Learning-Python【8】:Python字符编码
1、内存和硬盘都是用来存储的
内存:速度快
硬盘:永久保存
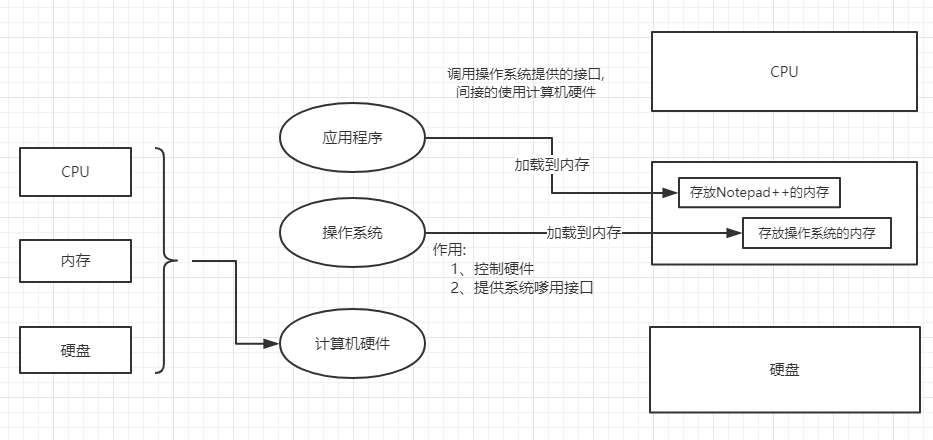
2、文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就可以启动一个进程,是在内存中的,所以在编辑器编写的内容也都是存放在内存中的,断电后数据就丢失了。因而需要保存在硬盘上,点击保存按钮或快捷键,就把内存中的数据保存到了硬盘上。在这一点上,我们编写的py文件(没有执行时),跟编写的其他文件没有什么区别,都只是编写一堆字符而已。
3、Python解释器执行py文件的原理,例如 python test.py
第一阶段:启动Python解释器,这就相当于启动了一个文本编辑器
第二阶段:将硬盘上的test.py文件当作文本文件读入内存
第三阶段:Python解释器执行刚刚加载到内存中的 test.py 的代码(在该阶段,即执行时,才会识别Python的语法,执行到字符串时,会开辟内存空间存放字符串)
总结:Python解释器与文本编辑器的异同
相同点:Python解释器是解释执行文件内容的,因而Python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python的语法)
4、什么是字符编码
计算机想要工作必须通电,高低电平(高电平即二进制数1,低电平即二进制数0)就是计算机的工作方式,也就是说计算机只认识数字。那么让计算机如何读懂人类的字符呢?
这就必须经过一个过程:
字符---------(翻译过程)-------------数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
5、以下两个场景涉及到字符编码的问题:
1)一个Python文件中的内容是由一堆字符组成的(Python文件未执行时)
2)Python中的数据类型字符串是由一串字符组成的(Python文件执行时)
6、字符编码的发展史
阶段一:计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII码:只能识别英文字符,一个字节(Bytes)代表一个英文字符或键盘上的所有其他字符,1Bytes = 8bit(比特位),8bit 可以表示 0 —— (2^8-1) 种变化,即可以表示256个字符。
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符,为了满足其他国家,各个国家纷纷定制了自己的编码,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里。
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码,于是产生了Unicode
统一用 2Bytes 代表一个字符,2^16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间,于是产生了UTF-8,对英文字符只用 1Bytes 表示,对中文字符用 3Bytes。
需要强调的是:
Unicode:简单粗暴,多有的字符都是2Bytes,优点是字符--数字的转换速度快;缺点是占用空间大。
UTF-8:精准,可变长,优点是节省空间;缺点是转换速度慢,因为每次转换都需要计算出需要多长Bytes才能够准确表示。
1、内存中使用的编码是Unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是越快越好)
2、硬盘中或网络传输用UTF-8,保证数据传输的稳定性。
所有程序,最终都要加载到内存,程序保存到硬盘,不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因就在于此),统一且固定使用Unicode
这就是为何内存固定用Unicode的原因,你可能会说兼容万国我可以用UTF-8啊,可以,完全可以正常工作,之所以不用肯定是Unicode比UTF-8更高效(Unicode固定用2个字节编码,UTF-8则需要计算),但是Unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把Unicode转成UTF-,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成UTF-8格式的,而不是Unicode。
为什么内存使用Unicode不使用UTF-8
7、字符编码转换
字符 --- 编码 --> Unicode的二进制 ------- 编码 -----> GBK的二进制
GBK的二进制 ----- 解码 --> unicode的二进制 ---- 解码 --> 字符
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
乱码:存文件时就已经乱码 或者 存文件时不乱码而读文件时乱码
总结:无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,字符用什么编码格式编码的,就应该用什么编码格式进行解码
8、 Python解释器默认的字符编码
例:文件 test.py 以 gbk 格式保存,内容为:
x = '湫'
无论是python2 test.py,还是python3 test.py,都会报错,因为解释器默认的字符编码:
Python2:ASCII
Python3:UTF-8
通过文件头可以修改Python解释器默认使用的字符编码,在文件首行写:#coding: 后面跟上文件当初存的时候用的字符编码
9、程序的执行
python3 test.py 或 python2 test.py(执行test.py的第一步,一定是先将文件内容读入到内存中)
阶段一:启动Python解释器
阶段二:Python解释器此时就是一个文本编辑器,负责打开文件test.py,即把硬盘中 test.py 的内容读取到内存中
此时,Python解释器会读取 test.py 的第一行内容,#coding :utf-8,来决定以什么编码格式来读入内存,这一行就是来设定Python解释器这个软件的编码使用的编码格式,其中这个编码,Python2默认使用ASCII,Python3默认使用UTF-8
阶段三:解释器读取已经加载到内存的代码(Unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如 x = "qiuxi"
注意:
内存的编码使用Unicode,不代表内存中全都是Unicode编码的二进制
在程序执行之前,内存中确实都是Unicode编码的二进制,比如从文件中读取了一行 x = "qiuxi",其中的x,赋值号,引号,地位都一样,都是普通字符而已,都是以Unicode编码的二进制形式存放于内存中的,但是程序在执行过程中,会申请内存(与程序代码所存在的内存是两个空间),可以存放任意编码格式的数据,比如x = "qiuxi",会被Python解释器识别为字符串,会申请内存空间来存放"qiuxi",然后让 x 指向该内存地址,此时新申请的内存地址保存的也是Unicode编码的qiuxi,如果代码换成 x = "qiuxi".encode('utf-8'),那么新申请的内存空间里存放的就是UTF-8编码的字符串qiuxi了
10、Python2与Python3的区别
在Python2中有两种字符串相关类型:str 和 Unicode
# -*- coding: utf-8 -*-
s = '林' # 在执行时,'林'会被utf-8的形式保存到新的内存空间中 print repr(s) # '\xe6\x9e\x97' 三个Bytes,证明确实是utf-8
print type(s) # <type 'str'> s.decode('utf-8')
# s.encode('utf-8') # 报错,s为编码后的结果bytes,所以只能decode
当Python解释器执行到产生字符串的代码时(例如s = u'林'),会申请新的内存地址,然后将 '林' 以Unicode的格式存放到新的内存空间中,所以 s 只能encode,不能decode
s = u'林'
print repr(s) # u'\u6797'
print type(s) # <type 'unicode'> # s.decode('utf-8') # 报错,s为Unicode,所以只能encode
s.encode('utf-8')
对于unicode格式的数据来说,无论怎么打印,都不会乱码
Python3中的字符串与Python2中的u'字符串',都是Unicode,所以无论如何打印都不会乱码
在python3中也有两种字符串相关类型:str 和 bytes
str是Unicode
# -*- coding: utf-8 -*-
s = '林' # 当程序执行时,无需加u,'林'也会被以Unicode形式保存新的内存空间中, # s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk') print(type(s)) # <class 'str'>
Learning-Python【8】:Python字符编码的更多相关文章
- python基础_字符编码
字符编码的历史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 阶段二:为了满足中文,中国人定制了GBK 阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的 ...
- 第1章 Python基础之字符编码
阅读目录 一.什么是字符编码 二.字符编码分类 三.字符编码转换关系 3.1 程序运行原理 3.2 终极揭秘 3.3 补充 总结 回到顶部 一.什么是字符编码 计算机要想工作必须通电,也就是说'电'驱 ...
- 永久修改python默认的字符编码为utf-8
这个修改说来简单,其实不同的系统,修改起来还真不一样.下面来罗列下3中情况 首先所有修改的动作都是要创建一个叫 sitecustomize.py的文件,为什么要创建这个文件呢,是因为python在启动 ...
- Python基础之字符编码
前言 字符编码非常容易出问题,我们要牢记几句话: 1.用什么编码保存的,就要用什么编码打开 2.程序的执行,是先将文件读入内存中 3.unicode是父编码,只能encode解码成其他编码格式 utf ...
- python 基础之字符编码和文件处理
一.字符编码 (1)计算机基础知识 (2)python 解释器执行py文件的原理 <1>python 解释器启动 <2>python解释器相当于一个文本编辑器,打开txt.py ...
- Python系列之 - 字符编码问题
1.内存和硬盘都是用来存储的. CPU:速度快 硬盘:永久保存 2.文本编辑器存取文件的原理(nodepad++,pycharm,word) 打开编辑器就可以启动一个进程,是在内存中的,所以在编辑器编 ...
- (Python基础)字符编码与转码
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧 ...
- Python编程Day7——字符编码、字符与字节、文件操作
一.字符编码 重点 ***** 1. 什么是字符编码:将人识别的字符转换计算机能识别的01,转换的规则就是字符编码表2. 常用的编码表:ascii.unicode.GBK.Shift_JIS.Euc- ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- 第一章:python基础语法| 字符编码| 条件语句...
1.编程语言介绍 编程就是写代码,让计算机帮你做事情.计算机底层是电路,只认识二进制0和1.机器语言&汇编语言语言进化历史:机器.汇编.高级.机器语言只接受二进制代码:汇编语言是采用英文缩写的 ...
随机推荐
- 10、DOM(文档对象模型)
1.认识DOM html 骨架 css 装修 javascript 物业 ==DOM 打破上述三者的通道.== [注]script标签一般情况下要写在head标签. <div id ...
- 有关自动化构建gulp的搭建
1,cnpm instal bower -g 2, cnpm install bower 3, bower init 生成bower.json文件 4, type null >.bowerr ...
- mpdf中文开发使用文档附demo实例
官网URL:http://www.mpdf1.com/mpdf/index.php github:https://github.com/mpdf/mpdf 官方开发手册,英文的:http://www. ...
- 1.7Oob方法的作用
public class Exse2 { public static void main(String[] args) { sumIntLong(10,15); sumIntLong(20,30); ...
- 从session中获取当前用户的工具类
package cn.crmx.crm.util; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.Ht ...
- bounds的应用
frame是参考父view的坐标系来设置自己左上角的位置.设置bounds可以修改自己坐标系的原点位置,进而影响到其“子view”的显示位置. 向上滚动scrollview,我们就不断增加scro ...
- Java-idea-安装配置优化等
1.属性配置 使用版本,winzip解压版,开发工具安装目录下idea.properties文件,自定义配置路径 # idea.config.path=${user.home}/.IntelliJId ...
- 数据模型model设置、生成数据迁移文件、执行数据迁移文件
一.model的配置 1.创建数据库 2.安装pymysql 3.修改配置文件 数据库连接配置 DATABASES = {'default': {'ENGINE': 'django.db.backen ...
- MySQL Workbench在archlinux中出现 Could not store password: The name org.freedesktop.secrets was not provided by any .service files的错误
MySQL Workbench在archlinux中出现 Could not store password: The name org.freedesktop.secrets was not prov ...
- Zookeeper应用之——选举(Election)
请注意,此篇文章并不是介绍Zookeeper集群内部Leader的选举机制,而是应用程序使用Zookeeper作为选举. 使用Zookeeper进行选举,主要用到了Znode的两个性质: 临时节点(E ...