大话Spark(2)-Spark on Yarn运行模式
Spark On Yarn 有两种运行模式:
- Yarn - Cluster
- Yarn - Client
他们的主要区别是:
Cluster: Spark的Driver在App Master主进程内运行, 该进程由集群上的YARN管理, 客户端可以在启动App Master后退出.
Client: Driver在提交作业的Client中运行, App Master仅用于从YARN请求资源.
这里以Client为例介绍:
Yarn-Client运行模式
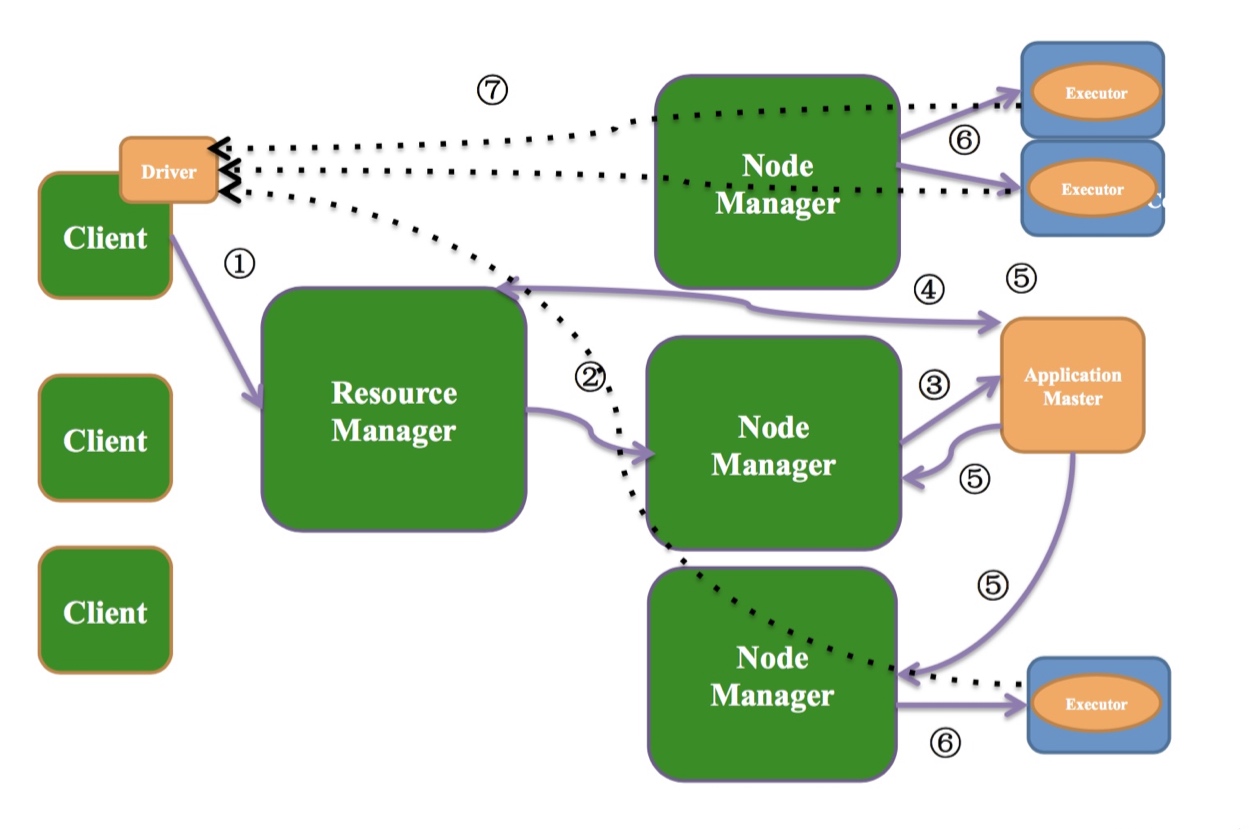 

如上图:
Yarn-Client模式中,Driver运行在客户端(提交Spark程序的机器, 代码中Main方法运行的机器).
作业提交过程
- Client端提交作业到ResourceManager
(连接到ResourceManager, 获取queue,resource等信息,upload app jar,设置运行环境和container上下文) - ResourceManager找一个NodeManager
- NodeManager启动ApplicationMaster(在运行的时候指定占用多少资源)
- ApplicationMaster启动之后跟ResourceManager通信,为Executor申请资源.
- ApplicationMaster申请资源之后跟NodeManager通信
- 启动Executor
- Exector启动之后会跟Driver通信领取任务.
每个Spark程序由1个Driver和多个Executor构成.
Executor个数, 内存, cpu多少由用户控制(默认1g内存 1个cpu 2个executor)
WorkCount--逻辑查询计划--物理查询计划
逻辑查询计划
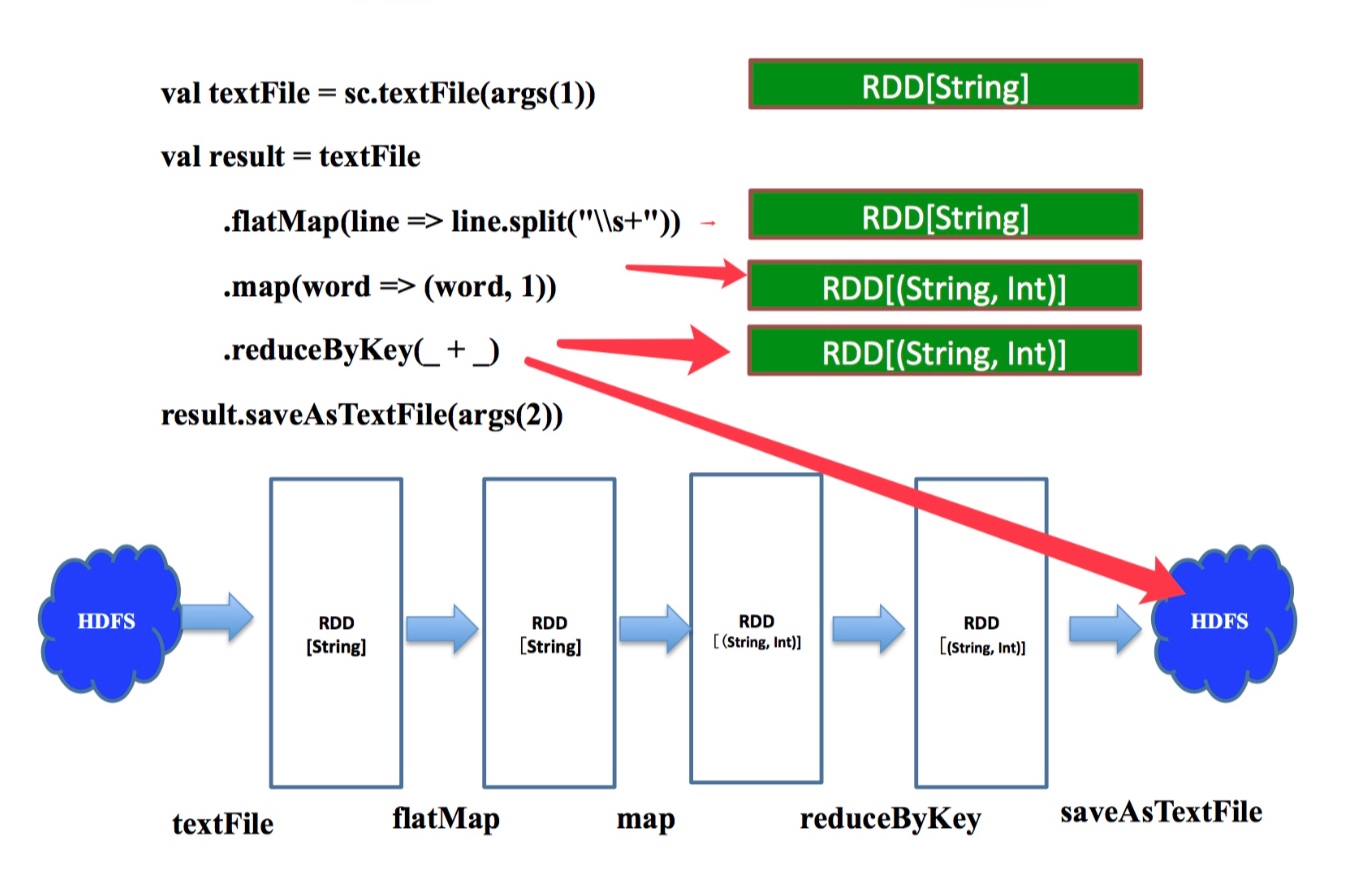 

上图右侧绿框代表每一步算子计算之后的结果
sc.textFile取hdfs路径生成rddtextFile.flatMap把rdd中的一行数据按照\s+(匹配任何空白字符,包括空格、制表符、换页符等等)拆成多行work=>(work, 1)把每条数据x 转换成(x, 1)这样key-value对的元组.reduceByKey(_ + _)按照每个key聚合,取value的总和(每个单词出现的次数)saveAsTextFile这是一个action操作,把最终结果写到hdfs
上图的下半部分是workcount作业的逻辑查询计划.
物理查询计划
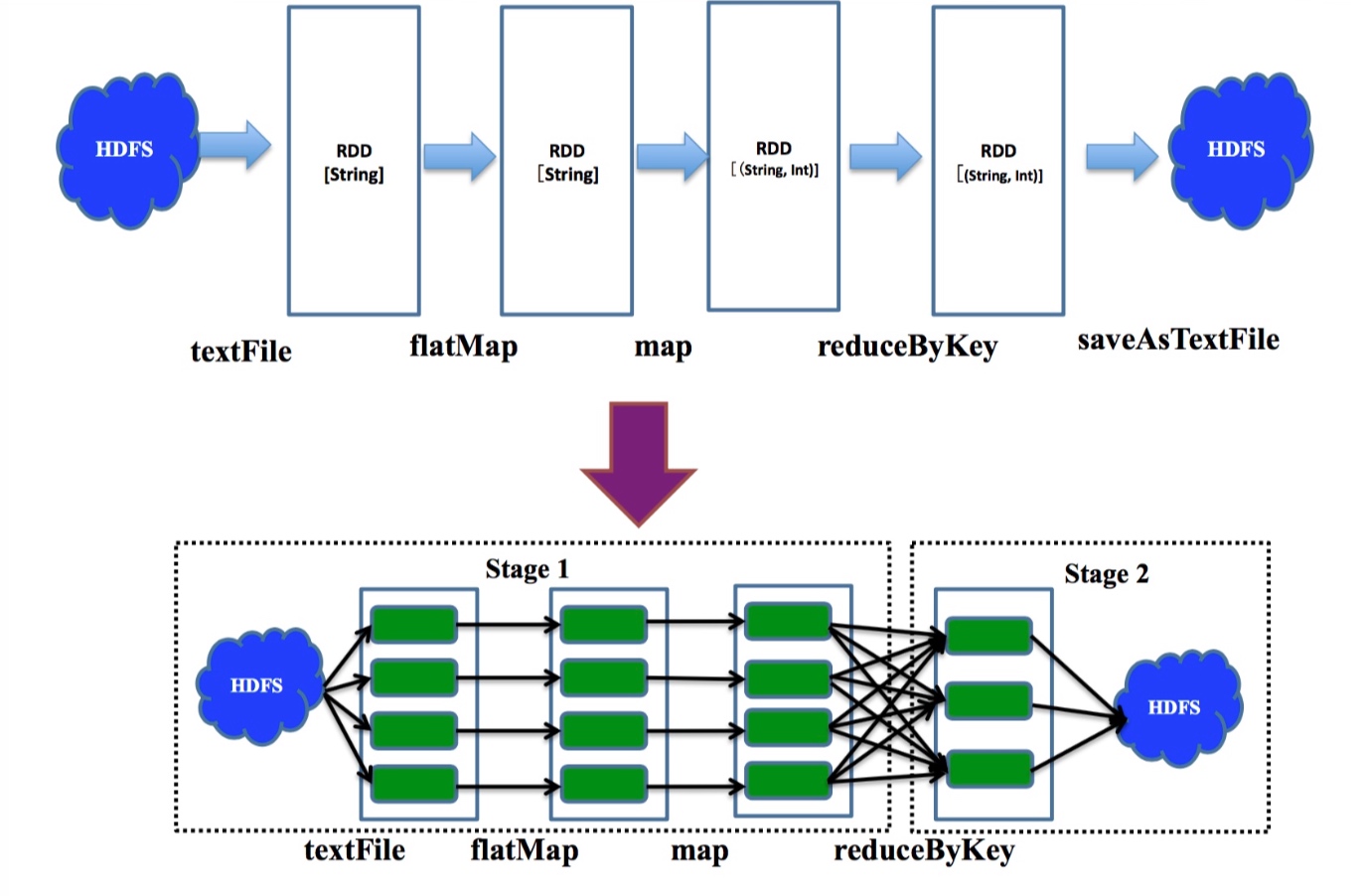 

上图上半部分展示了各级算子值键的依赖关系(逻辑查询计划)
下半部分的每个绿块代表一个partition的数据,多个partition值键并行计算, 遇到会产生shuffle的reduceByKey操作时划分stage.
窄依赖:
指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区
宽依赖:
是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区
stage内部是窄依赖,stage间是宽依赖.
大话Spark(2)-Spark on Yarn运行模式的更多相关文章
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- 六、yarn运行模式
简介 spark的yarn运行模式根据Driver在集群中的位置分成两种: 1)yarn-client 客户端模式 2)yarn-cluster 集群模式 yarn模式和standalone模式不同, ...
- spark on mesos 两种运行模式
spark on mesos 有粗粒度(coarse-grained)和细粒度(fine-grained)两种运行模式,细粒度模式在spark2.0后开始弃用. 细粒度模式 优点 spark默认运行的 ...
- Spark on YARN运行模式(图文详解)
不多说,直接上干货! 请移步 Spark on YARN简介与运行wordcount(master.slave1和slave2)(博主推荐) Spark on YARN模式的安装(spark-1.6. ...
- 【Hadoop】YARN 原理、MR本地&YARN运行模式
1.基本概念 2.YARN.MR交互流程 3.源码解读
- 理解Spark运行模式(一)(Yarn Client)
Spark运行模式有Local,STANDALONE,YARN,MESOS,KUBERNETES这5种,其中最为常见的是YARN运行模式,它又可分为Client模式和Cluster模式.这里以Spar ...
- Spark On Yarn搭建及各运行模式说明
之前记录Yarn:Hadoop2.0之YARN组件,这次使用Docker搭建Spark On Yarn 一.各运行模式 1.单机模式 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spa ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
随机推荐
- bzoj 2565: 最长双回文串 回文自动机
题目: Description 顺序和逆序读起来完全一样的串叫做回文串.比如acbca是回文串,而abc不是(abc的顺序为"abc",逆序为"cba",不相同 ...
- vue 打包去掉console.log
在webpack.prod.conf.js 文件中将设置修改为 先全局找到 UglifyJsPlugin 然后修改为: new UglifyJsPlugin({ uglifyOptions: { ...
- 洛谷【P2201】数列编辑器
我对模拟的理解:http://www.cnblogs.com/AKMer/p/9064018.html 题目传送门:https://www.luogu.org/problemnew/show/P220 ...
- SQL中replace函数
string sql1 = "select price from dbo.eazy_farm where REPLACE(title,' ','')='" + cainame + ...
- PTA实验作业-01
一.PTA实验作业 本周要求挑3道题目写设计思路.调试过程.设计思路用伪代码描述.题目选做要求: 顺序表选择一题(6-2,6-3,7-1选一题),代码必须用顺序结构抽象数据类型封装 单链表选择一题(6 ...
- HDOJ1213(并查集)
set容器中的值互异,非常好用. 水题,直接贴代码了 #include<iostream> #include<cstdio> #include<set> using ...
- JSP介绍(4)--- JSP 过滤器
过滤器是可用于 Servlet 编程的 Java 类,可以实现以下目的: 在客户端的请求访问后端资源之前,拦截这些请求. 在服务器的响应发送回客户端之前,处理这些响应. 过滤器通过 Web 部署描述符 ...
- python的WeakKeyDictionary类和weakref模块的其他函数
python的WeakKeyDictionary类和weakref模块的其他函数 # -*- coding: utf-8 -*- # @Author : ydf # @Time : 2019/6/13 ...
- (cdh)hive 基础知识 名词详解及架构
过程 启动 hive 之后出现的 CLI 是查询任务的入口,CLI 提交任务给 Driver Driver 接收到任务后调用 Compiler,Executor,Optimizer 将 SQL 语句转 ...
- LAMP 1.6 Discuz打开错误
打开discuz失败, ps aux |grep mysql ps aux |grep httpd 查看mysql apache有没有打开. 重启mysql service mysqld restar ...