机器学习中正则化项L1和L2的直观理解
正则化(Regularization)
概念
L0正则化的值是模型参数中非零参数的个数。
L1正则化表示各个参数绝对值之和。
L2正则化标识各个参数的平方的和的开方值。
L0正则化
稀疏的参数可以防止过拟合,因此用L0范数(非零参数的个数)来做正则化项是可以防止过拟合的。
从直观上看,利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但因为L0正则化很难求解,是个NP难问题,就是难以优化,因此一般采用L1正则化。L1正则化是L0正则化的最优凸近似,比L0容易求解,并且也可以实现稀疏的效果。
L1、L2正则化
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。

下图是Python中Ridge回归的损失函数,式中加号后面一项 即为L2正则化项。
即为L2正则化项。

一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。
1. 为什么要生成一个稀疏矩阵?(实现参数的稀疏有什么好处吗?)
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能呵呵了。另一个好处是参数变少可以使整个模型获得更好的可解释性。这就是稀疏模型与特征选择的关系。
2.参数值越小代表模型越简单吗?
是的。为什么参数越小,说明模型越简单呢,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
L1和L2正则化的直观理解
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数:

其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此J是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2的二维平面上画出来。如下图:
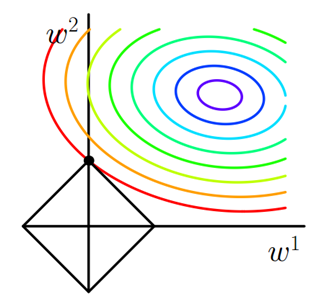
图1 L1正则化
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:

同样可以画出他们在二维平面上的图形,如下:
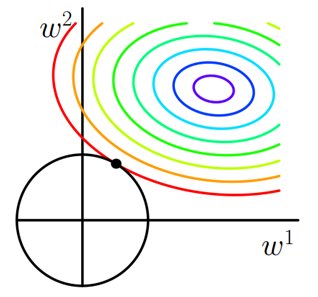
图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化和过拟合
避免过拟合的方式之一是使用交叉验证(cross validation),这有利于估计测试集中的错误,同时有利于确定对模型最有效的参数。本文将重点介绍一种方法,它有助于避免过拟合并提高模型的可解释性。
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
正则化
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为 是我们的假设函数,那么线性回归的代价函数如下:

那么在梯度下降法中,最终用于迭代计算参数θ的迭代式为:
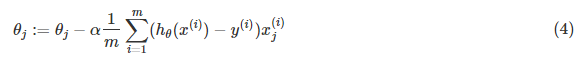
其中α是learning rate. 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:

其中λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θj都要先乘以一个小于1的因子,从而使得θj不断减小,因此总得来看,θ是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
正则化参数的选择
L1正则化参数
通常越大的λ可以让代价函数在参数为0时取到最小值。下面是一个简单的例子,这个例子来自Quora上的问答。为了方便叙述,一些符号跟这篇帖子的符号保持一致。
假设有如下带L1正则化项的代价函数:
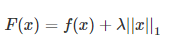
其中x是要估计的参数,相当于上文中提到的w以及θ. 注意到L1正则化在某些位置是不可导的,当λ足够大时可以使得F(x)在x=0时取到最小值。如下图:

图3 L1正则化参数的选择
分别取λ=0.5和λ=2,可以看到越大的λλ越容易使F(x)在x=0时取到最小值。
L2正则化参数
从公式5可以看到,λ越大,θj衰减得越快。另一个理解可以参考图2,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
学习源于:https://blog.csdn.net/jinping_shi/article/details/52433975
机器学习中正则化项L1和L2的直观理解的更多相关文章
- 神经网络损失函数中的正则化项L1和L2
神经网络中损失函数后一般会加一个额外的正则项L1或L2,也成为L1范数和L2范数.正则项可以看做是损失函数的惩罚项,用来对损失函数中的系数做一些限制. 正则化描述: L1正则化是指权值向量w中各个元素 ...
- 正则化项L1和L2
本文从以下六个方面,详细阐述正则化L1和L2: 一. 正则化概述 二. 稀疏模型与特征选择 三. 正则化直观理解 四. 正则化参数选择 五. L1和L2正则化区别 六. 正则化问题讨论 一. 正则化概 ...
- 正则化项L1和L2的区别
https://blog.csdn.net/jinping_shi/article/details/52433975 https://blog.csdn.net/zouxy09/article/det ...
- 损失函数———有关L1和L2正则项的理解
一.损失函: 模型的结构风险函数包括了 经验风险项 和 正则项,如下所示: 二.损失函数中的正则项 1.正则化的概念: 机器学习中都会看到损失函数之后会添加一个额外项,常用的额外项一般有2种, ...
- 机器学习中规范化项:L1和L2
规范化(Regularization) 机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- 深度学习(五)正则化之L1和L2
监督机器学习问题无非就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时最小化误差.最小化误差是为了让我们的模型 ...
- 正则化,L1,L2
机器学习中在为了减小loss时可能会带来模型容量增加,即参数增加的情况,这会导致模型在训练集上表现良好,在测试集上效果不好,也就是出现了过拟合现象.为了减小这种现象带来的影响,采用正则化.正则化,在减 ...
- 『科学计算』L0、L1与L2范数_理解
『教程』L0.L1与L2范数 一.L0范数.L1范数.参数稀疏 L0范数是指向量中非0的元素的个数.如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,让参数W是稀 ...
随机推荐
- Tomcat热部署的实现原理
Tomcat热部署机制 对于Java应用程序来说,热部署就是在运行时更新Java类文件.在基于Java的应用服务器实现热部署的过程中,类装入器扮演着重要的角色.大多数基于Java的应用服务器,包括EJ ...
- 基础篇 - pg_isready
pg_isready 发起一个到指定 PostgreSQL数据库的连接检查. 使用方法: pg_isready [选项]... 选项: -d, --dbname=DBNAME 数据库名 -q, --q ...
- FoundToday for HK 技术支持
FoundToday for HK 技术支持 技术支持网址:有问题或建议请留言. 邮箱地址: swvrwafet@zoho.com Program design & system cons ...
- jenkins+maven+Tomcat+shell构建自动化部署
https://yq.aliyun.com/articles/685931 1.官网下载war包:jenkins本质上就是一个web应用,直接下载jenkins的war包通过tomcat运行即可.ht ...
- tp5分页注意,分页生成的ul class是pagination,有些模板可能将pagination定义为display:none
今天在调用分页时总是无法显示,查看网页源代码是正常的,后来发现是在css文件里将pagination定义为display:none,所以无法显示
- What is Data Driven Testing? Learn to create Framework
What is Data Driven Testing? Data-driven is a test automation framework which stores test data in a ...
- JS事件之鼠标悬浮窗(鼠标悬浮窗抖动问题的解决)
鼠标进入显示悬浮窗,思路有简单有困难. 首先要注意的是我们要给悬浮窗设置position为absolute,不然我们改了 style.left style.top发现没有变化很尴尬.其余的内容看起来就 ...
- Javascript专题(三)c.各种轮播--上下滚动轮播(面向对象版本)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ubuntu下ganglia3.7.2编译安装
一.介绍 ganglia主要包括gmond和gmeta 1.gmond用于收集监测数据,可以发送也可以接收在同一个组播或单播通道上的统计信息.gmond有两个角色,一个是发送者,另一个是接收者.当mu ...
- Ubuntu14.04修改主机名
1.Ubuntu主机名位于/etc/hostname里,将其修改为自己需要的名称 2.修改/etc/hosts文件,将其中127.0.1.1对应的主机名更改为新的主机名,与/etc/hostname里 ...