c++ 异常处理(2)
前面一篇博文简单介绍了 c++ 异常处理的流程,但在一些细节上一带而过了,比如,_Unwind_RaiseException 是怎样重建函数现场的,Personality routine 是怎样清理栈上变量的等,这些细节涉及到很多与语言层面无关的东西,本文尝试介绍一下这些细节的具体实现。
相关的数据结构
如前所述,unwind 的进行需要编译器生成一定的数据来支持,这些数据保存了与每个可能抛异常的函数相关的信息以供运行时查找,那么,编译器都保存了哪些信息呢?根据 Itanium ABI 的定义,主要包括以下三类:
1)unwind table,这个表记录了与函数相关的信息,共三个字段:函数的起始地址,函数的结束地址,一个 info block 指针。
2)unwind descriptor table,这个列表用于描述函数中需要 unwind 的区域的相关信息。
3)语言相关的数据(language specific data area),用于上层语言内部的处理。
以上数据结构的描述来自 Itanium ABI 的标准定义,但在具体实现时,这些数据是怎么组织以及放到了哪里则是由编译器来决定的,对于 GCC 来说,所有与 unwind 相关的数据都放到了 .eh_frame 及 .gcc_except_table 这两个 section 里面了,而且它的格式与内容和标准的定义稍稍有些不同。
.eh_frame区域
.eh_frame 的格式与 .debug_frame 是很相似的(不完全相同),属于 DWARF 标准中的一部分。所有由 GCC 编译生成的需要支持异常处理的程序都包含了 DWARF 格式的数据与字节码,这些数据与字节码的主要作用有两个:
1)描述函数调用栈的结构(layout)
2)异常发生后,指导 unwinder 怎么进行 unwind。
DWARF 字节码功能很强大,它是图灵完备的,这意味着仅仅通过 DWARF 就可以做几乎任何事情(therotically)。但是从数据的组织上来看,DWARF 实在略显复杂晦涩,因此很少有人愿意去碰,本文也只是简单介绍其中与异常处理相关的东西。本质上来说,eh_frame 像是一张表,它用于描述怎样根据程序中某一条指令来设置相应的寄存器,从而返回到当前函数的调用函数中去,它的作用可以用如下表格来形象地描述。
| program counter | CFA | ebp | ebx | eax | return address |
| 0xfff0003001 | rsp+32 | *(cfa-16) | *(cfa-24) | eax=edi | *(cfa-8) |
| 0xfff0003002 | rsp+32 | *(cfa-16) | eax=edi | *(cfa-8) | |
| 0xfff0003003 | rsp+32 | *(cfa-16) | *(cfa-32) | eax=edi | *(cfa-8 |
上表中,CFA(canonical frame address) 表示一个基地址,用于作为当前函数中的其它地址的起始地址,使得其它地址可以用与该基地址的偏移来表示,由于这个表可能要覆盖很多程序指令,因此这个表的体积有可能是很大的,甚至比程序本身的代码量还要大。而在实际中,为了减少这个表的体积,GCC 通常会对它进行压缩编码,以及尽可能减少要覆盖的指令的数量,比如,只对会抛异常的函数里的特定区域指令进行记录。
具体的实现上,eh_frame 由一个CIE (Common Information Entry) 及多个 FDE (Frame Description Entry) 组成,它们在内存中是连续存放的:

CIE 及 FDE 格式的定义可以参看如下:
CIE结构:
|
Length |
Required |
| Extended Length | Optional |
| CIE ID | Required |
| Version | Required |
| Augmentation String | Required |
| EH Data | Optional |
| Code Alignment Factor | Required |
| Data Alignment Factor | Required |
| Return Address Register | Required |
| Augmentation Data Length | Optional |
| Augmentation Data | Optional |
| Initial Instructions | Required |
| Padding |
FDE结构:
| Length | Required |
| Extended Length | Optional |
| CIE Pointer | Required |
| PC Begin | Required |
| PC Range | Required |
| Augmentation Data Length | Optional |
| Augmentation Data | Optional |
| Call Frame Instructions | Required |
| Padding |
注意其中标注红色的字段:
1)Initial Instructions,Call Frame Instructions 这两字段里放的就是所谓的 DWARF 字节码,比如:DW_CFA_def_cfa R OFF,表示通过寄存器 R 及位移 OFF 来计算 CFA,其功能类似于前面的表格中第二列指明的内容。
2)PC begin,PC range,这两个字段联合起来表示该 FDE 所能覆盖的指令的范围,eh_frame 中所有的 FDE 最后会按照 pc begin 排序进行存放。
3)如果 CIE 中的 Augmentation String 中包含有字母 "P",则相应的 Augmentation Data 中包含有指向 personality routine 的指针。
4)如果 CIE 中的 Augmentation String 中包含有有字母“L”,则 FDE 中 Aumentation Data 包含有 language specific data 的指针。
对一个elf文件通过如下命令:readelf -Wwf xxx,可以读取其中关于 .eh_frame 的数据:
The section .eh_frame contains: 0000001c CIE
Version:
Augmentation: "zPL"
Code alignment factor:
Data alignment factor: -
Return address column:
Augmentation data: d8 DW_CFA_def_cfa: r7 ofs 8 ##以下为字节码
DW_CFA_offset: r16 at cfa- 0000002c FDE cie= pc=00400ac8..00400bd8
Augmentation data:
#以下为字节码
DW_CFA_advance_loc: to 00400ac9
DW_CFA_def_cfa_offset:
DW_CFA_offset: r6 at cfa-
DW_CFA_advance_loc: to 00400acc
DW_CFA_def_cfa_reg: r6
DW_CFA_nop
DW_CFA_nop
DW_CFA_nop
对于由 GCC 编译出来的程序来说,CIE, FDE 是其在 unwind 过程中恢复现场时所依赖的全部东西,而且是完备的,这里所说的恢复现场指的是恢复调用当前函数的函数的现场,比如,func1 调用 func2,然后我们可以在 func2 里通过查询 CIE,FDE 恢复 func1 的现场。CIE,FDE 存在于每一个需要处理异常的 ELF 文件中,当异常发生时,runtime 根据当前 PC 值调用 dl_iterate_phdr() 函数就可以把当前程序所加载的所有模块轮询一遍,从而找到该 PC 所在模块的 eh_frame。
for (n = info->dlpi_phnum; --n >= ; phdr++)
{
if (phdr->p_type == PT_LOAD)
{
_Unwind_Ptr vaddr = phdr->p_vaddr + load_base;
if (data->pc >= vaddr && data->pc < vaddr + phdr->p_memsz)
match = ;
}
else if (phdr->p_type == PT_GNU_EH_FRAME)
p_eh_frame_hdr = phdr;
else if (phdr->p_type == PT_DYNAMIC)
p_dynamic = phdr;
}
找到 eh_frame 也就找到 CIE,找到了 CIE 也就可以去搜索相应的 FDE,找到FDE及CIE后,就可以从这两数据表中提取相关的信息,并执行DWARF 字节码,从而得到当前函数的调用函数的现场,参看如下用于重建函数帧的函数:
static _Unwind_Reason_Code
uw_frame_state_for (struct _Unwind_Context *context, _Unwind_FrameState *fs)
{
struct dwarf_fde *fde;
struct dwarf_cie *cie;
const unsigned char *aug, *insn, *end; memset (fs, , sizeof (*fs));
context->args_size = ;
context->lsda = ; // 根据context查找FDE。
fde = _Unwind_Find_FDE (context->ra - , &context->bases);
if (fde == NULL)
{
/* Couldn't find frame unwind info for this function. Try a
target-specific fallback mechanism. This will necessarily
not provide a personality routine or LSDA. */
#ifdef MD_FALLBACK_FRAME_STATE_FOR
MD_FALLBACK_FRAME_STATE_FOR (context, fs, success);
return _URC_END_OF_STACK;
success:
return _URC_NO_REASON;
#else
return _URC_END_OF_STACK;
#endif
} fs->pc = context->bases.func; // 获取对应的CIE.
cie = get_cie (fde); // 提取出CIE中的信息,如personality routine的地址。
insn = extract_cie_info (cie, context, fs);
if (insn == NULL)
/* CIE contained unknown augmentation. */
return _URC_FATAL_PHASE1_ERROR; /* First decode all the insns in the CIE. */
end = (unsigned char *) next_fde ((struct dwarf_fde *) cie); // 执行dwarf字节码,从而恢复相应的寄存器的值。
execute_cfa_program (insn, end, context, fs); // 定位到fde的相关数据
/* Locate augmentation for the fde. */
aug = (unsigned char *) fde + sizeof (*fde);
aug += * size_of_encoded_value (fs->fde_encoding);
insn = NULL;
if (fs->saw_z)
{
_Unwind_Word i;
aug = read_uleb128 (aug, &i);
insn = aug + i;
} // 读取language specific data的指针
if (fs->lsda_encoding != DW_EH_PE_omit)
aug = read_encoded_value (context, fs->lsda_encoding, aug,
(_Unwind_Ptr *) &context->lsda); /* Then the insns in the FDE up to our target PC. */
if (insn == NULL)
insn = aug;
end = (unsigned char *) next_fde (fde); // 执行FDE中的字节码。
execute_cfa_program (insn, end, context, fs); return _URC_NO_REASON;
}
通过如上的操作,unwinder 就已经把调用函数的现场给重建起来了,这些现场信息包括:
struct _Unwind_Context
{
void *reg[DWARF_FRAME_REGISTERS+]; //必要的寄存器。
void *cfa; // canoniacl frame address, 前面提到过,基地址。
void *ra;// 返回地址。
void *lsda;// 该函数对应的language specific data,如果存在的话。
struct dwarf_eh_bases bases;
_Unwind_Word args_size;
};
实现 Personality routine
Peronality routine 的作用主要有两个:
1)检查当前函数是否有相应的 catch 语句。
2)清理当前函数中的局部变量。
十分不巧,这两件事情仅仅依靠运行时也是没法完成的,必须依靠编译器在编译时建立起相关的数据进行协助。对于 GCC 来说,这些与抛异常的函数具体相关的信息全部放在 .gcc_except_table 区域里去了,这些信息会作为Itanium ABI 接口中所谓的 language specific data 在 unwinder 与 c++ ABI 之间传递,根据前面的介绍,我们知道在 FDE 中保存有指向 language specific data 的指针,因此 unwinder 在重建现场的时候就已经把这些数据读取了出来,c++ 的 ABI 只要调用 _Unwind_GetLanguageSpecificData() 就可以得到指向该数据的指针。
关于 GCC 下 language specific data 的格式,在网上几乎找不到什么权威的文档,我只在 llvm 的官网上找到一个相关的链接,这个文档对 gcc_except_table 作了很详细的说明,我对比了一下 GCC 源码里的 personality routine 的相关实现,发现两者还是有些许出入,因此本文接下来的介绍主要基于对 GCC 相关源码的个人解读,如有错误欢迎指正。
下图来源于网络,展示了gcc_except_table 及 language specific data 的格式:

由上图所示,LSDA 主要由一个表头,及其后紧跟着的三张表组成。
1.LSDA Header:
该表头主要用来保存接下来三张表的相关信息,如编码,及表的位移等,该表头主要包含六个域:
1)Landing pad 起始地址的编码方式,长度为一个字节。
2)landing pad 起始地址,这是可选的,只有当前面指明的编码方式不等于 DW_EH_PE_omit 时,这个字段才存在,此时读取这个字段就需要根据前面指定的编码方式进行读取,长度不固定,如果这个字段不存在,则 landing pad 的起始地址需要通过调用 _Unwind_GetRegionStart() 来获得,得到其实就是当前模块加载的起始地址,这是最常见的形式。
3)type table 的编码方式,长度为一个字节。
4)type table 的位移,类型为 unsigned LEB128,这个字段是可选的,只有3)中编码方式不等于 DW_EH_PE_omit 时,这个才存在。
5)call site table 的编码方式,长度为一个字节。
6)call site table 的长度,一个 unsigned LEB128 的值。
2.call site table
LSDA 表头之后紧跟着的是 call site table,该表用于记录程序中哪些指令有可能会抛异常,表中每条记录共有4个字段:
1)可能会抛异常的指令的地址,该地址是距 Landing pad 起始地址的偏移,编码方式由 LSDA 表头中第一个字段指明。
2)可能抛异常的指令的区域长度,该字段与 1)一起表示一系列连续的指令,编码方式与 1)相同。
3)用于处理上述指令的 Landing pad 的位移,这个值如果为 0 则表示不存在相应的 landing pad。
4)指明要采取哪些 action,这是一个 unsigned LEB128 的值,该值减1后作为下标获取 action table 中相应记录。
call site table 中的记录按第一个字段也就是指令起始地址进行排序存放,因此 unwind 的时候可以加快对该表的搜索,unwind 的过程中,如果当前 pc 的值不在 call site table 覆盖的范围内的话,搜索就会返回,然后就调用std::terminate() 结束程序,这通常来说是不正常的行为。
如果在 call site table 中有对应的处理,但 landing pad 的位移却是 0 的话,表明当前函数既不存在 catch 语句,也不需要清理局部变量,这是一种正常情况,unwinder 应该继续向上 unwind,而如果 landing pad 不为0,则表明该函数中有 catch 语句,但是这些 catch 能否处理抛出的异常则还要结合 action 字段,到 type table 中去进一步加以判断:
1)如果 action 字段为 0,则表明当前函数没有 catch 语句,但有局部变量需要清理。
2)如果 action 字段不为 0,则表明当前函数中存在 catch 语句,又因为 catch 是可能存在多个的,怎么知道哪个能够 catch 当前的异常呢?因此需要去检查 action table 中的表项。
3. Action table
action table 中每一条记录是一个二元组,表示一个 catch 语句所对应的异常,或者表示当前函数所允许抛出的异常 (exception specification),该列表每条记录包含两个字段:
1)filter type,这是一个 unsigned LEB128 的数值,用于指向 type table 中的记录,该值有可能是负数。
2)指向下一个 action table 中的下一条记录,这是当函数中有多个 catch 或 exception specification 有多个时,将各个 action 记录链接起来。
4. Type Table
type table 中存放的是异常类型的指针:
std::type_info* type_tables[];
这个表被分成两部分,一部分是各个 catch 所对应的异常的类型,另一部分是该函数允许抛出的异常类型:
void func() throw(int, string)
{
}
type table中这两部分分别通过正负下标来进行索引:
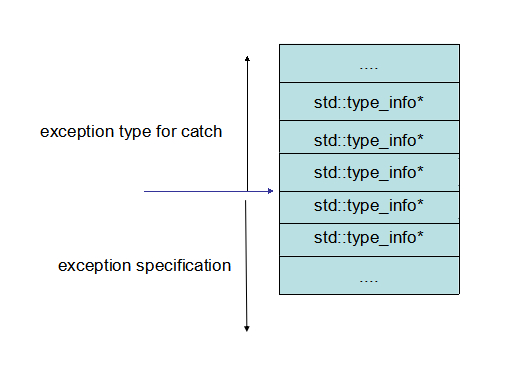
有了如上这些数据,personality routine 只需要根据当前的 pc 值及当前的异常类型,不断在上述表中查找,最后就能找到当前函数是否有 landing pad,如果有则返回 _URC_INSTALL_CONTEXT,指示 unwinder 跳过去执行相应的代码。
什么是 Landing pad
在前面一篇博文里,我们简单提到了Landing pad:指的是能够 catch 当前异常的 catch 语句。这个说法其实不确切,准确来说,landing pad 指的是 unwinder 之外的“用户代码”:
1)用于 catch 相应的 exception,对于一个函数来说,如果该函数中有 catch 语句,且能够处理当前的异常,则该 catch 就是 landing pad。
2)如果当前函数没有 catch 或者 catch 不能处理当前 exception,则意味着异常还要从当前函数继续往上抛,因而 unwind 当前函数时有可能要进行相应的清理,此时这些清理局部变量的代码就是 landing pad。
从名字上来看,顾名思议,landing pad 指的是程序的执行流程在进入当前函数后,最后要转到这里去,很恰当的描述。当 landing pad 是 catch 语句时,这个比较好理解,前面我们一直说清理局部变量的代码,这是什么意思呢?这些清理代码又放在哪里?为了说明这个问题,我们看一下如下代码:
#include <iostream>
#include <stddef.h>
using namespace std; class cs
{
public: explicit cs(int i) :i_(i) { cout << "cs constructor:" << i << endl; }
~cs() { cout << "cs destructor:" << i_ << endl; } private: int i_;
}; void test_func3()
{
cs c();
cs c2(); throw ; cs c3();
cout << "test func3" << endl;
} void test_func3_2()
{
cs c();
cs c2(); test_func3(); cs c3(); test_func3();
} void test_func2()
{
cs c(); cout << "test func2" << endl;
try
{
test_func3_2(); cs c2();
}
catch (int)
{
cout << "catch 2" << endl;
}
} void test_func1()
{
cout << "test func1" << endl;
try
{
test_func2();
}
catch (...)
{
cout << "catch 1" << endl;
}
} int main()
{
test_func1();
return ;
}
对于函数 test_func3_2() 来说,当 test_func3() 抛出异常后,在 unwind 的第二阶段,我们知道 test_func3_2() 中的局部变量 c 及 c2 是需要清理的,而 c3 则不用,那么编译器是怎么生成代码来完成这件事情的呢?当异常发生时,运行时是没有办法知道当前哪些变量是需要清理的,因为这个原因编译器在生成代码的时候,在函数的末尾设置了多个出口,使得当异常发生时,可以直接跳到某一段代码就能清理相应的局部变量,我们看看 test_func3_2() 编译后生成的对应的汇编代码:
void test_func3_2()
{
400ca4: push %rbp
400ca5: e5 mov %rsp,%rbp
400ca8: push %rbx
400ca9: ec sub $0x48,%rsp
cs c();
400cad: 8d 7d e0 lea 0xffffffffffffffe0(%rbp),%rdi
400cb1: be mov $0x20,%esi
400cb6: e8 9f callq 400f5a <_ZN2csC1Ei>
cs c2();
400cbb: 8d 7d d0 lea 0xffffffffffffffd0(%rbp),%rdi
400cbf: be mov $0x142,%esi
400cc4: e8 callq 400f5a <_ZN2csC1Ei> test_func3();
400cc9: e8 5a ff ff ff callq 400c28 <_Z10test_func3v> cs c3();
400cce: 8d 7d c0 lea 0xffffffffffffffc0(%rbp),%rdi
400cd2: be mov $0x143,%esi
400cd7: e8 7e callq 400f5a <_ZN2csC1Ei> test_func3();
400cdc: e8 ff ff ff callq 400c28 <_Z10test_func3v>
400ce1: eb jmp 400cfa <_Z12test_func3_2v+0x56>
400ce3: b8 mov %rax,0xffffffffffffffb8(%rbp)
400ce7: 8b 5d b8 mov 0xffffffffffffffb8(%rbp),%rbx
400ceb: 8d 7d c0 lea 0xffffffffffffffc0(%rbp),%rdi #c3的this指针
400cef: e8 2e callq 400f22 <_ZN2csD1Ev>
400cf4: 5d b8 mov %rbx,0xffffffffffffffb8(%rbp)
400cf8: eb 0f jmp 400d09 <_Z12test_func3_2v+0x65>
400cfa: 8d 7d c0 lea 0xffffffffffffffc0(%rbp),%rdi #c3的this指针
400cfe: e8 1f callq 400f22 <_ZN2csD1Ev>
400d03: eb jmp 400d1c <_Z12test_func3_2v+0x78>
400d05: b8 mov %rax,0xffffffffffffffb8(%rbp)
400d09: 8b 5d b8 mov 0xffffffffffffffb8(%rbp),%rbx
400d0d: 8d 7d d0 lea 0xffffffffffffffd0(%rbp),%rdi #c2的this指针
400d11: e8 0c callq 400f22 <_ZN2csD1Ev>
400d16: 5d b8 mov %rbx,0xffffffffffffffb8(%rbp)
400d1a: eb 0f jmp 400d2b <_Z12test_func3_2v+0x87>
400d1c: 8d 7d d0 lea 0xffffffffffffffd0(%rbp),%rdi #c2的this指针
400d20: e8 fd callq 400f22 <_ZN2csD1Ev>
400d25: eb 1e jmp 400d45 <_Z12test_func3_2v+0xa1>
400d27: b8 mov %rax,0xffffffffffffffb8(%rbp)
400d2b: 8b 5d b8 mov 0xffffffffffffffb8(%rbp),%rbx
400d2f: 8d 7d e0 lea 0xffffffffffffffe0(%rbp),%rdi #c的this指针
400d33: e8 ea callq 400f22 <_ZN2csD1Ev>
400d38: 5d b8 mov %rbx,0xffffffffffffffb8(%rbp)
400d3c: 8b 7d b8 mov 0xffffffffffffffb8(%rbp),%rdi
400d40: e8 b3 fc ff ff callq 4009f8 <_Unwind_Resume@plt> #c的this指针
400d45: 8d 7d e0 lea 0xffffffffffffffe0(%rbp),%rdi
400d49: e8 d4 callq 400f22 <_ZN2csD1Ev>
}
400d4e: c4 add $0x48,%rsp
400d52: 5b pop %rbx
400d53: c9 leaveq
400d54: c3 retq
400d55: nop
注意其中标红色的代码,_ZN2csD1Ev 即是类 cs 的析构函数,_Unwind_Resume() 则是当清理完成时,用来从 landing pad 返回的代码。test_func3_2() 中只有 3 个 cs 对象,但调用析构函数的代码却出现了 6 次。这里其实就是设置了多个出口函数,分别对应不同情况下,处理各个局部变量的析构,对于我们上面的代码来说,test_func3_2() 函数中的 landing pad 就是从地址:400d09 开始的,这些代码做了如下事情:
1)先析构 c2,然后 jump 到 400d2b 析构 c.
2)最后调用 _Unwind_Resume()
由此可见当程序中有多个可能抛异常的地方时,landing pad 也相应地会有多个,该函数的出口将更复杂,这也算是异常处理的一个 overhead 了。
总结
至此,关于 GCC 处理异常的具体流程及方式,各个细节都已写完,涉及很多比较琐碎的东西,只有反复阅读源码及相关文档才能搞明白,也不容易,只是古人说的好,纸上得来终觉浅,为了加深印象及验证所学的内容,我根据前面了解的这些知识,简单仿着 GCC 写了一个简化版的 c++ ABI,代码放到了 github 上这里,有兴趣的读者们可以参考一下,原本是打算把 unwinder 也写一遍的,但 DWARF 的格式实在太过复杂,已经超出了异常处理这个范围,就作罢了。
【引用】:
http://www.intel.com/content/dam/www/public/us/en/documents/guides/itanium-software-runtime-architecture-guide.pdf
http://mentorembedded.github.io/cxx-abi/abi-eh.html
http://refspecs.linuxfoundation.org/LSB_3.0.0/LSB-Core-generic/LSB-Core-generic/ehframechpt.html
https://www.opensource.apple.com/source/gcc/gcc-5341/gcc/
http://www.cs.dartmouth.edu/~sergey/battleaxe/hackito_2011_oakley_bratus.pdf
http://mentorembedded.github.io/cxx-abi/exceptions.pdf
http://www.airs.com/blog/archives/464
c++ 异常处理(2)的更多相关文章
- 关于.NET异常处理的思考
年关将至,对于大部分程序员来说,马上就可以闲下来一段时间了,然而在这个闲暇的时间里,唯有争论哪门语言更好可以消磨时光,估计最近会有很多关于java与.net的博文出现,我表示要作为一个吃瓜群众,静静的 ...
- 基于spring注解AOP的异常处理
一.前言 项目刚刚开发的时候,并没有做好充足的准备.开发到一定程度的时候才会想到还有一些问题没有解决.就比如今天我要说的一个问题:异常的处理.写程序的时候一般都会通过try...catch...fin ...
- 异常处理汇总 ~ 修正果带着你的Net飞奔吧!
经验库开源地址:https://github.com/dunitian/LoTDotNet 异常处理汇总-服 务 器 http://www.cnblogs.com/dunitian/p/4522983 ...
- JavaScript var关键字、变量的状态、异常处理、命名规范等介绍
本篇主要介绍var关键字.变量的undefined和null状态.异常处理.命名规范. 目录 1. var 关键字:介绍var关键字的使用. 2. 变量的状态:介绍变量的未定义.已定义未赋值.已定义已 ...
- IL异常处理
异常处理在程序中也算是比较重要的一部分了,IL异常处理在C#里面实现会用到一些新的方法 1.BeginExceptionBlock:异常块代码开始,相当于try,但是感觉又不太像 2.EndExcep ...
- Spring MVC重定向和转发以及异常处理
SpringMVC核心技术---转发和重定向 当处理器对请求处理完毕后,向其他资源进行跳转时,有两种跳转方式:请求转发与重定向.而根据要跳转的资源类型,又可分为两类:跳转到页面与跳转到其他处理器.对于 ...
- 【repost】JS中的异常处理方法分享
我们在编写js过程中,难免会遇到一些代码错误问题,需要找出来,有些时候怕因为js问题导致用户体验差,这里给出一些解决方法 js容错语句,就是js出错也不提示错误(防止浏览器右下角有个黄色的三角符号,要 ...
- 札记:Java异常处理
异常概述 程序在运行中总会面临一些"意外"情况,良好的代码需要对它们进行预防和处理.大致来说,这些意外情况分三类: 交互输入 用户以非预期的方式使用程序,比如非法输入,不正当的操作 ...
- 关于bug分析与异常处理的一些思考
前言:工作三年了,工作内容主要是嵌入式软件开发和维护,用的语言是C,毕业后先在一家工业自动化控制公司工作两年半,目前在一家医疗仪器公司担任嵌入式软件开发工作.软件开发中,难免不产生bug:产品交付客户 ...
- ABP(现代ASP.NET样板开发框架)系列之23、ABP展现层——异常处理
点这里进入ABP系列文章总目录 基于DDD的现代ASP.NET开发框架--ABP系列之23.ABP展现层——异常处理 ABP是“ASP.NET Boilerplate Project (ASP.NET ...
随机推荐
- python——列表入门
学习列表先分析一段程序: list = ['zx', 'xkd', 1997, 2018] list1=list+[1,2,3]#列表拼接 list2=[list,list1] print('嵌套的列 ...
- django之normalize函数的功能
from django.utils.regex_helper import normalize pat=r'^(?P<id>\d+)/(?P<name>\d+)$' bits= ...
- oracle 11g密码过期问题解决方法
ORACLE 11G密码过期问题: 1.使用oracle用户进入sql编辑器中执行修改密码(原始密码,保持不变)的命令 sql>alter user 用户名 identified by &quo ...
- IO密集型和计算密集型
我们常说的多任务或者单任务分为两种: IO密集型的任务 计算密集型的任务 IO密集型的任务或:有阻塞的状态,就是不一直会运行CPU(中间就一个等待状态,就告诉CPU 等待状态,这个就叫IO密集型 ...
- 第二篇*2、Python字符串格式化
1.字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 1)百分号方式 %[(name)][flags][width].[precision]typecode (nam ...
- input 选择框改变背景小技巧
最近在项目中遇到一个问题,想要改变input选择框的背景,然而,令我没有想到的是,竟然无法直接改变背景的颜色 通常情况下:我们都可以通过改变元素的 background-color 的值来改变元素的背 ...
- Java并发辅助类的使用
目录 1.概述 2.CountdownLatch 2-1.构造方法 2-2.重要方法 2-3.使用示例 3.CyclicBarrier 3-1.构造方法 3-2.使用示例 4.Semaphore 4- ...
- python 关于文件的操作
1.打开文件: f=open(r'E:\PythonProjects\test7\a.txt',mode='rt',encoding='utf-8') 以上三个单引号内分别表示:要打开的文件的路径,m ...
- elasticsearch数据结构
无论是关系型数据库还是非关系型数据库,乃至elasticsearch这种事实上承担着一定储存作用的搜索引擎,数据类型都是非常重要而基础的概念.本文基于elasticsearch 5.x版本. 核心数据 ...
- discuz代码转为html代码
下面附件是来自discuz的一个函数文件(原来是在source/function/function_discuzcode.php位置),已稍微修改: https://files.cnblogs.com ...