http头部信息学习
想的每2周进行知识的总结,自己拖延症有犯了,发现自己知识库量还是太少,平时总结和发现问题还不够深,对待问题的深度也存在很多问题,但是坚持学习,总结,后面应该会有收获,
1.常见的返回码
100: 请服务器端继续返回
200:成功
301:永久重定向 存的地址永久的改变了 301
302 : 暂时重定向 302仍然使用老得url
401 : 无法找到资源file not found
500服务器内部错误
501:服务器不支持请求的功能,无法完成请求
2.http提供的方法

方法有:get、post、head、put、teace、options、delete
get和Post的区别:
本质区别:
- get从服务器获取一份文档,而post是向服务器发送内容,如用户登录的就是提交一个post,GET一般用于获取/查询资源信息,而POST一般用于更新资源信息。
2. get提交是把数据存放在url,而post存放在主体
3.get大小有限制,GET方式提交的数据最多只能是1024字节,理论上POST没有限制,可传较大量的数据,
4.Get是通过地址栏来传值,而Post是通过提交表单来传值
比较详细区别推荐:http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
2.1http的方法
put 方法: 是创建资源
Delete:方法是删除资源
options : 询问支持的方法
head:与 GET 相同,但只返回 HTTP 报头,不返回文档主体。获得报文首部
trace: 跟踪 发起一个环回判断。
有比较好的博客
http://www.cnblogs.com/yin-jingyu/archive/2011/08/01/2123548.html
3.http请求头查看
1.查看请求和响应,有很多工具可以做到如fiddler、浏览器的F12,火狐的firefox,wireshardk
以下实例用火狐浏览器举例,访问百度实例,用火狐自带的firebug查看,
插曲,什么是PV什么是UV
pv:pageview 浏览量 pv页面浏览量或点击量,页面刷新一次计算一次,不排重
UV:userview 访问量 一个ip就是一个用户

3.1解读头部信息

1.accept:客户端接受服务器端的文件格式,代表服务器端返回什么样类型的格式返回客户端,客户端才能正常识别
- accept *:代表所有内容都可以
- accept
text/javascript:代表返回文本和js HTTP Header中Accept-Encoding 是浏览器发给服务器,声明浏览器支持的编码类型[1]- accept encoding:可以接受的编码
2.gzip:压缩格式 压缩数据, 文件上传到服务器压缩,这样传输数据可大大节省带宽 编码:指用什么编码
3.DEFLATE:是一个无专利的压缩算法,它可以实现无损数据压缩,有众多开源的实现算法、
常见的有
Accept-Encoding: compress, gzip //支持compress 和gzip类型Accept-Encoding://默认是identityAccept-Encoding: *//支持所有类型 Accept-Encoding: compress;q=0.5, gzip;q=1.0//按顺序支持 gzip , compressAccept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0 //按顺序支持 gzip , identity
4.Accept-Language:浏览器设置的语言用于告诉服务器浏览器可以支持什么语言。
5.Accept-Language:zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3 这里zh-CN 是表示中文,后面的我也不知道是什么
6.Connection:keep-alive :保持连接,表示长连接,Keep-Alive功能避免了建立或者重新建立连接,对于提供静态内容的网站来说,这个功能通常很有用。但是,对于负担较重的网站来说,这里存在另外一个问题:虽然为客户保留打开的连 接有一定的好处,但它同样影响了性能,因为在处理暂停期间,本来可以释放的资源仍旧被占用。
推荐博客:
http://www.cnblogs.com/huangfox/archive/2012/03/31/2426341.html
7.Cookie:Cookies就是服务器暂时存放在你的电脑里的资料(.txt格式的文本文件),好让服务器用来辨认你的计算机。当你在浏览网站的时候,Web服务器会先送一小小资料放在你的计算机上,Cookies 会把你在网站上所打的文字或是一些选择都记录下来。当下次你再访问同一个网站,Web服务器会先看看有没有它上次留下的Cookies资料,有的话,就会依据Cookie里的内容来判断使用者,送出特定的网页内容给你
8.User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:49.0) Gecko/20100101 Firefox/49. :访问浏览器的信息
9.X-Requested-With:Ajax 异步请求方式
使用request.getHeader("x-requested-with");为 null,则为传统同步请求;
3.2响应头信息
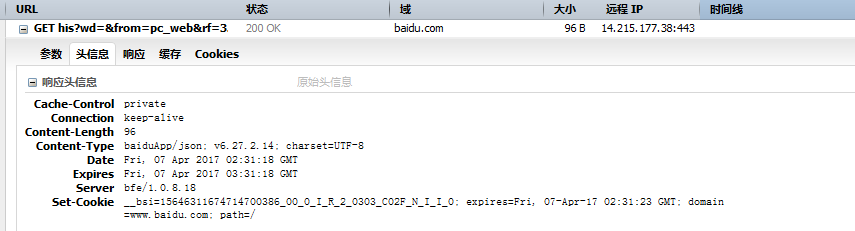
1.Cache-Control:这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令,网页的缓存是由HTTP消息头中的“Cache-control”来控制的,常见的取值有private、no-cache、max-age、must-revalidate等,默认为private。其作用根据不同的重新浏览方式分为以下几种情况。

推荐博客阅读:
2.Connection:keep-alive,保持长连接
3.Connect-length: 表示实体内容长度,客户端(服务器)可以根据这个值来判断数据是否接收完成,如断点续传用到这个功能
4.Content-Type:baiduApp/json; v6.27.2.14; charset=UTF-8 定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件
5.Date Fri, 07 Apr 2017 02:31:18 GMT:ate头域表示消息发送的时间,请求返回内容的时间格式
6.Expires Fri, 07 Apr 2017 03:31:18 GMT,HTTP控制缓存的基本手段,这个属性告诉缓存器:相关副本在多长时间内是新鲜的。过了这个时间,缓存器就会向源服务器发送请求,检查文档是否被修 改。几乎所有的缓存服务器都支持Expires(过期时间)属性;
如果以上date和expires相同,时间一样,说明每次都要去服务器重新获取,如果Expires 时间大于date,在没有过期的时间,说明获取是获取的缓存
7.Server:: nginx web容器
8.Set cookie:过期时间
忙活了半天,发现有个贴写的很详细,大赞
http://blog.chinaunix.net/uid-10540984-id-3130355.html
其他的一些头信息
content-length:报文主体的大小,可以做断点续传,一定要知道文本大小
Trans-encoding :chunked 传输编码浏览器传输数据格式 , 服务器通过这个头,告诉浏览器数据的传送格式,分块传输
Content-length:大小
Cache –control:表示不会有缓存
CDN: Content Delivery Network
存放静态资源的东西 内容分发网络
Vary:
请求报文:客户端发起的
响应报文:服务器端发起的
Accept-ranges:返回的字节
Age 9117 age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现在经过多长时间了
以上内容都是自己的见解,可能有很多理解上会有问题,
http头部信息学习的更多相关文章
- 简析TCP的三次握手与四次分手(TCP协议头部的格式,数据从应用层发下来,会在每一层都会加上头部信息,进行封装,然后再发送到数据接收端)good
2014-10-30 分类:理论基础 / 网络开发 阅读(4127) 评论(29) TCP是什么? 具体的关于TCP是什么,我不打算详细的说了:当你看到这篇文章时,我想你也知道TCP的概念了,想要更 ...
- PyCharm:设置py文件头部信息
P PyCharm:设置py文件头部信息file->setting->appearance & behavior->editor->file and code temp ...
- 【转】HTTP 头部解释,HTTP 头部详细分析,最全HTTP头部信息
HTTP 头部解释 ========================================================================================== ...
- HTTP消息中header头部信息的讲解
HTTP Request的Header信息 1.HTTP请求方式 如下表: GET 向Web服务器请求一个文件 POST 向Web服务器发送数据让Web服务器进行处理 PUT 向Web服务器发送数据并 ...
- 深入理解ajax系列第三篇——头部信息
前面的话 每个HTTP请求和响应都会带有相应的头部信息,其中有的对开发人员有用.XHR对象提供了操作头部信息的方法.本文将详细介绍HTTP的头部信息 默认信息 默认情况下,在发送XHR请求的同时,还会 ...
- HTTP消息中Header头部信息整理
1.HTTP请求方式 GET 向Web服务器请求一个文件 POST 向Web服务器发送数据让Web服务器进行处理 PUT 向Web服务器发送数据并存储在Web服务器内部 HEAD 检查一个对象是否存在 ...
- HTTP常用头部信息
下面用例子的形式来记录下常用的一些Http头部信息 Request Header: GET /sample.Jsp HTTP/1.1 //请求行 Host: www.uuid.online/ // ...
- [转]Sublime Text 新建文件快速生成Html【头部信息】和【代码补全】、【汉化】
Sublime Text 新建文件快速生成Html[头部信息]和[代码补全].[汉化] 真心越来越喜欢sublime 这个工具,高效便捷,渐渐离不了了! 安装package control简单的安装方 ...
- 深入理解ajax系列第六篇——头部信息
前面的话 每个HTTP请求和响应都会带有相应的头部信息,其中有的对开发人员有用.XHR对象提供了操作头部信息的方法.本文将详细介绍HTTP的头部信息 默认信息 默认情况下,在发送XHR请求的同时,还会 ...
随机推荐
- 远程控制Ubuntu系统小结
一.在远程控制的Ubuntu上,按shift键总会出现中文字符 因为在Ubuntu中,默认启动搜狗输入法,导致在按shift键时,不停出现中文字符 一开始以为是因为远程控制,在主控机和被控机的输入法之 ...
- centos 通过yum安装GlusterFS
1.环境 centos 6.5 64 bit glusterfs-3.5 2.配置yum源 http://download.gluster.org/pub/gluster/glusterfs/repo ...
- QT的学习
背景 最近正忙着做一个项目,由于之前对面向对象编程了解的非常少,所以导致项目的代码有很多不太清楚:看到代码的时候整个人是懵的.所以在国庆期间,结合着大神的博客看了一下面向对象编程,并学习了开发GUI应 ...
- Vue源码学习之双向绑定
首发地址:CJWbiu's Blog 原理: ‘当你把一个普通的 JavaScript 对象传给 Vue 实例的 data 选项,Vue 将遍历此对象所有的属性,并使用 Object.definePr ...
- ACM-ICPC 2018 南京赛区网络预赛 B. The writing on the wall
题目链接:https://nanti.jisuanke.com/t/30991 2000ms 262144K Feeling hungry, a cute hamster decides to o ...
- Sort HDU - 5884 哈夫曼权值O(n)
http://acm.hdu.edu.cn/showproblem.php?pid=5884 原来求一次哈夫曼可以有O(n)的做法. 具体是,用两个队列,一个保存原数组,一个保存k个节点合并的数值,然 ...
- POJ 3321 Apple Tree DFS序 + 树状数组
多次修改一棵树节点的值,或者询问当前这个节点的子树所有节点权值总和. 首先预处理出DFS序L[i]和R[i] 把问题转化为区间查询总和问题.单点修改,区间查询,树状数组即可. 注意修改的时候也要按照d ...
- Java文件与io——字节流
FileOutputStream用于写入诸如图像数据之类的原始字节的流 字节输出流:OutputStream 此抽象类表示输出字节流的所有类的超类.(写) 字节输入流:InputStream(读) p ...
- (转)vimdiff 快速比较和合并少量文件
vimdiff 快速比较和合并少量文件 原文:http://www.cnblogs.com/abeen/p/4255754.html 纯文本文件比较和合并工具一直是软件开发过程中比较重要的组成部分,v ...
- Storm概念学习系列之storm-starter项目(完整版)(博主推荐)
不多说,直接上干货! 这是书籍<从零开始学Storm>赵必厦 2014年出版的配套代码! storm-starter项目包含使用storm的各种各样的例子.项目托管在GitHub上面,其网 ...