42_并发编程-JionableQueue
from multiprocessing import Process,Queue
import time,random,os
def consumer(q):
while True:
res=q.get()
time.sleep(random.randint(1,3))
print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q):
for i in range(10):
time.sleep(random.randint(1,3))
res='包子%s' %i
q.put(res)
print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__':
q=Queue()
#生产者们:即厨师们
p1=Process(target=producer,args=(q,)) #消费者们:即吃货们
c1=Process(target=consumer,args=(q,)) #开始
p1.start()
c1.start()
print('主')
基于队列实现
总结:
#生产者消费者模型总结
#程序中有两类角色
一类负责生产数据(生产者)
一类负责处理数据(消费者) #引入生产者消费者模型为了解决的问题是:
平衡生产者与消费者之间的工作能力,从而提高程序整体处理数据的速度 #如何实现:
生产者<-->队列<——>消费者
#生产者消费者模型实现类程序的解耦和
问题:
通过上面基于队列的生产者消费者代码示例,我们发现一个问题:主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,则一直处于死循环中且卡在q.get()这一步。解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环
from multiprocessing import Process, Queue
import time
def shenchan(q):
for i in range(10): # 每1秒生产一个包子
time.sleep(1)
print('生产%s号包子' % i)
q.put(i) # 生产一个放入队列(缓冲区) def xiaofei(q):
while 1:
time.sleep(0.5) # 一直从队列中拿包子,每0.5秒那一次
if q.get() == None: # 当从队列中拿时,拿到了None,就不拿了退出,None信号由主进程发出
break
else:
print('消费者吃%s号包子' % q.get()) # 消费者拿的比生产者产包子快,则队列中每包子,还get,等待消费者向队列中放包子再取 if __name__ == '__main__': q = Queue(10)
sc = Process(target=shenchan, args=(q,))
sc.start()
xf = Process(target=xiaofei, args=(q,))
xf.start()
sc.join() # 设join,阻塞一下,先让生产者,消费者进程执行完
q.put(None) # 再想队列中方None
发送信号解决
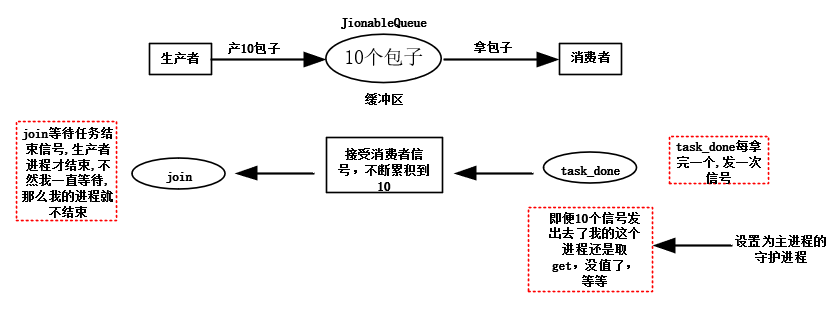
#生产者消费者模型
import time
from multiprocessing import Process,Queue,JoinableQueue def producer(q):
for i in range(1,11):
time.sleep(0.5)
print('生产了包子%s号' % i)
q.put(i)
q.join()
print('在这里等你')
def consumer(q):
while 1:
time.sleep(1)
s = q.get()
print('消费者吃了%s包子' % s)
q.task_done() #给q对象发送一个任务结束的信号 if __name__ == '__main__':
#通过队列来模拟缓冲区,大小设置为20
q = JoinableQueue(20)
#生产者进程
pro_p = Process(target=producer,args=(q,))
pro_p.start()
#消费者进程
con_p = Process(target=consumer,args=(q,))
con_p.daemon = True #
con_p.start()
pro_p.join()
print('主进程结束')
基于JoinableQueue
42_并发编程-JionableQueue的更多相关文章
- 并发编程,python的进程,与线程
并发编程 操作系统发展史 基于单核研究 多道技术 1.空间上的复用 多个程序公用一套计算机硬件 2.时间上的复用 切换+保存状态 例子:洗衣 烧水 做饭 切换 1.程序遇到IO操作系统会立刻剥夺走CP ...
- [ 高并发]Java高并发编程系列第二篇--线程同步
高并发,听起来高大上的一个词汇,在身处于互联网潮的社会大趋势下,高并发赋予了更多的传奇色彩.首先,我们可以看到很多招聘中,会提到有高并发项目者优先.高并发,意味着,你的前雇主,有很大的业务层面的需求, ...
- 伪共享(false sharing),并发编程无声的性能杀手
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- 【Java并发编程实战】----- AQS(四):CLH同步队列
在[Java并发编程实战]-–"J.U.C":CLH队列锁提过,AQS里面的CLH队列是CLH同步锁的一种变形.其主要从两方面进行了改造:节点的结构与节点等待机制.在结构上引入了头 ...
- 【Java并发编程实战】----- AQS(三):阻塞、唤醒:LockSupport
在上篇博客([Java并发编程实战]----- AQS(二):获取锁.释放锁)中提到,当一个线程加入到CLH队列中时,如果不是头节点是需要判断该节点是否需要挂起:在释放锁后,需要唤醒该线程的继任节点 ...
- 【Java并发编程实战】----- AQS(二):获取锁、释放锁
上篇博客稍微介绍了一下AQS,下面我们来关注下AQS的所获取和锁释放. AQS锁获取 AQS包含如下几个方法: acquire(int arg):以独占模式获取对象,忽略中断. acquireInte ...
- 【Java并发编程实战】-----“J.U.C”:CLH队列锁
在前面介绍的几篇博客中总是提到CLH队列,在AQS中CLH队列是维护一组线程的严格按照FIFO的队列.他能够确保无饥饿,严格的先来先服务的公平性.下图是CLH队列节点的示意图: 在CLH队列的节点QN ...
- 【Java并发编程实战】-----“J.U.C”:Exchanger
前面介绍了三个同步辅助类:CyclicBarrier.Barrier.Phaser,这篇博客介绍最后一个:Exchanger.JDK API是这样介绍的:可以在对中对元素进行配对和交换的线程的同步点. ...
- 【Java并发编程实战】-----“J.U.C”:CountDownlatch
上篇博文([Java并发编程实战]-----"J.U.C":CyclicBarrier)LZ介绍了CyclicBarrier.CyclicBarrier所描述的是"允许一 ...
随机推荐
- RedHat 7.0更新升级openSSH7.4p1
由于目前服务器上ssh版本较低,存在安全漏洞,需要升级到最新版本. 系统版本:RedHat 7.0 旧openSSH版本:6.4p1 新openSSH版本:7.4p1 升级方式:源码安装 安装操作步骤 ...
- leetcode297
public class Codec { // Encodes a tree to a single string. public string serialize(TreeNode root) { ...
- 第四篇、Python文件处理
1.文件操作 1) 文件操作流程 a. 打开文件,得到文件句柄并赋值给一个变量 b. 通过句柄对文件进行操作 c. 关闭文件 f=open('a.txt','r',encoding='utf-8') ...
- js 模拟css3 动画3
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 资产管理平台 glpi
1.安装apache yum install httpdyum install httpd-devel 2.安装php 3.配置apache支持php 4.下载glpi并解压 5.配置apache 6 ...
- nmap的使用
安装完nmap后,看网上都是直接cmd后nmap的方式来查看是否安装成功,但实际我总是不对,然后自己想着进入安装包执行命令,果然成功.
- tesseract编译错误:fatal error: allheaders.h: No such file or directory
错误描述: globaloc.cpp::: fatal error: allheaders.h: No such file or directory #include "allheaders ...
- Jenkins安装时Web页面报错提示离线安装
先跳过所有. 方法1 先看它的提示:”参考离线Jenkins安装文档“发现链接点不开,我还以为是被墙了呢,FQ以后还是打不开.看来这个参考文档是没有用滴.点击配置HTTP代理跳出如下界面:安装Jenk ...
- [leetcode]366. Find Leaves of Binary Tree捡树叶
Given a binary tree, collect a tree's nodes as if you were doing this: Collect and remove all leaves ...
- ubuntu系统安装微信小程序开发工具
在ubuntu系统中安装微信小程序开发工具之前,先要安装wine与git 一.安装wine 1.如果您的系统是64位,启用32位架构(如果您还没有) sudo dpkg --add-architect ...