ShuffleNet总结
在2017年末,Face++发了一篇论文ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices讨论了一个极有效率且可以运行在手机等移动设备上的网络结构——ShuffleNet。这个英文名我更愿意翻译成“重组通道网络”,ShuffleNet通过分组卷积与\(1 \times 1\)的卷积核来降低计算量,通过重组通道来丰富各个通道的信息。这个论文的mxnet源码的开源地址为:MXShuffleNet。
分组卷积与核大小对计算量的影响
论文说中到“We propose using pointwise group convolutions to reduce computation complexity of 1 × 1 convolutions”,那么为什么用分组卷积与小的卷积核会减少计算的复杂度呢?先来看看卷积在编程中是如何实现的,Caffe与mxnet的CPU版本都是用差不多的方法实现的,但Caffe的计算代码会更加简洁。
不分组且只有一个样本
在不分组与输入的样本量为1(batch_size=1)的条件下,输出一个通道上的一个点是卷积核会与所有的通道卷积之积,如图1所示:
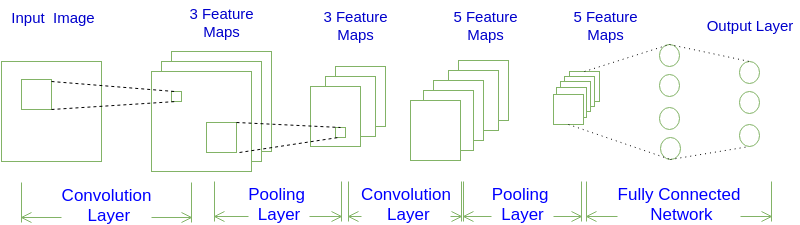
图1 输入层(第一层)只有一个通道,那个第二层一个通道上的点是第一层通道相应区域与相应卷积核的卷积,第三层一个通道上的点是与第二层所有通道上相应区域与相应卷积核的卷积,而且对于输出通道每个输入通道对应的卷积核是不一样的,不同的输出通道也有不同的卷积核,所以说卷积核的参数量是$C_{out} \times C_{in} \times K_h \times K_w$
在Caffe的计算方法中,先要将输入张量为\(n \times C_{in} \times H_{in} \times W_{in}\)(n是batch_size)转化为一个$ \left(C_{in} \times K_h \times K_w\right) \times \left(H_{in} \times W_{in}\right)\(的矩阵,这个过程叫**im2col**。最后得到的输出张量为\)n \times C_{out} \times H_{in} \times W_{in}$。
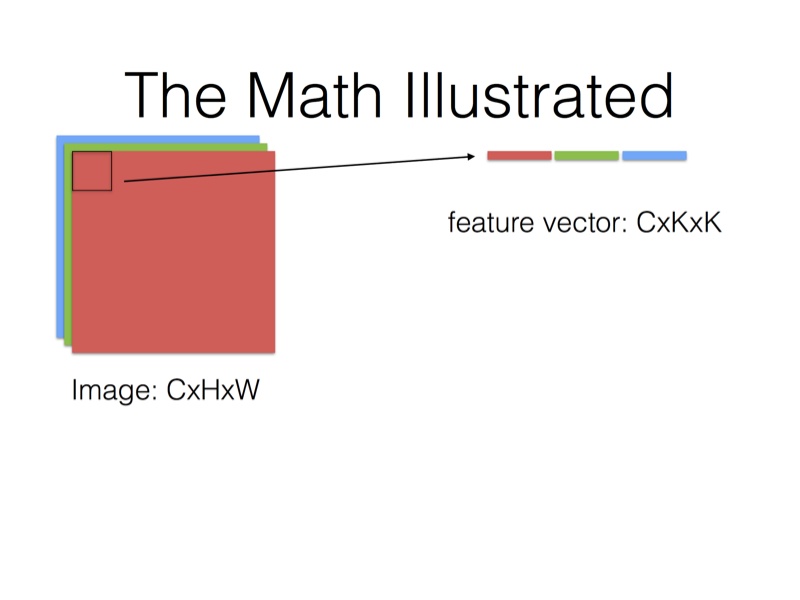
图2 输入的所有通道按卷积核的大小提取出来排列成一行,要注意的是在这只是示意图,在实际的程序中,一般会排成一列,因为在防问数据时会一个通道一个通道地访问的。输出一个点要输出的数据有$C_{in} \times K_h \times K_w$个。
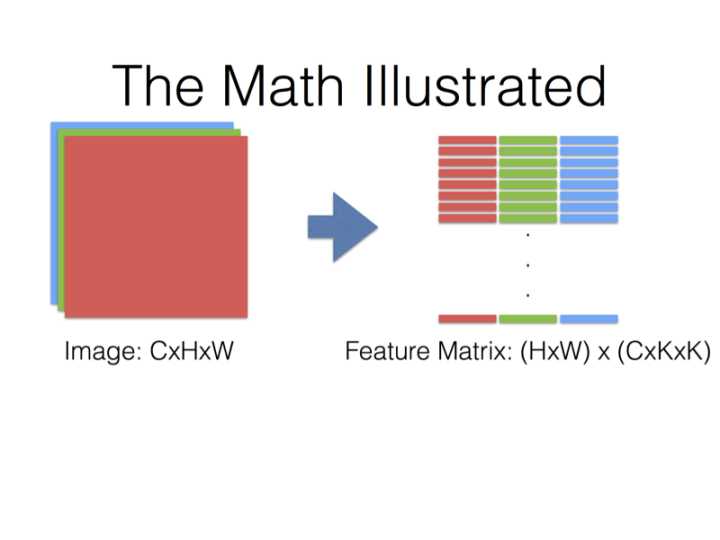
图3 输出一个通道就有$H_{out} \times W_{out}$个点,而且在程序中同一个通道(图中的同一个颜色)的内容是按行排列的,所以说转换出来的的矩阵是图中$ \left(C_{in} \times K_h \times K_w\right) \times \left(H_{out} \times W_{out}\right)$矩阵的转置。
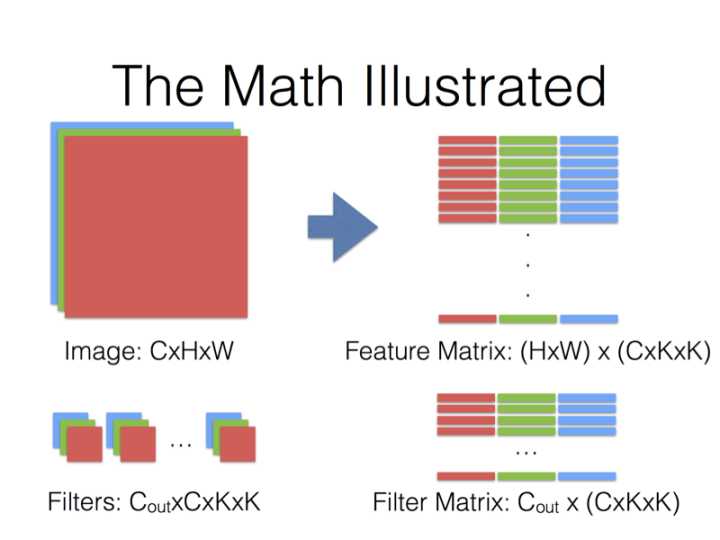
图4 同样卷积核(Filter)也要Reshape成$C_{out} \times \left( C_{in} \times K_h \times K_w \right)$ 的矩阵
得到的两个矩阵Feature与Filter相乘得到输出矩阵Output,再Reshape成\(C_{out} \times C_{in} \times H_{out} \times W_{out}\)张量:
\]
现在的计算技术中,对方长度为\(n\)的方阵,计算量能从\(n^3\)代码到\(n^{2.376}\),最小的复杂度现在仍然未知,本文为了方便计算量就以\(n^3\)为基准。所以式(1.1)的矩阵计算最普通的计算量\(Computation\)是:
\]
从式(1.2)中可以看出来,卷积核的大小对计算量影响是很大的,\(3 \times 3\)的卷积核比\(1 \times 1\)的计算量要大\(3^4=81\)倍。
分组且只有一个样本
什么叫做分组,就是将输入与输出的通道分成几组,比如输出与输入的通道数都是4个且分成2组,那第1、2通道的输出只使用第1、2通道的输入,同样那第3、4通道的输出只使用第1、2通道的输入。也就是说,不同组的输出与输入没有关系了,减少联系必然会使计算量减小,但同时也会导致信息的丢失。
当分成g组后,一层参数量的大小由\(Filter_{C_{out} \times \left( C_{in} \times K_h \times K_w \right)}\)变成\(Filter_{C_{out} \times \left( C_{in} \times K_h \times K_w / g \right)}\)。Feature Matrix的大小虽然没发生变化,但是每一组的使用量是原来的$1/g,Filter也只用到所有参数的\(1/g\)\(。然后再循环计算\)g$次(同时FeatureMatrix与FilterMatrix要有地址偏移),那么计算公式与计算量的大小为:
\]
\]
所以,分成\(g\)组可以使参数量变成原来的\(1/g\),计算量是原来的\(1/g^2\)。
多个样本输入
为了节省内存,多个样本输入的时候,上述的所有过程都不会改变,而是每一个样本都运行一次上述的过程。
以上只是最简单、粗略的分析,实际上计算效率的提升并不会有上述这么多,一方面因为im2col会消耗与矩阵运算差不多的时间,另一方面因为现代的blas库优化了矩阵运算,复杂度并没有上述分析的那么多,还有计算过程for循环是比较耗时的指令,即使用openmp也不能优化卷积的计算过程。
交换通道(Shuffle Channels)
在上面我提到过,分组会导致信息的丢失,那么有没有办法来解决这个问题呢?这个论文给出的方法就是交换通道,因为在同一组中不同的通道蕴含的信息可能是相同的,如果在不同的组之后交换一些通道,那么就能交换信息,使得各个组的信息更丰富,能提取到的特征自然就更多,这样是有利于得到更好的结果。
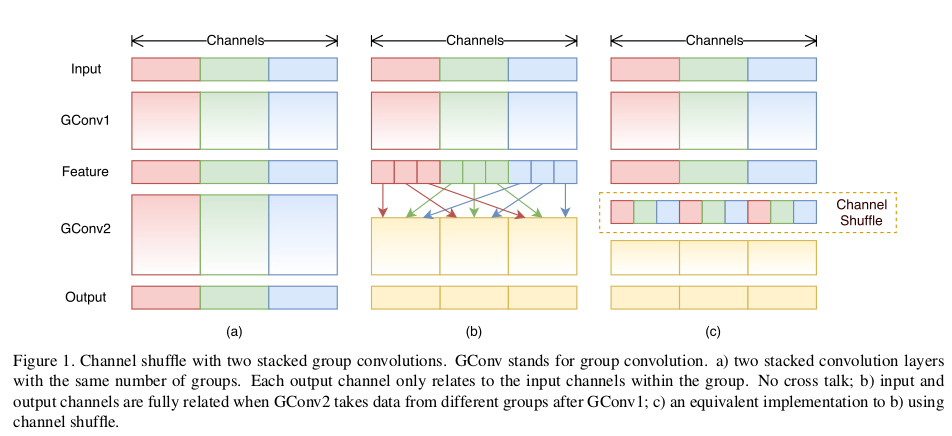
图5 分组交换通道的示意图,a)是不交换通道但是分成3组了,要吧看到,不同的组是完全独立的;b)每组内又分成3组,不分别交换到其它组中,这样信息就发生了交换,c)这个是与b)是等价的。
ShuffleUnit
ShuffleUnit的设计参考了ResNet,总有两个基本单元,两人个基本单元功能不一样,将他们组合起来就可以得到ShuffleNet。这样的设计可以在增加网络的深度(比mobilenet深约一倍)的同时,减少参数总量与计算量(本人运行Cifar10时,速度大约是molibenet的10倍)。
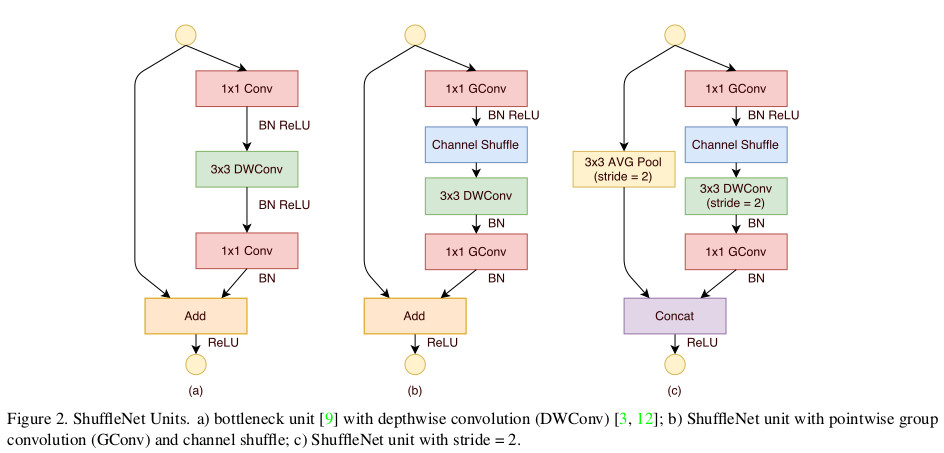
图6 b)与c)是两人个ShuffleNet的基本单元,这两个单元是参考了a)的设计,单元b)输出与输入的Shape一致,只是丰富了每个通道的信息,单元c)增加了一倍的通道数且输出的$H_{out}$、$W_{out}$ 比$H_{in}$、$W_{in}$减少了一倍
源码解读
def combine(residual, data, combine):
if combine == 'add':
return residual + data
elif combine == 'concat':
return mx.sym.concat(residual, data, dim=1)
return None
add是代表图6中的单元b),concat是代表图6中的单元c)。
def channel_shuffle(data, groups):
data = mx.sym.reshape(data, shape=(0, -4, groups, -1, -2))
data = mx.sym.swapaxes(data, 1, 2)
data = mx.sym.reshape(data, shape=(0, -3, -2))
return data
这个函数就是交换通道的函数,函数的第一行data = mx.sym.reshape(data, shape=(0, -4, groups, -1, -2))是将输入为\(n \times C_{in} \times H_{in} \times W_{in}\)reshape成\(n \times (C_{in}/g) \times g\times H_{in} \times W_{in}\),要注意的是mxnet中reshape不会改变张量在内存中的排列顺序。至于要mxnet中的0,-1,-2,-3,-4的具体意义可以这样看到:
import mxnet as mx
print(help(mx.sym.reshape))
可以看到输出以下(只提取出一小部分,其余的可用上述方法查看),这里有各个参数的具体意义:
- ``0`` copy this dimension from the input to the output shape.
- ``-1`` infers the dimension of the output shape by using the remainder of the input dimensions
- ``-2`` copy all/remainder of the input dimensions to the output shape.
- ``-3`` use the product of two consecutive dimensions of the input shape as the output dimension.
- ``-4`` split one dimension of the input into two dimensions passed subsequent to -4 in shape (can contain -1).
函数的第二行是交换第一与第二个维度,那么现在这个symbol的符号的shape就变成了\(n \times g \times (C_{in}/g) \times H_{in} \times W_{in}\)。这里的第零个维度是\(n\)。要注意的是交换维度改变了张量在内存中的排列顺序,改变了内存中的顺序实现上就是完成了图5c)中的Channel Shuffle操作,不同的颜色代码数据在原来内存中的位置。
函数的最后一行合并了第一与第二个维度,输出的张量与输入的张量shape都是\(n \times C_{in} \times H_{in} \times W_{in}\)。
def shuffleUnit(residual, in_channels, out_channels, combine_type, groups=3, grouped_conv=True):
if combine_type == 'add':
DWConv_stride = 1
elif combine_type == 'concat':
DWConv_stride = 2
out_channels -= in_channels
first_groups = groups if grouped_conv else 1
bottleneck_channels = out_channels // 4
data = mx.sym.Convolution(data=residual, num_filter=bottleneck_channels,
kernel=(1, 1), stride=(1, 1), num_group=first_groups)
data = mx.sym.BatchNorm(data=data)
data = mx.sym.Activation(data=data, act_type='relu')
data = channel_shuffle(data, groups)
data = mx.sym.Convolution(data=data, num_filter=bottleneck_channels, kernel=(3, 3),
pad=(1, 1), stride=(DWConv_stride, DWConv_stride), num_group=groups)
data = mx.sym.BatchNorm(data=data)
data = mx.sym.Convolution(data=data, num_filter=out_channels,
kernel=(1, 1), stride=(1, 1), num_group=groups)
data = mx.sym.BatchNorm(data=data)
if combine_type == 'concat':
residual = mx.sym.Pooling(data=residual, kernel=(3, 3), pool_type='avg',
stride=(2, 2), pad=(1, 1))
data = combine(residual, data, combine_type)
return data
ShuffleUnit这个函数实现上是实现图6的b)与c),add对应成b),comcat对应于c)。
def make_stage(data, stage, groups=3):
stage_repeats = [3, 7, 3]
grouped_conv = stage > 2
if groups == 1:
out_channels = [-1, 24, 144, 288, 567]
elif groups == 2:
out_channels = [-1, 24, 200, 400, 800]
elif groups == 3:
out_channels = [-1, 24, 240, 480, 960]
elif groups == 4:
out_channels = [-1, 24, 272, 544, 1088]
elif groups == 8:
out_channels = [-1, 24, 384, 768, 1536]
data = shuffleUnit(data, out_channels[stage - 1], out_channels[stage],
'concat', groups, grouped_conv)
for i in range(stage_repeats[stage - 2]):
data = shuffleUnit(data, out_channels[stage], out_channels[stage],
'add', groups, True)
return data
def get_shufflenet(num_classes=10):
data = mx.sym.var('data')
data = mx.sym.Convolution(data=data, num_filter=24,
kernel=(3, 3), stride=(2, 2), pad=(1, 1))
data = mx.sym.Pooling(data=data, kernel=(3, 3), pool_type='max',
stride=(2, 2), pad=(1, 1))
data = make_stage(data, 2)
data = make_stage(data, 3)
data = make_stage(data, 4)
data = mx.sym.Pooling(data=data, kernel=(1, 1), global_pool=True, pool_type='avg')
data = mx.sym.flatten(data=data)
data = mx.sym.FullyConnected(data=data, num_hidden=num_classes)
out = mx.sym.SoftmaxOutput(data=data, name='softmax')
return out
这两个函数可以直接得到作者在论文中的表:
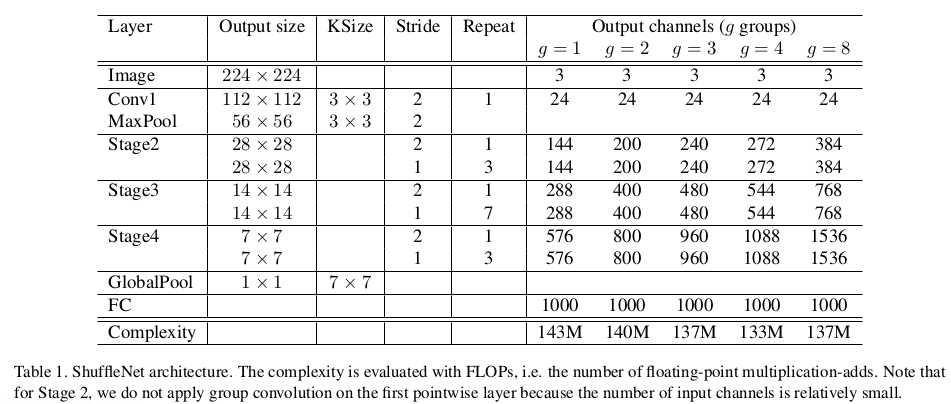
图7
结果比较
论文后面用了种实验证明这两个技术的有效性,且证实了ShuffleNet的优秀,这里就不细说,看论文后面的表就能一目了然。
【防止爬虫转载而导致的格式问题——链接】:
http://www.cnblogs.com/heguanyou/p/8087422.html
ShuffleNet总结的更多相关文章
- 机器视觉:MobileNet 和 ShuffleNet
虽然很多CNN模型在图像识别领域取得了巨大的成功,但是一个越来越突出的问题就是模型的复杂度太高,无法在手机端使用,为了能在手机端将CNN模型跑起来,并且能取得不错的效果,有很多研究人员做了很多有意义的 ...
- 轻量架构ShuffleNet V2:从理论复杂度到实用设计准则
转自:机器之心 近日,旷视科技提出针对移动端深度学习的第二代卷积神经网络 ShuffleNet V2.研究者指出过去在网络架构设计上仅注重间接指标 FLOPs 的不足,并提出两个基本原则和四项准则来指 ...
- 【论文阅读】ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet: An Extremely Efficient Convolutional Neural Network for MobileDevices
- 面向移动端的轻量级神经网络模型mobilenet、ShuffleNet
翻译: http://baijiahao.baidu.com/s?id=1565832713111936&wfr=spider&for=pc http://baijiahao.baid ...
- ShuffleNet
ShuffleNet (An Extremely Efficient Convolutional Neural Network for Mobile Devices) —— Face++ shuffl ...
- mobienet, shufflenet
参考github上各位大神的代码 mobilenet和shufflenet,实现起来感觉还是各种问题. mobilenet目前使用的代码来自这里:https://github.com/BVLC/caf ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- 图像分类丨浅析轻量级网络「SqueezeNet、MobileNet、ShuffleNet」
前言 深度卷积网络除了准确度,计算复杂度也是考虑的重要指标.本文列出了近年主流的轻量级网络,简单地阐述了它们的思想.由于本人水平有限,对这部分的理解还不够深入,还需要继续学习和完善. 最后我参考部分列 ...
- ShuffleNet:
ShuffleNet算法详解 论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices ...
随机推荐
- [转载] Java NIO教程
转载自并发编程网 – ifeve.com http://ifeve.com/java-nio-all/ 关于通道(Channels).缓冲区(Buffers).选择器(Selectors)的故事. 从 ...
- PullToRefreshListView插件初次进入页面自动刷新
只要将PullToRefreshListView源码中的: @Override protected void onRefreshing(final boolean doScroll) { /** * ...
- 用JAVA中BufferedImage画出漂亮的验证码点击变化
如果我们想用JAVA中BufferedImage画出漂亮的验证码点击变化怎么实现呢,类似这样: 点击变化,以下是实现过程,直接上代码: 首先前台:<i><img style=&quo ...
- webpack 3.X学习之基本配置
创建配置文件webpack.config.js 在根目录在手动创建webpack.config.js,配置基本模板 module.exports ={ entry:{}, output:{}, mod ...
- 静态频繁子图挖掘算法用于动态网络——gSpan算法研究
摘要 随着信息技术的不断发展,人类可以很容易地收集和储存大量的数据,然而,如何在海量的数据中提取对用户有用的信息逐渐地成为巨大挑战.为了应对这种挑战,数据挖掘技术应运而生,成为了最近一段时期数据科学的 ...
- Flash真的老了,HTML5将取代其地位
简单讲一些网页开发的趋势吧! Flash老了 Flash是一个落后于时代的技术,靠对客户端的高资源占用率来获取传输过程的低带宽占用. Flash不再安全 Flash是一个落后于时代的技术,靠对客户端的 ...
- c语言的内存分析
1. 进制 1. 什么是进制 ● 是一种计数的方式,数值的表示形式 汉字:十一 十进制:11 二进制:1011 八进制:13 ● 多种进制:十进制.二进制.八进制.十六进制.也就是说,同一个 ...
- linux网络、性能相关命令
netstat -tunpl #查看进程列表 top #查看系统资源统计 服务器速度测试 ping 123.57.92.9 -t 每一个被发送出的IP信息包都有一个TTL域,该域被设置为一个较高的数值 ...
- opencv摄像头捕获图像
#include <iostream> #include <opencv2/opencv.hpp> using namespace cv; using namespace st ...
- [Machine Learning]学习笔记-线性回归
模型 假定有i组输入输出数据.输入变量可以用\(x^i\)表示,输出变量可以用\(y^i\)表示,一对\(\{x^i,y^i\}\)名为训练样本(training example),它们的集合则名为训 ...