python正则表达式(二)
表示字符
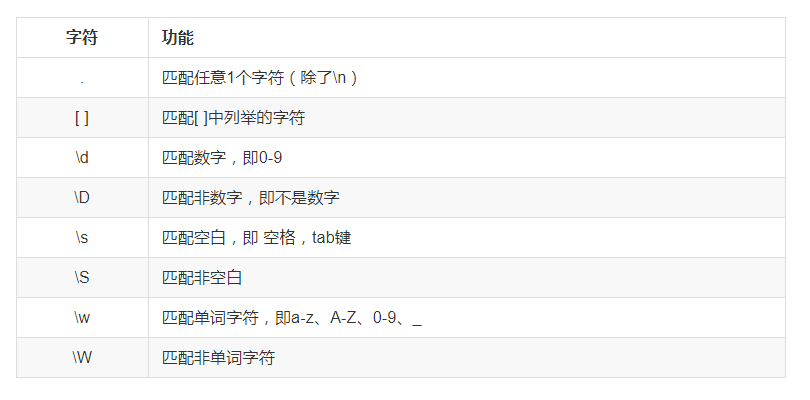
示例1: .
#coding=utf-8
import re
ret = re.match(".","a")
ret.group()
ret = re.match(".","b")
ret.group()
ret = re.match(".","M")
ret.group()

示例2:[ ]
#coding=utf-8
import re
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
ret.group()
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
ret.group()
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
ret.group()
ret = re.match("[hH]","Hello Python")
ret.group()
# 匹配0到9第一种写法
ret = re.match("[0123456789]","7Hello Python")
ret.group()
# 匹配0到9第二种写法
ret = re.match("[0-9]","7Hello Python")
ret.group()

示例3:\d
#coding=utf-8
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print ret.group()
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print ret.group()
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print ret.group()
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print ret.group()
ret = re.match("嫦娥\d号","嫦娥2号发射成功")
print ret.group()
ret = re.match("嫦娥\d号","嫦娥3号发射成功")
print ret.group()

原始字符串
>>> mm = "c:\\a\\b\\c"
>>> mm
'c:\\a\\b\\c'
>>> print(mm)
c:\a\b\c
>>> print(mm)
c:\a\b\c
>>> re.match("c:\\\\",mm).group()
'c:\\'
>>> ret = re.match("c:\\\\",mm).group()
>>> print(ret)
c:\
>>> ret = re.match("c:\\\\a",mm).group()
>>> print(ret)
c:\a
>>> ret = re.match(r"c:\\a",mm).group()
>>> print(ret)
c:\a
>>> ret = re.match(r"c:\a",mm).group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>>
说明
Python中字符串前面加上 r 表示原生字符串,
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,有了原始字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> ret = re.match(r"c:\\a",mm).group()
>>> print(ret)
c:\a
表示数量
匹配多个字符的相关格式
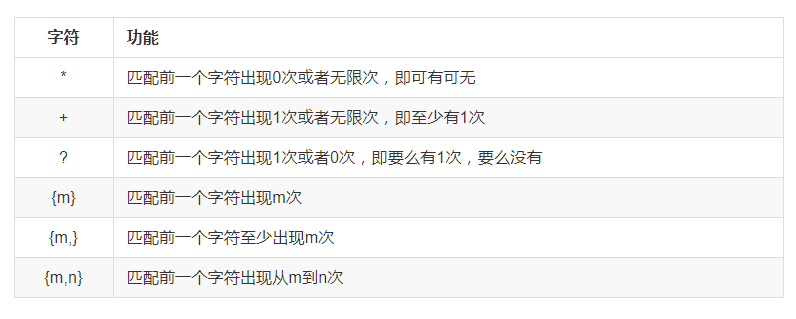
示例1:*
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
#coding=utf-8
import re ret = re.match("[A-Z][a-z]*","Mm")
ret.group() ret = re.match("[A-Z][a-z]*","Aabcdef")
ret.group()

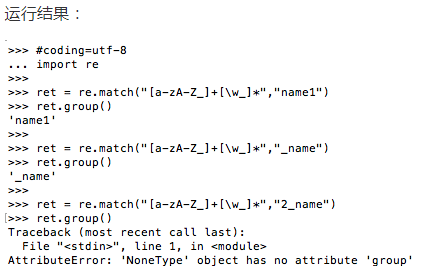
示例2:+
需求:匹配出,变量名是否有效
#coding=utf-8
import re ret = re.match("[a-zA-Z_]+[\w_]*","name1")
ret.group() ret = re.match("[a-zA-Z_]+[\w_]*","_name")
ret.group() ret = re.match("[a-zA-Z_]+[\w_]*","2_name")
ret.group()
示例3:?
需求:匹配出,0到99之间的数字
#coding=utf-8
import re ret = re.match("[1-9]?[0-9]","")
ret.group() ret = re.match("[1-9]?[0-9]","")
ret.group() ret = re.match("[1-9]?[0-9]","")
ret.group()

示例4:{m}
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
#coding=utf-8
import re ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
ret.group() ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
ret.group()

python正则表达式(二)的更多相关文章
- python正则表达式二[转]
原文:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html 1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一 ...
- python3.4学习笔记(十二) python正则表达式的使用,使用pyspider匹配输出带.html结尾的URL
python3.4学习笔记(十二) python正则表达式的使用,使用pyspider匹配输出带.html结尾的URL实战例子:使用pyspider匹配输出带.html结尾的URL:@config(a ...
- Python正则表达式初识(二)
前几天给大家分享了Python正则表达式初识(一),介绍了正则表达式中的三个特殊字符“^”.“.”和“*”,感兴趣的伙伴可以戳进去看看,今天小编继续给大家分享Python正则表达式相关特殊字符知识点. ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- python正则表达式 小例几则
会用到的语法 正则字符 释义 举例 + 前面元素至少出现一次 ab+:ab.abbbb 等 * 前面元素出现0次或多次 ab*:a.ab.abb 等 ? 匹配前面的一次或0次 Ab?: A.Ab 等 ...
- Python 正则表达式-OK
Python正则表达式入门 一. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分. 正则表达式是用于处理字符串的强大工具, 拥有自己独特的语法以及一个独立的处理引擎, 效率上 ...
- Python正则表达式一
推荐 http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html#!comments 这篇博客超好,建议收藏. 不过对于正则表达式小白,他没 ...
- python 正则表达式汇总
一. 正则表达式基础 1.1.概念介绍 正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥 ...
- 一篇搞定Python正则表达式
1. 正则表达式语法 1.1 字符与字符类 1 特殊字符:\.^$?+*{}[]()| 以上特殊字符要想使用字面值,必须使用\进行转义 2 字符类 1. 包含在[]中的一个或者多个字符被称为字符 ...
- Python正则表达式很难?一篇文章搞定他,不是我吹!
1. 正则表达式语法 1.1 字符与字符类 1 特殊字符:.^$?+*{}| 以上特殊字符要想使用字面值,必须使用进行转义 2 字符类 1. 包含在[]中的一个或者多个字符被称为字符类,字符类在匹配时 ...
随机推荐
- IDEA文件对比
- 关于使用summernote编辑器提示内容无法汉化临时解决办法
原因:使用汉化summernote-zh-CN.js文件无法汉化 $('#summernote').summernote({ lang: 'zh-CN' }); 解决方法: 打开summernote. ...
- CSS预处理器—Sass、LESS和Stylus
http://www.w3cplus.com/css/css-preprocessor-sass-vs-less-stylus-2.html 一.什么是CSS预处器 CSS预处理器定义了一种新的语言, ...
- java线程间的通信方式
1.同步 synchronized 2.轮询 while volatile 3.wait/notify机制 syncrhoized加锁的线程的Object类的wait()/notify()/not ...
- 一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)
Hive只在一个节点上安装即可: 1.上传tar包:这个上传就不贴图了,贴一下上传后的,看一下虚拟机吧: 2.解压操作: [root@slaver3 hadoop]# tar -zxvf hive-0 ...
- table无法控制宽度
table-layout:fixed
- MySQL事务提交过程(二)
上一篇文章我们介绍了在关闭binlog的情况下,事务提交的大概流程.之所以关闭binlog,是因为开启binlog后事务提交流程会变成两阶段提交,这里的两阶段提交并不涉及分布式事务,当然mysql把它 ...
- 未在本地计算机上注册“OraOLEDB.Oracle.1”提供程序。
问题描述:运行访问oracle数据库的.net程序时,弹出错误"未在本地计算机上注册“OraOLEDB.Oracle.1”提供程序". 系统环境:windows server 2 ...
- IIS:另一个程序正在使用此文件进程无法访问。
启动网站时,遇到这个错误,一般是端口已经被占用,更换一个空闲端口即可. 通过以下命令可查询 根据最后一列的数字在任务管理器中可查看被哪个程序占用了
- admin密码对应的MD5值
admin密码对应的MD5值,16位和32位 admin密码对应的MD5值,16位和32位 admin的md5值是多少,常用密码加密md5值,123456,admin,admin888 如果遇到MD5 ...