hadoop系列 第一坑: hdfs JournalNode Sync Status
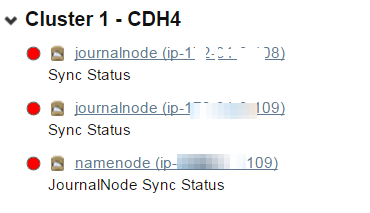
今天早上来公司发现cloudera manager出现了hdfs的警告,如下图:




IPC Server handler on , call org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.getEditLogManifest from 172.31.13.29:: error: org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /hadop-cdh-data/jddfs/nn/journalhdfs1 not formatted
org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /hadop-cdh-data/jddfs/nn/journalhdfs1 not formatted
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkFormatted(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.getEditLogManifest(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$.callBlockingMethod(QJournalProtocolProtos.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
IPC Server handler on , call org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.heartbeat from 172.31.9.109:: error: java.io.FileNotFoundException: /hadop-cdh-data/jddfs/nn/journalhdfs1/current/last-promised-epoch.tmp (No such file or directory)
java.io.FileNotFoundException: /hadop-cdh-data/jddfs/nn/journalhdfs1/current/last-promised-epoch.tmp (No such file or directory)
at java.io.FileOutputStream.open(Native Method)
at java.io.FileOutputStream.<init>(FileOutputStream.java:)
at java.io.FileOutputStream.<init>(FileOutputStream.java:)
at org.apache.hadoop.hdfs.util.AtomicFileOutputStream.<init>(AtomicFileOutputStream.java:)
at org.apache.hadoop.hdfs.util.PersistentLongFile.writeFile(PersistentLongFile.java:)
at org.apache.hadoop.hdfs.util.PersistentLongFile.set(PersistentLongFile.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.updateLastPromisedEpoch(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.heartbeat(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.heartbeat(JournalNodeRpcServer.java:)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.heartbeat(QJournalProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$.callBlockingMethod(QJournalProtocolProtos.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
scp -r -i /root/xxxxxxx.pem root@ip-xxx-xx-xx-111:/hadop-cdh-data/jddfs/nn/journalhdfs1 ./
chown -R hdfs:hdfs journalhdfs1
hadoop系列 第一坑: hdfs JournalNode Sync Status的更多相关文章
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop优化 第一篇 : HDFS/MapReduce
比较惭愧,博客很久(半年)没更新了.最近也自己搭了个博客,wordpress玩的还不是很熟,感兴趣的朋友可以多多交流哈!地址是:http://www.leocook.org/ 另外,我建了个QQ群:3 ...
- hadoop系列 第二坑: hive hbase关联表问题
关键词: hive创建表卡住了 创建hive和hbase关联表卡住了 其实针对这一问题在info级别的日志下是看出哪里有问题的(为什么只能在debug下才能看见呢,不太理解开发者的想法). 以调试模式 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- Hadoop 系列(一)—— 分布式文件系统 HDFS
一.介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错.高吞吐量等特性,可以部署在低成本的硬件上. 二.HDFS 设计原理 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop系列007-HDFS客户端操作
title: Hadoop系列007-HDFS客户端操作 date: 2018-12-6 15:52:55 updated: 2018-12-6 15:52:55 categories: Hadoop ...
随机推荐
- easyui combobox下拉列表的多选值
html: <input id="cc" class="easyui-combobox" value="" data-options= ...
- 由sql注入联想到PreparedStatement
PreparedStatement极大地提高了安全性. 即使到目前为止,仍有一些人连基本的恶意SQL语法都不知道. String sql = "select * from tb_ ...
- 基于Asp.Net Core的简单社区项目源代码开源
2019年3月27号 更新版本 本项目基于 ASP.NET CORE 3.0+EF CORE 3.0开发 使用vs2019 +sqlserver 2017(数据库脚本最低支持sql server 20 ...
- [转]完整记录在 windows7 下使用 docker 的过程
本文转自:https://www.jianshu.com/p/d809971b1fc1 借助 docker 可以不在开发电脑中安装环境,比如 nodejs,记录下如何实现. 下载安装 根据自己的电脑系 ...
- LeetCode 键盘行-Python3.7<四>
500. 键盘行 题目网址:https://leetcode-cn.com/problems/keyboard-row/hints/ 给定一个单词列表,只返回可以使用在键盘同一行的字母打印出来的单词. ...
- WebFrom 【文件上传】
文件上传 准备工作1.文件上传的页面2.上传文件要保存的文件夹 1.只要将文件传上来就行 //1.获取要上传的文件,并且知道要上传到服务器的路径 string s = "Uploads/aa ...
- DataTable的一个简单的扩展
我们在调试代码的时候经常遇到DataTable的数据类型错误,这个类可以帮助我们很快查看DataTable的结构信息. /// <summary> /// DataTable扩展类 /// ...
- 8.中断按键驱动程序之poll机制(详解)
本节继续在上一节中断按键程序里改进,添加poll机制. 那么我们为什么还需要poll机制呢.之前的测试程序是这样: ) { read(fd, &key_val, ); printf(" ...
- cSharp:use Activator.CreateInstance with an Interface?
///<summary> ///数据访问工厂 ///生成時間2015-2-13 10:54:34 ///塗聚文(Geovin Du) /// (利用工厂模式+反射机制+缓存机制,实现动态创 ...
- CSS&JS两种方式实现手风琴式折叠菜单
<div class="accordion"> <div id="one" class="section"> < ...