bittorrent 学习(一) 种子文件分析与bitmap位图
终于抽出时间来进行 BITTORRENT的学习了
BT想必大家都很熟悉了,是一种文件分发协议。每个下载者在下载的同时也在向其他下载者分享文件。
相对于FTP HTTP协议,BT并不是从某一个或者几个指定的点进行文件下载,而是用户之间进行交互,每个用户既是下载者也是上传者.
BT并不会出现提供下载的服务点出现问题而无法下载的现象。
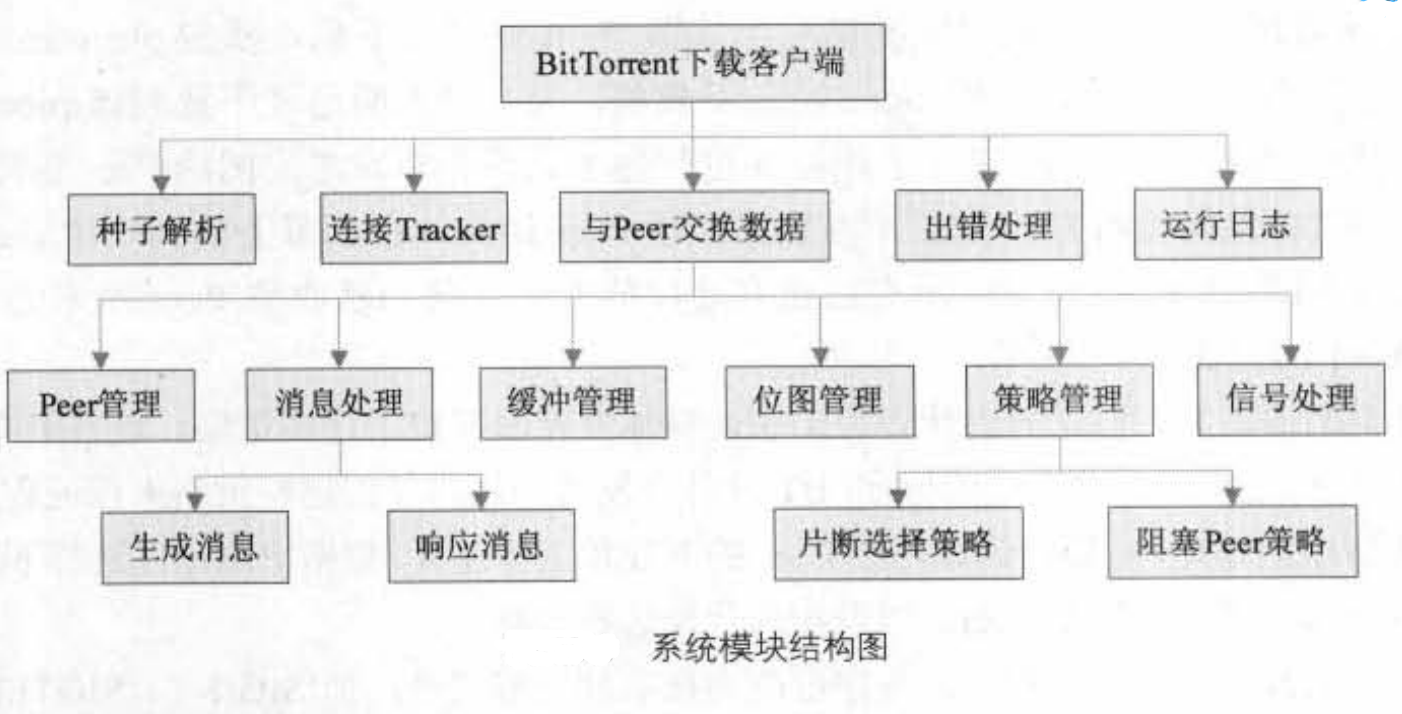
我尝试从BT文件开始下载的流程来分析下我们需要那些功能。
首先我们从某网站下载BT种子文件,文件很小,记录要下载的实际文件的一些信息。
那么我们就需要从该BT种子文件解析出 文件的数量(比如视频文件和文件字幕等多个文件),文件名称,文件大小,还有最重要的连接何处网站获取其他用户信息等等等等。
这个就是种子解析模块。
Tracker服务器会记录在下载该文件的ip和端口,我们连接上去就可以从其他用户peer下载文件了,同时Tracker服务器也会记录我们自己的IP和端口,为其他peer分享文件。
这个是连接Tracker模块。
我们与其他peer进行连接,交换文件数据。就是peer交换数据模块。
主体就是这些。那么在实际运行中,会有一些细节需要解决,衍生出次级模块。
比如我们要知道其他peer下载的文件内容进度和提供我们下载文件的内容进度,这就需要bitmap管理模块。
为了防止有的peer之下载不上传,就需要添加一个策略管理,鼓励所有peer踊跃分享文件。
我们不可能每下一点点文件内容就马上写入磁盘,这样效率太低,所以也需要缓冲管理模块。
以及整个流程中消息的流转和管理的,消息管理模块。
结构图如下:
今天看看种子文件解析代码.bt种子文件使用B编码。如图

了解了字符串 数字 列表和字典后,看看一个实际的BT文件
最开始的就是 d8:announce 41:http://tracker.trackerfix.com:80/announce
13:announce-list
l
l
41:http://tracker.trackerfix.com:80/announce
e
l
30:udp://9.rarbg.to:2710/announce
e
。。。。。。。
e
字典有两个 映射 一个key value是 announce 和 http://tracker.trackerfix.com:80/announce
一个key value 是 announce-list 对应一组列表 列表是 http://tracker.trackerfix.com:80/announce udp://9.rarbg.to:2710/announce 等等
announce-list 中包含了 announce项目下的tracker服务器IP和端口 所以代码中只需要搜索其中一个关键字即可
int read_announce_list()
{
Announce_list *node = NULL;
Announce_list *p = NULL;
int len = ;
long i; if( find_keyword("13:announce-list",&i) == ) {
if( find_keyword("8:announce",&i) == ) {
i = i + strlen("8:announce");
while( isdigit(metafile_content[i]) ) {
len = len * + (metafile_content[i] - '');
i++;
}
i++; // 跳过 ':' node = (Announce_list *)malloc(sizeof(Announce_list));
strncpy(node->announce,&metafile_content[i],len);
node->announce[len] = '\0';
node->next = NULL;
announce_list_head = node;
}
}
else { // 如果有13:announce-list关键词就不用处理8:announce关键词
i = i + strlen("13:announce-list");
i++; // skip 'l'
while(metafile_content[i] != 'e') {
i++; // skip 'l'
while( isdigit(metafile_content[i]) ) {
len = len * + (metafile_content[i] - '');
i++;
}
if( metafile_content[i] == ':' ) i++;
else return -; // 只处理以http开头的tracker地址,不处理以udp开头的地址
if( memcmp(&metafile_content[i],"http",) == ) {
node = (Announce_list *)malloc(sizeof(Announce_list));
strncpy(node->announce,&metafile_content[i],len);
node->announce[len] = '\0';
node->next = NULL; if(announce_list_head == NULL)
announce_list_head = node;
else {
p = announce_list_head;
while( p->next != NULL) p = p->next; // 使p指向最后个结点
p->next = node; // node成为tracker列表的最后一个结点
}
} i = i + len;
len = ;
i++; // skip 'e'
if(i >= filesize) return -;
}
} #ifdef DEBUG
p = announce_list_head;
while(p != NULL) {
printf("%s\n",p->announce);
p = p->next;
}
#endif return ;
}
piece length 表示每个piece的长度 一般是128K
int get_piece_length()
{
long i; if( find_keyword("12:piece length",&i) == ) {
i = i + strlen("12:piece length"); // skip "12:piece length"
i++; // skip 'i'
while(metafile_content[i] != 'e') {
piece_length = piece_length * + (metafile_content[i] - '');
i++;
}
} else {
return -;
} #ifdef DEBUG
printf("piece length:%d\n",piece_length);
#endif return ;
}
分析文件最常用的就是寻找关键字 代码采用比较简单的方法,逐个字节比较关键字
int find_keyword(char *keyword,long *position)
{
long i; *position = -;
if(keyword == NULL) return ; for(i = ; i < filesize-strlen(keyword); i++) {
if( memcmp(&metafile_content[i], keyword, strlen(keyword)) == ) {
*position = i;
return ;
}
} return ;
}
get_info_hash() 计算的是piece的哈希值
首先在文件中找到"4:info"关键字,找到其后的info信息 进行哈希计算.遇到需要‘e’字母对应的开头(比如字典开头‘d’,列表开头'l',数字开头'i'),计数加1.遇到‘e’,计数减1。
计数到零,则说明找到"4:info"的完整信息,可以开始进行哈希计算。
这个要比网络上一些 查找 "4:info" 到 "5:nodes"之间字符串要可靠得多 有些种子文件是没有"5:nodes"
int get_info_hash()
{
int push_pop = ;
long i, begin, end; if(metafile_content == NULL) return -; if( find_keyword("4:info",&i) == ) {
begin = i+; // begin是关键字"4:info"对应值的起始下标
} else {
return -;
} i = i + ; // skip "4:info"
for(; i < filesize; )
if(metafile_content[i] == 'd') {
push_pop++;
i++;
} else if(metafile_content[i] == 'l') {
push_pop++;
i++;
} else if(metafile_content[i] == 'i') {
i++; // skip i
if(i == filesize) return -;
while(metafile_content[i] != 'e') {
if((i+) == filesize) return -;
else i++;
}
i++; // skip e
} else if((metafile_content[i] >= '') && (metafile_content[i] <= '')) {
int number = ;
while((metafile_content[i] >= '') && (metafile_content[i] <= '')) {
number = number * + metafile_content[i] - '';
i++;
}
i++; // skip :
i = i + number;
} else if(metafile_content[i] == 'e') {
push_pop--;
if(push_pop == ) { end = i; break; }
else i++;
} else {
return -;
}
if(i == filesize) return -; SHA1_CTX context;
SHA1Init(&context);
SHA1Update(&context, &metafile_content[begin], end-begin+);
SHA1Final(info_hash, &context); #ifdef DEBUG
printf("info_hash:");
for(i = ; i < ; i++)
printf("%.2x ",info_hash[i]);
printf("\n");
#endif return ;
}
我们需要为自己生成一个用于辨识的peerid,调用get_peer_id()
int get_peer_id()
{
// 设置产生随机数的种子
srand(time(NULL));
// 生成随机数,并把其中12位赋给peer_id,peer_id前8位固定为-TT1000-
sprintf(peer_id,"-TT1000-%12d",rand()); #ifdef DEBUG
int i;
printf("peer_id:");
for(i = ; i < ; i++) printf("%c",peer_id[i]);
printf("\n");
#endif return ;
}
代码中使用了堆内存,在退出或者不使用的时候需要回收。调用 release_memory_in_parse_metafile()
void release_memory_in_parse_metafile()
{
Announce_list *p;
Files *q; if(metafile_content != NULL) free(metafile_content);
if(file_name != NULL) free(file_name);
if(pieces != NULL) free(pieces); while(announce_list_head != NULL) {
p = announce_list_head;
announce_list_head = announce_list_head->next;
free(p);
} while(files_head != NULL) {
q = files_head;
files_head = files_head->next;
free(q);
}
}
//=====================================================================================================
下面看下bitmap 位图
位图相当于一个文件的缩略图,一个字节有8位,如果每位的01代表一个文件的10k的空间是否下载成功,那么我们使用一个字节就可以表示80K文件的下载进度。
而实际上在bttorrent中,每位使用01表示一个piece的下载成功与否,若一个piece是256k,那么一个字节8位就可以表示 256*8=2048k=2M文件的下载进度。
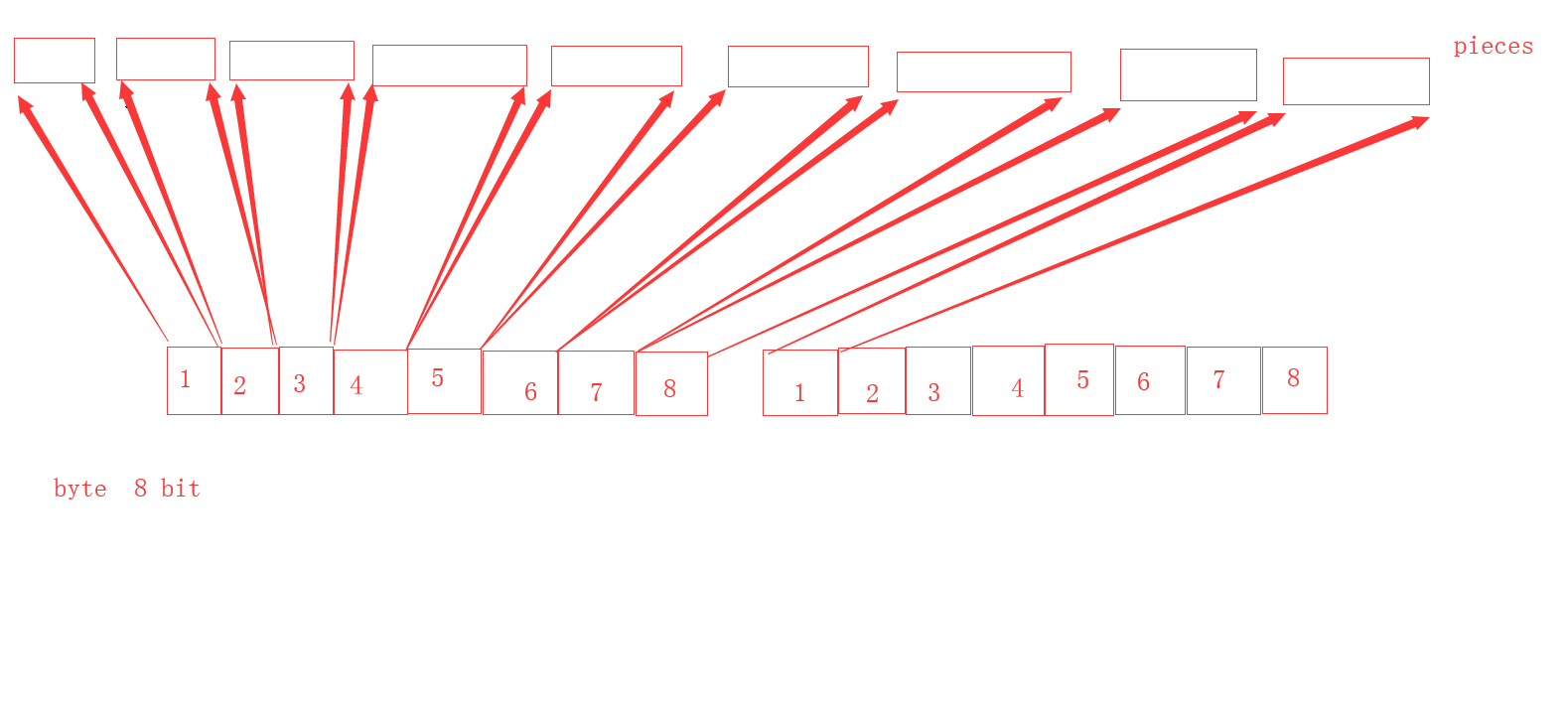
Bitmap结构如下
typedef struct _Bitmap {
unsigned char *bitfield; // 保存位图
int bitfield_length; // 位图所占的总字节数
int valid_length; // 位图有效的总位数,每一位代表一个piece
} Bitmap;
创建bitmap函数流程如下
首先分配Bitmap的内存,然后根据piece长度决定bitmap记录的长度。
valid_length是有效长度,就是能表示的真实文件的长度。 一个位图表示piece长度的1/20
bitfield_length就是位图占用的长度。 一个位图表示piece长度的1/20再除以8 ,就是字节长度
然后根据bitfield_length分配内存。这里需要注意的是,文件长度未必就是完全可以整除的长度,那么bitfield_length就在添加一个字节,用于指示文件整除后不足以显示的余额

// 如果存在一个位图文件,则读位图文件并把获取的内容保存到bitmap
// 如此一来,就可以实现断点续传,即上次下载的内容不至于丢失
int create_bitfield()
{
bitmap = (Bitmap *)malloc(sizeof(Bitmap));
if(bitmap == NULL) {
printf("allocate memory for bitmap fiailed\n");
return -;
} // pieces_length除以20即为总的piece数
bitmap->valid_length = pieces_length / ;
bitmap->bitfield_length = pieces_length / / ;
if( (pieces_length/) % != ) bitmap->bitfield_length++; bitmap->bitfield = (unsigned char *)malloc(bitmap->bitfield_length);
if(bitmap->bitfield == NULL) {
printf("allocate memory for bitmap->bitfield fiailed\n");
if(bitmap != NULL) free(bitmap);
return -;
} char bitmapfile[];
sprintf(bitmapfile,"%dbitmap",pieces_length); int i;
FILE *fp = fopen(bitmapfile,"rb");
if(fp == NULL) { // 若打开文件失败,说明开始的是一个全新的下载
memset(bitmap->bitfield, , bitmap->bitfield_length);
} else {
fseek(fp,,SEEK_SET);
for(i = ; i < bitmap->bitfield_length; i++)
(bitmap->bitfield)[i] = fgetc(fp);
fclose(fp);
// 给download_piece_num赋新的初值
download_piece_num = get_download_piece_num();
} return ;
}
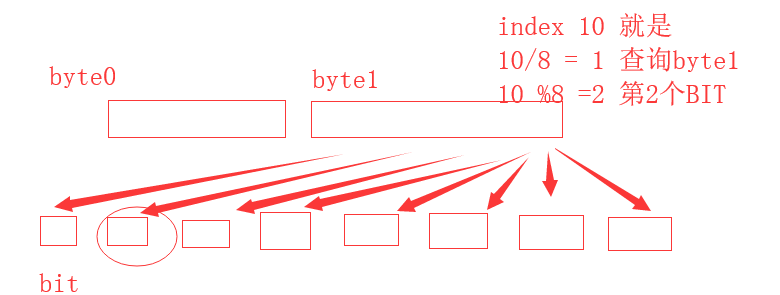
根据索引获取bitmap的标识值
因为是每1位代表一个pieces的下载与否
索引输入的索引值index是位的个数
index / 8 = i i就代表查询或者设置的那位在 第i个byte中。
但是byte有8位,具体是要查询或者设置哪一位呢? index%8=j j就是我们要查询设置的位
示意图 index从1开始
int get_bit_value(Bitmap *bitmap,int index)
{
int ret;
int byte_index;
unsigned char byte_value;
unsigned char inner_byte_index; if(index >= bitmap->valid_length) return -; byte_index = index / ;
byte_value = bitmap->bitfield[byte_index];
inner_byte_index = index % ; byte_value = byte_value >> ( - inner_byte_index);
if(byte_value % == ) ret = ;
else ret = ; return ret;
} int set_bit_value(Bitmap *bitmap,int index,unsigned char v)
{
int byte_index;
unsigned char inner_byte_index; if(index >= bitmap->valid_length) return -;
if((v != ) && (v != )) return -; byte_index = index / ;
inner_byte_index = index % ; v = v << ( - inner_byte_index);
bitmap->bitfield[byte_index] = bitmap->bitfield[byte_index] | v; return ;
}
int all_zero(Bitmap *bitmap)
int all_set(Bitmap *bitmap) 将bitmap记录全部置0和置1
int all_zero(Bitmap *bitmap)
{
if(bitmap->bitfield == NULL) return -;
memset(bitmap->bitfield,,bitmap->bitfield_length);
return ;
} int all_set(Bitmap *bitmap)
{
if(bitmap->bitfield == NULL) return -;
memset(bitmap->bitfield,0xff,bitmap->bitfield_length);
return ;
}
is_interested(Bitmap *dst,Bitmap *src) 比较两个bitmap
如果src的bitmap中有1位为0(即没有这个piece)
而dst的bitmap中这1位为1(即有这个piece) 则说明 src对dst感兴趣 interest
int is_interested(Bitmap *dst,Bitmap *src)
{
unsigned char const_char[] = { 0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01};
unsigned char c1, c2;
int i, j; if( dst==NULL || src==NULL ) return -;
if( dst->bitfield==NULL || src->bitfield==NULL ) return -;
if( dst->bitfield_length!=src->bitfield_length ||
dst->valid_length!=src->valid_length )
return -; for(i = ; i < dst->bitfield_length-; i++) {
for(j = ; j < ; j++) {
c1 = (dst->bitfield)[i] & const_char[j];
c2 = (src->bitfield)[i] & const_char[j];
if(c1> && c2==) return ;
}
} j = dst->valid_length % ;
c1 = dst->bitfield[dst->bitfield_length-];
c2 = src->bitfield[src->bitfield_length-];
for(i = ; i < j; i++) {
if( (c1&const_char[i])> && (c2&const_char[i])== )
return ;
} return ;
}
get_download_piece_num() 获取位图中为1的位数 也就是下载了多少pieces
直接和 0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01 相与
这种做法是遍历一次查询多少个1 要快很多
int get_download_piece_num()
{
unsigned char const_char[] = { 0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01};
int i, j; if(bitmap==NULL || bitmap->bitfield==NULL) return ; download_piece_num =; for(i = ; i < bitmap->bitfield_length-; i++) {
for(j = ; j < ; j++) {
if( ((bitmap->bitfield)[i] & const_char[j]) != )
download_piece_num++;
}
} unsigned char c = (bitmap->bitfield)[i]; // c存放位图最后一个字节
j = bitmap->valid_length % ; // j是位图最后一个字节的有效位数
for(i = ; i < j; i++) {
if( (c & const_char[i]) != ) download_piece_num++;
} return download_piece_num;
}
把代码改写成了cpp
附上
#pragma once
#include "pre.h"
#include <string>
#include <vector> NAMESPACE(DEF)
NAMESPACE(BTPARSE)
class ParseBT {
public:
ParseBT() {
metaFileSize = ;
piece_length = -;
pieces_length = ;
multi_file = false;
buf_ptr = std::shared_ptr<char>(new char[DEF_BUF_SIZE], std::default_delete<char[]>());
}
~ParseBT() {}
bool ReadMetaFile(std::string name);
bool ReadAnnounceList();
bool FindKeyWord(const std::string& key,int& pos);
bool IsMultiFiles();
bool GetPieceLength();
bool GetPieces();
bool GetFileName();
bool GetFilesLengthPath();
bool GetFileLength();
bool GetInfoHash();
bool GetPerID();
private:
long metaFileSize;
bool multi_file;
int piece_length;
int pieces_length;
ParseBT(const ParseBT&) = delete;
ParseBT& operator=(const ParseBT&) = delete;
enum {
DEF_BUF_SIZE = *
}; unsigned char infoHash[];
unsigned char peerID[];
std::vector < std::pair<std::string, size_t> > fileInfos; std::shared_ptr<char> buf_ptr;
std::shared_ptr<char> pieces_ptr;
std::vector<std::string> announce_list;
}; ENDNAMESPACE(BTPARSE)
ENDNAMESPACE(DEF)
ParseBT.h
#include <iostream> #include <time.h>
extern "C" {
#include "sha1.h"
}
#include "ParseBT.h" NAMESPACE(DEF)
NAMESPACE(BTPARSE)
struct Fclose
{
void operator()(FILE* fp)
{
fclose(fp);
fp = NULL;
}
}; bool ParseBT::ReadMetaFile(std::string name) {
bool b = false;
if (name.empty())
return b; std::unique_ptr<FILE, Fclose> fp(fopen(name.c_str(), "rb"));
if (fp == nullptr) {
std::cerr << __FUNCTION__ << "error!" << std::endl;
return b;
} // 获取种子文件的长度
fseek(fp.get(), , SEEK_END);
metaFileSize = ftell(fp.get());
if (metaFileSize == -) {
printf("%s:%d fseek failed\n", __FILE__, __LINE__);
return b;
}
if (DEF_BUF_SIZE < metaFileSize) {
std::shared_ptr<char> p = std::shared_ptr<char>(new char[metaFileSize], std::default_delete<char[]>());
buf_ptr.swap( p );
} fseek(fp.get(), , SEEK_SET);
int readbyte = fread(buf_ptr.get(),, metaFileSize,fp.get());
if (readbyte != metaFileSize) {
std::cerr << __FUNCTION__ << ". fread() error!" << std::endl;
return b;
} b = true;
return b;
} bool ParseBT::GetInfoHash() {
bool b = false;
int i = ;
int begin = ; int push_pop = ; int end = ; if (buf_ptr == NULL) return b; if (FindKeyWord("4:info", i) == true) {
begin = i + ; // begin是关键字"4:info"对应值的起始下标
}
else {
return -b;
} i = i + ; // skip "4:info" for (; i < metaFileSize; )
if (buf_ptr.get()[i] == 'd') {
push_pop++;
i++;
}
else if (buf_ptr.get()[i] == 'l') {
push_pop++;
i++;
}
else if (buf_ptr.get()[i] == 'i') {
i++; // skip i
if (i == metaFileSize) return -;
while (buf_ptr.get()[i] != 'e') {
if ((i + ) == metaFileSize) return -;
else i++;
}
i++; // skip e
}
else if ((buf_ptr.get()[i] >= '') && (buf_ptr.get()[i] <= '')) {
int number = ;
while ((buf_ptr.get()[i] >= '') && (buf_ptr.get()[i] <= '')) {
number = number * + buf_ptr.get()[i] - '';
i++;
}
i++; // skip :
i = i + number;
}
else if (buf_ptr.get()[i] == 'e') {
push_pop--;
if (push_pop == ) { end = i; break; }
else i++;
}
else {
return -;
}
if (i == metaFileSize) return b; SHA1Context context;
SHA1Reset(&context);
unsigned char* p = (unsigned char*)buf_ptr.get();
SHA1Input(&context, &(p[begin]), end - begin + );
SHA1Result(&context, infoHash); printf("begin = %d ,end = %d \n", begin, end); #if 1
printf("info_hash:");
for (i = ; i < ; i++)
printf("%.2x ", infoHash[i]);
printf("\n");
#endif b = true;
return b;
} bool ParseBT::GetFileName() {
bool b = false;
int i;
int count = ; if (FindKeyWord("4:name", i) == true) {
i = i + ; // skip "4:name"
while ((buf_ptr.get())[i] != ':') {
count = count * + ((buf_ptr.get())[i] - '');
i++;
}
i++; // skip ':'
std::string file_name(&(buf_ptr.get())[i], &(buf_ptr.get())[i]+count);
//std::string s = "反贪风暴3.L.Storm.2018.1080p.WEB-DL.X264.AAC-国粤中字-RARBT";
}
else {
return b;
} #if 1
// 由于可能含有中文字符,因此可能打印出乱码
// printf("file_name:%s\n",file_name);
#endif return b;
} bool ParseBT::FindKeyWord(const std::string& key, int& pos) {
bool b = false;
pos = ;
if (key.empty()) return b; for (int i = ; i < metaFileSize - key.size(); i++) {
if (memcmp(&(buf_ptr.get())[i], key.c_str(),key.size()) == ) {
pos = i; b = true;
return b;
}
} return b;
} bool ParseBT::ReadAnnounceList() {
bool b = false;
int i = -;
int len = ;
if (FindKeyWord("13:announce-list", i) == false) {
if (FindKeyWord("8:announce", i) == true) {
i = i + strlen("8:announce");
while (isdigit((buf_ptr.get())[i])) {
len = len * + ((buf_ptr.get())[i] - '');
i++;
}
i++; // 跳过 ':' std::string s ( &(buf_ptr.get())[i] , &(buf_ptr.get())[i]+len);
announce_list.push_back(s);
b = true;
}
}
else {
//如果有13:announce-list关键词就不用处理8:announce关键词
i = i + strlen("13:announce-list");
i++; // skip 'l'
while ((buf_ptr.get())[i] != 'e') {
i++; // skip 'l'
while (isdigit((buf_ptr.get())[i])) {
len = len * + ((buf_ptr.get())[i] - '');
i++;
}
if ((buf_ptr.get())[i] == ':') i++;
else return b; // 只处理以http开头的tracker地址,不处理以udp开头的地址
if (memcmp(&(buf_ptr.get())[i], "http", ) == ) { std::string s(&(buf_ptr.get())[i], &(buf_ptr.get())[i] + len);
announce_list.push_back(s);
} i = i + len;
len = ;
i++; // skip 'e'
if (i >= metaFileSize) return b; }
}
#if 0
std::cout << "announce_list size = " << announce_list.size() << std::endl;
for (auto& e : announce_list) {
std::cout << e << std::endl;
}
std::cout << std::endl;
#endif
b = true;
return b;
} bool ParseBT::IsMultiFiles() {
bool b = false;
int i; if (FindKeyWord("5:files", i) == true) {
multi_file = true;
b = true;
} #if 1
printf("is_multi_files:%d\n",multi_file);
#endif b = true;
return b;
} bool ParseBT::GetPieceLength() {
int length = ;
int i = ;
if (FindKeyWord("12:piece length", i) == true) {
i = i + strlen("12:piece length"); // skip "12:piece length"
i++; // skip 'i'
while ((buf_ptr.get())[i] != 'e') {
length = length * + ((buf_ptr.get())[i] - '');
i++;
}
}
else {
return false;
} piece_length = length; #if 1
printf("piece length:%d\n", piece_length);
#endif return true;
} bool ParseBT::GetPieces() {
bool b = false;
int i = ; if (FindKeyWord("6:pieces", i) == true) {
i = i + ; // skip "6:pieces"
while ((buf_ptr.get())[i] != ':') {
pieces_length = pieces_length * + ((buf_ptr.get())[i] - '');
i++;
}
i++; // skip ':' pieces_ptr = std::shared_ptr<char>(new char[pieces_length + ], std::default_delete<char[]>()); memcpy(pieces_ptr.get(), &(buf_ptr.get())[i], pieces_length);
(pieces_ptr.get())[pieces_length] = '\0';
}
else {
return b;
} #if 1
printf("get_pieces ok\n");
#endif b = true;
return b;
} bool ParseBT::GetFileLength() {
bool b = false;
int i = ;
size_t file_length = ;
if (IsMultiFiles() == true) {
if (fileInfos.empty())
GetFilesLengthPath();
for (auto& e : fileInfos) {
file_length += e.second;
}
}
else {
if (FindKeyWord("6:length", i) == true) {
i = i + ;
i++;
while (buf_ptr.get()[i] != 'e') {
file_length = file_length * + (buf_ptr.get()[i] -'');
i++;
}
}
} #if 1
printf("file_length:%lld\n", file_length);
#endif b = true; return b;
} bool ParseBT::GetFilesLengthPath() {
bool b = false;
if (IsMultiFiles() != true) {
return b;
} std::string name;
size_t length = ;
int i = ;
int count = ;
for ( i = ; i < metaFileSize - ; i++) {
if (memcmp(&(buf_ptr.get())[i], "6:length", ) == ) {
i = i + ;
i++; while ((buf_ptr.get())[i] != 'e') {
length = length* + ((buf_ptr.get())[i] - '');
i++;
}
} if (memcmp(&(buf_ptr.get())[i], "4:path", ) == ) {
i = i + ;
i++;
count = ;
while (buf_ptr.get()[i] != ':') {
count = count * + (buf_ptr.get()[i] - '');
i++;
}
i++;
name = std::string(&(buf_ptr.get())[i], &(buf_ptr.get())[i] + count);
//std::cout << name << std::endl; if (!name.empty() && length != ) {
std::pair<std::string, size_t> pa{ name,length };
fileInfos.push_back(pa);
name.clear();
length = ;
}
}
} b = true;
return b;
} bool ParseBT::GetPerID() {
bool b = false;
srand(time(NULL));
sprintf((char*)peerID, "TT1000-%12d", rand()); #if 1
int i;
printf("peer_id:");
for (i = ; i < ; i++) printf("%c", peerID[i]);
printf("\n");
#endif b = true;
return b;
} ENDNAMESPACE(BTPARSE)
ENDNAMESPACE(DEF)
ParseBT.cpp
// MyParseBTFile.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
// #include <iostream>
#include "ParseBT.h" using namespace DEF::BTPARSE; int main()
{
for (int i = ; i < ; i++) {
ParseBT pbt;
if (false == pbt.ReadMetaFile("1.torrent"))
return ;
int pos = -;
pbt.FindKeyWord("info", pos);
pbt.ReadAnnounceList();
pbt.IsMultiFiles();
pbt.GetPieceLength();
pbt.GetPieces();
pbt.GetFileName();
pbt.GetFilesLengthPath();
pbt.GetFileLength();
pbt.GetInfoHash();
pbt.GetPerID();
} }
main.cpp
参考
《linux c编程实战》第十三章节btcorrent 及代码
bittorrent 学习(一) 种子文件分析与bitmap位图的更多相关文章
- 学习CTF的经历-文件分析
文件分析-ZIP伪加密 最近在准备铁人三项赛的比赛,所以在实验吧上尝试着学习CTF,目前菜鸡一枚 我主要负责的是Web和安全杂项这一块,安全杂项的知识点较为薄弱,在实验吧练习的过程中遇到一个很有趣的题 ...
- bittorrent 学习(三) MSG
msg.c中 int转化 char[4] char[4]转化int的函数 如下(有多种方案) ]) { c[] = i % ; c[] = (i - c[]) / % ; c[] = (i - c[ ...
- 原 iOS深入学习(Block全面分析)http://my.oschina.net/leejan97/blog/268536
原 iOS深入学习(Block全面分析) 发表于1年前(2014-05-24 16:45) 阅读(26949) | 评论(14) 39人收藏此文章, 我要收藏 赞21 12月12日北京OSC源创会 ...
- Nmap脚本文件分析(AMQP协议为例)
Nmap脚本文件分析(AMQP协议为例) 一.介绍 上两篇文章 Nmap脚本引擎原理 编写自己的Nmap(NSE)脚本,分析了Nmap脚本引擎的执行过程,以及脚本文件的编写,这篇文章将以解析AMQ ...
- FFmpeg 结构体学习(二): AVStream 分析
在上文FFmpeg 结构体学习(一): AVFormatContext 分析我们学习了AVFormatContext结构体的相关内容.本文,我们将讲述一下AVStream. AVStream是存储每一 ...
- FFmpeg 结构体学习(三): AVPacket 分析
在上文FFmpeg 结构体学习(二): AVStream 分析我们学习了AVStream结构体的相关内容.本文,我们将讲述一下AVPacket. AVPacket是存储压缩编码数据相关信息的结构体.下 ...
- FFmpeg 结构体学习(七): AVIOContext 分析
在上文FFmpeg 结构体学习(六): AVCodecContext 分析我们学习了AVCodec结构体的相关内容.本文,我们将讲述一下AVIOContext. AVIOContext是FFMPEG管 ...
- DotNetty网络通信框架学习之源码分析
DotNetty网络通信框架学习之源码分析 有关DotNetty框架,网上的详细资料不是很多,有不多的几个博友做了简单的介绍,也没有做深入的探究,我也根据源码中提供的demo做一下记录,方便后期查阅. ...
- python入门学习:9.文件和异常
python入门学习:9.文件和异常 关键点:文件.异常 9.1 从文件中读取数据9.2 写入文件9.3 异常9.4 存储数据 9.1 从文件中读取数据 9.1.1 读取整个文件 首先创建一个pi_ ...
随机推荐
- Excel技巧--按内容分列与合并
上表的A列,如果想要按横线分隔开多列,复制粘贴很麻烦,可以使用“数据”-->“分列”来分隔开: 1.选择A列,在A列后预先插入三列空列.点击“数据”—>“分列”,对话框选择按“分隔符号”分 ...
- 2017 browser market share
Refer to Net Market Share published data for year 2017, browser share percentage as below table show ...
- 浅读官方代码--ActionManager
用于管理节点的动作 { CCDirector* pDirector = CCDirector::sharedDirector(); //获得单例 pDirector->getActionMana ...
- 廖雪峰Java7处理日期和时间-1概念-1日期和时间
1.日期 日期是指某一天,如2016-11-20,2018-1-1 2.时间有2种: 不带日期的时间:14:23:54 带日期的时间:2017-1-1 20:21:23,唯一确定某个时刻 3.时区 时 ...
- base64图片内容下载转为图片保存
网页中的base64图片内容下载后,利用PIL转为图片保存 from skimage.io import imread from PIL import Image from cStringIO imp ...
- 初识docker-镜像
前言: 以前学习docker 都是零零碎碎的,只知道用,有些莫名其妙的报错自己也没有思路去解决,所以基于一本专业的介绍docker的书籍,重新开启学习,该博客就记录下我自己的学习过程吧. 1.dock ...
- [sharepoint]修改Item或者File的Author和Editor
写在前面 最近项目中调用sharepoint rest api方式获取文件或者Item列表,而用的方式是通过证书请求,在上传文件,或者新建item的时候,默认的用户是在sharepoint端注册的用户 ...
- C语言 链表(VS2012版)
// ConsoleApplication2.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <stdio.h> ...
- android 开发 框架系列 使用 FileDownloader 实现检查更新的功能class
首先介绍一下FileDownloader GH :https://github.com/lingochamp/FileDownloader/blob/master/README-zh.md FileD ...
- Google Colab Notebook 的外部文件引用配置
Google Colab Notebook 的外部文件引用配置 Reference: How to upload the file and read Google Colab 先装工具:google- ...