JDK学习---深入理解java中的String
本文参考资料:
1、《深入理解jvm虚拟机》
2、《大话数据结构》、《大话设计模式》
3、http://www.cnblogs.com/ITtangtang/p/3976820.html#3441029
4、http://www.cnblogs.com/xiaoxi/p/6036701.html
5、https://www.zhihu.com/question/20618891
6、http://blog.csdn.net/zhangjg_blog/article/details/18319521
今天无锡下着小雨,冷飕飕的,不适合出去玩。此刻,我喝着咖啡,心想着也没事,那就索性整理一下基础知识,方便以后自己的理解与记忆,毕竟年纪也不小了,记忆力与精力都大不如前了,不服老不行呀。
本篇我先挑了String类型进行分析,一开始是从虚拟机、源码、案例的角度去分析和整理文档的。后来当我读完HashMap的层源码的时候,我发现HashMap的底层源码居然是一个链表,而且还是单向链表,此刻再回头看了看String,好像也涉及到了数据结构的线性表顺序存储结构。思虑再三,还是把数据结构的相关知识也添加了进来,因此才有了第四节的《数据结构》。
一、认识JVM基本知识
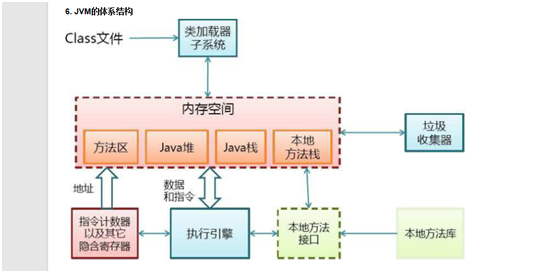
这是一张JVM基本结构图,本文主要是解读String类型,涉及虚拟机知识有限。因此,将主要针对方法区、java堆、java栈进行分析
JVM栈
JVM栈是线程私有的,每个线程创建的同时都会创建JVM栈,JVM栈中存放的为当前线程中局部基本类型的变量(java中定义的八种基本类型:boolean、char、byte、short、int、long、float、double)、部分的返回结果以及Stack Frame,非基本类型的对象在JVM栈上仅存放一个指向堆上的地址。
堆内存用于存放由new创建的对象和数组
方法区域(Method Area)
(1)在Sun JDK中这块区域对应的为PermanetGeneration,又称为持久代。
(2)方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、 isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
二、运行时常量池(Runtime Constant Pool)
存放的为类中的固定的常量信息、方法和Field的引用信息等,其空间从方法区域中分配。
Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、 anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量数据(int, short, long, byte, float, double, boolean, char)和对象句柄(引用)。
虚拟机必须为每个被装载的类型维护一个常量池。常量池就是该类型所用到常量的一个有序集合,包括直接常量(string,integer和 floating point常量)和对其他类型,字段和方法的符号引用。
三、字符串常量池
我们知道字符串的分配和其他对象分配一样,是需要消耗高昂的时间和空间的,而且字符串我们使用的非常多。JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一些优化:使用字符串常量池。每当我们创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中。由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串(这点对后面会重点讲解String不可变)。
对于String常量,它的值是在常量池中的。而JVM中的常量池在内存当中是以表的形式存在的, 对于String类型,有一张固定长度的CONSTANT_String_info表用来存储文字字符串值,注意:该表只存储文字字符串值,不存储符号引用。说到这里,对常量池中的字符串值的存储位置应该有一个比较明了的理解了。在程序执行的时候,常量池会储存在Method Area,而不是堆中。常量池中保存着很多String对象; 并且可以被共享使用,因此它提高了效率
四、数据结构
为什么要介绍数据结构的相关知识,因为在我把String底层实现读完之后,其实String的数据存储是放在一个char[]类型的数组中的,虽然这个数组被定义为private final类型,每次添加元素和替换等其他操作都是直接生成新的字符数组进行操作,但是这完全不影响我们来介绍数据结构知识,尤其是线性表的顺序存储结构相关知识。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。 【DP】
按照视点的不同,我们把数据结构分为逻辑结构与物理结构。
逻辑结构:是指数据对象中数据元素之间的相互关系。它分为集合结构、线性结构、树形结构和图形结构。
物理结构: 是指数据的逻辑结构在计算机中的存储形式。它分为顺序存储结构和链式存储结构
下面来分别认识一下逻辑结构的各个结构图:
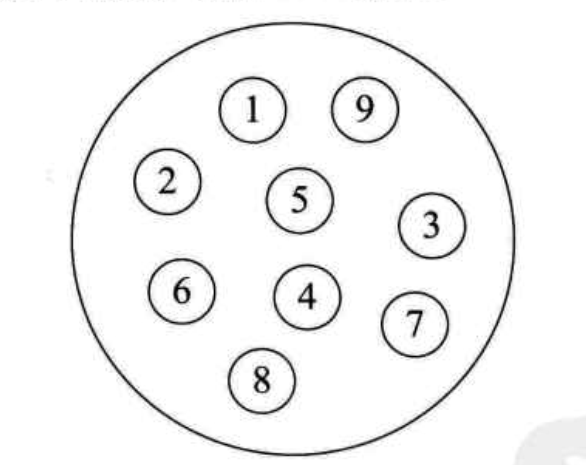
集合结构:
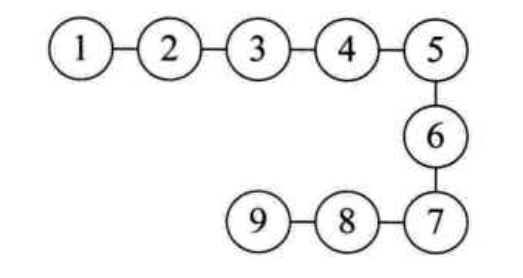
线性结构:
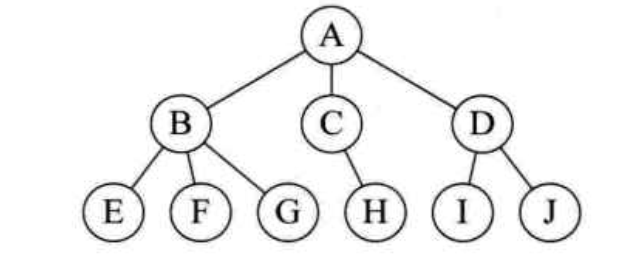
树形结构
图形结构
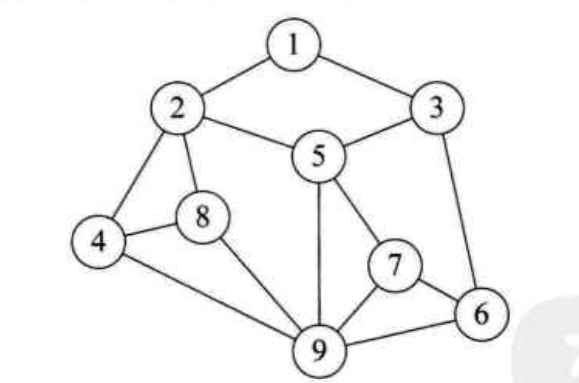
接下来介绍一下物理结构我两种存储结构:顺序存储结构、链式存储结构。
顺序存储结构

链式存储结构
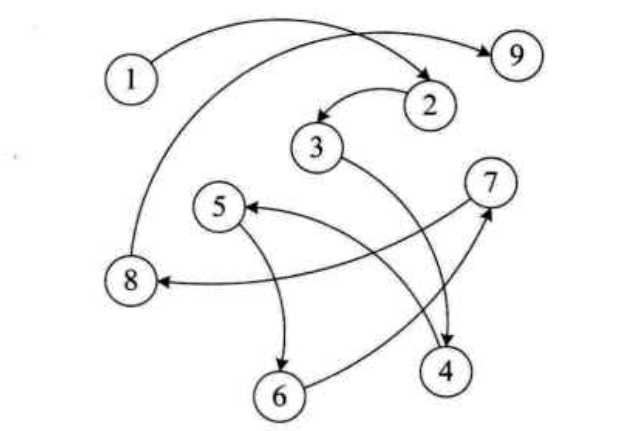
我以前出去找工作面试的时候,经常会有人问我ArrayList和LinkedList的区别以及插入和查找的性能,其实这就是想问数据结构的顺序存储结构和链式存储结构知识。后来我当了面试官,遇到有两三年工作经验的小伙伴,我喜欢问HashMap的key为什么不能重复、HashSet为什么元素不能重复、以及ArrayList和LinkedList区别等等。其实,即使不知道这些知识,也不会严重影响正常的编码,但是却能反应出一个程序员是否有爱动脑的习惯,是否有好奇心或者主动性去看点东西习惯,这个很重要。
有了以上的数据结构做铺垫,那么我们接下来会重点介绍一下线性表的顺序存储结构。因为String类型底层实现是字符数组,这是典型的线性表的顺序存储结构。
线性表:零个或多个数据元素的有序集合 【DP】
线性表强调的是有序,那么接下来看看常见的线性表:
星座列表:

班级点名册:
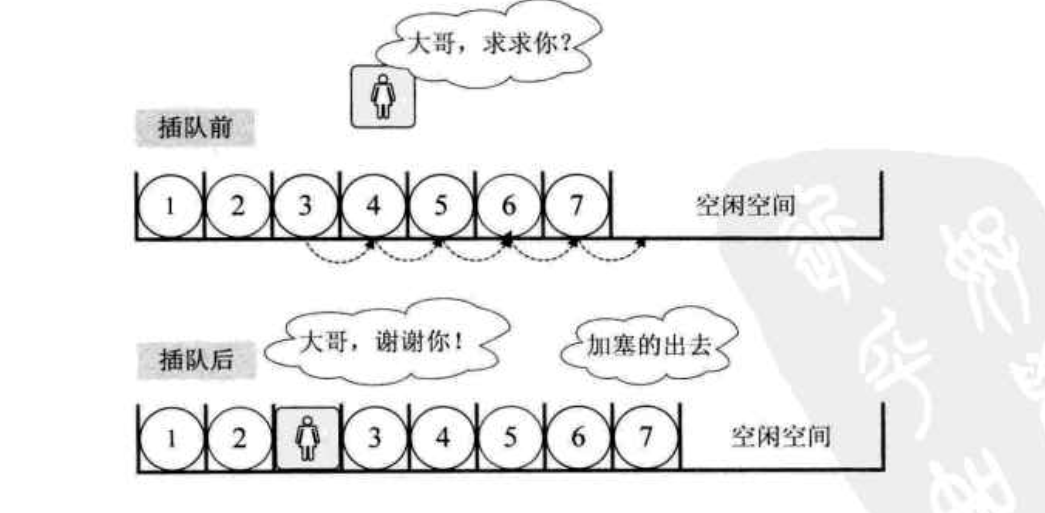
线性表的顺序存储结构:指的是用一段地址连续的去存储单元依次存储线性表的数据元素。【DP】
举个例子,本来我们买春运火车票,大家都好好的排队,这时候来了一个美女,对着队伍中的第三位的你说:“大哥,求你帮帮忙,我家母亲有病,我着急回去一趟,队伍这么长,我能否插个队排在你的前面?” ,你心一软,就同意了。这时,你必须往后退一步,否则她没法插到队伍里面来。这个影响很大,后面的人像蠕虫一样,全部都得往后退一步。其实这个例子很好的说明了线性表的顺序存储结构。
线性表顺序存储结构总结:
优点:
1、无须为表中元素之间的逻辑关系而增加额外的存储空间(这一点你学完链式存储结构就明白了,因为链表每个元素除了值域,还要保存一个指针域)。
2、其次是可以快速的读取表中任意一个位置的元素(因为元素相邻存储在同一段内存中,查找速度快)。
缺点:1、首先是插入和删除需要移动大量的数据,上面插队的例子就是很好的说明;
2、当线性表长度变化较大时,难以确定存储空间的容量(典型的就是初始化数组时要有长度)
3、造成存储空间的“碎片”
注意:如果你觉得用String来说明线性表的顺序存储结构有点勉强的话,那你可以拿ArrayList的底层实现来说服自己,原理都是一样的。
五、 String各种奇葩案例分析:
例子1:
/**
* 采用字面值的方式赋值
*/
public void test1(){
String str1="aaa";
String str2="aaa";
System.out.println("===========test1============");
System.out.println(str1==str2);//true 可以看出str1跟str2是指向同一个对象
}
执行上述代码,结果为:true。
分析:当执行String str1="aaa"时,JVM首先会去字符串池中查找是否存在"aaa"这个对象,如果不存在,则在字符串池中创建"aaa"这个对象,然后将池中"aaa"这个对象的引用地址返回给字符串常量str1,这样str1会指向池中"aaa"这个字符串对象;如果存在,则不创建任何对象,直接将池中"aaa"这个对象的地址返回,赋给字符串常量。当创建字符串对象str2时,字符串池中已经存在"aaa"这个对象,直接把对象"aaa"的引用地址返回给str2,这样str2指向了池中"aaa"这个对象,也就是说str1和str2指向了同一个对象,因此语句System.out.println(str1 == str2)输出:true。
例子2:
/**
* 采用new关键字新建一个字符串对象
*/
public void test2(){
String str3=new String("aaa");
String str4=new String("aaa");
System.out.println("===========test2============");
System.out.println(str3==str4);//false 可以看出用new的方式是生成不同的对象
}
执行上述代码,结果为:false。
分析: 采用new关键字新建一个字符串对象时,JVM首先在字符串池中查找有没有"aaa"这个字符串对象,如果有,则不在池中再去创建"aaa"这个对象了,直接在堆中创建一个"aaa"字符串对象,然后将堆中的这个"aaa"对象的地址返回赋给引用str3,这样,str3就指向了堆中创建的这个"aaa"字符串对象;如果没有,则首先在字符串池中创建一个"aaa"字符串对象,然后再在堆中创建一个"aaa"字符串对象,然后将堆中这个"aaa"字符串对象的地址返回赋给str3引用,这样,str3指向了堆中创建的这个"aaa"字符串对象。当执行String str4=new String("aaa")时, 因为采用new关键字创建对象时,每次new出来的都是一个新的对象,也即是说引用str3和str4指向的是两个不同的对象,因此语句System.out.println(str3 == str4)输出:false。
例子3:
/**
* 编译期确定
*/
public void test3(){
String s0="helloworld";
String s1="helloworld";
String s2="hello"+"world";
System.out.println("===========test3============");
System.out.println(s0==s1); //true 可以看出s0跟s1是指向同一个对象
System.out.println(s0==s2); //true 可以看出s0跟s2是指向同一个对象
}
执行上述代码,结果为:true、true。
分析:因为例子中的s0和s1中的"helloworld”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而"hello”和"world”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中"helloworld”的一个引用。所以我们得出s0==s1==s2。
例子4:
/**
* 编译期无法确定
*/
public void test4(){
String s0="helloworld";
String s1=new String("helloworld");
String s2="hello" + new String("world");
System.out.println("===========test4============");
System.out.println( s0==s1 ); //false
System.out.println( s0==s2 ); //false
System.out.println( s1==s2 ); //false
}
执行上述代码,结果为:false、false、false。
分析:用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
s0还是常量池中"helloworld”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象"helloworld”的引用,s2因为有后半部分new String(”world”)所以也无法在编译期确定,所以也是一个新创建对象"helloworld”的引用。
例子5:
/**
* 继续-编译期无法确定
*/
public void test5(){
String str1="abc";
String str2="def";
String str3=str1+str2;
System.out.println("===========test5============");
System.out.println(str3=="abcdef"); //false
}
执行上述代码,结果为:false。
分析:因为str3指向堆中的"abcdef"对象,而"abcdef"是字符串池中的对象,所以结果为false。JVM对String str="abc"对象放在常量池中是在编译时做的,而String str3=str1+str2是在运行时刻才能知道的。new对象也是在运行时才做的。而这段代码总共创建了5个对象,字符串池中两个、堆中三个。+运算符会在堆中建立来两个String对象,这两个对象的值分别是"abc"和"def",也就是说从字符串池中复制这两个值,然后在堆中创建两个对象,然后再建立对象str3,然后将"abcdef"的堆地址赋给str3。
步骤:
1)栈中开辟一块中间存放引用str1,str1指向池中String常量"abc"。
2)栈中开辟一块中间存放引用str2,str2指向池中String常量"def"。
3)栈中开辟一块中间存放引用str3。
4)str1 + str2通过StringBuilder的最后一步toString()方法还原一个新的String对象"abcdef",因此堆中开辟一块空间存放此对象。
5)引用str3指向堆中(str1 + str2)所还原的新String对象。
6)str3指向的对象在堆中,而常量"abcdef"在池中,输出为false。
例子6:
/**
* 编译期优化
*/
public void test6(){
String s0 = "a1";
String s1 = "a" + 1;
System.out.println("===========test6============");
System.out.println((s0 == s1)); //result = true
String s2 = "atrue";
String s3= "a" + "true";
System.out.println((s2 == s3)); //result = true
String s4 = "a3.4";
String s5 = "a" + 3.4;
System.out.println((s4 == s5)); //result = true
}
执行上述代码,结果为:true、true、true。
分析:在程序编译期,JVM就将常量字符串的"+"连接优化为连接后的值,拿"a" + 1来说,经编译器优化后在class中就已经是a1。在编译期其字符串常量的值就确定下来,故上面程序最终的结果都为true。
例子7:
/**
* 编译期无法确定
*/
public void test7(){
String s0 = "ab";
String s1 = "b";
String s2 = "a" + s1;
System.out.println("===========test7============");
System.out.println((s0 == s2)); //result = false
}
执行上述代码,结果为:false。
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + s1无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s2。所以上面程序的结果也就为false。
例子8:
/**
* 比较字符串常量的“+”和字符串引用的“+”的区别
*/
public void test8(){
String test="javalanguagespecification";
String str="java";
String str1="language";
String str2="specification";
System.out.println("===========test8============");
System.out.println(test == "java" + "language" + "specification");
System.out.println(test == str + str1 + str2);
}
执行上述代码,结果为:true、false。
分析:为什么出现上面的结果呢?这是因为,字符串字面量拼接操作是在Java编译器编译期间就执行了,也就是说编译器编译时,直接把"java"、"language"和"specification"这三个字面量进行"+"操作得到一个"javalanguagespecification" 常量,并且直接将这个常量放入字符串池中,这样做实际上是一种优化,将3个字面量合成一个,避免了创建多余的字符串对象。而字符串引用的"+"运算是在Java运行期间执行的,即str + str2 + str3在程序执行期间才会进行计算,它会在堆内存中重新创建一个拼接后的字符串对象。总结来说就是:字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算实在运行时进行的,新创建的字符串存放在堆中。
对于直接相加字符串,效率很高,因为在编译器便确定了它的值,也就是说形如"I"+"love"+"java"; 的字符串相加,在编译期间便被优化成了"Ilovejava"。对于间接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
例子9:
/**
* 编译期确定
*/
public void test9(){
String s0 = "ab";
final String s1 = "b";
String s2 = "a" + s1;
System.out.println("===========test9============");
System.out.println((s0 == s2)); //result = true
}
执行上述代码,结果为:true。
分析:和例子7中唯一不同的是s1字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + s1和"a" + "b"效果是一样的。故上面程序的结果为true。
例子10:
/**
* 编译期无法确定
*/
public void test10(){
String s0 = "ab";
final String s1 = getS1();
String s2 = "a" + s1;
System.out.println("===========test10============");
System.out.println((s0 == s2)); //result = false } private static String getS1() {
return "b";
}
执行上述代码,结果为:false。
分析:这里面虽然将s1用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定,因此s0和s2指向的不是同一个对象,故上面程序的结果为false。
六、理解 String 类型值的不可变
1、String的不可变实现如下图,给一个已有字符串"abcd"第二次赋值成"abcedl",不是在原内存地址上修改数据,而是重新指向一个新对象,新地址。
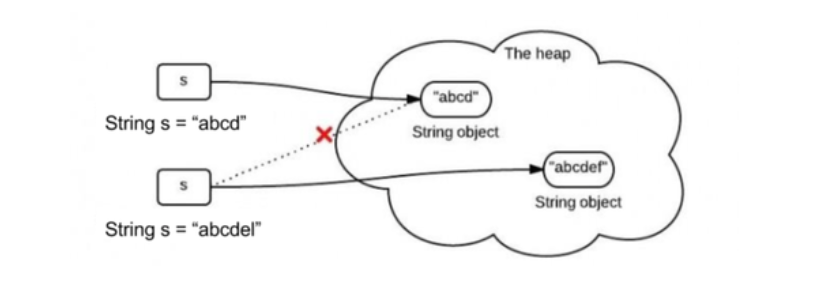
2. String为什么不可变?
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[]; /** Cache the hash code for the string */
private int hash; // Default to 0 /** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
首先类String是final修饰的,这就说明String不可继续;而String储存在字符数组value中,value也是final,这就说明value创建以后地址(注意,是地址)也是不可变的;还有一个也比较重要,那就是private修饰的value,并且value没有提供set、get方法,这就保证外部无法直接去操作value数组,这一点也非常重要。
除此以外,String内部的各个逻辑方法都没有对value数组进行直接的修改,而是拷贝到新的字符数组中,这一点是保证String不可变的最重要的因素。因为value只是一个指向堆内存的指针,value不可变,但是value所指向的堆内存中的对象的内容是可以变的,如果不是String内部一系列底层实现,仅仅依靠private和final是根本没有办法保证String不可变的。
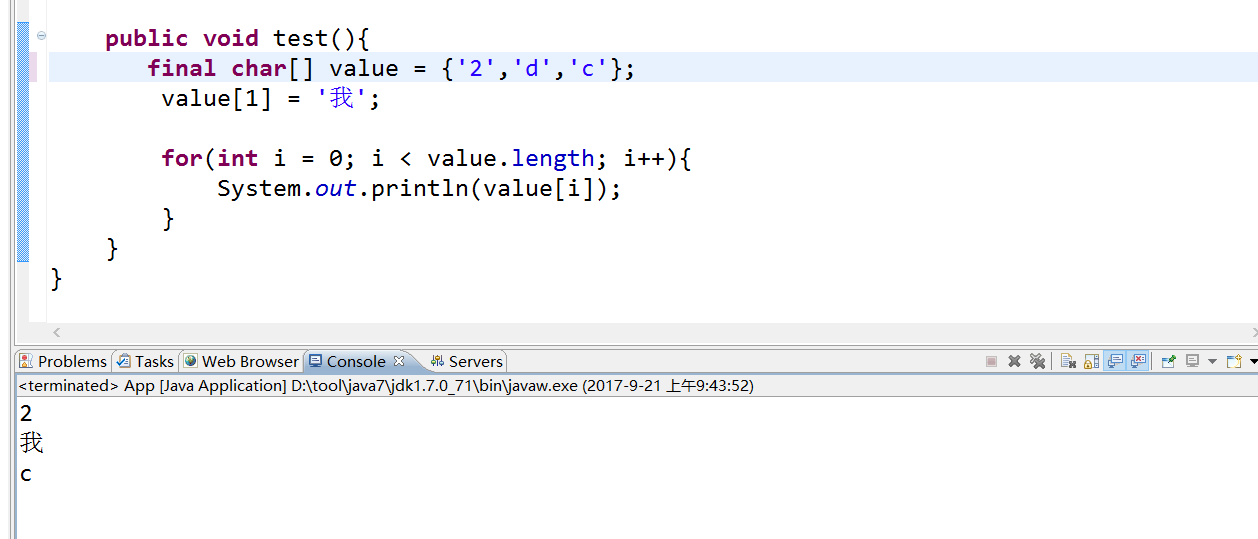
下面的案例可以说明一切:
public void test(){
final char[] value = {'2','d','c'};
value[1] = '我';
for(int i = 0; i < value.length; i++){
System.out.println(value[i]);
}
}
运行结果:
七、底层源码分析
length()方法:其实就是直接返回value字符数组的长度而已
public int length() {
return value.length;
}
trim()方法:看看逻辑吧,其实就是对字符数组首、尾进行无限循环判断是否为空格字符,直到不是空格字符才跳出循环
public String trim() {
int len = value.length;
int st = 0;
char[] val = value; /* avoid getfield opcode */
while ((st < len) && (val[st] <= ' ')) {
st++;
}
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}
concat()方法:就是拷贝到新的char[]数组进行存储,而value才是String的存储元素,因此直接new String进行赋值。(因为value是 final的,不可以直接将value指向buf[]所指向的对象;而value长度也不可以变化,因此只能重新new String对value进行重新初始化)
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
public static char[] copyOf(char[] original, int newLength) {
char[] copy = new char[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
void getChars(char dst[], int dstBegin) {
System.arraycopy(value, 0, dst, dstBegin, value.length);
}
indexOf(String str)方法:看看代码,还用解释吗?
public int indexOf(String str) {
return indexOf(str, 0);
}
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
} char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount); for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
} /* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++); if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
substring(int ,int)方法:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
看了这么多的String底层代码实现,有没有看到那个方法是对value数组进行重新初始化或者修改value数组元素的?没有,都是拷贝到新的char[]数组 或者 直接new 新的String对象吧,这样印证了上一张《理解 String 类型值的不可变》分析结论
八、对String各个方法进行模拟
package foo; import java.util.Arrays;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class StringDemo
{
public static void main(String[] args)
{
StringStr s = new StringStr(); String str1 = "hello,大家好,我是C";
String str2 = "nice to see you!";
String str21 = "nice to see you!"; //模拟concat方法
String str3 = s.concat(str1, str2);
System.out.println("模拟concat方法 : " + str3); //模拟concat方法
String str4 = s.concat(s.trim(str1), str2);
System.out.println("模拟trim方法 : " + str4); //模拟substring
String str5 = s.substring(0, 10, str1);
System.out.println("模拟trim方法 : " + str5); //模拟equals
boolean b1 = s.equals(str1, str2);
boolean b2 = s.equals(str2,str21);
System.out.println("模拟equals方法 : b1:" + b1 + " b2:" + b2); //模拟replace
String str6 = s.replace("我是C", " java", str1);
System.out.println("模拟replace方法 : " + str6); //模拟length
int length = s.length(str6);
System.out.println("模拟length方法 : " + length);
}
} class StringStr
{
public String concat(String str1, String str2)
{
char[] value1 = this.getChars(str1);
int len = value1.length; char[] value2 = this.getChars(str2);
int otherLen = value2.length; int newLength = len + otherLen;
char[] buf = new char[newLength];
System.arraycopy(value1, 0, buf, 0, len);
System.arraycopy(value2, 0, buf, len, otherLen); return new String(buf);
} public String trim(String str)
{
char[] value = this.getChars(str);
int len = value.length;
int st = 0;
char[] val = value; while ((st < len) && (val[st] <= ' ')) {
st++;
}
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
return ((st > 0) || (len < value.length)) ? this.substring(st, len, str) : str;
} public String substring(int beginIndex, int endIndex, String str)
{
char[] value = this.getChars(str);
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (((beginIndex == 0) && (endIndex == value.length)) ? str: new String(value, beginIndex, subLen));
} public String replace(CharSequence target, CharSequence replacement, CharSequence str) {
return Pattern.compile(target.toString(), Pattern.LITERAL).matcher(
str).replaceAll(Matcher.quoteReplacement(replacement.toString()));
} public boolean equals(Object object, Object anObject)
{
if (object == anObject) {
return true;
}
if (anObject instanceof String && object instanceof String)
{
String anotherString = (String) anObject;
int len1 = this.getChars(anotherString).length; String objectString = (String) objectString;
int len2 = this.getChars(objectString).length; if (len1 == len2) {
char v1[] = this.getChars(anotherString);
char v2[] = this.getChars(objectString);
int i = 0;
while (len1-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
} public int length(String str) {
return this.getChars(str).length;
} public char[] getChars(String str){
return str.toCharArray();
} }
运行看看吧,看看这些自定义的方法是不是和String的这些方法功能一致?
JDK学习---深入理解java中的String的更多相关文章
- JDK学习---深入理解java中的HashMap、HashSet底层实现
本文参考资料: 1.<大话数据结构> 2.http://www.cnblogs.com/dassmeta/p/5338955.html 3.http://www.cnblogs.com/d ...
- JDK学习---深入理解java中的LinkedList
本文参考资料: 1.<大话数据结构> 2.http://blog.csdn.net/jzhf2012/article/details/8540543 3.http://blog.csdn. ...
- 深入理解Java中的String
一.String类 想要了解一个类,最好的办法就是看这个类的实现源代码,来看一下String类的源码: public final class String implements java.io.Ser ...
- 【转】深入理解Java中的String
原文链接:http://www.cnblogs.com/xiaoxi/p/6036701.html 一.String类 想要了解一个类,最好的办法就是看这个类的实现源代码,来看一下String类的源码 ...
- 深刻理解Java中的String、StringBuffer和StringBuilder的差别
声明:本博客为原创博客,未经同意.不得转载!小伙伴们假设是在别的地方看到的话,建议还是来csdn上看吧(链接为http://blog.csdn.net/bettarwang/article/detai ...
- 全面理解Java中的String数据类型
1. 首先String不属于8种基本数据类型,String是一个对象. 因为对象的默认值是null,所以String的默认值也是null:但它又是一种特殊的对象,有其它对象没有的一些特性. 2. ne ...
- 深刻理解Java中final的作用(一):从final的作用剖析String被设计成不可变类的深层原因
声明:本博客为原创博客,未经同意,不得转载!小伙伴们假设是在别的地方看到的话,建议还是来csdn上看吧(原文链接为http://blog.csdn.net/bettarwang/article/det ...
- Java内存管理-探索Java中字符串String(十二)
做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 一.初识String类 首先JDK API的介绍: public final class String extends O ...
- map和flatmap的区别+理解、学习与使用 Java 中的 Optional
转自:map和flatmap的区别 对于stream, 两者的输入都是stream的每一个元素,map的输出对应一个元素,必然是一个元素(null也是要返回),flatmap是0或者多个元素(为n ...
随机推荐
- [LeetCode]11. Container With Most Water 盛最多水的容器
Given n non-negative integers a1, a2, ..., an , where each represents a point at coordinate (i, ai). ...
- 特殊的流程控制语句break continue exit
break语句可以结束当前的for.foreach.while.do-while.或者switch的执行. for($i=1; $i<10; $i++) { if($i == 5) { echo ...
- SQL获得连续的记录的统计
SELECT TYEAR, MIN(TDATE) AS STARTDATE, MAX(TDATE), COUNT(TYEAR) AS ENDNUM --TYEAR年,STARTDATE连续记录的开始时 ...
- 【Unity3D学习笔记】解决放大后场景消失不显示问题
不知道为啥,我的Unity场景放大到一定大小后,就会消失... 解决方案: 选中一个GameObject,然后按F键. F键作用是聚焦,视图将移动,以选中对象为中心.
- Eclipse导入web项目后,run列表中没有run on server?
Eclipse导入web项目,没有run列表中run on server? 首先确保正确安装Tomcat和JDK .找到对于web项目的文件夹,打开文件夹下.project文件 <?xml ve ...
- Hadoop federation配置
Hadoop federation配置 1.介绍 hadoop federation也称为联邦,主要是对namenode进行扩容.HA模式下只是实现了hadoop namenode的高可用,但是随着文 ...
- CODESOFT条码设计软件如何隐藏数据源方法
作为强大的条码标签设计软件,用户在用CODESOFT设计条码标签时,有时需要根据实际情况,将条码数据源隐藏,也就是使设计与打印出来的条形码下不带有数据.那么这要怎么在CODESOFT中实现呢?下面,小 ...
- STM32-开发环境搭建-STM32CubeMX-安装及配置
STM32CubeMX系列教程之1.流水灯 刚刚接触到STM32CubeMX软件,感觉挺有意思,动动鼠标使STM32开发变得简单,特写文与大家分享.但具体性能如何还需测试. 硬件开发中的流水灯相当于软 ...
- 【转载】#335 - Accessing a Derived Class Using a Base Class Variable
You can use a variable whose type is a base class to reference instances of a derived class. However ...
- java常用输出技巧,debug
package control; import javax.swing.JFrame; public class DebugTest { public static void main(String[ ...