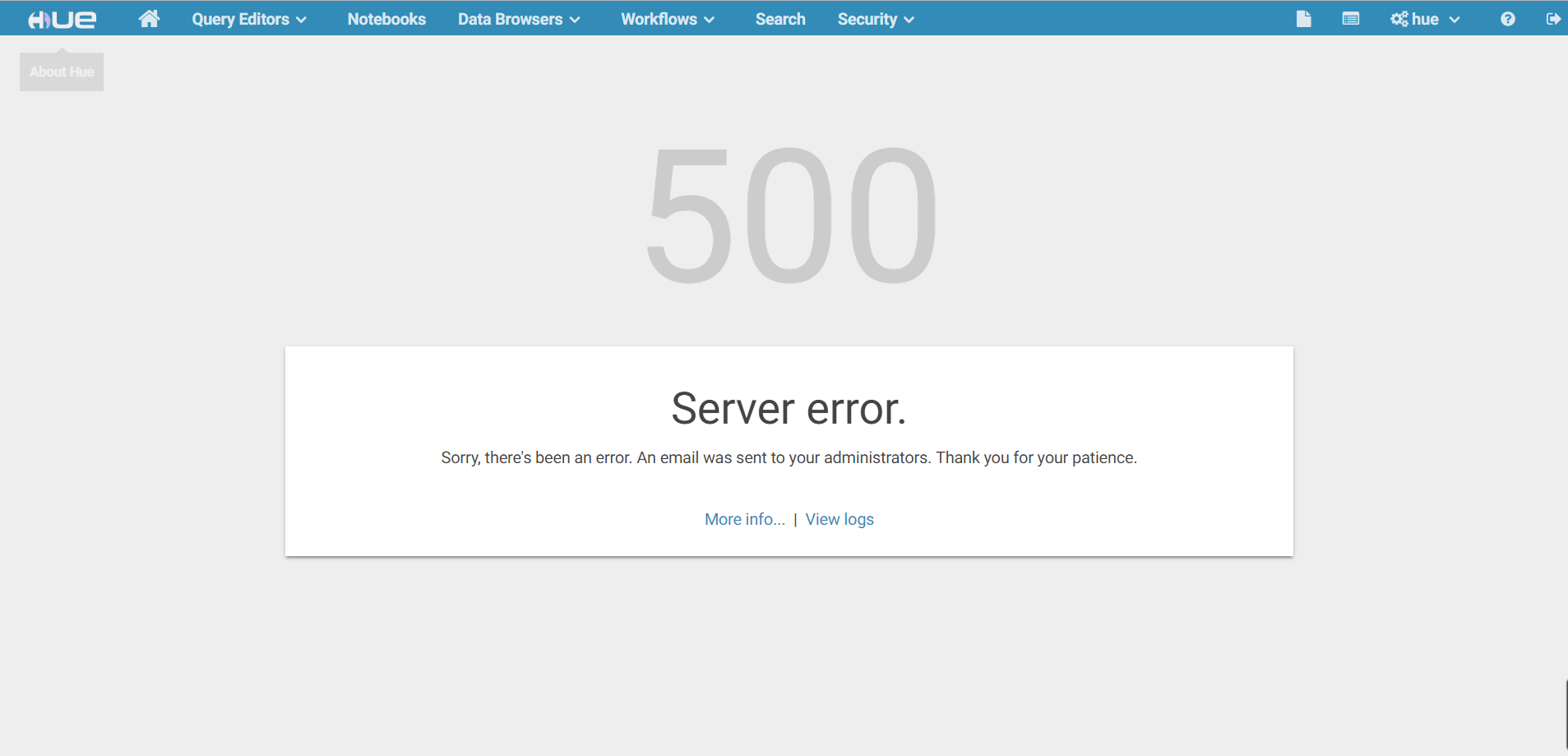
8.2 点击View logs,查看报错日志
有一行报错:NameError:global name 'SHOW_NOTEBOOKS' is not defined
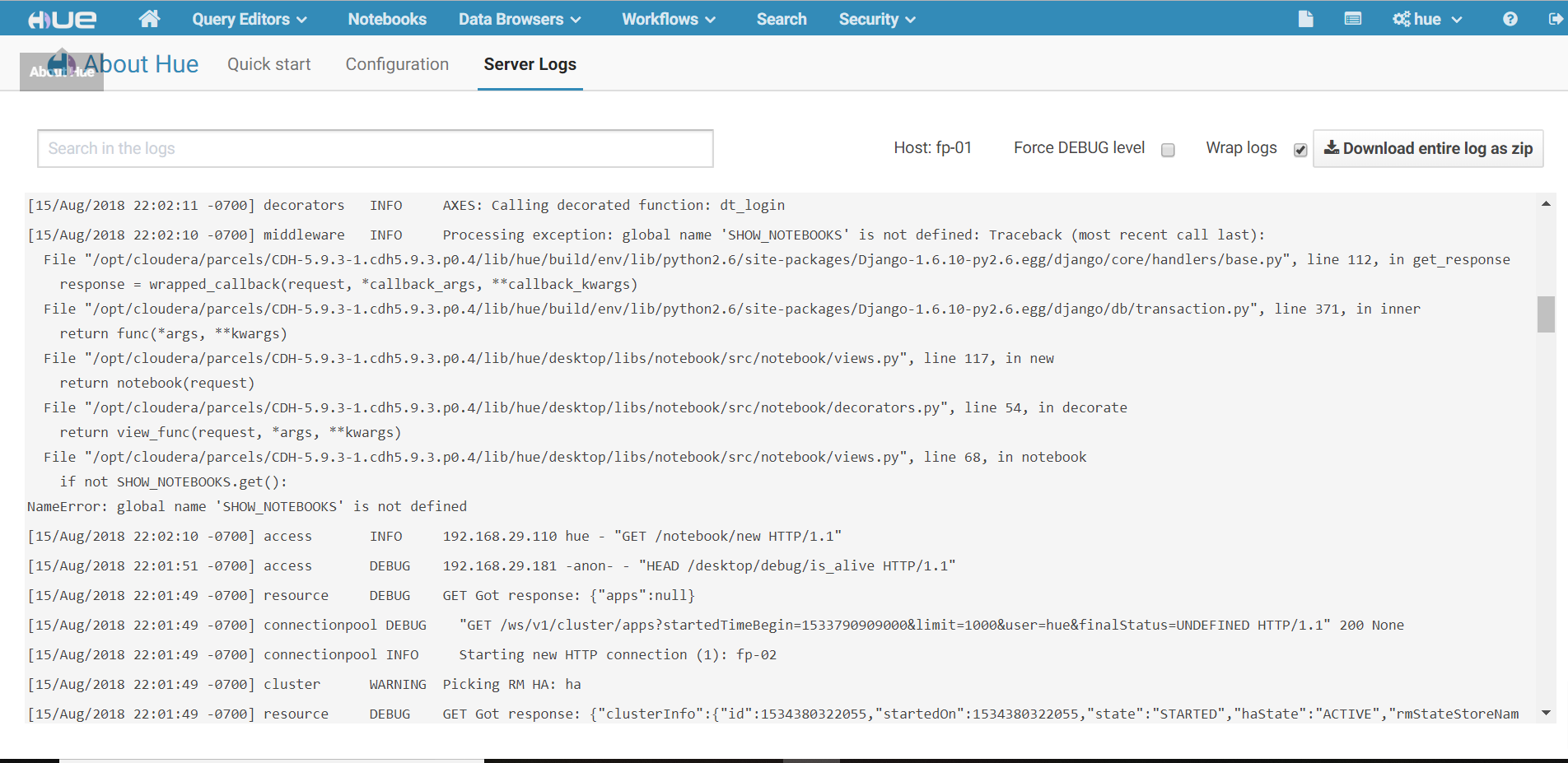
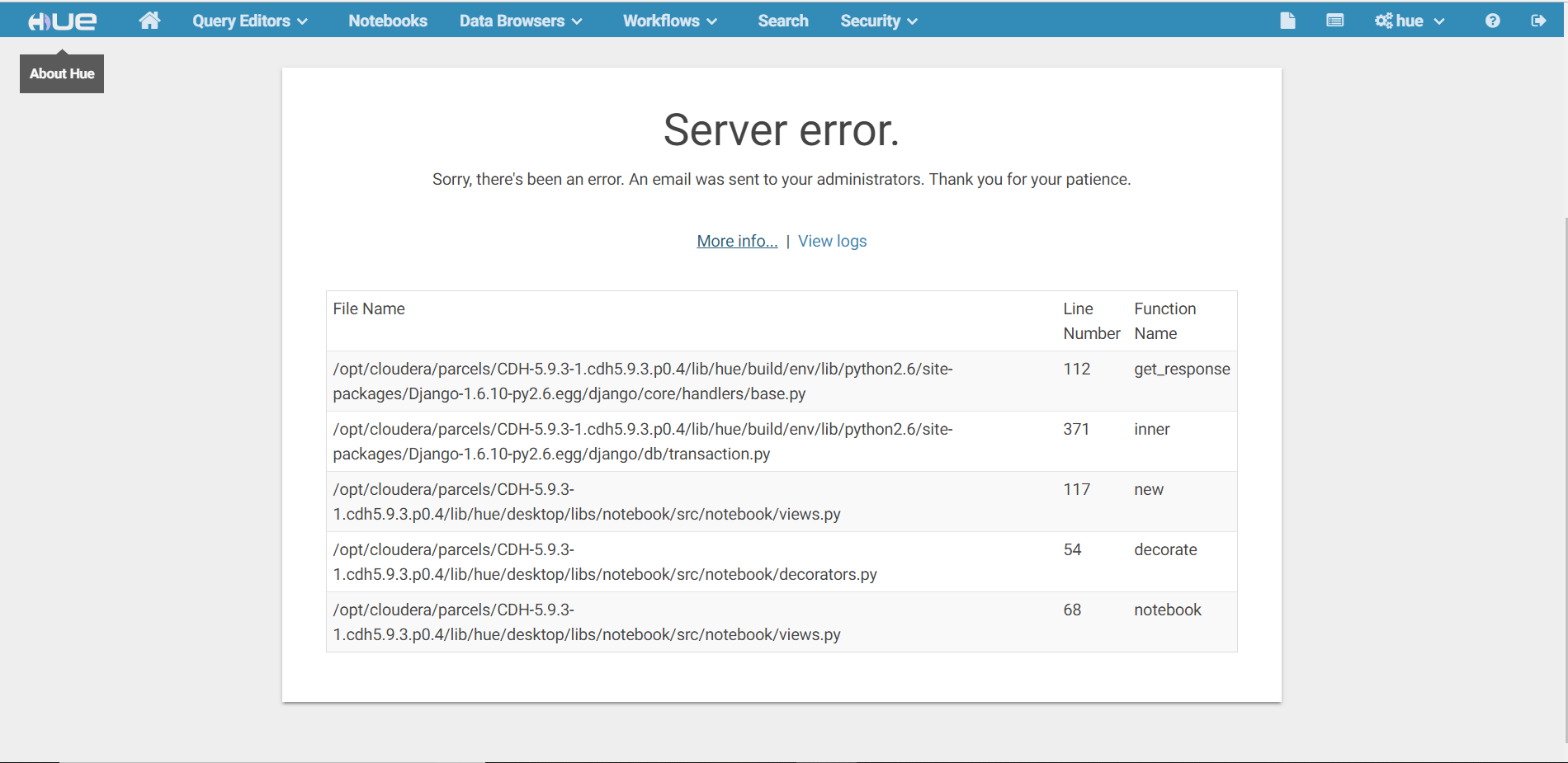
8.3 点击More info
查看最下面的文件views.py,第68行,问题代码if not SHOW_NOTEBOOKS.get(),但是前面并没有定义,所以报错。
8.4 查看hue源码
https://github.com/cloudera/hue
https://github.com/cloudera/hue/blob/master/desktop/libs/notebook/src/notebook/views.py
发现是在前面引入

8.5 修改cdh hue的views.py文件
[root@fp- ~]# cd /opt/cloudera/parcels/CDH-5.9.-.cdh5.9.3.p0./lib/hue/desktop/libs/notebook/src/notebook/
[root@fp- notebook]# vi views.py

8.6 重启hue服务,在hue web UI界面点击notebooks
一切正常
Hue添加Spark notebook的更多相关文章
- Hue添加MySQL数据库
Hue没有配置RDBMS 问题描述 CHD集群添加完Hue组件之后.使用hive进行查询正常,但是使用DB Query查询报错, 报错内容如下: 解决方法 1. 在CHD集群中点击Hue组件,选择配置 ...
- 测试环境添加spark parcel 2.1步骤
1.先到http://archive.cloudera.com/spark2/parcels/2.1.0.cloudera1/ 下载需要的文件比如我linux版本需要是6的 hadoop6需要下载这些 ...
- spark、hadoop集群添加节点
1.首先添加hdfs的节点,将安装包上传到服务器,设置好环境变量.配置文件按之前spark集群搭建的那里进行修改. 设置完成后,要对新节点新型格式化: # hdfs dfs namenode - ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- centos7 hue安装
p.MsoNormal { margin: 0pt; margin-bottom: .0001pt; text-align: justify; font-family: Calibri; font-s ...
- 利用docker搭建spark hadoop workbench
目的 用docker实现所有服务 在spark-notebook中编写Scala代码,实时提交到spark集群中运行 在HDFS中存储数据文件,spark-notebook中直接读取 组件 Spark ...
- Hive记录-使用Hue管理Hive元数据
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web ...
- hive on spark的坑
原文地址:http://www.cnblogs.com/breg/p/5552342.html 装了一个多星期的hive on spark 遇到了许多坑.还是写一篇随笔,免得以后自己忘记了.同事也给我 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
随机推荐
- Lucene实战之关键字匹配多个字段
前言 当我们输入关键字时希望可以支持筛选多个字段,这样搜索内容的覆盖率就会大一些. 匹配多个字段主要用 MultiFieldQueryParser类. 单一字段搜索 QueryParser parse ...
- 互联网推送服务原理:长连接+心跳机制(MQTT协议)
互联网推送消息的方式很常见,特别是移动互联网上,手机每天都能收到好多推送消息,经过研究发现,这些推送服务的原理都是维护一个长连接(要不不可能达到实时效果),但普通的socket连接对服务器的消耗太大了 ...
- ECMAScript typeof用法
typeof 返回变量的类型字符串值 .其中包括 “object”.“number”.“string”.“undefined”.“boolean”. 1.在变量只声明.却不初始化值 Or 在变量没 ...
- elasticsearch6.7 01.入门指南(3)
4.Modifying Your Data(修改数据) Elasticsearch 提供了近实时的操纵数据和搜索的能力.默认情况下,从索引/更新/删除数据到在搜索结果中显示数据会有 1 秒的延迟(刷新 ...
- 浏览器能正常访问的url,superagent不能正常访问
在写音乐播放器的过程中,我需要获取qq音乐排行榜的信息,于是我向以前一样,在后台的MusicController中添加一个getTopList方法 然后写下以下代码 // 获取排行 async get ...
- Python shelve
shelve模块只有一个open函数,返回类似字典的对象,可读可写; key必须为字符串,而值可以是python所支持的数据类型. import shelve f = shelve.open('SHE ...
- Flume初入门简单配置与使用
1.Flume在集群中扮演的角色 Flume.Kafka用来实时进行数据收集,Spark.Storm用来实时处理数据,impala用来实时查询. 2.Flume框架简介 1.1 Flume提供一个分布 ...
- tfs 禁止多人签出
好久没用tfs了,忘了怎么设置了,记录下 编辑----->高级
- Java集合之TreeMap源码分析
一.概述 TreeMap是基于红黑树实现的.由于TreeMap实现了java.util.sortMap接口,集合中的映射关系是具有一定顺序的,该映射根据其键的自然顺序进行排序或者根据创建映射时提供的C ...
- eclipse下载教程
Eclipse 是一个开放源代码的.基于 Java 的可扩展开发平台. Eclipse 是 Java 的集成开发环境(IDE),当然 Eclipse 也可以作为其他开发语言的集成开发环境,如C,C++ ...