【C/C++】内存基础
1. 基本数据类型
short s = 0x4142; // 16进制
char c = *(char*)&s;
cout << c << endl;
我的电脑上输出为字符 'B'
Why???
short 型在内存中占 2 字节(bytes),bit 表示如下。
&s 取 s 的地址,(char *)&s 让机器强行认为该指针指向 char 型元素,而 char 型在内存中占 1 字节。
因此用 * 取地址后只向后获取 8 bits(1 字节),得到 0x41 赋值给 char 型变量 c。
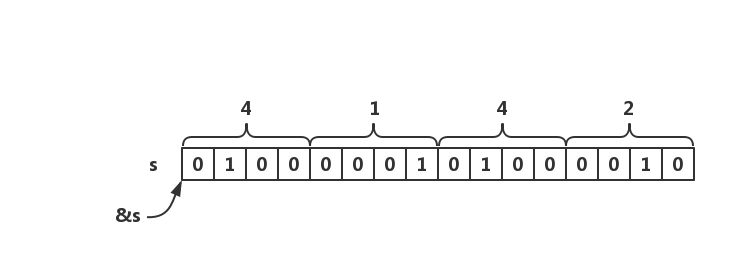
但 0x41 = 65,这样 char c 应该是字符 'A' 啊???
因为计算机系统以字节(8 位)为单位,对于位数大于 8 位的处理器,例如 16 位或 32 位处理器,由于寄存器宽度大于 1 字节,那么必然存在着安排多个字节的问题。因此就导致了大端存储模式和小端存储模式,俗称大尾 / 小尾。
大尾,是指数据的低位(权值较小的后面那几位)保存在内存的高地址(图示中从左到右即为内存地址从低到高)中;而数据的高位,保存在内存的低地址中。
而我的电脑是小尾处理器,即 short s 的低位 0x42 保存在内存的低地址,高位 0x41 保存在内存的高地址。也就是说,
((char*)&s)[0] = 0x42 // 低地址单元
((char*)&s)[1] = 0x41 // 高地址单元
因此我的电脑将 0x42 赋值给 c,因此输出 'B'。
2. 结构体
struct st {
int a;
int b;
};
st s;
s.a = ;
s.b = ;
cout << s.b << endl;
((st*)&(s.b))->a = ;
// ((st*)&(s.b))->b = 99; // 很可能报错,操作不合法内存
cout << s.b << endl;
输出为
2
99
Why 99???
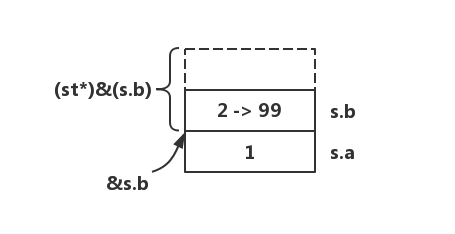
而 ((st*)&(s.b))->b 这片内存很可能未开辟,修改该处的值很可能报错。
结构体的大小(sizeof)需要考虑存储结构体变量时的地址对齐问题。
例如以下 2 个结构体
struct Struct1 {
char a;
int n;
char b;
};
struct Struct2 {
char a;
char b;
int n;
};
用 sizeof() 求这两个结构体大小,Struct1 是 12,Struct2 是 8,WHY???
结构体变量大小 = 最后一个成员变量的地址 + 最后一个成员变量的大小。
Struct1 中第一个成员变量的地址就是结构体变量的首地址,第一个成员 char a 的偏移地址为 0;第二个成员 int n 的地址是第一个成员的地址加上第一个成员的大小(0 + 1),其值为 1;第三个成员 char b 的地址是第二个成员的地址加上第二个成员的大小(1 + 4),其值为 5。
然而,实际存储结构体变量时地址要求对齐,编译器在编译程序时有自己的规则,大多编译器会遵循以下两条原则:
(1)结构体中成员变量的偏移地址 = 其自身大小的整数倍
(2)结构体变量大小 = 所有成员变量大小的整数倍,也即所有成员变量大小的公倍数
上例中 Struct1 的第二个成员变量 int n 的偏移地址为 1,并不是自身大小(4)的整数倍,因此编译器在处理时会在第一个成员后面补上 3 个空字节,使得第二个成员的偏移地址变成 4;这样第三个成员 char b 的偏移地址就是(4 + 4),其值为 8;最后结构体变量的大小等于最后一个成员的偏移地址加上其大小(8 + 1),其值为 9,不是所有成员变量大小的整数倍(9 不是 4 的整数倍),因此编译器会在第三个成员变量 char b 后面补上 3 个空字节,结构体总大小即为 12,满足要求。Struct2 也是同理,会在第二个成员 char b 后补 2 个空字节以满足要求。
通过输出这两个结构体每个成员的地址,会更加清楚这种地址结构。
int main() {
Struct1 s1;
Struct2 s2;
cout << sizeof(s1) << " " << sizeof(s2) << endl;
cout << "Struct1:" << (void*)&s1 << endl
<< "a: " << (void*)&(s1.a) << endl
<< "n: " << (void*)&(s1.n) << endl
<< "b: " << (void*)&(s1.b) << endl;
cout << "Struct2:" << (void*)&s2 << endl
<< "a: " << (void*)&(s2.a) << endl
<< "n: " << (void*)&(s2.b) << endl
<< "b: " << (void*)&(s2.n) << endl;
return ;
}
输出结果为

嵌套结构体的大小(sizeof)需要将其展开考虑。 原则如下:
(1)展开后的结构体的第一个成员变量的偏移地址 = 被展开的结构体中最大的成员变量大小的整数倍。
(2)整个结构体变量大小 = 所有成员大小的整数倍(所有成员计算的是展开后的成员,而不是将嵌套的结构体当做一个整体)。
3. Union
Union 是一种特殊的结构体。它能够包含访问权限(默认访问权限是 public)、成员变量、成员函数(可以包含构造函数和析构函数),但不能包含虚函数、静态数据变量、引用(后两者无法共享内存),也不能被用作其他类的基类,它本身也不能从某个基类派生而来。
Union 类型的成员之间是共享内存的,同一时刻,一个 Union 中只有一个值是有效的。因此当多种数据类型要占用同一片内存时,即“n 选 1”时,可以使用 Union 来发挥其长处。
如下例 Union
union Union {
struct StructInUnion {
int a;
int b;
}s;
int c;
int d;
};
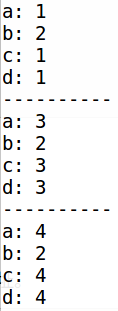
观察对不同成员赋值造成的相互影响(s、a、c、d 的首地址相同)
int main() {
Union u;
u.s.a = ;
u.s.b = ;
cout << "a: " << u.s.a << endl
<< "b: " << u.s.b << endl
<< "c: " << u.c << endl
<< "d: " << u.d << endl;
cout << "----------" << endl;
u.c = ;
cout << "a: " << u.s.a << endl
<< "b: " << u.s.b << endl
<< "c: " << u.c << endl
<< "d: " << u.d << endl;
cout << "----------" << endl;
u.d = ;
cout << "a: " << u.s.a << endl
<< "b: " << u.s.b << endl
<< "c: " << u.c << endl
<< "d: " << u.d << endl;
return ;
}
输出结果
3. 数组
主要地,array + k = &array[k],数组即是数组首元素的地址。
类似地,可以通过 k 合法 / 不合法地操作内存。
4. swap() 函数
实现交换两个元素内容的函数swap,对于不同数据类型,C++可使用模板 template,使用模板更加的类型安全(type safe)。
但其实,当编译器发现模板函数被使用(注意,不是被定义),则在编译这段代码时会使用那个强类型构造一个新函数,导致代码膨胀,因此编译效率并不高。
此时可以通过无类型指针 void* 实现泛型编程,优点是执行速度很快,只需要一份代码副本。
但是,
void swap(void *vp1, void *vp2) {
void temp = *vp1;
*vp1 = *vp2;
*vp2 = temp;
}
这样写是错误的!!!因为
- 变量无法声明为 void 类型
- void* 无法被解引用,因为系统没有此地址指向的对象的大小信息
要想实现泛型函数,需要在调用的地方传入相关要交换的对象的地址空间大小 size。
void swap(void *vp1, void *vp2, int size) {
char *buffer = new char[size];
memcpy(buffer, vp1, size);
memcpy(vp1, vp2, size);
memcpy(vp2, buffer, size);
delete[] buffer;
}
具体使用如下
int x = , y = ;
cout << "x = " << x << ", y = " << y << endl;
swap(&x, &y, sizeof(int));
cout << "x = " << x << ", y = " << y << endl;
char *a = strdup("storm"), *b = strdup("nevermore");
cout << "a = " << a << ", b = " << b << endl;
swap(&a, &b, sizeof(char **)); // 字符串不等长,需要交换指针
cout << "a = " << a << ", b = " << b << endl;
swap(a, b, sizeof(char *)); // 错误!!!注意与上面的区别
cout << "a = " << a << ", b = " << b << endl;
注意输出结果的区别
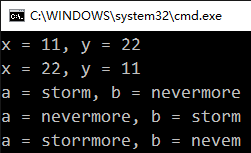
注意字符串的交换传递的参数是二级指针 &a 和 &b,如图
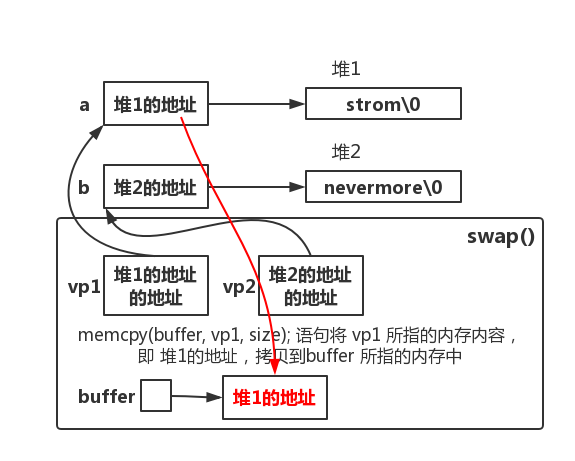
如果直接将一级指针 a、b 作为参数传递,则 swap 函数执行过程中 vp1 的内容是字符串 “storm\0” 的地址,mencpy 后缓冲区 buffer 指向的内容的将是字符串 “stor”(指针变量一律占 4 字节),因此最后交换的是两个字符串的前 4 个字节。
PS:数组名 a、b 即是一级指针,a = &a[0] 隐式传入 &。
5. 线性搜索函数
int 型版本
int lsearch(int key, int array[], int size) {
for (int i = ; i < size; i++)
if (array[i] == key)
return i;
return -;
}
基本数据类型数组的泛型线性搜索函数的实现
// key为搜索值的指针,base为基数组的指针,n为数组元素个数,elemSize为每个元素的大小
void* lsearch(void *key, void *base, int n, int elemSize) {
for (int i = ; i < n; ++i) {
void *elemAddr = (char*)base + i * elemSize;
if (memcmp(key, elemAddr, elemSize) == )
return elemAddr;
}
return NULL;
}
TIP: 代码第 3 行,将基数组的首地址强制转换为 char 型指针。WHY???
对于非 void 指针,如 int array[10];
array[i] 等价于 *(array + i),编译器会根据数组类型在 i 后面乘以 sizeof(int),以获取正确的内存地址。
而不允许对 void 指针进行算术运算,是因为编译器不知道 void 数组中每个元素的大小,仅仅使用 base + i 的话编译器并不知道 base 数组中每个元素大小为 elemSize。
这里的强制类型转换利用了 char 型大小为 1 字节的特性,使 elemAddr 指向此 void 数组的第 i 个元素的首地址。
使用 memcmp 可以比较 char、int、double 等基本数据类型,但无法比较字符指针 char * 类型,因为 char * 所指向的字符串不等长, memcmp 的第三个参数无法确定。也就无法在 char ** 字符指针数组中找到所要的 char * 字符串。
因此可以通过函数指针传入我们自定义的比较函数。
// 为char**定制的比较函数
int StrCmp(void *vp1, void *vp2) {
char *s1 = *(char **)vp1;
char *s2 = *(char **)vp2;
return strcmp(s1, s2);
} void* lsearch(void *key, void *base, int n, int elemSize, int (*cmpfn)(void *, void *)) {
for (int i = ; i < n; i++) {
void *elemAddr = (char *)base + i * elemSize;
if (cmpfn(key, elemAddr) == )
return elemAddr;
}
return NULL;
}
函数的使用如下
int main() {
char *heroes[] = {"JUGG", "QOP", "Storm Spirit", "Zeus", "SF"};
char *a1 = "JUGG", *a2 = "yyf";
char **found;
found = (char **)lsearch(&a1, heroes, , sizeof(char *), StrCmp);
if (found)
cout << *found << " is Found!" << endl;
else
cout << "Not Found!" << endl;
found = (char **)lsearch(&a2, heroes, , sizeof(char *), StrCmp);
if (found)
cout << *found << " is Found!" << endl;
else
cout << "Not Found!" << endl;
return ;
}
输出为
JUGG is Found!
Not Found!
注意:
- heroes 的类型是 char** ,即字符指针数组,数组元素都是指向一个字符串的指针,这些字符串不在堆(heap)中,它们是字符串常量,存储在静态存储区。(C语言中没有字符串变量,只能用字符数组 char [] 表示)
- 由于 base 是字符串指针数组,即 char**,所以返回值 elemAddr 也是 char** 类型,所以将 found 设置为 char** 类型。当 found 不为空,对 found 解引用后,输出的 *found 为字符指针 char* 类型,指向所要找的字符串。
- 为什么给 char** 定制的比较函数 StrCmp 要这样写???
- 我们逻辑上知道 elemAddr 是 char** 类型,并且我们希望对 vp1 和 vp2 的处理保持格式一致,因此我们传递的参数key,即 &a1 和 &a2 也是 char** 类型。因此把 vp1 和 vp2 强制类型转换为 char**,这样在逻辑上正确。
- 我们继续将 vp1 和 vp2 解引用,是因为这样得到的 s1 和 s2 是 char* 类型,对字符指针指向的字符串比较可以调用内置函数 strcmp()。
以上。
【C/C++】内存基础的更多相关文章
- 【STM32H7教程】第25章 STM32H7的TCM,SRAM等五块内存基础知识
完整教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 第25章 STM32H7的TCM,SRAM等五块内 ...
- linux内存基础知识和相关调优方案
内存是计算机中重要的部件之中的一个.它是与CPU进行沟通的桥梁. 计算机中全部程序的执行都是在内存中进行的.因此内存的性能对计算机的影响很大.内存作用是用于临时存放CPU中的运算数据,以及与硬盘等外部 ...
- java基础内存基础详解
堆区: 1.存储的全部是对象,每个对象都包含一个与之对应的class的信息.(class的目的是得到操作指令) 2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对 ...
- .NET 内存基础(通过内存体验类型、传参、及装箱拆箱)
该随笔受启发于<CLR Via C#(第三版)>第四章4.4运行时的相互联系 一.内存分配的几个区域 1.线程栈 局部变量的值类型 和 局部变量中引用类型的指针(或称引用)会被分配到该区域 ...
- C语言学习(记录)【内存相关_1:内存基础】
本学习是基于嵌入式的C语言学习记录(课程内容来源于某位老师的网络课程,为了证明不是在打广告,就不写出老师的名字了,感谢.) -------------------------------------- ...
- AS3 内存基础
1:获取一个对象的字节数: var str:String="ddd啊"; var byte:ByteArray=new ByteArray(); byte.writeMultiBy ...
- java内存基础(一)
博客园 闪存 首页 新随笔 联系 管理 订阅 随笔- 35 文章- 0 评论- 29 关于Java 数组内存分配一点认识 //总结:[ 数组引用变量存储在栈内存中,数组对象存储在堆内存当中.数 ...
- Java虚拟机内存基础、垃圾收集算法及JVM优化
1 JVM 简单结构图 1.1 类加载子系统与方法区 类加载子系统负责从文件系统或者网络中加载 Class 信息,加载的类信息存放于一块称 为方法区的内存空间.除了类的信息外,方法区中可能还会存放 ...
- Linux性能优化从入门到实战:08 内存篇:内存基础
内存主要用来存储系统和应用程序的指令.数据.缓存等. 内存映射 物理内存也称为主存,动态随机访问内存(DRAM).只有内核才可以直接访问物理内存. Linux 内核给每个进程都提供了一个独立的 ...
随机推荐
- Linux 两台服务器之间传输文件
一.scp命令的使用 1.传输文件(不包括目录) 命令格式:scp 源文件路径目录/需要传输的文件 目标主机的用户名@目标主机IP/主机别名:目标主机存储目录 举个例子:scp /root/ceshi ...
- ORACLE——NVL()、NVL2() 函数的用法
NVL和NVL2两个函数虽然不经常用,但是偶尔也会用到,所以了解一下. 语法: --如果表达式1为空则显示表达式2的值,如果表达式1不为空,则显示表达式1的值 NVL(表达式1,表达式2); --如果 ...
- 大牛推荐的5本 Linux 经典必读书
今天给大家推荐5本Linux学习相关的书籍:这些书籍基本都是很多大牛推荐过,并且深受业界好评的书:虽然只有5本,但是相信把5本全都认真看过的同学应该不多吧?希望这些书能够帮助你进阶为大牛! 上期传送门 ...
- 家庭记账本之微信小程序(七)
最后成果 在经过对微信小程序的简单学习后,对于微信小程序也稍有理解,在浏览学习过别人的东西后自己也制作了一个,觉得就是有点low,在今后的学习中会继续完善这个微信小程序 //index.js //获取 ...
- iPhoneX快速适配,简单到你想哭。
研究了5个小时的iPhoneX适配. 从catalog,storyboard,safearea等一系列文章中发现.如果我们想完全撑满全屏.那直接建一个storyboard就好了.但撑满全屏后,流海就是 ...
- Ubuntu16.04彻底卸载MySQL
删除mysql的数据文件 sudo rm /var/lib/mysql/ -R 删除mysql的配置文件 sudo rm /etc/mysql/ -R 自动卸载mysql(包括server和clien ...
- java之连接数据库之JDBC访问数据库的基本操作
1.将数据库的JDBC驱动加载到classpath中,在基于JavaEE的web应用实际开发过程中通常要把目标数据库产品的JDBC驱动复制到WEB—INF/lib下. 2.加载JDBC驱动并将其注册到 ...
- CentOS 7 nginx+tomcat9 session处理方案之session保持
Session保持(会话保持)是我们见到最多的名词之一,通过会话保持,负载均衡进行请求分发的时候保证每个客户端固定的访问到后端的同一台应用服务器.会话保持方案在所有的负载均衡都有对应的实现.而且这是在 ...
- py-faster-rcnn
踩坑: 1. 服务器上训练: sh ./experiments/scripts/faster_rcnn_end2end.sh 会各种报错 有说是因为#!/bin/bash的问题,改过,不行. 改成如下 ...
- Sanic
基础 厉害了我的 Sanic hello word, Sanic