deeplearning.ai 卷积神经网络 Week 2 深度卷积网络:实例研究 听课笔记
1. Case study:学习经典网络的原因是它们可以被迁移到其他任务中。
1.1)几种经典的网络:
a)LeNet-5(LeCun et al., 1998. Gradient-based learning applied to document recognition,NG建议重点读II部分,泛读III部分):这个网络大概60k个参数。那个时期习惯于用average pooling(现在是max pooling),sigmoid/tanh(现在是ReLU),最后的分类函数现在已经不常用了(现在是Softmax)。可以看到随着网络越来越深,图片越来越小,通道数越来越多。

b)AlexNet(Krizhevsky et al., 2012. ImageNet classification with deep convolutional neural networks.):比LeNet大很多,大概6000万参数。其次,使用了ReLU激活函数。作者使用了非常复杂的方法在两个GPU上训练(这些层被分别拆分到两个不同的GPU上,并且还有一些两块GPU数据通信的方法)。原文还提出了局部响应归一化层(Local Response Normalization,LRN),这种层用的不多,后来的研究者论证它没什么用。

c)VGG-16(Simonyan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition.)16层(有参数的,POOL不算),1.38亿个参数。本文很独特的提出,与其有那么多超参数,不如所有卷积层、池化层的超参数都是一样的。下图中X2的意思是重复了两次。

1.2)ResNet (He et al., Deep residual networks for image recognition):这是为了解决很深的网络(多达100层)因为存在梯度消失和梯度爆炸的问题而难训练的问题。基本思想是跳过某一层或者若干曾网络,直接把数据传递到后面的层。理论上随着网络深度的增加,训练误差应该越来越小。但对于一般的网络(ResNet论文里叫Plain network),随着层数的增加,训练误差会先减小后增加,这是由于很深的网络难优化。ResNet克服了这个问题,即使训练上百上千层的网络,训练误差也是越来越小,这种方法很有效的解决了梯度消失和梯度爆炸的问题。
Residual block:
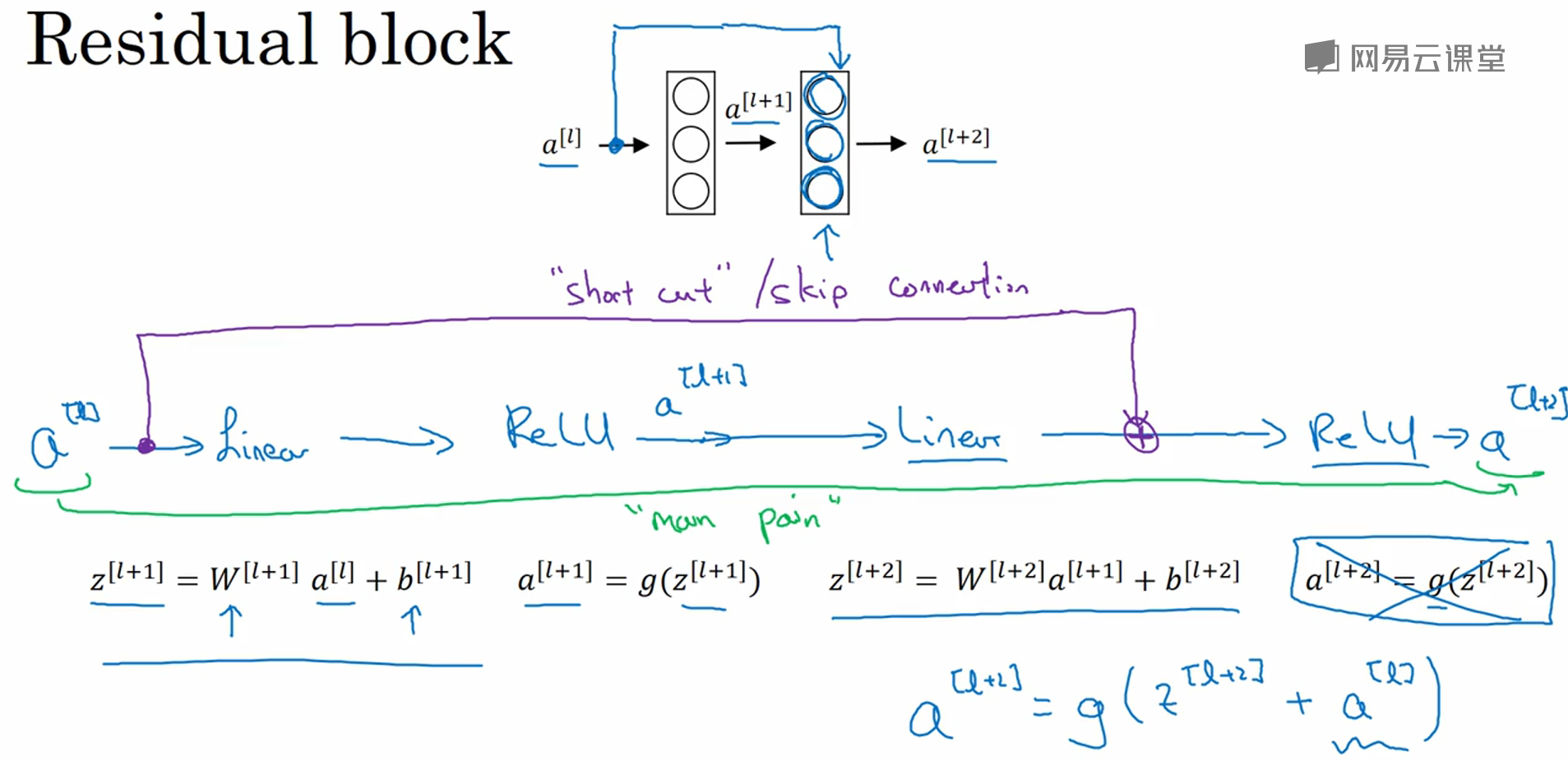
原本的前向传播:z[l+1] = W[l+1]a[l]+b[l+1],a[l+1] = g(z[l+1]),z[l+2] = W[l+2]a[l+1]+b[l+2],a[l+2] = g(z[l+2]);
加入short cut (或者叫skip connection)之后,a[l+2] = g(z[l+2]+a[l]);这里的a[l]就是在原来的前向传播中加入了一个residual。
ResNet的一个例子:每两层构成一个Residual block,一共五个串联。

为什么ResNet有效?我们把 a[l+2] = g(z[l+2]+a[l]) 展开可以得到 a[l+2] = g(W[l+2]a[l+1]+b[l+2] + a[l]),如果采用了L2正则化(也就是权重衰减(weight decay)),W[l+2]会变小,如果W[l+2]=0,b[l+2]=0,则a[l+2] = g(a[l]),如果用ReLU激活函数,所有激活值非负,则a[l+2] = a[l],这意味着多出来的层无效,NG课程里的原话是:"the identity function is easy for residual block to learn."所以ResNet的效率不逊色于更简单的神经网络,而大部分情况下,它很幸运的还要表现的更好。
另外一个需要注意的是,z[l+2]+a[l] 这一步操作需要二者维度相同,所以在ResNet中,一般使用"same" convolution(也就是先padding,保证输入和输出的尺寸一致),如果二者维度不同(比如中间加了池化层),则会增加一个矩阵变换 z[l+2]+Wsa[l] 。
1.3)Inception(Szegedy et al., 2014. Going deeper with convolutions)。在实际搭建网络的时候,我们需要决定滤波器的大小(例如是1x1还是3x3还是5x5)、要不要添加池化层,Inception network的想法是把这些滤波器和池化层全做一遍,然后堆叠起来,一起丢给神经网络让它自己优化选择。
比如在下面这个例子中,同时使用了64个1x1的filter、128个3x3的filter、32个5x5的filter和32个MAX池化层(为了统一大小,这里都使用了"same"操作),然后把结果堆叠起来,得到256个通道的输出。
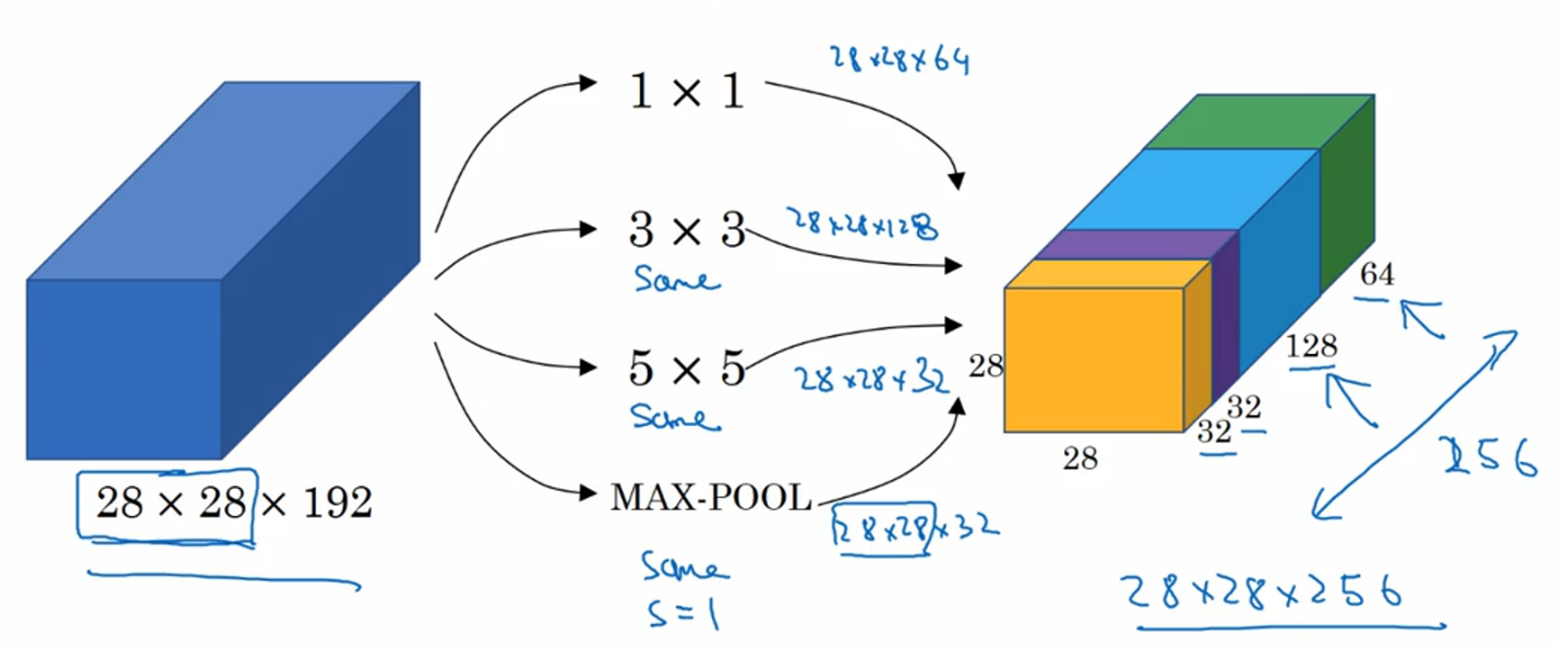
这种思路带来的问题是计算量太大(比如上面例子中的32个5x5的filter进行了28*28*32*5*5*192=120million),解决的办法是用1x1的filter来减少运算量。这里先讲一下1x1的卷积
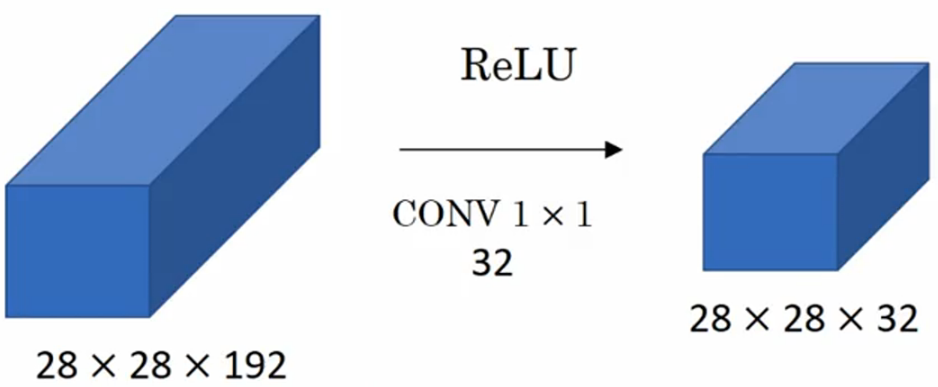
1x1卷积:最主要的目的是压缩通道数量,降低运算量。比如下面例子中,32个1x1x192的filter(filter的通道数和输入相同)和28x28x192的输入卷积得到28x28x32的输出,把输入的通道数从192压缩成32。所以池化层是压缩图像大小,而1x1卷积层是压缩通道数量。
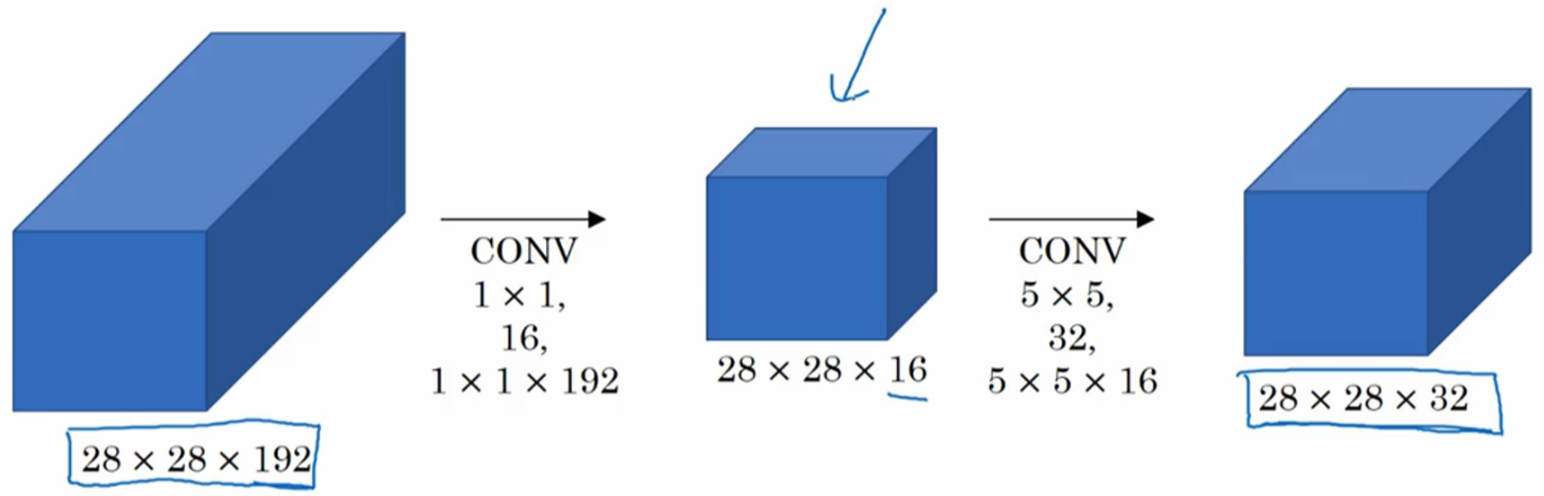
回到用1x1卷积层解决Inception network运算量大的问题,如下图所示,在进行32个5x5x16的filter运算之前,先用16个1x1x192的filter把输入压缩成28x28x16的大小(这也被称做bottleneck layer),这时候的计算量是28*28*16*1*1*192+28*28*32*5*5*16=12.4million,为之前的十分之一。
下图展示了一个典型的Inception module,使用多种不同的filter,并用1x1的卷积层降低通道数,最后把结果堆叠起来:

最后,Inception这个名字的由来是《盗梦空间(Inception)》,因为里面有句台词:“We need to go deeper.”
2. 迁移学习(Transfer learning)
相比于从头开始训练,把别人已经训练好的网络结构作为预训练,然后迁移到自己的任务上,会极大的加快项目进度。
核心思想就是:越多的数据集支持训练越大的网络。如果自己的任务只有很小的数据集,那么可以把前人的网络都固定住,只替换并训练最后的softmax输出层;如果自己有中等大小的数据集,可以固定网络的前部分,只替换并训练最后若干层网络;如果自己有很大的数据集,可以把前人的网络的参数作为初始值(这时候就不需要随机初始化参数了),把所有层都训练一遍。自己有极其庞大的数据集,才值得完全从头开始训练。
3. 数据扩充(Data augmentation)
在计算机视觉领域,越多的数据会带来越好的效果(其他领域可能非常多的数据不会带来显著提高)。
常用的手段:
1)垂直镜像;
2)随机修剪(random cropping),随机剪裁出原图的一部分。
3)旋转;
4)Shearing;
5)Local warping;
6)Color shifting,给RGB三通道加上各自的bias(比如RGB三通道分别+20,-20,+20)。更高阶的方式是用PCA(主成分分析),AlexNet的论文里提出的,有时被称作“PCA color augmentation”,基本想法是如果图片呈现紫色即主要成分是红色和蓝色,绿色相对较少,则PCA颜色增强算法会把红色和蓝色减小很多,使总体三通道保持一致。
在实际部署中,数据集存在硬盘上,有一个CPU线程不断从硬盘读图片并且做data augmentation,构成batch数据或者mini-batch数据,这些数据会被传递给其他线程或者进程在CPU或者GPU上做训练。一般数据的读取和训练是并行实现的。
4. 计算机视觉现状
机器学习的系统有两个知识来源:1)带标签的数据(labeled data);2)手工提取的特征(hand engineered features/network architecture/other omponents)。如果有海量的数据,人们倾向于用更简单的算法,以及更少的手工工程(hand engineering);相反,当没有那么多数据时,会更多的利用手工工程,大部分的机器学习问题都是归在这一类。
对于计算机视觉来说,这是要实现非常复杂的功能,所以我们总是感觉我们没有足够的数据。这也是为什么从历史甚至到现在,计算机视觉都更多的依赖手工工程。这也是为什么计算机视觉有非常复杂的网络架构,因为在没有足够的数据的情况下,还是要花更多的精力来进行架构设计,以此获得更好的表现。
如何在benchmarks上获得更好的表现?NG给的建议是:1)同时训练几个网络,对它们的结果取均值,这可以提高1%、2%的表现(甚至更好); 2)multi-crop at test time,在测试集上应用data augmentation,一种比较著名的方式是10-crop,它从一张图片生成十张来做预测,然后对结果平均。NG说如果有足够的计算资源,可以做这些事情,但他自己不倾向于在构建实际产品时使用这些方法。
另外的关于开源代码的建议:1)使用已经发表的论文的架构,计算机视觉领域,在某个任务上表现很好的架构在其他视觉问题上表现也通常很好。2)如果可能的话,可以使用开源代码的部署。3)把开源代码作为预训练,在自己的数据集上微调。
deeplearning.ai 卷积神经网络 Week 2 深度卷积网络:实例研究 听课笔记的更多相关文章
- 卷积神经网络CNN与深度学习常用框架的介绍与使用
一.神经网络为什么比传统的分类器好 1.传统的分类器有 LR(逻辑斯特回归) 或者 linear SVM ,多用来做线性分割,假如所有的样本可以看做一个个点,如下图,有蓝色的点和绿色的点,传统的分类器 ...
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达deepLearning.ai循环神经网络RNN学习笔记_看图就懂了!!!(理论篇)
前言 目录: RNN提出的背景 - 一个问题 - 为什么不用标准神经网络 - RNN模型怎么解决这个问题 - RNN模型适用的数据特征 - RNN几种类型 RNN模型结构 - RNN block - ...
- 吴恩达deepLearning.ai循环神经网络RNN学习笔记_没有复杂数学公式,看图就懂了!!!(理论篇)
本篇文章被Google中国社区组织人转发,评价: 条理清晰,写的很详细! 被阿里算法工程师点在看! 所以很值得一看! 前言 目录: RNN提出的背景 - 一个问题 - 为什么不用标准神经网络 - RN ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面 听课笔记
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- 卷积神经网络实战-----0001(移植卷积神经网络c++ to python or java)
1. https://github.com/174high/simple_cnn 自己fork的 2. https://github.com/can1357/simple_cnn 最初始的 3. ...
- SIGAI深度学习第九集 卷积神经网络3
讲授卷积神经网络面临的挑战包括梯度消失.退化问题,和改进方法包括卷积层.池化层的改进.激活函数.损失函数.网络结构的改 进.残差网络.全卷机网络.多尺度融合.批量归一化等 大纲: 面临的挑战梯度消失问 ...
- deeplearning.ai 卷积神经网络 Week 1 卷积神经网络 听课笔记
1. 传统的边缘检测(比如Sobel)手工设计了3*3的filter(或者叫kernel)的9个权重,在深度学习中,这9个权重都是学习出来的参数,会比手工设计的filter更好,不但可以提取90度.0 ...
- deeplearning.ai 卷积神经网络 Week 1 卷积神经网络
1. 传统的边缘检测(比如Sobel)手工设计了3*3的filter(或者叫kernel)的9个权重,在深度学习中,这9个权重都是学习出来的参数,会比手工设计的filter更好,不但可以提取90度.0 ...
随机推荐
- Gulp 的简单使用(原创)
1.安装nodejs 安装省略 npm的全称是Node Package Manager,是随同NodeJS一起安装的包管理和分发工具,它很方便让JavaScript开发者下载.安装.上传以及管理已经安 ...
- [array] leetcode - 31. Next Permutation - Medium
leetcode - 31. Next Permutation - Medium descrition Implement next permutation, which rearranges num ...
- 利用VSTS跟Kubernetes进行CI/CD
准备VSTS管理环境 首先我们需要到www.visualstudio.com下申请好的VSTS账号,然后在账号下创建一个用Git作为代码管理的项目 创建好项目后我们就可以利用git clone将代码库 ...
- express整合webpack的打包文件dist
对于我来说,第一次接触前后端整合问题的小白,刚开始是一脸懵逼,这个问题整整坑了我一个晚上加一个早上,现在写出来总结: 前端开发:vue-cli+webpack: 后台开发:nodejs框架expres ...
- SpringBoot_02_servlet容器配置
二.参考资料 1.Spring boot 自定义端口 2.Spring Boot的Web配置(九):Tomcat配置和Tomcat替换
- 关于java字节流的read()方法返回值为int的思考
我们都知道java中io操作分为字节流和字符流,对于字节流,顾名思义是按字节的方式读取数据,所以我们常用字节流来读取二进制流(如图片,音乐 等文件).问题是为什么字节流中定义的read()方法返回值为 ...
- Android studio Error:org.gradle.api.internal.tasks.DefaultTaskInputs$TaskInputUnionFileCollection cannot be cast to
http://blog.csdn.net/FlyRabbit_1/article/details/74536317 Error:org.gradle.api.internal.tasks.Defaul ...
- Sql Server 里的向上取整、向下取整、四舍五入取整的实例!
http://blog.csdn.net/dxnn520/article/details/8454132 =============================================== ...
- java多线程(五)-访问共享资源以及加锁机制(synchronized,lock,voliate)
对于单线程的顺序编程而言,每次只做一件事情,其享有的资源不会产生什么冲突,但是对于多线程编程,这就是一个重要问题了,比如打印机的打印工作,如果两个线程都同时进行打印工作,那这就会产生混乱了.再比如说, ...
- SpringMvc开发步骤
1.导入基本jar包 2.在Web.xml中配置DispatcherServlet <!-- 配置 DispatcherServlet --> <servlet> <se ...