正则化--Lambda
模型开发者通过以下方式来调整正则化项的整体影响:用正则化项的值乘以名为 lambda(又称为正则化率)的标量。也就是说,模型开发者会执行以下运算:
执行 L2 正则化对模型具有以下影响:
- 使权重值接近于 0(但并非正好为 0)
- 使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布。
增加 lambda 值将增强正则化效果。 例如,lambda 值较高的权重直方图可能会如图 2 所示。
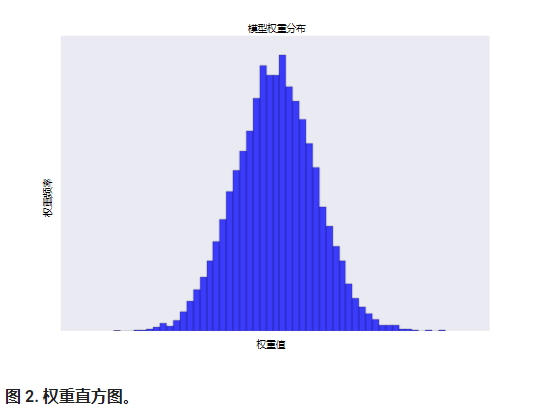
降低 lambda 的值往往会得出比较平缓的直方图,如图 3 所示。
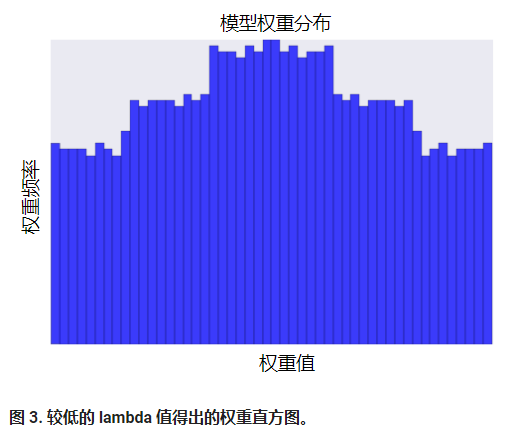
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡:
- 如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。
- 如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
- 将 lambda 设为 0 可彻底取消正则化。 在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
理想的 lambda 值生成的模型可以很好地泛化到以前未见过的新数据。 遗憾的是,理想的 lambda 值取决于数据,因此您需要手动或自动进行一些调整。
了解 L2 正则化和学习速率
学习速率和 lambda 之间存在密切关联。强 L2 正则化值往往会使特征权重更接近于 0。较低的学习速率(使用早停法)通常会产生相同的效果,因为与 0 的距离并不是很远。 因此,同时调整学习速率和 lambda 可能会产生令人混淆的效果。
早停法指的是在模块完全收敛之前就结束训练。在实际操作中,我们经常在以在线(连续)方式进行训练时采取一些隐式早停法。也就是说,一些新趋势的数据尚不足以收敛。
如上所述,更改正则化参数产生的效果可能会与更改学习速率或迭代次数产生的效果相混淆。一种有用的做法(在训练一批固定的数据时)是执行足够多次迭代,这样早停法便不会起作用。
引用
简化正则化 (Regularization for Simplicity):Lambda
正则化--Lambda的更多相关文章
- 论XGBOOST科学调参
XGBOOST的威力不用赘述,反正我是离不开它了. 具体XGBOOST的原理可以参见之前的文章<比XGBOOST更快--LightGBM介绍> 今天说下如何调参. bias-varianc ...
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 4—反向传播神经网络
课程笔记 Coursera—Andrew Ng机器学习—课程笔记 Lecture 9_Neural Networks learning 作业说明 Exercise 4,Week 5,实现反向传播 ba ...
- Andrew Ng机器学习总结(自用)
监督学习: 线性回归,逻辑回归,神经网络,支持向量机. 非监督学习: K-means,PCA,异常检测 应用: 推荐系统,大规模机器学习 机器学习系统优化: 偏差/方差,正则化,下一步要进行的工作:评 ...
- XGBoost和LightGBM的参数以及调参
一.XGBoost参数解释 XGBoost的参数一共分为三类: 通用参数:宏观函数控制. Booster参数:控制每一步的booster(tree/regression).booster参数一般可以调 ...
- lambda正则化参数的大小影响
当lambda的值很小时,其惩罚项值不大,还是会出现过拟合现象,当时lambda的值逐渐调大的时候,过拟合现象的程度越来越低,但是当labmda的值超过一个阈值时,就会出现欠拟合现象,因为其惩罚项太大 ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
- stanford coursera 机器学习编程作业 exercise 5(正则化线性回归及偏差和方差)
本文根据水库中蓄水标线(water level) 使用正则化的线性回归模型预 水流量(water flowing out of dam),然后 debug 学习算法 以及 讨论偏差和方差对 该线性回归 ...
- 正则化(Regularization)
正则化(Regularization)是机器学习中抑制过拟合问题的常用算法,常用的正则化方法是在损失函数(Cost Function)中添加一个系数的\(l1 - norm\)或\(l2 - norm ...
- 深度神经网络(DNN)的正则化
和普通的机器学习算法一样,DNN也会遇到过拟合的问题,需要考虑泛化,这里我们就对DNN的正则化方法做一个总结. 1. DNN的L1&L2正则化 想到正则化,我们首先想到的就是L1正则化和L2正 ...
随机推荐
- MySql实现分页查询的SQL,mysql实现分页查询的sql语句(转)
http://blog.csdn.net/sxdtzhaoxinguo/article/details/51481430 摘要:MySQL数据库实现分页查询的SQL语句写法! 一:分页需求: 客户端通 ...
- python描述符的应用
使用描述符为python实现类型检测 class Typed: def __get__(self, instance, owner): print(instance) print(owner) def ...
- Cookies/Session机制详解
# 转载自:https://blog.csdn.net/fangaoxin/article/details/6952954/ 会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话 ...
- 关于python浮点数的精度问题。
若想严格按照四舍五入进行,可使用Decimal,代码如下: from decimal import Decimal, ROUND_HALF_UP def round(x, n): return Dec ...
- sersync+rsync作实时同事
http://liubao0312.blog.51cto.com/2213529/1677586 配置搞定,参照上面的文章,用时搞一搞就OK. 注意IPTABLES的配置及环境变量 最简陋配置: rs ...
- 异步 JavaScript 之理解 macrotask 和 microtask(转)
这个知识点... https://blog.keifergu.me/2017/03/23/difference-between-javascript-macrotask-and-microtask/? ...
- FTP-Filezilla首次配置
最新新弄了个服务器,先吐槽下,之前买镜像都是免费的,昨天试了,竟然收费.... 好吧,用户多了也正常. 代码发布之前都是很暴力的直接远程桌面然后粘贴,有个合作伙伴突然需要FTP,说之前用的就是,我就做 ...
- 先刷一波简单的web前端面试题
1简述一下src与href的区别href 是指向网络资源所在位置,建立和当前元素(锚点)或当前文档(链接)之间的链接,用于超链接.src是指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置 ...
- Educational Codeforces Round 1D 【DFS求联通块】
http://blog.csdn.net/snowy_smile/article/details/49924965 D. Igor In the Museum time limit per test ...
- Tomcat服务器与HTTP协议
Tomcat服务器与HTTP协议 一. Tomcat服务器 1.tomcat服务器 1.web :网页,它代表的是网络上的资源.(java技术开发动态的web资源,即动态web页面,在Java中,动 ...