python 基础知识点二
深浅copy
1对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的。
l1 = [1,2,3,['barry','alex']]
l2 = l1 l1[0] = 111
print(l1,id(l1)) # [111, 2, 3, ['barry', 'alex']] 112431152
print(l2,id(l2)) # [111, 2, 3, ['barry', 'alex']] 112431152 l1[3][0] = 'wusir'
print(l1,id(l1)) # [1, 2, 3, ['wusir', 'alex']] 112431152
print(l2,id(l2)) # [1, 2, 3, ['wusir', 'alex']] 112431152
2对于浅copy(copy)来说,只是在内存中重新创建了开辟了一个空间存放一个新列表(内存地址不同),列表中的元素的内存地址是一样的。
列表中可变的数据类型修改就会跟着修改,但是列表中的不可变的数据类型修改就不会跟着修改。
解释:copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。子对象(数组,字典等可变数据类型)修改,也会修改
l1 = [1, '太白', True, (1,2,3), [22, 33]]
l2 = l1.copy() print(id(l1), id(l2)) # 112496688 112475312 print(id(l1[-2]), id(l2[-2])) #35243432 35243432 print(id(l1[-1]),id(l2[-1])) #112410096 112410096
3.对于深copy(deepcopy)来说,列表是在内存中重新创建的,是原始的对象。不会随着修改而修改。
copy.deepcopy 深拷贝 拷贝对象及其子对象(原始对象)
import copy
l1 = [1, 'alex', True, (1,2,3), [22, 33]]
l2 = copy.deepcopy(l1)
# print(id(l1), id(l2)) # 112627760 112606384
print(id(l1[0]),id(l2[0])) # 1521669168 1521669168
print(id(l1[-1]),id(l2[-1])) # 112999960 112999880 #元素为列表 为不可哈希(可变类型)
print(id(l1[-2]),id(l2[-2])) # 6735272 6735272
例子:
import copy
a = [1, 2, [3, 4], {'a': 1}] # 原始对象
b = a # 赋值,传对象的引用
c = copy.copy(a) # 对象拷贝,浅拷贝
d = copy.deepcopy(a) # 对象拷贝,深拷贝
e = a[:] # 能复制序列,浅拷贝
a.append('add1')
# 修改对象a
a[2].append('add2')
# 修改对象a中的[3,4]数组对象
a[3]['a'] = 666
print('a:', a)
print('b:', b)
print('c:', c)
print('d:', d)
print('e:', e)
结果;
a: [1, 2, [3, 4, 'add2'], {'a': 666}, 'add1']
b: [1, 2, [3, 4, 'add2'], {'a': 666}, 'add1']
c: [1, 2, [3, 4, 'add2'], {'a': 666}]
d: [1, 2, [3, 4], {'a': 1}]
e: [1, 2, [3, 4, 'add2'], {'a': 666}]
- 解释:copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。子对象(数组)修改,也会修改
- copy.deepcopy 深拷贝 拷贝对象及其子对象(原始对象)
文件的操作
文件句柄 = open(‘文件路径’,‘模式’,'编码')
#1. 打开文件的模式有(默认为文本模式):
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 #注意读是读光标后的内容
w,只写模式【不可读;不存在则创建;存在则清空内容】
a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、
图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 #3,‘+’模式(就是增加了一个功能)
r+, 读写【可读,可写】
w+,写读【可写,可读】
a+, 写读【可写,可读】 #4,以bytes类型操作的读写,写读,写读模式
r+b, 读写【可读,可写】
w+b,写读【可写,可读】
a+b, 写读【可写,可读】
#在读的时候,bytes类型在读的时候内置函数自动转变为字符串了
# with open('01.txt','r',encoding='UTF-8') as f:
# # f.write('曾辉123456')
# print(f.read()) bytes ---->str
read:
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
其余的文件内光标移动都是以字节为单位的如:seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下使用。
with open('log',mode='a+',encoding='utf-8') as f:
# f.write('佳琪')
count = f.tell() #tell 是获取光标的位置,也是以一个字节为单位的。
f.seek(0) #seek 光标的移动是以一个字节为单位的
print(f.read()) #读取光标后的文本
f.read(2) #读取几个字符
f.truncate(5) #截断原文件,对原文件进行变化,
print(f.readline()) #只读取文件光标后的一行内容
coun = f.readlines() #readlines读取文件的每行内容,并且把每行内容
#作为List中的元素储存起来。
f.writelines(['1','23','3']) #将一个字符串列表(列表中的元素为字符串)写入文件
with open('log',mode='a+',encoding='utf-8') as f,\
open('log',mode='a+',encoding='utf-8') as f1,\
open('log',mode='a+',encoding='utf-8') as f2: #用 with 可以同时打开多个文件,
#同时不用在最后关闭文件
文件的修改,实际上文件不能直接进行修改,可以通过间接修改。修改的过程为:先打开2个文件,然后在写入新的内容放在一个文件里面,然后在删除原来的文件,在将修改内容的文件重命名为原来的文件名。
#函数的文件修改
def txt_func(fliename,old,new): #打开文件
with open(fliename,encoding='utf-8') as f,open('%s.bak'%(fliename),'w',encoding='utf-8') as f2:
for line in f:
if old in line:
line = line.replace(old,new)
#写文件
f2.write(line) import os
os.remove(fliename) #删除文件
os.rename('%s.bak'%(fliename),fliename) #重命名文件 txt_func('123.txt','123','aaa')
函数的返回值
函数:可读性强 复用性强
return 关键字的作用:
1,结束函数的执行(return 下面的语句都不执行)
2,返回值
没有返回值。
不写return的情况下,会默认返回一个None;
有返回值包括一个值或者是多个值。
def fun(a,b):
c= a+b
return c,a
sun,b = fun(1,1) #返回多个值,如果用一个变量去接收,变量代表一个元组;
sun1 = fun(1,1)
print(sun1) #用相对应的个数的变量去接收,每一个变量代表一个值.
print(sun,b)
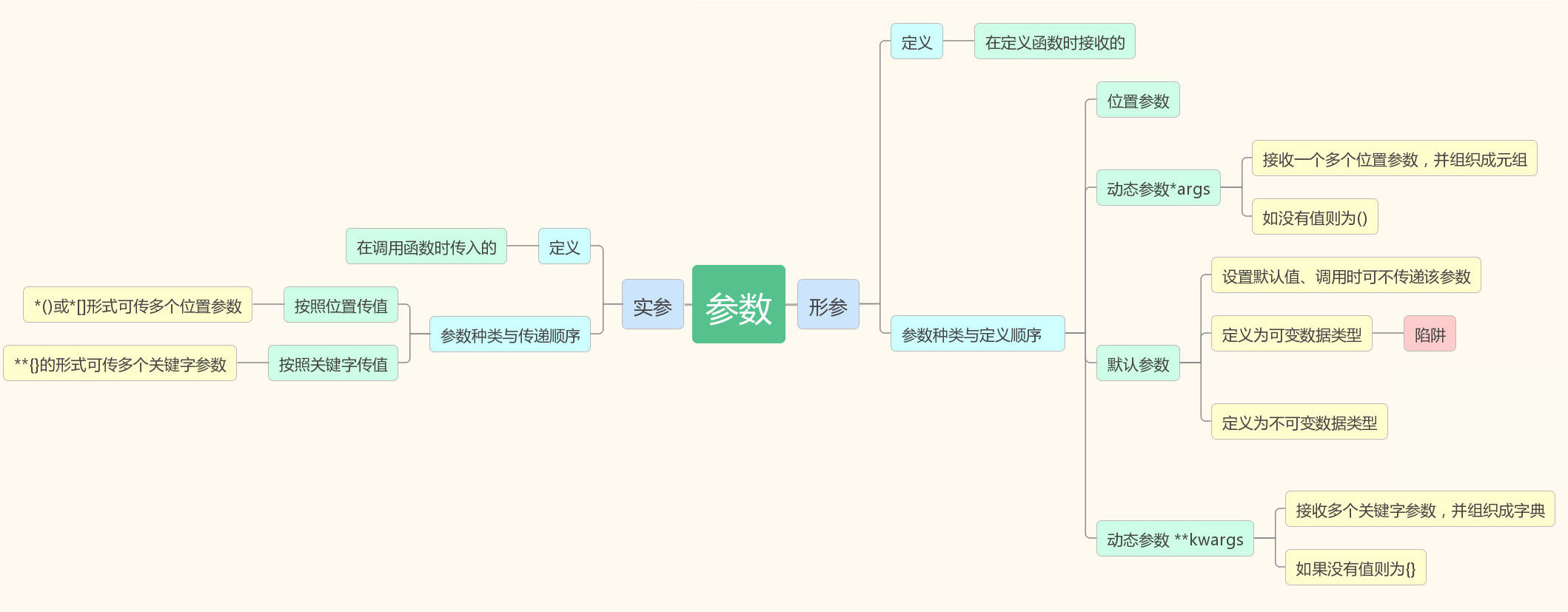
函数的参数
实参:调用函数传递的参数(实际的参数); 形参:定义函数时传递的参数;
站在实参的角度上:
1,按照位置传参;
2, 按照关键字传参
#位置传参必须在关键字传参之前;
形参里面的:
默认参数(不可变数据的类型);
#参数陷阱:默认参数是一个可变数据的类型;
# 如果默认参数的值是一个可变数据类型,
# 那么每一次调用函数的时候,
# 如果不传值就公用这个数据类型的资源
def defult_param(a,l = []):
l.append(a)
print(l) defult_param('alex')
defult_param('egon') #每次调用公用一个列表 #['alex'] #默认参数l里面只一个元素
#['alex', 'egon'] #l里面变成2个元素来;
站在形参的角度上:
1,按照位置传参;
2,按照动态传参(*args)
3,按照关键字传参(默认参数);
4,**kwargs
所有参数的传参的顺序是 位置参数,*args,关键字参数,**kwargs。
#参数的位置: 位置参数 ,*args, 默认参数,**kargs #*args :接收多个位置参数,组织成一个元组
#**kwargs可以接收多个关键字参数,组成成一个字典
# def func(*args ,**kwargs): #站在形参的角度上(定义函数的时候),给变量加上*;**,就是组合所有传来的值.
# print (args,kwargs)
# # return ('{},{}'.format(name,age))
# l = [1,2,3,'abc1']
# # l='12331231'
# a={'name':'zenghui','age':'22'}
#
# # func(1,2,3,name='zenghui',age = '22'
# func(*l,**a) #**就是将a的字典按照位置的顺序打散;
#站在实参的角度上(调用函数的时候),给一个序列加上*;**,就是将这个序列按照顺利打散.
函数的注释
def fun(a,b):
'''
函数的功能
param a(参数):
param b(参数):
return(返回值):
'''
c= a+b #函数的主体
return c,a
参数的总结:
命名空间和作用域python
python代码运行的时候碰到函数的运行过程:
第一步是python解释器先执行,然后在内存中开辟了一个空间,每当遇到一个变量的时候,就把变量名和值之间的对应的关系记录下来。但是当遇到函数的定义的时候,解释器只是将函数名读入内存中,表示这个函数的存在。但是不关心函数内部的变量以及名字。等到执行函数调用的时候,python解释器会再开辟一块内存开存储这个函数里面的内容,这个时候才关注函数里面有哪些变量,而函数中的变量会存储在新开辟出来的内存中。函数中的变量只能在函数的内部使用,并且会随着函数执行完毕,这块内存中的所有内容也会被清空。
我们给这个“存放名字与值的关系”的空间起了一个名字——叫做命名空间
代码在运行开始,创建的存储“变量名与值的关系”的空间叫做全局命名空间,在函数的运行中开辟的临时的空间叫做局部命名空间
有三种命名空间;分别为内置的命名空间;全局的命名空间;局部的命名空间;
#内置命名空间 —— python解释器
就是python解释器一启动就可以使用的名字存储在内置命名空间中
内置的名字在启动解释器的时候被加载进内存里
#全局命名空间 —— 我们写的代码但不是函数中的代码
是在程序从上到下被执行的过程中依次加载进内存的
放置了我们设置的所有变量名和函数名
#局部命名空间 —— 函数
就是函数内部定义的名字
当调用函数的时候 才会产生这个名称空间 随着函数执行的结束 这个命名空间就又消失了 在局部:可以使用全局、内置命名空间中的名字
在全局:可以使用内置命名空间中的名字,但是不能用局部中使用
在内置:不能使用局部和全局的名字的
在正常情况下,直接使用内置的名字
当我们在全局定义了和内置名字空间中同名的名字时,会使用全局的名字
当我自己有的时候 我就不找我的上级要了
如果自己没有 就找上一级要 上一级没有再找上一级 如果内置的名字空间都没有 就报错
多个函数应该拥有多个独立的局部名字空间,不互相共享
三种命名空间之间的加载与取值顺序:
加载顺序:内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
取值:
从底层开始往上寻找并且取值;
在局部调用的时候: 局部命名空间————全局命名空间————内置的命名空间
在全局调用的时间:全局命名空间————内置的命名空间
作用域
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
global 关键字:声明全局变量
对于不可变数据类型 在局部可是查看全局作用域中的变量
但是不能直接修改
如果想要修改,需要在程序的一开始添加global声明
如果在一个局部(函数)内声明了一个global变量,那么这个变量在局部的所有操作将对全局的变量有效
a=2
def fi():
a = 1
def f2():
global a
a+=1
print(a)
f2()
# print("--a---",a)
fi()
print(a)
globals和locals方法
#globals 永远打印全局的名字
#locals 输出什么 根据locals所在的位置
def func():
a = 12
b = 20
print(locals())
print(globals()) func()
#print(globals())打印的内置空间和局部空间的名字 #{'__name__': '__main__', '__doc__':.....
#print(locals()) 打印的是本地的空间的名字(此时的本地为函数内部即局部命名空间)即{'b': 20, 'a': 12}
def func():
a = 12
b = 20
# print(locals())
print(globals()) func()
print(locals())
#都是打印的内置空间和局部空间的名字 #{'__name__': '__main__', '__doc__':.....
#因为此时locals()的本地为全局
函数的嵌套和作用域链
#函数的嵌套定义
#内部函数可以使用外部函数的变量
def max2(x,y):
m = x if x>y else y
return m def max4(a,b,c,d):
res1 = max2(a,b)
res2 = max2(res1,c)
res3 = max2(res2,d)
return res3 # max4(23,-7,31,11)
函数的作用域链
def f1():
a = 1
def f2():
a = 2
f2()
print('a in f1 : ',a) f1()
nonlocal关键字
#nonlocal 只能用于局部变量 找上层中离当前函数最近一层的局部变量
#声明了nonlocal的内部函数的变量修改会影响到 离当前函数最近一层的局部变量
# 对全局无效
# 对局部 也只是对 最近的 一层 有影响
a=1 def outer():
a=1
def inner():
b=1
def inner2():
nonlocal a
# global a
a+=1
# print('小小局部',a) inner2()
# print('小局部',a)
inner()
print('局部:',a)
outer() print("全局:",a) #局部: 2
#全局: 1
函数名的本质
函数名本质上就是函数的内存地址
1.可以被引用
2.可以被当作容器类型(可变数据类型)的元素
3.可以当作函数的参数和返回值
def func():
print(123) # func() #函数名就是内存地址
func2 = func #函数名可以赋值
func2() l = [func,func2] #函数名可以作为容器类型的元素
print(l)
for i in l:
i()
'''
123
[<function func at 0x0000000002071E18>, <function func at 0x0000000002071E18>]
123
123
'''
def func():
print(123) def wahaha(f):
f()
return f #函数名可以作为函数的返回值 qqxing = wahaha(func) # 函数名可以作为函数的参数
qqxing() #123
#123
闭包:
闭包需要2个条件:嵌套函数;内部函数调用外部函数的变量
def outer():
a = 1
def inner():
print(a)
inner()
outer()
闭包常用的方法:在外面直接执行内部的函数
def outer():
a = 1
def inner():
print(a)
return inner inn = outer()
inn()
判断闭包函数的方法__closure__
def outer():
a = 1
def inner():
print(a)
print(inner.__closure__)
inner()
# print(outer.__closure__)
outer() #(<cell at 0x0000000009993C78: int object at 0x0000000060846B00>,)
#输出中有<cell的就为闭包函数
def outer():
a = 1
def inner():
print(1)
print(inner.__closure__)
inner()
outer()
#不是闭包函数,就输出为None
总结:
命名空间:
一共有三种命名空间从大范围到小范围的顺序:内置命名空间、全局命名空间、局部命名空间
作用域(包括函数的作用域链):
小范围的可以用大范围的
但是大范围的不能用小范围的
范围从大到小(图)

在小范围内,如果要用一个变量,是当前这个小范围有的,就用自己的
如果在小范围内没有,就用上一级的,上一级没有就用上上一级的,以此类推。
如果都没有,报错
函数的嵌套:
嵌套调用
嵌套定义:定义在内部的函数无法直接在全局被调用
函数名的本质:
就是一个变量,保存了函数所在的内存地址
闭包:
内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数
装饰器函数
装饰器形成的过程 : 最简单的装饰器 有返回值的 有一个参数 万能参数
装饰器的作用:在不改变函数调用方式的基础上,在函数的前、后添加功能。
原则 :开放封闭原则
语法糖 :@
装饰器的固定模式
def timmer(f): #装饰器函数
def inner():
start = time.time()
ret = f() #被装饰的函数
end = time.time()
print(end - start)
return ret
return inner @timmer #语法糖 @装饰器函数名
def func(): #被装饰的函数
time.sleep(0.01)
print('老板好同事好大家好')
return '新年好'
# func = timmer(func)
ret = func() #inner()
print(ret)
# 装饰器的作用 —— 不想修改函数的调用方式 但是还想在原来的函数前后添加功能
# timmer就是一个装饰器函数,只是对一个函数 有一些装饰作用
原则: 开放封闭原则
开放 : 对扩展是开放的
封闭 : 对修改是封闭的 带参数的装饰器
# def wrapper(f): #装饰器函数,f是被装饰的函数
# def inner(*args,**kwargs):
# '''在被装饰函数之前要做的事'''
# ret = f(*args,**kwargs) #被装饰的函数
# '''在被装饰函数之后要做的事'''
# return ret
# return inner
#
# @wrapper #语法糖 @装饰器函数名
# def func(a,b): #被装饰的函数
# time.sleep(0.01)
# print('老板好同事好大家好',a,b)
# return '新年好'
装饰器的固定模式
def wrapper(func): #qqxing
def inner(*args,**kwargs):
ret = func(*args,**kwargs) #被装饰的函数
return ret
return inner @wrapper #qqxing = wrapper(qqxing)
def qqxing():
print(123) ret = qqxing() #inner
时间功能的装饰器
import time def wrapper(func):
def inner(*args,**kwargs):
start=time.time()
ret = func(*args,**kwargs)
end = time.time()
print(end - start)
return ret
return inner @wrapper #qqxing = wrapper(qqxing)
def qqxing(a,b):
ret=a+b
time.sleep(0.1)
return ret print(qqxing(1,2))
from functools import wraps
wraps(func)是python提供的给装饰器函数专门用来恢复被装饰函数性状的机制
import time
def wrapper(func):
# @wraps(func) #带参数的装饰器
def inner(*args,**kwargs):
start=time.time()
ret = func(*args,**kwargs)
end = time.time()
print(end - start)
return ret
return inner @wrapper #qqxing = wrapper(qqxing)
def qqxing(a,b):
'''
这是一个记录运行时间的代码
:param a:
:param b:
:return:
'''
ret=a+b
time.sleep(0.1)
return ret print(qqxing(1,2))
print(qqxing.__name__)
print(qqxing.__doc__)
#
#
# #结果为 0.10000038146972656
# #3
# #inner #实际上被装饰器的函数为inner
# #None import time
from functools import wraps
def wrapper(func):
@wraps(func) #带参数的装饰器
def inner(*args,**kwargs):
start=time.time()
ret = func(*args,**kwargs)
end = time.time()
print(end - start)
return ret
return inner @wrapper #qqxing = wrapper(qqxing)
def qqxing(a,b):
'''
这是一个记录运行时间的代码
:param a:
:param b:
:return:
'''
ret=a+b
time.sleep(0.1)
return ret print(qqxing(1,2))
print(qqxing.__name__)
print(qqxing.__doc__) #函数的注释 #结果为:0.09999990463256836
#3
#qqxing #在装饰器内部的函数加上了一个wraps带参数的装饰器,这样被装饰函数就是自己了
'''
这是一个记录运行时间的代码
:param a:
:param b:
:return:
'''
带参数的装饰器可以方便的控制装饰器的取消.
import time
from functools import wraps
flag = True
def outer(flag):
def wrapper(func):
@wraps(func) #带参数的装饰器
def inner(*args,**kwargs):
if flag:
start=time.time()
ret = func(*args,**kwargs)
end = time.time()
print(end - start)
return ret
else:
ret = func(*args, **kwargs)
return ret
return inner
return wrapper @outer(flag) #带参数的装饰器 #qqxing = wrapper(qqxing)
def qqxing(a,b):
ret=a+b
time.sleep(0.1)
return ret print(qqxing(1,2))
多个装饰器控制一个函数
#多个装饰器控制一个函数
#离函数最近的装饰器函数先执行
from functools import wraps
flag = True
def outer1(flag):
def wrapper1(func): #func ---> func
@wraps(func)
def inner1(*args,**kwargs):
if flag:
print('函数之前执行w1')
ret1 =func(*args,**kwargs) #func()
print('函数之后结束w1')
return ret1 #ret1 = ret
else:
ret1 = func(*args, **kwargs)
return ret1
return inner1
return wrapper1 def outer2(flag):
def wrapper2(func): #func ----> inner1
@wraps(func)
def inner2(*args,**kwargs):
if flag:
print('函数之前执行w2')
ret2 =func(*args,**kwargs) #inner1()
print('函数之后结束w2')
return ret2 # ret2 = ret1= ret
else:
ret2 = func(*args, **kwargs)
return ret2
return inner2
return wrapper2 # wrapper1 = outer1(flag)
# wrapper2 = outer2(flag)
#
# @wrapper2 #func = w2(func) = w2(inner1) --->inner2
# @wrapper1 #func = w1(func) ---> inner1
# def func():
# print('123')
# ret ='hahha'
# return ret @outer2(flag) #func = w2(func) = w2(inner1) --->inner2
@outer1(flag) #先执行 outer1装饰器函数 #func = w1(func) ---> inner1
def func():
print('123')
ret ='hahha'
return ret ret = func() #func() ----> innner2()
print(ret)
print(func.__name__)
迭代器(iterator)
可以被for循环的就是可迭代的(iterable),所以说str,list,dic,tuple,set,文件句柄(f=open()),range(),enumerate都是可迭代的,同时他们中的双下方法都含有__iter__,因此只要是能被for循环的数据类型 就一定拥有__iter__方法,就一定是可迭代的。
[].__iter__()则返回的就是一个迭代器。,即可迭代的对象.__iter__就返回一个迭代器。迭代器里面重要的2个双下方法就是__iter__和__next__。所以只要有这2个内置方法就是一个迭代器。
Iterable 可迭代的 -- > __iter__ ;只要含有__iter__方法的都是可迭代的.
可迭代的对象.__iter__() 迭代器 -- > __next__ ;通过next就可以从迭代器中一个一个的取值。
只要含有__iter__方法的都是可迭代的 —— 可迭代协议
迭代器的概念:
迭代器协议 —— 内部含有__next__和__iter__方法的就是迭代器
迭代器协议和可迭代协议
可以被for循环的都是可迭代的
可迭代的内部都有__iter__方法
只要是迭代器 一定可迭代
可迭代的对象.__iter__()方法就可以得到一个迭代器。
迭代器中的__next__()方法可以一个一个的获取值;
for循环,就是在内部帮助可迭代对象变成一个迭代器,然后调用__next__方法来取值;其实就是在使用迭代器iterator可迭代对象直接给你内存地址;
只有可迭代对象才能for循环,因此在我们遇到一个新的变量的时候,不确定能不能用for循环的时候,就判断它是否可迭代.(通过dir(数据类型(变量))查看内部是否含有__iter__方法)
# for i in l:
# pass
#iterator = l.__iter__()
#iterator.__next__()
迭代器的好处:
从容器类型中一个一个的取值,会把所有的值都取到。
从而节省内存空间。
迭代器并不会在内存中再占用一大块内存,
而是随着循环,每次生成一个
每次用next方法每次给我一个。
生成器------>迭代器(generator)
生成器表达形式:
1.生成器函数——本质上就是我们自己写的函数,只不过返回值要用yield 来返回;每__next__一次执行一次yield。
生成器函数()调用之后不执行函数里面的代码,而是返回 一个迭代器 (<generator object tail at 0x0000000009D01DB0>)
2.生成器表达式
Python中提供的生成器:
1.生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,不会结束,以便下次重它离开的地方继续执行
def func():
for i in range(10):
yield '娃哈哈%s'%i a = func()
print(a.__next__()) #娃哈哈0
print(a.__next__()) #娃哈哈1
print(a.__next__()) #娃哈哈2
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
生成器Generator:
本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
特点:惰性运算,开发者自定义
生成器的2个特点:
1.一个生成器中的数据只能从头到尾读取一次,读取完了就没有了。
2.惰性运算是指不找它取值,它就不工作,而且找它要一个,它就给你一个。
生成器函数的列子(监听文件输入的列子)
def tail(filename):
f = open(filename,encoding='utf-8')
while True:
line = f.readline()
if line.strip('\r\n'):
yield line.strip() #把文件返回用作过滤文件的内容,不用return ,用了函数就执行结束了。 data=tail('file') #用生成器来过滤
for i in data:
if 'python' in i :
print(i)
send方法
send 获取下一个值的效果和next基本一致;
只是在获取下一个值的时候,给上一yield的位置传递一个数据。
使用send的注意事项:第一次使用生成器的时候 是用next获取下一个值;最后一个yield不能接受外部的值
def generator():
print('123')
ret = yield 1
print('#####',ret)
print('456')
yield 2
print('789')
ret = yield 3
print(ret)
''' '''
yield
g = generator()
ret = g.__next__()
print(ret)
ret1 =g.send('marry') #send的效果和__next__效果一样,只不过send可以给上一个yield传一个值。
print(ret1)
ret = g.__next__()
print(ret)
计算移动平均值的生成器,只不过每次第一步的时候要使用next方法;
def average():
sum = 0
count = 0
avg = 0
while True:
ret = yield avg
sum += ret
count += 1
avg = sum/count a = average()
a.__next__()
print(a.send(10))
print(a.send(20))
因此有了预激生成器的装饰器,为了方便多个函数的时候,不用再外面写next方法‘
def gener_waper(func):
def inner(*args,**kwargs):
ret = func(*args,**kwargs)
ret.__next__()
return ret
return inner @gener_waper
def average():
sum = 0
count = 0
avg = 0
while True:
ret = yield avg
sum += ret
count += 1
avg = sum/count a = average()
print(a.send(10))
print(a.send(20))
yield from 返回最小的字符,即拆分
def generator():
a = ['123456','aaaaa','aa']
b = {'name':'zenghui','age':24}
b = {'name': 'zenghui', 'age': 24}.items()
yield from a #单个返回
yield from b #若为字典,则返回k g = generator()
for i in g:
print(i)
列表推导式和生成器表达式
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存,不占用内存.
a = (i*i for i in range(10)) #生成器表达式 list = [ i for i in range(10)] #列表推导式 print(list) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a) #<generator object <genexpr> at 0x0000000009D01DB0>
for i in a:
print(i)
#1 4 9 16 25 36 49 64 81
完整的列表推导式:
1.遍历取所有的值
2.筛选功能
[ 每一个元素或者是和元素的相关操作 for 元素 in 可迭代的数据类型 ] # 遍历挨个取值
[ 每一个元素或者是和元素的相关操作 for 元素 in 可迭代的数据类型 if 元素相关的条件 ] #筛选功能
#输出30以内被3整除的数
ret = [ i*i for i in range(30) if i%3==0]
print(ret)
生成器相关的面试题:
#生成器的面试题1
# def genger():
# for i in range(4):
# yield i
#
# g = genger()
#
# g1 = ( i for i in g)
# # print(list(g1))
# # print(g1)
# g2 = ( i for i in g1)
# print(list(g2))
#面试题2 def add(n,i):
return n+i def gen():
for i in range(4):
yield i g = gen() for n in [1,10]:
g = (add(n,i) for i in g)
print(list(g)) # n = 1
# g = (add(n,i) for i in gen()) #g = [0,1,2,3]
# # print(list(g)) #一个生成器只能取一次,取完就没了
# n= 10 # i :10,11,12,13 n :10
# g = (add(n,i) for i in (add(n,i) for i in gen())) #没有取值还是一个生成器;
# # for i in (0,1,2,3)
# # (10,11,12,13)
# # (20,21,22,23)
# # print(list(g))
# print(list(g)) #取值的时候才执行调用生成器 n = 10 ,g = [10,11,12,13], for i in g for n in [1,10,5]: #碰到循环生成器的时候需要拆开分析
g = (add(n, i) for i in g) print(list(g)) # n = 1
# g = (add(n, i) for i in gen())
# n = 10
# g = (add(n, i) for i in (add(n, i) for i in gen()))
# n = 5
# g = (add(n, i) for i in (add(n, i) for i in (add(n, i) for i in gen())))
# # (0,1,2,3)
# # (5,6,7,8)
# # (10,11,12,13)
# # (15,16,17,18)
# print(list(g)) #取值,生成器里面的代码才执行
python 基础知识点二的更多相关文章
- Python 基础语法(二)
Python 基础语法(二) --------------------------------------------接 Python 基础语法(一) ------------------------ ...
- python基础知识(二)
python基础知识(二) 字符串格式化 格式: % 类型 ---- > ' %类型 ' %(数据) %s 字符串 print(' %s is boy'%('tom')) ----> ...
- Python基础学习二
Python基础学习二 1.编码 utf-8编码:自动将英文保存为1个字符,中文3个字符.ASCll编码被囊括在内. unicode:将所有字符保存为2给字符,容纳了世界上所有的编码. 2.字符串内置 ...
- 最全Python基础知识点梳理
本文主要介绍一些平时经常会用到的python基础知识点,用于加深印象,也算是对于学习这门语言的一个总结与回顾.python的详细语法介绍可以查看官方编程手册,也有一些在线网站可以学习 python语言 ...
- Python之路:Python 基础(二)
一.作用域 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. if 1==1: name = 'lenliu' print name 下面的结论对吗?(对) 外层变量,可以被 ...
- Python基础知识点总结
Python基础知识与常用数据类型 一.Python概述: 1.1.Python的特点: 1.Python是一门面向对象的语言,在Python中一切皆对象 2.Python是一门解释性语言 3.Pyt ...
- Python基础篇(二)_基本数据类型
Python基础篇——基本数据类型 数字类型:整数类型.浮点数类型.复数类型 整数类型:4种进制表示形式:十进制.二进制.八进制.十六进制,默认采用十进制,其他进制需要增加引导符号 进制种类 引导符号 ...
- Python基础知识点小结
1.Python基础知识 在Python中的两种注释方法,分别是#注释和引号(''' ''')注释,#注释类似于C语言中的//注释,引号注释类似于C语言中的/* */注释.接着在Python中 ...
- python 基础知识点整理 和详细应用
Python教程 Python是一种简单易学,功能强大的编程语言.它包含了高效的高级数据结构和简单而有效的方法,面向对象编程.Python优雅的语法,动态类型,以及它天然的解释能力,使其成为理想的语言 ...
随机推荐
- mybatis11--多对多关联查询
多对多关联! 其实就是两个一对多的关联! 比如说 一个学生可以有多个老师!一个老师可以有多个学生! 那么 学生和老师之间的关系 可以理解为 多对多的关联关系! 关键是怎么建立数据库中两个表之间的关系 ...
- yarn卸载或增加节点
yarn卸载或增加节点 卸载节点或者增加节点: 方式一:静态的增添删除:将集群关闭,修改配置文件(etc/hadoop/slaves),重新启动集群(很黄很暴力,不够人性化). 方式二:动态的增加 ...
- Tomcat部署工程需注意的三点
Tomcat部署工程需注意: 1.如果该服务器是第一安装Tomcat,则各位大人应将该Tomcat的解压文件夹 backup 一份,已被不时之用.2.部署时应当注意修改Tomcat安装目录中conf文 ...
- ERP项目实施记录09
今天报价软件测试版本出来了,可看上去不怎么像是一款报价的软件,整个界面上都没有"报价"相关的字眼: 软件标题就不说了,反正影响不大,就当没看见,可左边这一大片菜单里也找不到和报价有 ...
- Codeforces 1072 - A/B/C/D - (Done)
链接:http://codeforces.com/contest/1072/ A - Golden Plate - [计算题] #include<bits/stdc++.h> using ...
- 洛谷P1021邮票面值设计 [noip1999] dp+搜索
正解:dfs+dp 解题报告: 传送门! 第一眼以为小凯的疑惑 ummm说实话没看标签我还真没想到正解:D 本来以为这么多年前的noip应该不会很难:D 看来还是太菜了鸭QAQ 然后听说题解都可以被6 ...
- MongoDB 目录
MongoDB 介绍 centos7.6 安装与配置 MongoDB yum方式 MongoDB 数据库操作 MongoDB 用户管理 MongoDB 新建数据库和集合 查询集合 MongoDB 增删 ...
- Oracle 数据库逻辑结构.md
一.存储关系Oracle 数据库逻辑上是由一个或多个表空间组成的,表空间物理上是由一个或多个数据文件组成的:而在逻辑上表空间又是由一个或多个段组成的.在Oracle 数据库中,通过为每种不同的数据对象 ...
- node os模块
const os = require('os'); console.log(os.homedir()); console.log(os.hostname()); console.log(os.plat ...
- [js]面向对象2
delete删除属性 删除对象的属性 删除未用var定义的变量. delete返回布尔 删除不存在的属性,返回true 无法删除原形中的属性 如 delete obj.toString() resu= ...