序列化(pickle,shelve,json,configparser)
一,序列化
在我们存储数据或者网络传输数据的时候,需要对我们的对象进行处理,把对象处理成方便存储和传输的数据结构,这个过程叫序列化,不同的序列化,结果也不同,但是目的是一样的,都是为了存储和传输。
在python中存在三种序列化的方案。
1,pickle,可以将我们python中的任意数据类型转化成bytes并写入到文件中,同样也可以把文件中写好的bytes转换回我们python的数据,这个过程称为反序列化。
2,shelve,简单另类的一种序列化的方案,有点类似Redis,可以作为一种小型数据库来使用
3,json,将python中常见的字典,列表转化成字符串,是目前前后端数据交互使用频率最高的一种数据格式。
二,pickle(重点)
pickle就是把我们的python对象写入到文件中的一种解决方案。首先要引用pickle模块,主要是使用pickle.dumps()把对象转换成bytes;pickle.loads()把bytes转换成对象;

pickle.dump()把对象转换成bytes,然后写入文件中;pickle.load()从文件中读出,然后把bytes转换成对象。

多个对象写入和读


三,shelve
shelve提供python的持久化操作,就是把数据写到硬盘上,在操作shelve的时候非常像操作一个字典。

但是有个坑,在对内层的数据进行修改时,或者删除字典中的元素时,要用到writeback参数,不然操作后结果不会改变。

得到后的字典,可以完成字典所有操作,比如遍历,setdefault()


四,json(重点)
json就是前后端交互的枢纽,导入json模块,所使用的方法和pickle一样的。json.dumps()把字典转化成json字符串,json.loads()是把json字符串转化成字典。


json.dump()把字典转化成json字符串,然后写入文件中;json.load()把json字符串从文件中读出来,然后转换成字典。


对于多个字典的写入或者读,要采用以下办法。

用json来处理对象
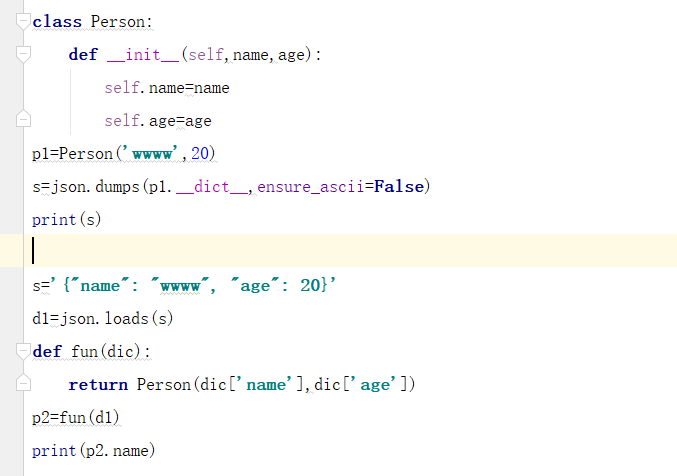
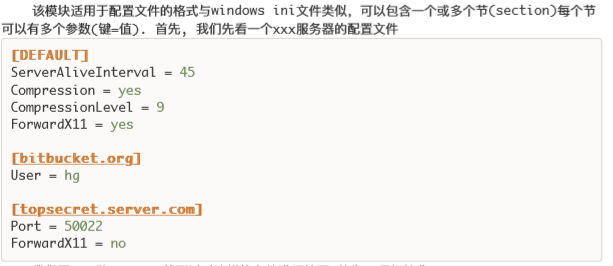
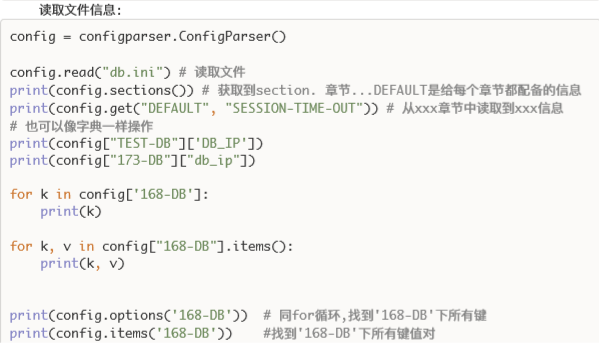
五,configparser模块




序列化(pickle,shelve,json,configparser)的更多相关文章
- python 序列化 pickle shelve json configparser
1. 什么是序列化 我们把变量从内存中变成可存储或传输的过程称之为序列化. 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上. 反过来,把变量内容从序列化的对象重新读到内存里称 ...
- 序列化 pickle shelve json configparser
模块pickle(皮考) dumps(当破死)序列化. 把对象转化成bytes loads(楼死) 反序列化. 吧bytes转化成对象 dic = {"jay": "周杰 ...
- Python 常用模块(2) 序列化(pickle,shelve,json,configpaser)
主要内容: 一. 序列化概述 二. pickle模块 三. shelve模块 四. json模块(重点!) 五. configpaser模块 一. 序列化概述1. 序列化: 将字典,列表等内容转换成一 ...
- 各类模块的粗略总结(time,re,os,sys,序列化,pickle,shelve.#!json )
***collections 扩展数据类型*** ***re 正则相关操作 正则 匹配字符串*** ***time 时间相关 三种格式:时间戳,格式化时间(字符串),时间元组(结构化时间).***`` ...
- python笔记-7(shutil/json/pickle/shelve/xml/configparser/hashlib模块)
一.shutil模块--高级的文件.文件夹.压缩包处理模块 1.通过句柄复制内容 shutil.copyfileobj(f1,f2)对文件的复制(通过句柄fdst/fsrc复制文件内容) 源码: Le ...
- json/pickle/shelve/xml/configparser/hashlib/subprocess - 总结
序列化:序列化指把内存里的数据类型转成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes为什么要序列化:可以直接把内存数据(eg:10个列表,3个嵌套字典)存到硬盘 ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
- Python序列化-pickle和json模块
Python的“file-like object“就是一种鸭子类型.对真正的文件对象,它有一个read()方法,返回其内容.但是,许多对象,只要有read()方法,都被视为“file-like obj ...
- 序列化与反序列化,json,pickle,xml,shelve,configparser模块
序列化与反序列化 什么是序列化?序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输.反序列化就是将硬盘中或者网络中传来的一种数据格式转换成内存中数据结构. 为什么要有? 1.可以 ...
- 模块简介:(random)(xml,json,pickle,shelve)(time,datetime)(os,sys)(shutil)(pyYamal,configparser)(hashlib)
Random模块: #!/usr/bin/env python #_*_encoding: utf-8_*_ import random print (random.random()) #0.6445 ...
随机推荐
- AX_InventDim
static void Job1(Args _args) { ; info(InventDim::find("D00000001").preFix()); } public voi ...
- FTP服务与配置
FTP简介 网络文件共享服务主流的主要有三种,分别是ftp.nfs.samba. FTP是File Transfer Protocol(文件传输协议)的简称,用于internet上的控制文件的双向传输 ...
- URI编码时遇到特殊字符的处理方式
今天遇到一个问题,在向一个地址发起get请求时,某个参数是这种形式:foo=xx&&yyyy,其中"&&"是参数值的一部分,在调用这个接口时,后台收 ...
- boost--内存池
boost的内存池实现了一个快速.紧凑的内存分配和管理器,使用它可以完全不用考虑delete释放问题.常用的boost内存池有pool.object_pool.singleton_pool. 1.po ...
- dom4j 使用原生xpath 处理带命名空间的文档
测试文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.o ...
- VB.NET 定义多行文本字符的几种方式
vbCrLf 在 .NET 刚刚推出的时候,VB作为一款被微软用来"衬托"C#的语言,在许多细节设计上远不如C#方便. 比如在C#中写一个多行文本,就有各种方式: string s ...
- 《分布式Java应用与实践》—— 后面两章
failover? NAT IP-tunneling DSR vrrp gossip 什么是2PC? 什么是3PC? 什么是Pasox? sna? dal? mpi?
- vsftpd安装配置以及常见问题解决
vsftpd安装配置以及踩坑解决办法,Centos7 nginx已经配置成功了,但是使用http始终没办法访问到图片,那么你来对地方了(在文章末尾是原因) 配置nginx教程:http://blog. ...
- [Python列表]-索引
Python 列表(List) 前言 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. Python有6个序列的内 ...
- 使用 Maven 插件将 class(字节码文件),resource(资源文件),lib(依赖的jar包)分开打包
1. 在pom文件中对各个插件进行配置 <?xml version="1.0" encoding="UTF-8"?> <project xml ...