robotframework的学习笔记(十六)----robotframework标准库String
官方文档:http://robotframework.org/robotframework/latest/libraries/String.html
Introduction
A test library for string manipulation and verification.String is Robot Framework's standard library for manipulating strings
Following keywords from BuiltIn library can also be used with strings:
- Catenate
- Get Length
- Length Should Be
- Should (Not) Be Empty
- Should (Not) Be Equal (As Strings/Integers/Numbers)
- Should (Not) Match (Regexp)
- Should (Not) Contain
- Should (Not) Start With
- Should (Not) End With
- Convert To String
- Convert To Bytes
Altogether 30 keywords.
| Keyword | Arguments | Documentation | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Convert To Lowercase | string |
Converts string to lowercase. Examples:
New in Robot Framework 2.8.6. |
||||||||||||||||||||||||||||||
| Convert To Uppercase | string |
Converts string to uppercase. Examples:
New in Robot Framework 2.8.6. |
||||||||||||||||||||||||||||||
| Decode Bytes To String | bytes, encoding,errors=strict |
Decodes the given
Examples:
Use Encode String To Bytes if you need to convert Unicode strings to byte strings, and Convert To String in |
||||||||||||||||||||||||||||||
| Encode String To Bytes | string, encoding,errors=strict |
Encodes the given Unicode
Examples:
Use Convert To Bytes in |
||||||||||||||||||||||||||||||
| Fetch From Left | string, marker |
Returns contents of the If the See also Fetch From Right, Split String and Split String From Right. |
||||||||||||||||||||||||||||||
| Fetch From Right | string, marker |
Returns contents of the If the See also Fetch From Left, Split String and Split String From Right. |
||||||||||||||||||||||||||||||
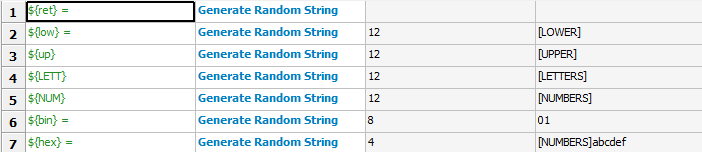
| Generate Random String | length=8, chars=[LETTERS][NUMBERS] |
Generates(生成) a string with a desired(期望) The population sequence
Examples:
log: 20170719 11:20:59.200 : INFO : ${ret} = bjgo5Rz7 |
||||||||||||||||||||||||||||||
| Get Line | string, line_number |
Returns the specified line from the given Line numbering starts from 0 and it is possible to use negative indices(负数) to refer to lines from the end. The line is returned without the newline character. Examples:
Use Split To Lines if all lines are needed. |
||||||||||||||||||||||||||||||
| Get Line Count | string |
Returns and logs the number of lines in the given string. |
||||||||||||||||||||||||||||||
| Get Lines Containing String | string, pattern,case_insensitive=False |
Returns lines of the given The The match is case-sensitive by default, but giving Lines are returned as one string catenated back together with newlines. Possible trailing newline is never returned. The number of matching lines is automatically logged. Examples:
See Get Lines Matching Pattern and Get Lines Matching Regexp if you need more complex pattern matching. |
||||||||||||||||||||||||||||||
| Get Lines Matching Pattern | string, pattern,case_insensitive=False |
Returns lines of the given The
A line matches only if it matches the The match is case-sensitive by default, but giving Lines are returned as one string catenated back together with newlines. Possible trailing newline is never returned. The number of matching lines is automatically logged. Examples:
See Get Lines Matching Regexp if you need more complex patterns and Get Lines Containing String if searching literal strings is enough. |
||||||||||||||||||||||||||||||
| Get Lines Matching Regexp | string, pattern,partial_match=False |
Returns lines of the given See BuiltIn.Should Match Regexp for more information about Python regular expression syntax in general and how to use it in Robot Framework test data in particular. By default lines match only if they match the pattern fully, but partial matching can be enabled by giving the If the pattern is empty, it matches only empty lines by default. When partial matching is enabled, empty pattern matches all lines. Notice that to make the match case-insensitive, you need to prefix the pattern with case-insensitive flag Lines are returned as one string concatenated back together with newlines. Possible trailing newline is never returned. The number of matching lines is automatically logged. Examples:
See Get Lines Matching Pattern and Get Lines Containing String if you do not need full regular expression powers (and complexity).
|
||||||||||||||||||||||||||||||
| Get Regexp Matches | string, pattern,*groups |
Returns a list of all non-overlapping matches in the given string.
If no groups are used, the returned list contains full matches. If one group is used, the list contains only contents of that group. If multiple groups are used, the list contains tuples that contain individual group contents. All groups can be given as indexes (starting from 1) and named groups also as names. Examples:
=> ${no match} = []
New in Robot Framework 2.9. |
||||||||||||||||||||||||||||||
| Get Substring | string, start,end=None |
Returns a substring from The Examples:
|
||||||||||||||||||||||||||||||
| Remove String | string, *removables |
Removes all
Use Remove String Using Regexp if more powerful pattern matching is needed. If only a certain number of matches should be removed, Replace String or Replace String Using Regexp can be used. A modified version of the string is returned and the original string is not altered. Examples:
New in Robot Framework 2.8.2. |
||||||||||||||||||||||||||||||
| Remove String Using Regexp | string, *patterns |
Removes This keyword is otherwise identical to Remove String, but the New in Robot Framework 2.8.2. |
||||||||||||||||||||||||||||||
| Replace String | string, search_for,replace_with,count=-1 |
Replaces
If the optional argument A modified version of the string is returned and the original string is not altered. Examples:
|
||||||||||||||||||||||||||||||
| Replace String Using Regexp | string, pattern,replace_with,count=-1 |
Replaces This keyword is otherwise identical to Replace String, but the If you need to just remove a string see Remove String Using Regexp. Examples:
|
||||||||||||||||||||||||||||||
| Should Be Byte String | item, msg=None |
Fails if the given Use Should Be Unicode String if you want to verify the The default error message can be overridden with the optional |
||||||||||||||||||||||||||||||
| Should Be Lowercase | string, msg=None |
Fails if the given For example, The default error message can be overridden with the optional See also Should Be Uppercase and Should Be Titlecase. |
||||||||||||||||||||||||||||||
| Should Be String | item, msg=None |
Fails if the given With Python 2, except with IronPython, this keyword passes regardless is the With Python 3 and IronPython, this keyword passes if the string is a Unicode string but fails if it is bytes. Notice that with both Python 3 and IronPython, The default error message can be overridden with the optional |
||||||||||||||||||||||||||||||
| Should Be Titlecase | string, msg=None |
Fails if given
For example, The default error message can be overridden with the optional See also Should Be Uppercase and Should Be Lowercase. |
||||||||||||||||||||||||||||||
| Should Be Unicode String | item, msg=None |
Fails if the given Use Should Be Byte String if you want to verify the The default error message can be overridden with the optional |
||||||||||||||||||||||||||||||
| Should Be Uppercase | string, msg=None |
Fails if the given For example, The default error message can be overridden with the optional See also Should Be Titlecase and Should Be Lowercase. |
||||||||||||||||||||||||||||||
| Should Not Be String | item, msg=None |
Fails if the given See Should Be String for more details about Unicode strings and byte strings. The default error message can be overridden with the optional |
||||||||||||||||||||||||||||||
| Split String | string,separator=None,max_split=-1 |
Splits the If a Split words are returned as a list. If the optional Examples:
See Split String From Right if you want to start splitting from right, and Fetch From Left and Fetch From Right if you only want to get first/last part of the string. |
||||||||||||||||||||||||||||||
| Split String From Right | string,separator=None,max_split=-1 |
Splits the Same as Split String, but splitting is started from right. This has an effect only when Examples:
|
||||||||||||||||||||||||||||||
| Split String To Characters | string |
Splits the given Example:
|
||||||||||||||||||||||||||||||
| Split To Lines | string, start=0,end=None |
Splits the given string to lines. It is possible to get only a selection of lines from Lines are returned without the newlines. The number of returned lines is automatically logged. Examples:
Use Get Line if you only need to get a single line. |
||||||||||||||||||||||||||||||
| Strip String | string, mode=both,characters=None |
Remove leading and/or trailing whitespaces from the given string.
If the optional Examples:
New in Robot Framework 3.0. |
robotframework的学习笔记(十六)----robotframework标准库String的更多相关文章
- python3.4学习笔记(十六) windows下面安装easy_install和pip教程
python3.4学习笔记(十六) windows下面安装easy_install和pip教程 easy_install和pip都是用来下载安装Python一个公共资源库PyPI的相关资源包的 首先安 ...
- python3.4学习笔记(十五) 字符串操作(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
python3.4学习笔记(十五) 字符串操作(string替换.删除.截取.复制.连接.比较.查找.包含.大小写转换.分割等) python print 不换行(在后面加上,end=''),prin ...
- (C/C++学习笔记) 十六. 预处理
十六. 预处理 ● 关键字typeof 作用: 为一个已有的数据类型起一个或多个别名(alias), 从而增加了代码的可读性. typedef known_type_name new_type_nam ...
- Python学习笔记011_模块_标准库_第三方库的安装
容器 -> 数据的封装 函数 -> 语句的封装 类 -> 方法和属性的封装 模块 -> 模块就是程序 , 保存每个.py文件 # 创建了一个hello.py的文件,它的内容如下 ...
- JavaScript权威设计--CSS(简要学习笔记十六)
1.Document的一些特殊属性 document.lastModified document.URL document.title document.referrer document.domai ...
- MySQL学习笔记十六:锁机制
1.数据库锁就是为了保证数据库数据的一致性在一个共享资源被并发访问时使得数据访问顺序化的机制.MySQL数据库的锁机制比较独特,支持不同的存储引擎使用不同的锁机制. 2.MySQL使用了三种类型的锁机 ...
- python 学习笔记十六 django深入学习一 路由系统,模板,admin,数据库操作
django 请求流程图 django 路由系统 在django中我们可以通过定义urls,让不同的url路由到不同的处理函数 from . import views urlpatterns = [ ...
- SharpGL学习笔记(十六) 多重纹理映射
多重纹理就把多张贴图隔和在一起.比如下面示例中,一个表现砖墙的纹理,配合一个表现聚光灯效果的灰度图,就形成了砖墙被一个聚光灯照亮的效果,这便是所谓的光照贴图技术. 多重纹理只在OpenGL扩展库中才提 ...
- yii2源码学习笔记(十六)
Module类的最后代码 /** * Registers sub-modules in the current module. * 注册子模块到当前模块 * Each sub-module shoul ...
- Swift学习笔记十六:协议
Protocol(协议)用于统一方法和属性的名称,而不实现不论什么功能. 协议可以被类.枚举.结构体实现.满足协议要求的类,枚举,结构体被称为协议的遵循者. 遵循者须要提供协议指定的成员,如属性,方法 ...
随机推荐
- 简陋的斗地主,js实现
最近闲了两天没事做,用js写了个斗地主,练习练习.代码和功能都很简陋,还有bug,咋只是聊聊自己的思路. 这里说说斗地主主要包含的功能:洗牌,发牌,玩家出牌.电脑出牌,出牌规则的验证,输赢啥的没有判断 ...
- 非常棒的教程记录(JVM)
这里暂且记录下看过的非常棒的博客吧! JVM 指令集简单解释,来自一个不认识的网友的个人博客:http://www.iloveandroid.net/2015/12/06/jvm%E6%8C%87%E ...
- NIO相关基础篇二
转载请注明原创出处,谢谢! 上篇NIO相关基础篇一,主要介绍了一些基本的概念以及缓冲区(Buffer)和通道(Channel),本篇继续NIO相关话题内容,主要就是文件锁.以及比较关键的Selecto ...
- HTML5标签总结笔记
HTML5标签笔记 1.格式标签 元素名和属性一般不区分大小写,特殊的如id和class需要区分 格式标签: <acronym> 定义只取首字母的标签 <abbr>定义缩写 & ...
- java线程池的创建使用
利用java的多线程编程可以大大的提高系统的并发运行效率,线程越多并发执行的任务就越多,但是并不意味着效率会一直提高,相反会得到适得其反的效果. java中的多线程编程一共有三种方法: 继承Threa ...
- 命令行保存指定目录文件的名字(可包含文件夹文字)到txt文本文件
Microsoft Visual Studio中配置OpenCV解决方案属性的时候, 需要将OpenCV的lib扩展名的库文件添加到属性的依赖列表里面,网上的有些人博客里面直接给出的会有问题(但大多数 ...
- Windows Azure系列-- 配置Azure Power Shell
1.下载Azure Power shell https://azure.microsoft.com/en-us/documentation/articles/powershell-install-co ...
- 漂亮CSS样式用户留言表单
基本样式 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- 巧用CAS解决数据一致性问题
缘起:在高并发的分布式环境下,对于数据的查询与修改容易引发一致性问题,本文将分享一种非常简单但有效的优化方法. 一.业务场景 业务场景为,购买商品的过程要对余额进行查询与修改,大致的业务流程如下: ( ...
- Linux计划任务crontab
Linux系统中存在两种工作调度的方式 周期性的(at),每隔一个固定的周期要来办的事项: 一次性的(crontab),做完一次以后就不会再执行: at at是个可以处理仅执行一次就结束调度的指令,不 ...