Preference Learning——Object Ranking
Basics About Orders
- Object Ranking应用:
- 量化的受訪者的感觉或印象(quantification of respondents’ sensations or impressions)
- 信息检索(information retrieval)
- 理性决策(decision making)
- 定义基本符号
- X:object集合
- xj:索引號为j的object
- xj = [xj1,xj2,…xjk]:xj由一个长度为k的特征向量表示。当中k是特征个数
- O = xa>xb>…xc:O是一个排名
- X(Oi)= Xi:X中Oi的object
- Li = |X(Oi)| = |Xi|:Xi的长度
- 假设某个Oi的个数等于X。那么这个Oi排名就是一个全排名。
- r(Oi , xj)= rij:Oi排名中的第j名是哪个object
- 举例:Oi = x1>x3>x2, r(Oi,x2) = ri2表示Oi的第二名:3
- 对于两个排名O1,O2,存在两个不等的xa,xb,假设(r1a-r1b)(r2a-r2b)>= 0说明这两个object(xa,xb)在两个排名(O1,O2)的排名前后是一致的。
- 假设O1,O2中全部的object的排名前后都一致。则说明O1,O2这两个排名是一致的。
斯皮尔曼距离(Spearman distance)
- 当两个排名中的元素同样时(仅仅有元素同样才有可比性)能够计算这两个排名的距离。计算公式例如以下:
将其规范化到[-1,1]得到 Spearman’s rank correlation p,(当中L =|X|)
- 这得到的是两个全排名的相关性系数。
- 当两个排名中的元素同样时(仅仅有元素同样才有可比性)能够计算这两个排名的距离。计算公式例如以下:
肯德尔距离(Kendall distance)是还有一个被广泛应用的距离
- 当x>0时,sgn(x)=0,当x<0时。 sgn(x)= -1.
- M= (L-1)L/2等于全部的object pairs.
- 将其规范化到[-1,1]得到Kendall’s rank correlation τ:
计算p和τ的代价各自是O(LlogL)和O(L^2),这这两个值本身也有非常高的相关性。他们之间的差距能够通过Daniels’ inequality来界定:
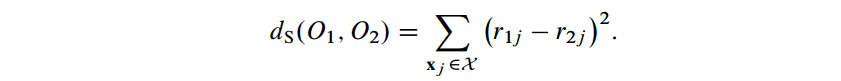
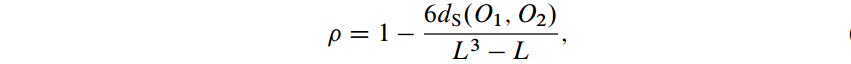
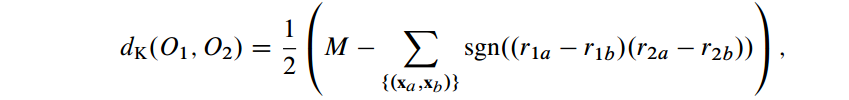
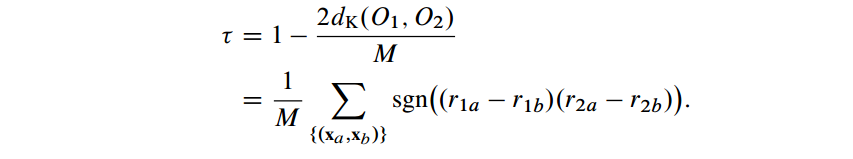
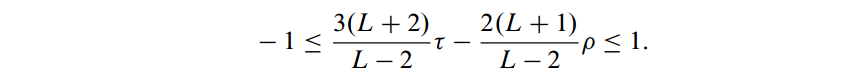
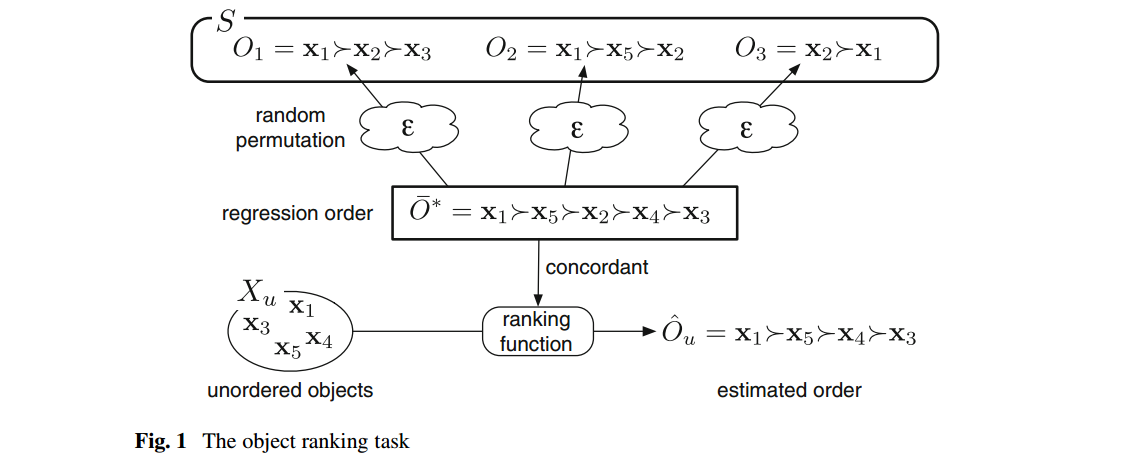
- 还有一个描写叙述ds和dk之间的关系的不等式是Durbin–Stuart’s inequality:
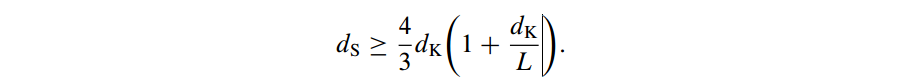
An Object Ranking Task
- 输入:若干个object pair之间的相对关系{O1,O2,…On}
- 给定:模型的误差函数ε()
目的:找到一个排名函数(ranking function)ord(),使得ε(ord(Xi)).sum()最小。ord(Xi)表示了预測排名和输入排名Oi之间的差。
看一个样例:
当中O1,O2,O3是能够观測到的object排名,通过一个回归函数。进行排名得到的是O,当中对于每一个Oi都会产生一个误差ε,通过最小化这个误差和来求得最优的回归模型。*这个概念在机器学习中叫aggregated ranking,在统计学中叫center of orders。
当中的x4在输入模型中并没有观測数据,那么处理这类数据的原则是:若两个object在特征空间上是邻居,那么其排名上也会非常接近。
- 绝对排名(absolute):描写叙述的是回归函数对x1,x2的排名不论是否存在x3,都是一致的
- 相对排名(relative):当存在其它object时。x1,x2的排名可能不一致。可能会出现x1 >x2 > x3 and x2 >x4 > x1
绝对排名在过滤或者推荐系统中更受欢迎。在总结多文档时。当提取了重要句子后又出现新的句子时。那么原有的排序将会受到影响,採用相对排名比較合适。
Object Ranking Methods
Cohen’s method (Cohen)
Cohen的目标是找到一个Ou使得以下这个式子最大化:
当X非常大时,这个问题是NP难的。
因此Cohen提出了一个贪心的算法(Xu表示全部的objects):
- 第一个for循环是计算每一个节点的排名在前面的个数(遍历每对object。对在前面的object的score加1)
- 第二个while循环里面,首先将score的分最大的那个object排在Ou的后面,然后在Xu中删除该元素。
- 内循环for的任务是改动score,此处掉了求和符号。应该与第一个一样。仅仅是这里的Xu改动了
- P[xa>xb|xa,xb]是通过Cohen的Hedge algorithm计算出来的。该算法是一个在线算法(online algorithm)。是Winnow算法的变体。
- Hedge algorithm是一种专家建议预測算法。它仅仅考虑了顺序信息而忽略了数值信息,因此,对于属性值是数值型数据的问题不适合用这个算法。
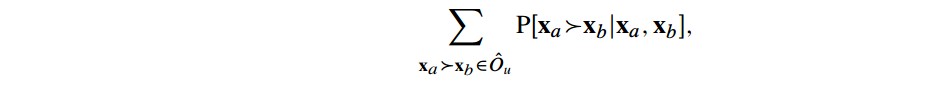

RankBoost (RB)
Freund提出了RankBoost。
- Input:
- feedback function ∅(xa,xb),假设∅(xa,xb) >0那么xb>xa。
- a set of ranking features fl(xi),包括了目标排名(target ording)的部分信息。
Output:
- final ranking H(xi),是一个计分函数(score function)
算法描写叙述
- 首先:计算初始分布D1(xa,xb)=max(∅(xa,xb),0)/Z1(Z1是规范化系数)
然后:迭代T次。反复选择权值αt以及弱化学习器ht(x)。更新公式例如以下:
h(x)是弱学习器(Weak learners),从特征值中捕捉了真实排名的若干信息。比方说h(xb)>h(xa)表示xb>xa. 一旦αt和ht被确定了,那么排名从大到下的顺序也就确定了,通过以下这个公式能够获取排名信息:
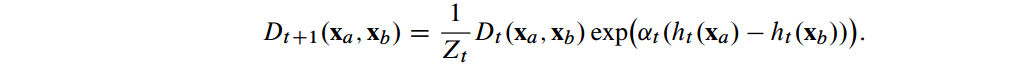
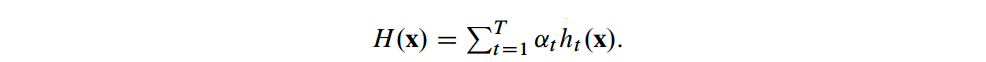
SVM-Based Methods: Order SVM (OSVM) and Herbrich’s Method (SVOR)
OSVM是用来判别给定的对象排名是否高于第j名。 SVOR是用来判别给定的两个object哪个排在前面。
- Order SVM:通过不同的阈值来构建多个SVM分类器,然后对于新的object,利用全部SVM的平均来给予一个固定的名次。SVM算法能够描写叙述为这样一个优化问题:
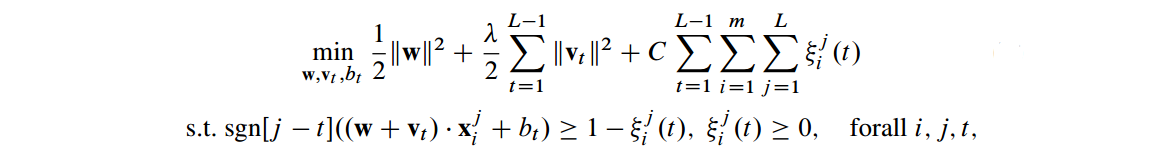
Preference Learning——Object Ranking的更多相关文章
- The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near
The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near ...
- learning to rank
Learning to Rank入门小结 + 漫谈 Learning to Rank入门小结 Table of Contents 1 前言 2 LTR流程 3 训练数据的获取4 特征抽取 3.1 人工 ...
- Deep Learning in a Nutshell: Core Concepts
Deep Learning in a Nutshell: Core Concepts This post is the first in a series I’ll be writing for Pa ...
- (转) Deep Learning in a Nutshell: Core Concepts
Deep Learning in a Nutshell: Core Concepts Share: Posted on November 3, 2015by Tim Dettmers 7 Comm ...
- 图像分类之特征学习ECCV-2010 Tutorial: Feature Learning for Image Classification
ECCV-2010 Tutorial: Feature Learning for Image Classification Organizers Kai Yu (NEC Laboratories Am ...
- Reinforcement Learning Solutions Ed2 Chapter 1 - 2 问题解答
RL到了第三章题目多的不可思议 前两章比较简单,就在博客随便写写了.之后的用pdf更新. 1.1: Self-play will result different move even from the ...
- Learning to Rank(转)
https://blog.csdn.net/kunlong0909/article/details/16805889 Table of Contents 1 前言 2 LTR流程 3 训练数据的获取4 ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
- YOLO object detection with OpenCV
Click here to download the source code to this post. In this tutorial, you’ll learn how to use the Y ...
随机推荐
- 测试计划驱动开发模式 TPDD:一种比 TDD 更友好的开发模式
相信大部分开发团队都在使用TDD,并且还有很多开发团队都 对外声明 在使用 TDD 开发模式. 之所以说是“对外声明”,是因为很多开发团队虽然号称使用的是 TDD 开发模式,实际开发过程中却无法满足 ...
- 2017 多校4 Security Check
2017 多校4 Security Check 题意: 有\(A_i\)和\(B_i\)两个长度为\(n\)的队列过安检,当\(|A_i-B_j|>K\)的时候, \(A_i和B_j\)是可以同 ...
- 【POJ 2976 Dropping tests】
Time Limit: 1000MSMemory Limit: 65536K Total Submissions: 13849Accepted: 4851 Description In a certa ...
- 如何写出高质量的JavaScript代码
优秀的Stoyan Stefanov在他的新书中(<Javascript Patterns>)介绍了很多编写高质量代码的技巧,比如避免使用全局变量,使用单一的var关键字,循环式预存长度等 ...
- DP———4.完全背包问题(容量为V的背包可装最大价值的问题)
Piggy-Bank Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total ...
- 手动删除Win7系统服务列表中残留服务的操作步骤
卸载tomcat的时候服务用cmd运行不能删除 需要用管理员才能删除 手动删除Win7系统服务列表中残留服务的操作步骤分享给大家,在使用深度Win7系统过程中,将一些程序删除后,有些在服务列表中还会残 ...
- 积木大赛(NOIP2013)(纯贪心+模拟)
好吧,这道题也是..醉了. 其实题目编程挺水的,但是贪心过程不好想. 原题传送门 这道题对于任何一个点a[i]如果a[i]<a[i-1]的话,那么假设a[i-1]的高度为X,a[i]的高度为y, ...
- Microsoft SilverLightt是一个跨浏览器的、跨平台的插件,为网络带来下一代基于.NETFramework的媒体体验和丰富的交互式应用程序。
Microsoft Silverlight是一个跨浏览器的.跨平台的插件,为网络带来下一代基于.NETFramework的媒体体验和丰富的交互式应用程序.Silverlight提供灵活的编程模型,并可 ...
- VIM使用系列: 复制并移动文本
1 5. 复制并移动文本 *copy-move* 2 3 *quote* 4 "{a-zA-Z0-9.%#:-"} 指定下次的删除.抽出和放置命令使用的寄存器 5 {a-zA-Z0 ...
- C语言高级应用---操作linux下V4L2摄像头应用程序【转】
转自:http://blog.csdn.net/morixinguan/article/details/51001713 版权声明:本文为博主原创文章,如有需要,请注明转载地址:http://blog ...