【Python62--scrapy爬虫框架】
一、Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
Scrapy最初是为页面抓取而设计的,也可以应用在获取API所返回的数据,或者通用的网络爬虫
二、使用Scrapy抓取一个网站一共需要4个步骤:
1、创建一个Scrapy项目
2、定义Item容器
3、编写爬虫
4、存储内容
三、Scrapy框架
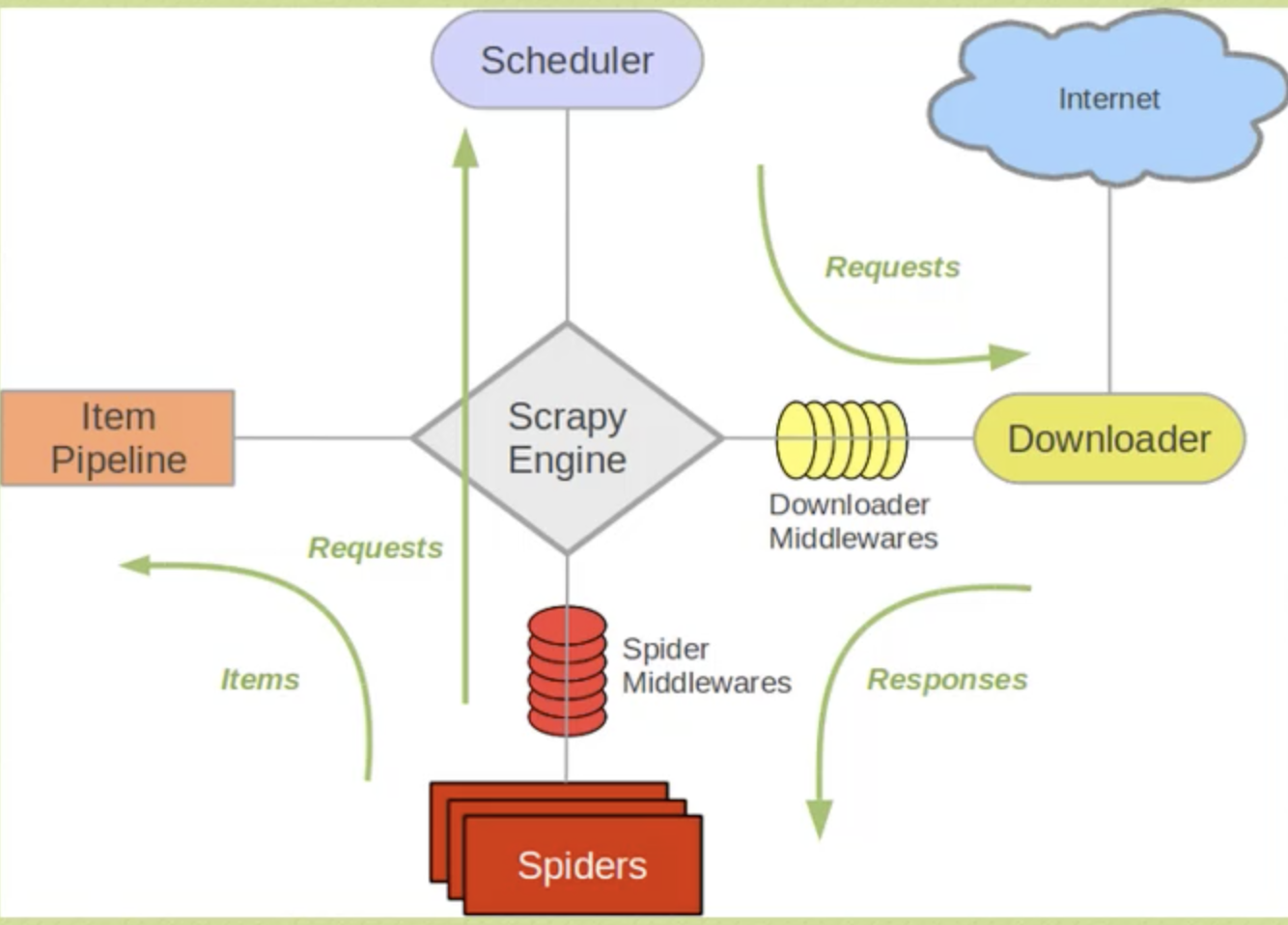
四、安装scrapy并创建scrapy框架
参考文档:https://blog.csdn.net/qijingpei/article/details/70194251
步骤1:安装Anaconda,在cmd窗口输入:conda install scrapy ,输入y回车表示允许安装依赖库
步骤2:测试scrapy是否安装成功,在dos窗口输入scrapy回车
步骤3:在Pycharm-->file-->settings-->搜索project interpreter(项目解释器)-->选择Anaconda3的python.exe --〉点击“OK”,千万不要点apply,可能会让你更新一大堆东西
步骤4:在pycharm中输入import scrapy ,如果不报错,应该就是可以用了
步骤5:在pycharm的终端输入:scrapy startproject module”,其中module为模块名
步骤6:创建后,在终端可以看到创建的module路径:如:/用户/wufq/module
步骤7:用pycharm打开此路径下的文件夹:module,这样在pycharm里面就可以看到scrapy的框架
步骤8:框架如下:
1)scrapy.cfg 框架的基本设置
2)settings.py 用户的相关设置
3)spiders 用户自己实现的spider文件夹
4)items.py 数据条目(保存爬取到的数据的容器,其使用方法和python字典类似,并且提供了额外的保护机制来避免拼写错误导致的未定义字段错误)
5)pipelines 管道
五、爬虫代码编写
1、首先对希望获取的数据进行建模:网站的名字,网站的超链接,网站的描述。即在items.py里面进行编写
- #items.py里面编写
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class ModuleItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- title = scrapy.Field() #建模(爬取)的网站标题
- link= scrapy.Field() #连接地址
- desc = scrapy.Field() #网站描述
2、编写爬虫,在spider里面写(Spider是用户编写用于从网站上爬取数据的类。其包含了一个用于下载的初始URL,然后是如何跟进网页中的连接以及如何分析页面中的内容,还有提取item的方法)
【Python62--scrapy爬虫框架】的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- IOS如何安装ipa文件
https://www.i4.cn/pro_ios.html#jiaocheng 用电脑下载 爱思助手PC端 然后电脑连接 苹果手机, 用 安装的 爱思助手PC端 软件 安装 “爱思助手移动端” 下载 ...
- jquery面试(2)
DOM操作——怎样添加.移除.移动.复制.创建和查找节点? (1)创建新节点 createDocumentFragment() //创建一个DOM片段 createElement() //创建一个具体 ...
- 使用call、apply和bind解决js中烦人的this,事件绑定时的this和传参问题
1.什么是this 在JavaScript中this可以是全局对象.当前对象或者任意对象,这完全取决于函数的调用方式,this 绑定的对象即函数执行的上下文环境(context). 为了帮助理解,让我 ...
- arch 将 普通用户添加到 docker 组
如果还没有 docker group 就添加一个: sudo groupadd docker 如果你想用你的使用者帳戶(非root帳戶)來使用Docker,把你的帳戶加到Docker的群組中 sudo ...
- luke下载使用
网上内容太多,下载了却不管用,即使下载了,也不知道怎么用.(对我这种小白来说,大神就一笑而过吧) 下载地址:http://www.xdowns.com/app/253909.html(如若下载不到可以 ...
- 教你如何用笔记本设置超快WIFI
以win7为例 1.在主菜单运行框输入 cmd------->以管理员的身份运行 2.命令提示符中输入:netsh wlan set hostednetwork mode=allow ssid ...
- python全栈开发 * 线程锁 Thread 模块 其他 * 180730
一,线程Thread模块1.效率更高(相对于进程) import time from multiprocessing import Process from threading import Thre ...
- Luogu 1093 - 奖学金 - [排序水题]
题目链接:https://www.luogu.org/problemnew/show/P1093 题目描述某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金.期末,每个学生 ...
- Golang go get第三方库的坑
在树莓派上go get fail的问题记录及解决方案 go get github.com/terrancewong/serial # 错误为GOPATH路径的问题 cannot find packag ...
- C# 让String.Contains忽略大小写
在C#里,String.Contains是大小写敏感的,所以如果要在C#里用String.Contains来判断一个string里是否包含一个某个关键字keyword,需要把这个string和这个ke ...