语音笔记:CTC
CTC全称,Connectionist temporal classification,可以理解为基于神经网络的时序类分类。语音识别中声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。对于语音的一帧数据,很难给出一个label,但是几十帧数据就容易判断出对应的发音label。CTC的引入可以放宽了这种逐一对应的要求,只需要一个输入序列和一个输出序列即可以训练。CTC解决这一问题的方法是,在标注符号集中加一个空白符号blank,然后利用RNN进行标注,最后把blank符号和预测出的重复符号消除。比如有可能预测除了一个"--a-bb",就对应序列"ab",这样就让RNN可以对长度小于输入序列的标注序列进行预测了。RNN的训练需要用到前向后向算法(Forward-backward algorithm),大概思路是:对于给定预测序列,比如“ab”,在各个字符间插入空白符号,建立起篱笆网络(Trellis),然后对将所有可能映射到给定预测的序列都穷举出来求和。
CTC有两点好处:不需要对数据对齐和一一标注;CTC直接输出序列预测的概率,不需要外部的后处理。
在端到端的语音识别中有以下问题:
1).输入语音序列和标签(即文字结果)的长度不一致
2).标签和输入序列的位置是不确定的(对齐问题)
即长度问题和对齐问题,多个输入帧对应一个输出或者一个输入对多个输出。
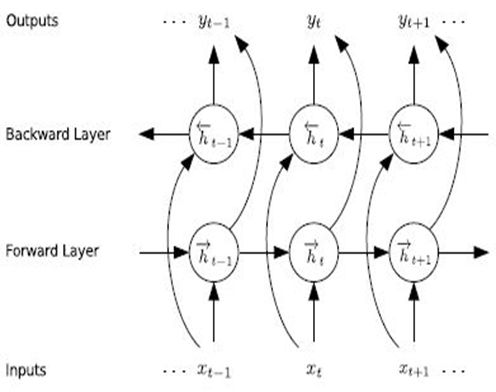
1.结构
系统可以通过双向rnn进行建模。RNN用来训练得到每个时刻不同音素的概率分布。
输入:按时序输入的每一帧的特征。
输出:每一个时刻的输出,是一个softmax,表示K+1个类别的不同概率,K表示音素的个数,1表示blank。(分类问题,是某个音素or空白)
对于给定时序长度为T的输入特征序列和任意一个输出标签序列π={π1,π2,π3,….,πT}。输出为该序列的概率为每个时刻相应标签的概率乘积:

把上式中的pr概率写成y,就变为论文中的原始公式(y表示softmax输出的概率):
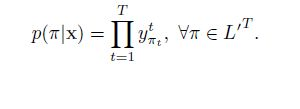
2.损失函数
因为输出序列和最后的训练标签一般不等长,我们用x表示输入序列,y表示对于的标签,a表示我们之前预测的序列:采用一个many-to-one的对应准则β(去除blank和重复),使上述的输出序列与给定的标签序列对应,比如(a,-,b,c,-,-)和(-,-,a,-,b,c)都映射成标签y(a,b,c)。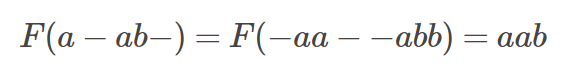
表示β的逆过程,即one-to-many,也就是把(a,b,c)映射成有重复和blank的所有可能,所以最终的标签y为给定输入序列x在LSTM模型下各个序列标签的概率之和:
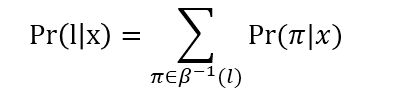
所以给定一个输入序列x和一个标注l*,上式为给定输入x,输出序列为 l 的概率。LSTM的目标函数最大化上述概率值(最小化负对数)。
CTC的损失函数定义如下所示:
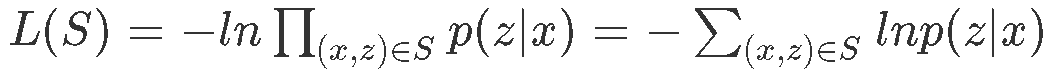
其中 p(z|x)p(z|x) 代表给定输入x,输出序列 zz 的概率,S为训练集。损失函数可以解释为:给定样本后输出正确label的概率的乘积,再取负对数就是损失函数了。取负号之后我们通过最小化损失函数,就可以使输出正确的label的概率达到最大了。
由于上述定义的损失函数是可微的,因此我们可以求出它对每一个权重的导数,然后就可以使用梯度下降、Adam等优化算法来进行求解。
语音笔记:CTC的更多相关文章
- 语音笔记:MFCC
一,传统语音识别体系结构 二,MFCC特征提取 MFCC(Mel-frequency cepstral coefficients):梅尔频率倒谱系数.梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率 ...
- 论文笔记:语音情感识别(三)手工特征+CRNN
一:Emotion Recognition from Human Speech Using Temporal Information and Deep Learning(2018 InterSpeec ...
- 语音识别中的CTC算法的基本原理解释
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文作者:罗冬日 目前主流的语音识别都大致分为特征提取,声学模型,语音模型几个部分.目前结合神经网络的端到端的声学模型训练方法主要CTC和基 ...
- 测试使用wiz来发布blog
晚上尝试了下用wiz写随笔并发布,貌似成功了,虽然操作体验和方便性上不如word,但起码它集成了这个简单的功能可以让我用:如果能让我自动新建blog文章并自动定时更新发布就完美了.2013年7月5日1 ...
- M2阶段事后总结报告
会议照片: 设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 开发一个快捷方便的记事本App.从用户体验角度出发,在一般记事本App的基础上进行创新 ...
- 孤荷凌寒自学python第八十六天对selenium模块进行较详细的了解
孤荷凌寒自学python第八十六天对selenium模块进行较详细的了解 (今天由于文中所阐述的原因没有进行屏幕录屏,见谅) 为了能够使用selenium模块进行真正的操作,今天主要大范围搜索资料进行 ...
- 孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1
孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1 (完整学习过程屏幕记录视频地址在文末) 要模拟进行浏览器操作,只用requests是不行的,因此今天了解到有专门的解决方案 ...
- 孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块
孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块 (完整学习过程屏幕记录视频地址在文末) 由于本身tesseract模块针对普通的验证码图片的识别率并不高 ...
- 孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境
孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境 (完整学习过程屏幕记录视频地址在文末) 学习Python我肯定不会错过图片文字的识别,当然更重要的是简单的验证码识别了,今天 ...
随机推荐
- 使用Maven分环境打包:dev sit uat prod
使用Maven管理的项目,经常需要根据不同的环境打不同的包,因为环境不同,所需要的配置文件不同,比如database的连接信息,相关属性等等. 在Maven中,我们可以通过P参数和profiles元素 ...
- indexOf() 使用方法(数组去重)
对于indexOf()的用法一直停留在查找第几个字符串,却不知道它能用到数组去重中,首先还是温顾下indexOf()的语法: <!DOCTYPE html> <html lang=& ...
- 控件_TimePicker
import android.app.Activity; import android.os.Bundle; import android.view.View; import android.view ...
- Ngnix中的fastcgi參数性能优化和解释
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/luozhonghua2014/article/details/37737823 优化性能參数设置,在 ...
- 【Java多线程】线程状态、线程池状态
线程状态: 线程共包括以下5种状态.1. 新建状态(New) 线程对象被创建后,就进入了新建状态.例如,Thread thread = new Thread().2. 就绪状态(Runnable) 也 ...
- luogu P4146 序列终结者
嘟嘟嘟 这是一道splay基础题. 最坑的一点是,因为有些节点可能没有左儿子或右儿子,所以必须把t[0].Max赋成-INF! 因为这个调了半天,看来回头复习复习splay是对的-- #include ...
- canvas的drawImage函数
HTML5中引入新的元素canvas,其drawImage 方法允许在 canvas 中插入其他图像( img 和 canvas 元素) .drawImage函数有三种函数原型: drawImage( ...
- ThinkPHP5.0 实现 app微信支付功能
相对于之前随笔写的<ThinkPHP5.0实现app支付宝支付功能>来说,php对接app微信支付功能就相对简单的多了,最近有加我的朋友问到app微信支付,所以我把app微信支付的demo ...
- e 的由来
https://www.zhihu.com/question/20296247 对数的发现 很多科学家发现对数螺线在自然界中广泛存在.从大如星系.台风,到小如花朵.海螺……宇宙中到处都是对数螺线的身影
- 转载 【.NET基础】--委托、事件、线程(3)
之前的两篇文章我们了解了委托和事件,本文我们看一下线程. 1,一个窗体程序,默认拥有一个线程(相当于一个商店里面,只有一个店员),这个默认的线程叫做 UI线程/主线程. 2,进程和线程的关系: A ...