转:InnoDB Crash Recovery 流程源码实现分析
此文章转载给登博的文章,给大家分享
InnoDB Crash Recovery 流程源码实现分析
Crash Recovery问题
本文主要分析了InnoDB整个crash recovery的源码处理流程,总入口函数是innobase_start_or_create_for_mysql()。InnoDB的crash recovery流程非常长,也十分复杂,以下我总结了几个问题,如果大家能够回答出这些问题,那么就不用看下面的内容了。
crash recovery的起点,checkpoint_lsn存于何处?
redo过程是batch redo,还是single redo?如果是batch redo,那么是如何实现的?
redo过程中是否需要读取所有数据文件?
redo过程,日志解析,日志回放操作对应的分别是什么函数?
redo过程中,何时使用doublewrite检查错误页面?
InnoDB的系统表何时创建,有哪些系统表,分别是什么表结构?
undo操作的起点是什么?
一个rollback segment能够支持的并发事务数是多少?
多rollback segments是如何实现的?
如何找到每个rollback segment中的undo信息?
事务与undo是如何关联起来的?
同一事务的操作,是单一undo链表?还是需要区分insert与update操作?
同一事务的undo,是如何链接起来的?
最后,在crash recovery流程的哪些地方作调整,即可实现Percona XtraBackup类似的全量备份,增量备份的功能?
1 Crash Recovery流程
代码调用流程:
ha_innodb.cc::innobase_init
// InnoDBCrash Recovery主函数入口,在此函数中完成所有动作,并open数据库
srv0start.c::innobase_start_or_create_for_mysql();
// 打开所有的InnoDB数据文件,并且获取所有数据文件中最大最小
//的flush_lsn,因为每个数据文件最后一次flush的时间可能不一致
open_or_create_data_files();
// 读取数据文件第一页,FIL_PAGE_FILE_FLUSH_LSN宏定义指向的flush_lsn
// 系统保证数据文件中page_lsn小于此flush_lsn的脏页都被写到磁盘
fil_read_flushed_lsn_and_arch_log_no();
open_or_create_log_files();
// 打开系统表空间对应的文件+日志文件,防止出现文件句柄不足导致
// 系统文件无法打开的情况。
fil_open_log_and_system_tablespace_files();
// 清空buffer pool,所有的page都需要重新读取
// 此时buffer pool中应该只有一个非脏page
buf_pool_invalidate();
// InnoDB恢复Redo入口函数
log0recv.c::recv_recovery_from_checkpoint_start_func();
// 遍历所有的log group,查找其中最大的checkpoint lsn
// checkpoint信息保存在每个日志组日志文件第一页之中,有两处
// LOG_CHECKPOINT_1(第一个LOG_BLOCK_SIZE处)处;LOG_CHECKPOINT_2(3)处
recv_find_max_checkpoint();
//
// 流程如下:
// 1. contiguous_lsn开始,遍历当前日志组。此lsn即为checkpoint lsn。
// group_scanned_lsn为当前日志组能够提供的最大lsn。
// 2. 根据给定的checkpoint lsn,计算在log文件中的偏移位置
// 3. 每次读取RECV_SCAN_SIZE (宏定义:4) 个日志pages,存入log buf。
recv_group_scan_log_recs(group, contiguous_lsn, group_scanned_lsn);
log_group_read_log_seg();
log_group_calc_lsn_offset();
// avail_mem为crash recovery期间,hash表能够使用的buffer pool
// 上限。若buffer pool的大于10MB,则需要预留512个free pages。
// 这些free pages buffer用于读取页面到内存中,进行恢复之用。
// hash表的bucket个数为 buffer pool的大小 / 512.
// 根据日志组,进行redo的流程如下:
// 1. 循环遍历buf中的每一个log block (buf 为4 pages,block = 512)
// 2. 对于每一个block,读取block头,获取block中已写日志长度
// 疑问:block头信息何时写入?block内容写完之后 or 之前?
// 3. 若当前block中最大lsn > checkpoint lsn,就需要进行崩溃恢复
// 4. 递归方式,遍历base目录下的所有目录与文件,并打开其中的
// ibd文件(数据文件),保存在fil_space_struct的chain链表之中
// 5. 读取系统表空间的第五个页面(TRX_SYS_PAGE_NO),获取其中的
// doublewrite信息。若使用doublewrite,则视情况恢复损坏页面
// 关于doublewrite相关的读取,恢复操作,将在后面详细讨论
// 6. 将log block中的log首先保存在recv_sys_struct的buf中,等
// 收集一次读取的4个pages中的所以日志之后,统一进行解析
// 7. 日志解析的操作,在函数recv_parse_log_recs中完成
// 8. 完成日志解析之后,所有的解析日志并非立即应用,而是存储
// 于hash表之中,hash表大小的上限就是前面提到的avail_mem
// 也就是buf pool大小 – 512个pages,hash表大小超过此限制,
// 则需要调用recv_apply_hashed_log_recs函数,redo hash表中的
// 日志,此函数的详细流程在下方给出。
recv_scan_log_recs(avail_mem, store_to_hash, buf, contigous_lsn);
recv_init_crash_recovery();
fil_load_single_table_tablespaces(); // 流程4
fil_load_single_table_tablespace();
fil_node_create();
trx_sys_doublewrite_init_or_restore_pages();// 流程5
recv_sys_add_to_parsing_buf(); // 流程6
start_offset = LOG_BLOCK_HDR_SIZE;
end_offset=OS_FILE_LOG_BLOCK_SIZE–LOG_BLOCK_TRL_SIZE;
// 将log block中的redo日志内容copy到recv_sys->buf中,
// 需要跳过log block的头部(12 bytes)与尾部(4 bytes)
memcpy(…,log_block+start_offset, end_offset-start_offset);
// 将recv_sys_struct->buf中保存的日志进行解析。解析完成
// 的日志存储到hash表之中,流程如下:
// 7.1 首先划分日志大类型:单一日志(文件操作?) or 多日志
// 7.2 解析一条日志,返回的内容包括:日志长度;日志类型;
// 日志操作对应的表空间ID;Page_no;以及日志主体body
// 关于日志类型,可参考mtr0mtr.h文件中的定义
// recv_parse_or_apply_log_rec_body函数遍历所有日志
// 类型,解析并应用(crash recovery时先不应用,解析返回)
// 7.3 若日志操作对应的是文件操作,那么crash recover不处理
// 但是XtraBackup需要处理文件操作日志,重用这些日志
// 7.4 日志操作对应的不是文件操作,则将解析的日志存入
// hash表,hash值根据(space, page_no)组合计算而来,
// 相同的page操作日志,在hash表中保存在一起,同时
// 按照日志操作的顺序,链接在双向链表之中。
// (可以尽量合并同一个page的操作,回放日志更加高效?)
// 7.5 上面提到的流程,同样适用于多日志的处理,唯一的不同
// 之处在于,多日志不包含文件操作,文件操作一定是单条
recv_parse_log_recs(); // 流程7
recv_parse_log_rec(type, space, page_no, body); // 流程7.2
mlog_parse_initial_log_record();
recv_parse_or_apply_log_rec_body();
recv_add_to_hash_table(); // 流程7.4
recv_get_fil_addr_struct();
// 若hash表空间占用量超过上限,那么则应用hash表中的
// 所有日志到对应的page上,过程中不允许使用Insert Buf
// 应用日志的流程如下:
// 8.1 遍历hash表中的每一个bucket,以及bucket中的每一项,
// 8.2 调用buf_page_peek函数,判断page是否已经在buffer,
// 若存在,则直接根据buffer pool中的页面进行日志重做,
// 重做(redo)按照日志生成的顺序进行,老日志先做。
// 首先,读取page的最新page_lsn,若大于日志lsn,跳过,
// 否则,调用recv_parse_or_apply_log_rec_body函数进行
// redo。需要记录redo日志,并且修改page_lsn。
// 重做完一个页面,recv_sys->n_addrs计数– .
// 8.3 若page当前不在buffer pool中,则调用recv_read_in_area
// 函数进行批量读取page(这些page都是需要恢复的page)
// 批量读取的页面数上限RECV_READ_AHEAD_AREA = 128。
// 批量读取page之后,视情况flush前面redo产生的脏页。
// 8.4 当前log hash表中的日志redo全部完成之后,清空
// buffer pool中的所有页面,开始进行下一轮的redo操作
// 8.5 清空当前的log hash表,为下一轮redo准备。
recv_apply_hashed_log_recs(FALSE); // 流程8
// 取出Hash表第i个bucket中的第一个页面对应的日志组
HASH_GET_FIRST(recv_sys->addr_hash, i);
buf_page_peek();
buf_page_get();
recv_recover_page(); // 流程8.2
recv_parse_or_apply_log_rec_body();
recv_read_in_area(); // 流程8.3
buf_read_recv_pages();
buf_flush_free_margins();
// 取出Hash表第i个bucket中的下一个页面对应的日志组
HASH_GET_NEXT(addr_hash, recv_addr);
Buf_pool_invalidate(); // 流程8.4
Recv_sys_empty_hash(); // 流程8.5
// 回到recv_recovery_from_checkpoint_start_func函数,在redo完成之后,
// 若当前有多个日志组,则同步所有日志组到一致状态。
// recv_recovery_from_checkpoint_start_func函数至此结束。
recv_synchronize_groups();
// 初始化表数据字典,同时初始化系统表数据字典结构,主要包括:
// SYS_TABLES; SYS_COLUMNS; SYS_INDEXES; SYS_FIELDS;
dict_boot();
// 前面的recv_recovery_from_checkpoint_start_func函数完成了crash recovery
// 的redo部分操作,而下面的trx_sys_init_at_db_start函数则为了实现crash
// recovery阶段的undo部分操作(基于rollback segment回滚段的undo),包括:
// 未成功commit事务的收集整理,按类别划分,真正undo操作的前期准备。
// undo信息收集整理的流程如下:
// 1. 读取Transaction system header页面,系统表空间的第五个page
// 2. 初始化内存回滚段对象,主要内容包括:
// 2.1 读取每个回滚段对应的回滚段段头页(page_no)
// 2.2 读取每个回滚段对应的表空间序号(space_id)
// 2.3 根据2.1;2.2读取的信息,重构回滚段内存结构:
// 2.3.1 将回滚段链接到系统事务管理结构的链表中(trx_sys->rseg_list)
// 2.3.2 读取当前回滚段的段头页(trs_rsegf_get_new()),结构可见trx0rseg.h
// 2.3.3 分析回滚段段头页,取出其中的undo slot (每个回滚段段头页,
// 最多能够包含个TRX_RSEG_N_SLOTS undo slot,page_size / 16 = 1024)
// 每个slot占用 4 bytes,记录的则是当前undo对应的undo page_no
// 每个事务需要占用两个undo slot(insert & update)
// 2.3.4 根据undo slot中记录的page_no,读取对应的undo page信息:
// undo_type: UNDO_INSERT or UPDATE;
// undo_state: TRX_UNDO_ACTIVE or TRX_UNDO_PREPARE
// undo_offset: 当前undo最后一条undo日志在页面中的位置
// trx_id: 读取最后一条undo日志头,获得日志对应事务ID
// xid: 若存在XA事务,则读取XA事务的xid
// last_page_no: 当前undo最后(最新)一条日志写的undo page
// 在这些信息读取之后,创建trx_undo_t,undo内存结构
// 2.3.5 根据last_page_no与undo_offset,读取最后一条undo日志内容
// 2.3.6 根据最后一条undo rec,读取其对应的undo 序列号
// 2.3.7 当前undo,链接到回滚段对应的链表中(insert/update_undo_list)
trx_sys_init_at_db_start();
trx_sysf_get(TRX_SYS_SPACE, TRX_SYS_PAGE_NO);
trx_rseg_list_and_array_init();
trx_rseg_create_instance();
trx_sysf_rseg_get_page_no(); // 流程2.1
trx_sysf_rseg_get_space(); // 流程2.2
trx_rseg_mem_create(); // 流程2.3
trx_undo_lists_init(); // 流程2.3.3
trx_undo_mem_create_at_db_start(); // 流程2.3.4
trx_undo_mem_create(); // 流程
trx_undo_page_get_last_rec(); // 流程2.3.5
trx_undo_rec_get_undo_no(); // 流程2.3.6
UT_LIST_ADD_LAST(undo_list, undo); // 流程2.3.7
// 完成undo信息的收集,接下来就是根据undo信息,重建未提交事务。
// 未提交事务的重建流程如下:
// 1. 遍历trx_sys结构中的rollback segment回滚段链表,取出所有回滚段
// 2. 遍历每个回滚段的insert_undo_list与update_undo_list,取出的undo
// 3. 根据undo日志信息,重建事务;并且根据事务的不同状态:
// 3.1 undo事务状态为TRX_UNDO_ACTIVE,为活跃事务,TRX_ACTIVE
// 3.2 undo事务状态为TRX_UNDO_PREPARED -> TRX_PREPARED
// 4. 将事务按照trx_id的顺序链入trx_sys->trx_list链表
// 注意:在重建事务时,事务的start_time也为新的时间,而不是crash
// 前的事务真正创建时间。
trx_lists_init_at_db_start();
trx_create(); // 流程3
// trx->undo_no,记录了当前事务的undo序列号,也代表当前事务一共
// 修改了多少行记录。
rows_to_undo += trx->undo_no;
// 创建purge操作系统结构。至此,undo信息与undo事务的创建结束。
trx_purge_sys_create();
// undo信息重构,事务创建完成之后,进入到crash recovery的最后一个步骤
// 最后一个步骤的流程如下:
// 1. redo最后hash表中最后一部分log,最后一次hash表未满,在此时redo
// 2. 打印InnoDB redo log位置信息;以及最后一次commit操作的binlog信息
// 两个信息都保存于transaction system header page中。[0, 5]
// 3. 回滚处于ACTIVE状态的DDL操作事务,此时并不回滚DML事务。
recv_recovery_from_checkpoint_finish();
recv_apply_hashed_log_recs();
trx_rollback_or_clean_recovered(FALSE);
// 回滚DML操作ACTIVE事务,在此函数中完成;而处于PREPARE状态的
// 事务,并不回滚,而是等待MySQL上层的binlog判断最终的回滚or提交
// 回滚DML操作,通过新创建一个线程完成,而非在主线程中执行
recv_recovery_rollback_active();
os_thread_create(trx_rollback_or_clean_all_recovered);
trx_rollback_or_clean_recover(TRUE);
// 创建加锁超时监控线程
os_thread_create(&srv_lock_timeout_thread);
// 创建InnoDB主线程,做purge,checkpoint,dirty pages flush操作
os_thread_create(&srv_master_thread);
// 至此,innobase_start_or_create_for_mysql函数处理完毕,crash recovery
// 操作也基本完成,InnoDB引擎恢复成功,处于open状态
2 Crash Recovery优化
根据crash recovery流程,后续人员发现其中有两个性能不足的点:
控制redo log hash table的大小
redo log hash table大小,不能超过available_mem,如何判断?Bug #49535
redo 过程中维护flush_list
按照dirty page最早的修改时间排序的一个链表结构,方便进行fuzzy checkpoint?Bug #29847
在正常超过过程中,由于lsn是递增生成,因此新修改的page一定位于flush list的最前面。但是在crash recovery过程中,redo是按照页面进行batch操作,不同页面的oldest_modification不一定递增产生,因此每个页面加入flush list,都需要遍历flush list链表,消耗cpu性能。
两个问题的说明与解决方案,具体可参考[1][2]。而接下来的部分,主要是从源码分析两个问题的解决方案。
Hash Table Size
原来是遍历hash table,获得hash table中的页面数量,然后判断hash table的size是否已经超过指定大小。
新的做法是,在 recs_sys->heap 结构中,新增一个total_size字段,每次heap新增一个block,则将相应的block_size加到total_size之上。
只需要判断total_size与available_memory之间的大小,即可以判断hash table size是否超过指定大小,简单方便。
Red Black Tree(RBT)
crash recovery过程中,page的oldest_modification不一定递增生成,需要遍历整个flush list链表,查找正确的插入位置。为了解决链表插入操作的性能不足,InnoDB Plugin在crash recovery过程中,提供了一个Red Black Tree(红黑树:ib_rbt_struct)数据结构,用于加速crash recovery过程。源码的修改主要集中于buf_flush_insert_sorted_into_flush_list函数:
buf0flu.c::buf_flush_insert_sorted_into_flush_list();
// 1. 如果使用Red Black Tree,则首先将页面插入Red Black Tree之中
// 2. Red Black Tree,按照<page.oldest_modification, space, offset>排序
// 3. 插入完成之后,并且返回当前插入节点的前一个节点
if (buf_pool->flush_rbt)
prev_b = buf_flush_insert_in_flush_rbt(&block->page); // 流程1
cnode = rbt_insert(buf_pool->flush_rbt, &page, &page); // 流程2
rbt_prev(buf_pool->flush_rbt, cnode); // 流程3
// 4. 根据Red Black Tree返回的前一个节点,将当前page链入flush list中
UT_LIST_INSERT_AFTER(list, buf_pool->flush_list, prev_b, &block->page); // 流程4
crash recovery过程中,当恢复由于内存不足,或者是全部hash table中的全部redo应用完毕,都会调用函数,清空内存中的所有dirty pages,与此同时,也相应的逐个删除Red Black Tree中的page。
buf0flu.cc::buf_flush_remove(bpage);
buf_flush_delete_from_flush_rbt(bpage);
rbt_delete(buf_pool->flush_rbt, &bpage);
优化效果
下图是截自于[2]的第13页,从中可以看出两个优化对于crash recovery带来的影响。在这个测试用例下,恢复时间改进了32倍。尤其是改进2,让log applying改进了35.5倍。

rollback segment & Transaction
本小节,主要讨论InnoDB的两个主要数据结构的关系,其一是rollback segment,其二是transaction。
rollback segment
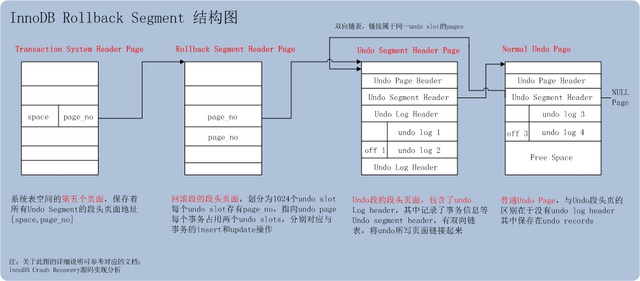
Transaction System Header Page
系统表空间的第五个Page [TRX_SYS_SPACE, TRX_SYS_PAGE_NO] ,该页面中保存了最新的binlog信息,日志信息等。同时,保存了每个undo segments的回滚段段头页信息。每个回滚段信息包括[space_id, page_no]组合,指向回滚段段头页。
Rollback Segment Header Page
回滚段段头页,其中最重要的信息是undo slot:undo槽。回滚段段头页包含1024个undo slot,每个slot中存储的是page_no,指向Undo Segment Header Page。
undo slot可以这么理解,一个事务的一类操作(insert or update)的undo通过链表链接起来,形成一个undo slot。
每个事务,需要占用两个undo slot,一个slot用于处理事务的所有insert操作;另一个slot用于处理事务的delete/update操作,在事务中的定义如下:
trx_undo_t* insert_undo; /*!< pointer to the insert undo log, or
NULL if no inserts performed yet */
trx_undo_t* update_undo; /*!< pointer to the update undo log, or
NULL if no update performed yet */
Undo Segment Header Page
undo slot中存储的page_no,对应的就是Undo Segment Header Page。Undo Segment Header Page,主要有以下几个头结构:
TRX_UNDO_PAGE_HDR(undo页头)
事务操作类型;page的free空间等(trx0undo.h)
TRX_UNDO_SEG_HDR(undo段头)
事务状态;undo log header位置;undo page链表(trx0undo.h)
undo log header(undo日志头)
起始地址在TRX_UNDO_SEG_HDR中保存。内容包括:事务id;xid;下一个undo log header位置等(trx0undo.h)
通过读取undo段头中的undo page链表,获取当前undo写的最后一个page,然后读取此page上的最后一个undo record,就完成了一个undo slot的解析。事务rollback时,首先rollback最后一个undo record,然后根据此undo record记录的上一个undo的位置,继续回滚上一条undo。
根据当前undo record,如何获取上一条undo record?通过跟踪函数trx0roll.c::trx_roll_pop_top_rec_of_trx(),可以略知一二。
undo page有两种,undo segment header page与普通undo page。
普通undo page不包含前面提到的undo日志头。
普通undo page中,第一个undo记录存储于[TRX_UNDO_PAGE_HDR + TRX_UNDO_PAGE_HDR_SIZE]处
undo segment header page,第一个undo记录(不是undo日志头)存储于undo日志头结构中的TRX_UNDO_LOG_START处。
普通undo page,最后一个undo记录存储于空闲位置之前
undo segment header page,最后一个undo记录存储于下一个undo日志头之前
若undo的前一条记录与当前undo记录在同一页面
前一条记录的位置 = undo_page + mach_read_from_2(rec – 2);
当前undo record的前面2 bytes,记录了前一个undo record的位置
若undo的前一条记录与当前undo记录不在同一页面
首先通过当前undo record所处的undo page页面,读取其TRX_UNDO_SEG_HDR(undo段头)获得前一个undo page
然后读取前一个undo page中的最后一个undo record即可。
Transaction
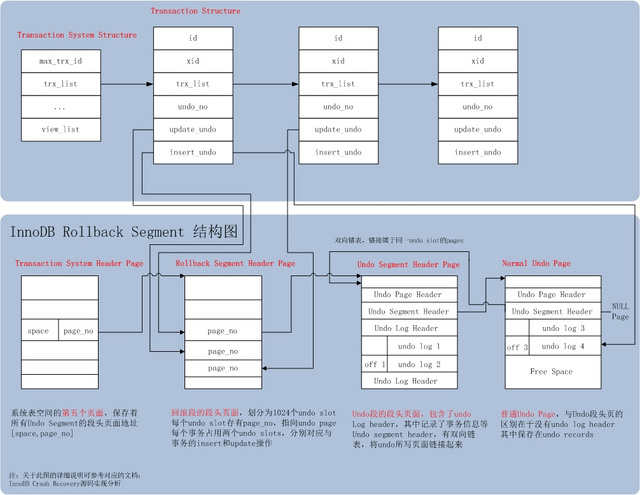
在Rollback Segment的基础上,加上了事务部分。事务部分相对简单,与undo相关的包括:
Transaction System Structure
事务的集中管理者,主要的结构包括:
max_trx_id: 下一个未分配事务ID
trx_list: 所有活跃事务链表
Transaction Structure
事务的内存结构,跟undo相关的成员包括:
undo_no
事务的DML序列号。标识事务当前修改了多少行记录。
update_undo
事务所有的update/delete_mark操作,保存在这个undo链表中,占用一个undo slot
update_undo对应的是trx_undo_struct数据结构,其中包含undo slot id;rollback segment id;最新一条undo记录写的page_no以及page_offset信息。
insert_undo
事务所有的insert操作,保存在一个undo链表中,占用一个undo slot
因此,一个事务,如果既包括insert操作,也包括update/delete_mark操作,则需要占用两个undo slot。
DB_ROLLBACK_PTR
在InnoDB cluster index的记录,有一个系统列DB_ROLLBACK_PTR:7 bytes。组成如下:
最低位2 bytes:前一版本所在undo页面内的偏移;
中间 4 bytes:所在undo页面page_no;
最高位 1 bytes分为两部分;
低 7 bits: rollback segment id (128个)。
最高位 1 bit:标识当前操作类型,insert or update操作。若为insert操作,则直接不用undo,没有前一版本。
转:InnoDB Crash Recovery 流程源码实现分析的更多相关文章
- JobTracker启动流程源码级分析
org.apache.hadoop.mapred.JobTracker类是个独立的进程,有自己的main函数.JobTracker是在网络环境中提交及运行MR任务的核心位置. main方法主要代码有两 ...
- mapreduce job提交流程源码级分析(三)
mapreduce job提交流程源码级分析(二)(原创)这篇文章说到了jobSubmitClient.submitJob(jobId, submitJobDir.toString(), jobCop ...
- [Android]Android系统启动流程源码分析
以下内容为原创,欢迎转载,转载请注明 来自天天博客:http://www.cnblogs.com/tiantianbyconan/p/5013863.html Android系统启动流程源码分析 首先 ...
- [Android]从Launcher开始启动App流程源码分析
以下内容为原创,欢迎转载,转载请注明 来自天天博客:http://www.cnblogs.com/tiantianbyconan/p/5017056.html 从Launcher开始启动App流程源码 ...
- Spring加载流程源码分析03【refresh】
前面两篇文章分析了super(this)和setConfigLocations(configLocations)的源代码,本文来分析下refresh的源码, Spring加载流程源码分析01[su ...
- Android Activity启动流程源码全解析(1)
前言 Activity是Android四大组件的老大,我们对它的生命周期方法调用顺序都烂熟于心了,可是这些生命周期方法到底是怎么调用的呢?在启动它的时候会用到startActivty这个方法,但是这个 ...
- Android Activity启动流程源码全解析(2)
接上之前的分析 ++Android Activity启动流程源码全解析(1)++ 1.正在运行的Activity调用startPausingLocked 一个一个分析,先来看看startPausing ...
- Spring IOC容器启动流程源码解析(四)——初始化单实例bean阶段
目录 1. 引言 2. 初始化bean的入口 3 尝试从当前容器及其父容器的缓存中获取bean 3.1 获取真正的beanName 3.2 尝试从当前容器的缓存中获取bean 3.3 从父容器中查找b ...
- Android笔记--View绘制流程源码分析(二)
Android笔记--View绘制流程源码分析二 通过上一篇View绘制流程源码分析一可以知晓整个绘制流程之前,在activity启动过程中: Window的建立(activit.attach生成), ...
随机推荐
- Oracle常用知识小总结
永不放弃,一切皆有可能!!! 只为成功找方法,不为失败找借口! Oracle常用知识小总结 1. 创建自增主键 对于习惯了SQL SERVER的图形化界面操作的SQLer,很长一段时间不用oracle ...
- linux shell执行SQL脚本
#!/bin/sh user="user" pass="pass" sqlplus -S $user/$pass select 1 from dual; exi ...
- 机器学习-chapter1机器学习的生态系统
1.机器学习工作流程 获取->检查探索->清理准备->建模->评估->部署 2.搭建机器学习环境 1..通过安装Python,配置相关环境变量 2.强烈建议直接安装ana ...
- Spring插件的安装与卸载---笔记
Spring插件的安装 1.在eclipse中选择工具菜单Help--->Install New Software选项 2.点击Add, 3.选择插件地址或输入网址,点击 OK . http ...
- 浅谈CDN技术的性能与优势
从淘宝架构中的CDN入手分析 使用CDN和反向代理提高网站性能.由于淘宝的服务器不能分布在国内的每个地方,所以不同地区的用户访问需要通过互联路由器经过不同长度的路径来访问服务器,返回路径也一样,所以数 ...
- mysql基础(1)-基本操作
数据库 数据库(Database,DB)是数据的集合,是一个长期存储在计算机内的.有组织的.有共享的.统一管理的数据集合. 存储数据 管理数据 数据库类型 关系型数据库:由二维表及其之间的联系组成的一 ...
- div css 练习1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Windows下软件调试
1. 视频: (1).VS下的C++调试方法.wnv (2).WinDbg高级调试技术.wmv (3).内存与句柄泄漏处理技巧.wmv 2. “WinDbg高级调试技巧” 中 [01:22]讲到“软件 ...
- STL视频_01
ZC:这里视频里面有一个调试小技巧,VS08/VS2010开始,控制台程序会自动退出(不像VC6),那么可以在 函数退出的最后一句语句上设置断点,然后查看控制台打印出来的信息.ZC:这一讲,给我的感觉 ...
- 深度学习—BN的理解(一)
0.问题 机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障.那BatchNorm的作用是 ...