Django--models--多表操作
一 创建模型
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
Book id title price publish
php 100 人民出版社
python 200 老男孩出版社
go 100 人民出版社
java 300 人民出版社 为了存储出版社的邮箱,地址,在第一个表后面加字段 Book id title price publish email addr
php 100 人民出版社 111 北京
python 200 老男孩出版社 222 上海
go 100 人民出版社 111 北京
java 300 人民出版社 111 北京 这样会有大量重复的数据,浪费空间 #################################################################################### 一对多:一个出版社对应多本书(关联信息建在多的一方,也就是book表中) Book id title price publish_id
php 100 1
python 200 1
go 100 2
java 300 1 Publish id name email addr
人民出版社 111 北京
沙河出版社 222 沙河 总结:一旦确定表关系是一对多:在多对应的表中创建关联字段(在多的表里创建关联字段) ,publish_id 查询python这本书的出版社的邮箱(子查询) select publish_id from Book where title=“python”
select email from Publish where id=1 #################################################################################### 多对多:一本书有多个作者,一个作者出多本书 Book id title price publish_id
php 100 1
python 200 1
go 100 2
java 300 1 Author
id name age addr
alex 34 beijing
egon 55 nanjing Book2Author id book_id author_id
2 1
2 2
3 2 总结:一旦确定表关系是多对多:创建第三张关系表(创建中间表,中间表就三个字段,自己的id,书籍id和作者id) : id book_id author_id # alex出版过的书籍名称(子查询) select id from Author where name='alex' select book_id from Book2Author where author_id=1 select title from Book where id =book_id #################################################################################### 一对一:对作者详细信息的扩展(作者表和作者详情表) Author
id name age ad_id(UNIQUE)
alex 34 1
egon 55 2 AuthorDetail id addr gender tel gf_name author_id(UNIQUE)
beijing male 110 小花 1
nanjing male 911 杠娘 2 总结: 一旦确定是一对一的关系:在两张表中的任意一张表中建立关联字段+Unique ==================================== Publish
Book
Author
AuthorDetail
Book2Author CREATE TABLE publish(
id INT PRIMARY KEY auto_increment ,
name VARCHAR (20)
); CREATE TABLE book(
id INT PRIMARY KEY auto_increment ,
title VARCHAR (20),
price DECIMAL (8,2),
pub_date DATE ,
publish_id INT ,
FOREIGN KEY (publish_id) REFERENCES publish(id)
); CREATE TABLE authordetail(
id INT PRIMARY KEY auto_increment ,
tel VARCHAR (20)
); CREATE TABLE author(
id INT PRIMARY KEY auto_increment ,
name VARCHAR (20),
age INT,
authordetail_id INT UNIQUE ,
FOREIGN KEY (authordetail_id) REFERENCES authordetail(id)
); CREATE TABLE book2author(
id INT PRIMARY KEY auto_increment ,
book_id INT ,
author_id INT ,
FOREIGN KEY (book_id) REFERENCES book(id),
FOREIGN KEY (author_id) REFERENCES author(id)
) 分析如下
分析如下
注意:关联字段与外键约束没有必然的联系(建管理字段是为了进行查询,建约束是为了不出现脏数据)
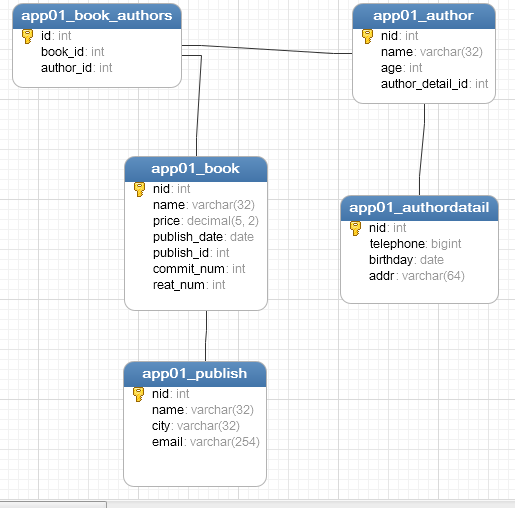
在Models创建如下模型
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField()
# 阅读数
# reat_num=models.IntegerField(default=0)
# 评论数
# commit_num=models.IntegerField(default=0) publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.name class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDatail',to_field='nid',unique=True,on_delete=models.CASCADE) class AuthorDatail(models.Model):
nid = models.AutoField(primary_key=True)
telephone = models.BigIntegerField()
birthday = models.DateField()
addr = models.CharField(max_length=64) class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
注意事项:
- 表的名称
myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称 id字段是自动添加的- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的
CREATE TABLESQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
二 添加表记录
一对多的
方式1:
publish_obj=Publish.objects.get(nid=1)
book_obj=Book.objects.create(title="",publishDate="2012-12-12",price=100,publish=publish_obj) 方式2:
book_obj=Book.objects.create(title="",publishDate="2012-12-12",price=100,publish_id=1)
核心:book_obj.publish与book_obj.publish_id是什么?
关键点:
一 book_obj.publish=Publish.objects.filter(id=book_obj.publish_id).first()
二 book_obj.authors.all()
关键点:book.authors.all() # 与这本书关联的作者集合
1 book.id=3
2 book_authors
id book_id author_ID
3 3 1
4 3 2
3 author
id name
1 alex
2 egon
book_obj.authors.all() -------> [alex,egon]
# -----一对多添加
pub=Publish.objects.create(name='egon出版社',email='445676@qq.com',city='山东')
print(pub) # 为book表绑定和publish的关系
import datetime,time
now=datetime.datetime.now().__str__()
now = datetime.datetime.now().strftime('%Y-%m-%d')
print(type(now))
print(now)
# 日期类型必须是日期对象或者字符串形式的2018-09-12(2018-9-12),其它形式不行
Book.objects.create(name='海燕3',price=333.123,publish_date=now,publish_id=2)
Book.objects.create(name='海3燕3',price=35.123,publish_date='2018/02/28',publish=pub)
pub=Publish.objects.filter(nid=1).first()
book=Book.objects.create(name='测试书籍',price=33,publish_date='2018-7-28',publish=pub)
print(book.publish.name)
# 查询出版了红楼梦这本书出版社的邮箱
book=Book.objects.filter(name='红楼梦').first()
print(book.publish.email)
多对多
# 当前生成的书籍对象
book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)
# 为书籍绑定的做作者对象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录
egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录 # 绑定多对多关系,即向关系表book_authors中添加纪录
book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
book = Book.objects.filter(name='红楼梦').first()
egon=Author.objects.filter(name='egon').first()
lqz=Author.objects.filter(name='lqz').first()
# 1 没有返回值,直接传对象
book.authors.add(lqz,egon)
# 2 直接传作者id
book.authors.add(1,3)
# 3 直接传列表,会打散
book.authors.add(*[1,2])
# 解除多对多关系
book = Book.objects.filter(name='红楼梦').first()
# 1 传作者id
book.authors.remove(1)
# 2 传作者对象
egon = Author.objects.filter(name='egon').first()
book.authors.remove(egon)
#3 传*列表
book.authors.remove(*[1,2])
#4 删除所有
book.authors.clear()
# 5 拿到与 这本书关联的所有作者,结果是queryset对象,作者列表
ret=book.authors.all()
# print(ret)
# 6 queryset对象,又可以继续点(查询红楼梦这本书所有作者的名字)
ret=book.authors.all().values('name')
print(ret)
# 以上总结:
# (1)
# book=Book.objects.filter(name='红楼梦').first()
# print(book)
# 在点publish的时候,其实就是拿着publish_id又去app01_publish这个表里查数据了
# print(book.publish)
# (2)book.authors.all()
核心:book_obj.authors.all()是什么?
多对多关系其它常用API:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
book_obj.authors.clear() #清空被关联对象集合
book_obj.authors.set() #先清空再设置
三 基于对象的跨表查询
一对多查询(publish与book)
正向查询(按字段:publish)
# 查询主键为1的书籍的出版社所在的城市
book_obj=Book.objects.filter(pk=1).first()
# book_obj.publish 是主键为1的书籍对象关联的出版社对象
print(book_obj.publish.city)
反向查询(按表名:book_set)
publish=Publish.objects.get(name="苹果出版社")
#publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合
book_list=publish.book_set.all()
for book_obj in book_list:
print(book_obj.title)
# 一对多正向查询
book=Book.objects.filter(name='红楼梦').first()
print(book.publish)#与这本书关联的出版社对象
print(book.publish.name)
# 一对多反向查询
# 人民出版社出版过的书籍名称
pub=Publish.objects.filter(name='人民出版社').first()
ret=pub.book_set.all()
print(ret)
一对一查询(Author 与 AuthorDetail)
正向查询(按字段:authorDetail):
egon=Author.objects.filter(name="egon").first()
print(egon.authorDetail.telephone) 反向查询(按表名:author):
# 查询所有住址在北京的作者的姓名 authorDetail_list=AuthorDetail.objects.filter(addr="beijing")
for obj in authorDetail_list:
print(obj.author.name)
# 一对一正向查询
# lqz的手机号
lqz=Author.objects.filter(name='lqz').first()
tel=lqz.author_detail.telephone
print(tel)
# 一对一反向查询
# 地址在北京的作者姓名
author_detail=AuthorDatail.objects.filter(addr='北京').first()
name=author_detail.author.name
print(name)
多对多查询 (Author 与 Book)
正向查询(按字段:authors):
# 眉所有作者的名字以及手机号 book_obj=Book.objects.filter(title="眉").first()
authors=book_obj.authors.all()
for author_obj in authors:
print(author_obj.name,author_obj.authorDetail.telephone)
反向查询(按表名:book_set):
# 查询egon出过的所有书籍的名字
author_obj=Author.objects.get(name="egon")
book_list=author_obj.book_set.all() #与egon作者相关的所有书籍
for book_obj in book_list:
print(book_obj.title)
# 正向查询----查询红楼梦所有作者名称
book=Book.objects.filter(name='红楼梦').first()
ret=book.authors.all()
print(ret)
for auth in ret:
print(auth.name)
# 反向查询 查询lqz这个作者写的所有书
author=Author.objects.filter(name='lqz').first()
ret=author.book_set.all()
print(ret)
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改:
publish = ForeignKey(Book, related_name='bookList')
那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍 publish=Publish.objects.get(name="人民出版社") book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合四 基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
一对多查询
# 练习: 查询苹果出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="苹果出版社")
.values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="苹果出版社")
.values_list("book__title","book__price")
查询的本质一样,就是select from的表不一样
# 正向查询按字段,反向查询按表名小写
# 查询红楼梦这本书出版社的名字
# select * from app01_book inner join app01_publish
# on app01_book.publish_id=app01_publish.nid
ret=Book.objects.filter(name='红楼梦').values('publish__name')
print(ret)
ret=Publish.objects.filter(book__name='红楼梦').values('name')
print(ret)
多对多查询
# 练习: 查询alex出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")
# 正向查询按字段,反向查询按表名小写
# 查询红楼梦这本书出版社的名字
# select * from app01_book inner join app01_publish
# on app01_book.publish_id=app01_publish.nid
ret=Book.objects.filter(name='红楼梦').values('publish__name')
print(ret)
ret=Publish.objects.filter(book__name='红楼梦').values('name')
print(ret)
# sql 语句就是from的表不一样
# -------多对多正向查询
# 查询红楼梦所有的作者
ret=Book.objects.filter(name='红楼梦').values('authors__name')
print(ret)
# ---多对多反向查询
ret=Author.objects.filter(book__name='红楼梦').values('name')
ret=Author.objects.filter(book__name='红楼梦').values('name','author_detail__addr')
print(ret)
一对一查询
# 查询alex的手机号
# 正向查询
ret=Author.objects.filter(name="alex").values("authordetail__telephone")
# 反向查询
ret=AuthorDetail.objects.filter(author__name="alex").values("telephone")
# 查询lqz的手机号
# 正向查
ret=Author.objects.filter(name='lqz').values('author_detail__telephone')
print(ret)
# 反向查
ret= AuthorDatail.objects.filter(author__name='lqz').values('telephone')
print(ret)
进阶练习(连续跨表)
# 练习: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__authors__age","book__authors__name")
# 练习: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
# 方式1:
queryResult=Book.objects
.filter(authors__authorDetail__telephone__regex="151")
.values_list("title","publish__name")
# 方式2:
ret=Author.objects
.filter(authordetail__telephone__startswith="151")
.values("book__title","book__publish__name")
# ----进阶练习,连续跨表
# 查询手机号以33开头的作者出版过的书籍名称以及书籍出版社名称
# author_datail author book publish
# 基于authorDatail表
ret=AuthorDatail.objects.filter(telephone__startswith='33').values('author__book__name','author__book__publish__name')
print(ret)
# 基于Author表
ret=Author.objects.filter(author_detail__telephone__startswith=33).values('book__name','book__publish__name')
print(ret)
# 基于Book表
ret=Book.objects.filter(authors__author_detail__telephone__startswith='33').values('name','publish__name')
print(ret)
# 基于Publish表
ret=Publish.objects.filter(book__authors__author_detail__telephone__startswith='33').values('book__name','name')
print(ret)
related_name
publish = ForeignKey(Blog, related_name='bookList')
反向查询时,如果定义了related_name ,则用related_name替换表名,例如:
# 练习: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price")
五 聚合查询与分组查询
聚合
aggregate(*args, **kwargs)
# 计算所有图书的平均价格
>>> from django.db.models import Avg >>> Book.objects.all().aggregate(Avg('price')) {'price__avg': 34.35}>>> Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35}>>> from django.db.models import Avg, Max, Min
>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')){'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}# 查询所有书籍的平均价格
from django.db.models import Avg,Count,Max,Min
ret=Book.objects.all().aggregate(Avg('price'))
# {'price__avg': 202.896}
# 可以改名字
ret=Book.objects.all().aggregate(avg_price=Avg('price'))
# 统计平均价格和最大价格
ret=Book.objects.all().aggregate(avg_price=Avg('price'),max_price=Max('price'))
# 统计最小价格
ret = Book.objects.all().aggregate(avg_price=Avg('price'), min_price=Min('price'))
# 统计个数和平均价格
ret = Book.objects.all().aggregate(avg_price=Avg('price'), max_price=Max('price'),count=Count('price'))
ret = Book.objects.all().aggregate(avg_price=Avg('price'), max_price=Max('price'),count=Count('nid'))
print(ret)
分组
###################################--单表分组查询--####################################################### 查询每一个部门名称以及对应的员工数 emp: id name age salary dep
alex 12 2000 销售部
egon 22 3000 人事部
wen 22 5000 人事部 sql语句:
select dep,Count(*) from emp group by dep; ORM:
emp.objects.values("dep").annotate(c=Count("id") # 示例:查询每一个部门的名称,以及平均薪水
# select dep,Avg(salary) from app01_emp group by dep
from django.db.models import Avg, Count, Max, Min
# ret=Emp.objects.values('dep').annotate(Avg('salary'))
# 重新命名
ret=Emp.objects.values('dep').annotate(avg_salary=Avg('salary'))
print(ret)
总结:单表分组查询orm语法:单表模型.objects.values('group by 的字段').annotate(聚合函数('统计的字段'))
查询每一个省份名称以及对应的员工数
Emp.objects.values('province').annotate(Count('id')) ###################################--多表分组查询--###########################
Book表 id title date price publish_id
红楼梦 2012-12-12 101 1
西游记 2012-12-12 101 1
三国演绎 2012-12-12 101 1
金梅 2012-12-12 301 2 Publish表
id name addr email
人民出版社 北京 123@qq.com
南京出版社 南京 345@163.com 多表分组查询:
查询每个出版社出版的书籍个数
ret=Book.objects.values('publish_id').annotate(Count('nid'))
print(ret)
查询每个出版社的名称和书籍个数(先join,再分组)
SELECT app01_publish.name,COUNT(app01_book.name) from app01_book
INNER JOIN app01_publish
on app01_publish.nid = app01_book.publish_id
GROUP BY app01_publish.nid
orm实现:
ret=Publish.objects.values('name').annotate(Count('book__name'))
ret=Publish.objects.values('nid').annotate(c=Count('book__name')).values('name','c')
print(ret)
模型总结:跨表查询的模型:每一个后表模型.objects.value('pk').annotate(聚合函数('关联表__统计字段')).values()
# 查询每个作者的名字,以及出版过书籍的最高价格
ret=Author.objects.values('pk').annotate(c=Max('book__price')).values('name','c')
print(ret)
# 查询每一个书籍的名称,以及对应的作者个数
ret=Book.objects.values('pk').annotate(c=Count('authors__name')).values('name','c')
print(ret)
class Emp(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
salary=models.DecimalField(max_digits=8,decimal_places=2)
dep=models.CharField(max_length=32)
province=models.CharField(max_length=32)
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
查询练习
(1) 练习:统计每一个出版社的最便宜的书
publishList=Publish.objects.annotate(MinPrice=Min("book__price"))
for publish_obj in publishList: print(publish_obj.name,publish_obj.MinPrice)queryResult= Publish.objects
.annotate(MinPrice=Min("book__price"))
.values_list("name","MinPrice")
print(queryResult)
ret=Book.objects.annotate(authorsNum=Count('authors__name'))
(3) 统计每一本以py开头的书籍的作者个数:
queryResult=Book.objects
.filter(title__startswith="Py")
.annotate(num_authors=Count('authors'))
(4) 统计不止一个作者的图书:
queryResult=Book.objects
.annotate(num_authors=Count('authors'))
.filter(num_authors__gt=1)
(5) 根据一本图书作者数量的多少对查询集 QuerySet进行排序:
Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors')
(6) 查询各个作者出的书的总价格:
# 按author表的所有字段 group by
queryResult=Author.objects
.annotate(SumPrice=Sum("book__price"))
.values_list("name","SumPrice")
print(queryResult)
# ————————————单表下的分组查询
'''
查询每一个部门名称以及对应的员工数
emp:
id name age salary dep
1 alex 12 2000 销售部
2 egon 22 3000 人事部
3 wen 22 5000 人事部
'''
# select count(id) from emp group by dep
# 示例一:查询每一个部门的名称,以及平均薪水
# select dep,Avg(salary) from app01_emp group by dep
from django.db.models import Avg, Count, Max, Min
ret=Emp.objects.values('dep').annotate(Avg('salary'))
# 重新命名
ret=Emp.objects.values('dep').annotate(avg_salary=Avg('salary'))
print(ret)
# ---*******单表分组查询ORM总结:表名.objects.values('group by 的字段').annotate(聚合函数('统计的字段'))
# 示例2 查询每个省份对应的员工数
ret=Emp.objects.values('province').annotate(Count('id'))
ret=Emp.objects.values('province').annotate(c=Count('id'))
print(ret)
# 补充知识点:
ret=Emp.objects.all()
# select * from emp
ret=Emp.objects.values('name')
# select name from emp
# ****单表下,按照id进行分组是没有任何意义的
ret=Emp.objects.all().annotate(Avg('salary'))
print(ret)
# ******多表分组查询
# 查询每一个出版社出版的书籍个数
ret=Book.objects.values('publish_id').annotate(Count('nid'))
print(ret)
# 查询每个出版社的名称以及出版社书的个数(先join在跨表分组)
# 正向
ret=Publish.objects.values('name').annotate(Count('book__name'))
ret=Publish.objects.values('nid').annotate(c=Count('book__name')).values('name','c')
print(ret)
# 反向
ret=Book.objects.values('publish__name').annotate(Count('name'))
ret=Book.objects.values('publish__name').annotate(c=Count('name')).values('publish__name','c')
print(ret)
# 查询每个作者的名字,以及出版过书籍的最高价格
ret=Author.objects.values('pk').annotate(c=Max('book__price')).values('name','c')
print(ret)
# 跨表查询的模型:每一个后表模型.objects.value('pk').annotate(聚合函数('关联表__统计字段')).values() # 查询每一个书籍的名称,以及对应的作者个数
ret=Book.objects.values('pk').annotate(c=Count('authors__name')).values('name','c')
print(ret)
# 统计不止一个作者的图书
ret=Book.objects.values('pk').annotate(c=Count('authors__name')).filter(c__gt=1).values('name','c')
print(ret)
六 F查询与Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
# 查询评论数大于收藏数的书籍 from django.db.models import F
Book.objects.filter(commnetNum__lt=F('keepNum'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
# 查询评论数大于收藏数2倍的书籍
Book.objects.filter(commnetNum__lt=F('keepNum')*2)
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
Book.objects.all().update(price=F("price")+30)
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
from django.db.models import Q
Q(title__startswith='Py')
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon"))
等同于下面的SQL WHERE 子句:
WHERE name ="yuan" OR name ="egon"
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title")
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python"
)
# 查询评论数大于阅读数的书籍
from django.db.models import F,Q
# select * from book where commit_num>read_num;
# 这样肯定是不行的
# Book.objects.filter(commit_num__gt=read_num)
ret=Book.objects.filter(commit_num__gt=F('reat_num'))
print(ret)
# 把所有书籍的价格加10
Book.objects.all().update(price=F('price')+10)
# ----Q函数,描述一个与,或,非的关系
# 查询名字叫红楼梦或者价格大于100的书
ret=Book.objects.filter(Q(name='红楼梦')|Q(price__gt=100))
print(ret)
# 查询名字叫红楼梦和价格大于100的书
ret = Book.objects.filter(Q(name='红楼梦') & Q(price__gt=100))
print(ret)
# # 等同于
ret2=Book.objects.filter(name='红楼梦',price__gt=100)
print(ret2)
# 也可以Q套Q
# 查询名字叫红楼梦和价格大于100 或者 nid大于2
ret=Book.objects.filter((Q(name='红楼梦') & Q(price__gt=100))|Q(nid__gt=2))
print(ret)
# ----非
ret=Book.objects.filter(~Q(name='红楼梦'))
print(ret)
# Q和键值对联合使用,但是键值对必须放在Q的后面(描述的是一个且的关系)
# 查询名字不是红楼梦,并且价格大于100的书
ret=Book.objects.filter(~Q(name='红楼梦'),price__gt=100)
print(ret)
# 查询每一个出版社出版的书籍个数
ret=Book.objects.values('publish_id').annotate(Count('nid'))
print(ret)
Django--models--多表操作的更多相关文章
- Django models多表操作
title: Django models多表操作 tags: Django --- 多表操作 单独创建第三张表的情况 推荐使用的是使用values/value_list,selet_related的方 ...
- Django ORM 多表操作
目录 Django ORM 多表操作 表模型 表关系 创建模型 逆向到表模型 插入数据 ORM 添加数据(添加外键) 一对多(外键 ForeignKey) 一对一 (OneToOneFeild) 多对 ...
- Django ORM多表操作
多表操作 创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是一对 ...
- django第8天(在测试文件中运行django项目|单表操作)
django第8天 在测试文件中运行django项目 1.将项目配置文件数据库该为mysql,修改配置信息 PORT = '127.0.0.1' DATABASES = { 'default': { ...
- Django之ORM表操作
ORM表操作 1.ORM单表操作 首先想操作表的增删改查,需要先导入这个表,以之前创建的UserInfo表为例,在app下的views.py中导入 from app import models def ...
- Django day08 多表操作 (二) 添加表记录
一: 一对多 1. 一对多新增 两种方式: publish = 对象 publish_id = id 1. publish_id 和 publish 的区别就是: 1)publish_id 可 ...
- Django数据库数据表操作
建立表单 django通过设置类来快速建表,打开models.py 例: from __future__ import unicode_literals from django.db import m ...
- Django models ORM基础操作--白话聊Django系列
上次我们讲完了views视图,那我们这次来看一下Django强大的ORM,可以这么说,你不懂Django的ORM,你就不懂Django,那废话不多说 ORM又称关系对象映射,在ORM里,一张表就是一个 ...
- django ORM单表操作
1.ORM介绍 ORM是“对象-关系-映射”的简称 映射关系: mysql---------Python 表名----------类名 字段----------属性 表记录--------实例化对象 ...
- Django models 单表查询
从数据库中查询出来的结果一般是一个集合,这个集合叫做 QuerySet 1. 查看Django QuerySet执行的SQL .query.__str__()或 .query属性打印执行的sql语句 ...
随机推荐
- mysql面试题集
Mysql 的存储引擎,myisam和innodb的区别. 答: 1.MyISAM 是非事务的存储引擎,适合用于频繁查询的应用.表锁,不会出现死锁,适合小数据,小并发.5.6之前默认myisam 2. ...
- [leetcode]88. Merge Sorted Array归并有序数组
Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: T ...
- java_22.1 Map 的应用
定义一个九年级,年级里面有一班和二班.且有属于自己班的学生. 九年级 一班 001 张三 002 李四 二班 001 王五 002 马六 把同学都遍历出来 package demo; import ...
- 集群环境下定时调度的解决方案之Quartz集群
集群环境可能出现的问题 在上一篇博客我们介绍了如何在自己的项目中从无到有的添加了Quartz定时调度引擎,其实就是一个Quartz 和Spring的整合过程,很容易实现,但是我们现在企业中项目通常都是 ...
- 操作系统学习笔记(二) 页式映射及windbg验证方式
页式映射 本系列截图来自网络搜索及以下基本书籍: <Windows内核设计思想> <Windows内核情景分析> <WINDOWS内核原理与实现> 一个32位虚拟地 ...
- 学习Acegi应用到实际项目中(1)
在此,本人声明,我处于菜鸟阶段,文章的内容大部分摘自zhanjia的博客(http://zhanjia.iteye.com/category/43399),旨在学习,有很多地方,我理解不够透彻,可能存 ...
- Noxim Overview
PE+Router= Tile Node Architectural Elements: Buffer.h, Router.h, LocalRoutingTable.h, Tile.h, NoC.h, ...
- Android开发之Activity
活动(Activity) 活动是最容易吸引用户的地方,它是一种可以包含用户界面的组件,主要用于和用户交互. FirstActivity 手动创建活动 新建一个project,不再选择empty act ...
- Eclipse进行远程调试(Tomcat远程调试)
1.配置tomcat Linxu系统: tomcat/bin/catalina.sh或者startup.sh开始处中增加如下内容: declare -x CATALINA_OPTS="-Xd ...
- noip第17课资料