(译)Web是如何工作的(3):HTTP&REST
什么是HTTP?
HTTP: 主要内容
HTTP:细节
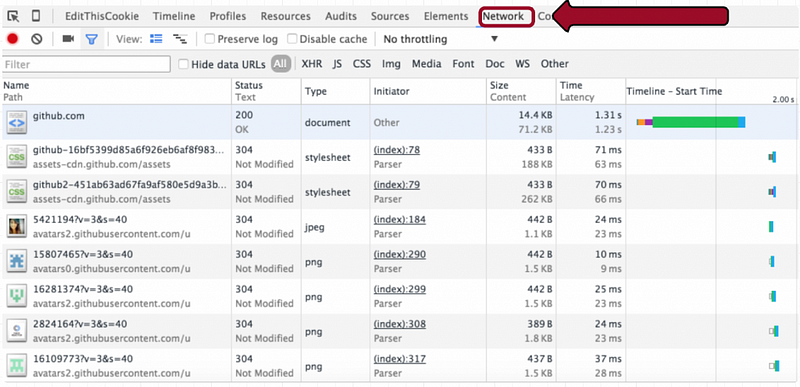
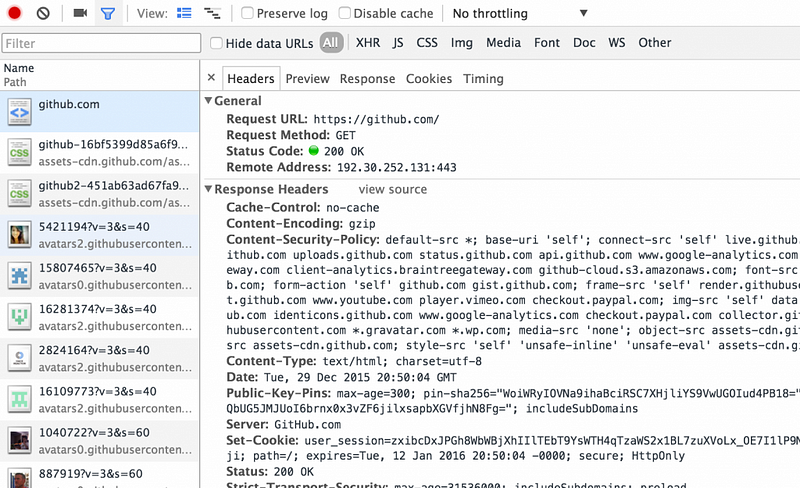
HTTP请求头
- 请求URL:https://github.com/ (这是我们请求的URL)
- 请求方法:GET (在这个例子里使用的这种HTTP请求方法,相当于浏览器说:“喂,GitHub服务器,把你的主要给我”)
- 状态码:200 OK (这是服务器告诉客户端,说你的请求结果正常的一种标准方式。状态码200意味着服务器成功地找到了资源,并正在发送给你)
- 远程地址:192.30.252.129:443 (这个IP地址和端口号是我们访问的GitHub网站,注意它的端口#443(意思是我们使用的是HTTPS协议,而不是HTTP))
- 内容编码:gzip (这是我们接受的资源编码,在这个例子里,GitHub服务器告诉我们,它发送回来的内容是压缩过的,GitHub可能压缩了文件,这样你下载时耗时更少。)
- 内容类型:text/html;字符集=utf-8 (规定响应主体中的数据表示方式,包括类型及其子集,这个类型描述的是数据类型,同时这个子集指定了这个数据类型的特定格式。在我们这个例子里,我们的文本是以HTML的形式返回给我们的;第二部分指定了对于这个HTML文档使用的字符编码,大部分情况下用的是这个例子中的用的UTF-8)
- 用户代理:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36 (这表示用户使用的软件,有时网站需要知道它们是如何被浏览的,所以浏览器发送这个用户代理字符串给服务器,服务器可以用来确定访问网站所用的内容)
- 接收编码:gzip,deflate,sdch (规定浏览器将以什么编码来接收内容,我们可以看到列表中的gzip,这就是为什么GitHub服务器能够发送gzip格式的内容给我们。)
- 接收语言:en-US;q=0.8 (描述我们想要的网页使用的语言,在这个例子里,“en”代表英语)
- 主机:github.com (这就不言自明了吧)
- Cookie:_octo=GH1.1.491617779.1446477115; logged_in=yes; dotcom_user=iam-peekay; _gh_sess=somethingFakesomething FakesomethingFakesomethingFakesomethingFakesomethingFakesomethingFakesomethingFake; user_session=FakesomethingFake somethingFakesomethingFakesomethingFake; _ga=9389479283749823749; tz=America%2FLos_Angeles_ (这段文本是Web服务器存储在用户机器上,以便以后检索,这些信息是以键值对存储的,其中一个键值对是GitHub为了这个请求存储的,例如,“dotcom_user=iam-peekay”是用来告诉GitHub我的用户ID是iam-peekay)
tl;dr:这些键值对又是做什么的?
HTTP 主体

附加练习
HTTP请求方法
- GET http://www.example.com/users (取得所有用户)
- POST http://www.example.com/users/a-unique-id (创建一个新用户)
- PUT http://www.example.com/comments/a-unique-id (更新评论)
- DELETE http://www.example.com/comments/a-unique-id (删除评论)
GET

POST
PUT
DELETE
什么是REST呢?
- 在请求里资源必须是可识别的(比如在URI用资源识别器)。一个资源(比如数据库里的数据)是定义资源表示的数据(如JSON,HTML)。资源和资源表示是分离的——客户端只与资源表示互动。
- 客户端使用资源表示时必须要有足够的信息去操作服务器上的资源。
- 客户端与服务器交换的每条消息必须是自我描述的,通过这些信息来决定如何处理这些消息。
- 客户端必须使用HTTP主体内容、HTTP请求头、查询参数和URL发送状态数据。服务器必须使用HTTP主体内容、响应码和响应头部发送状态数据。
- 注意:我们上面描述的HTTP动词使得“接口一致性”占据了很重要的部分,因为它们对那些操作的资源呈现一致性。
结尾语
(译)Web是如何工作的(3):HTTP&REST的更多相关文章
- (译)Web是如何工作的:给Web开发新手的初级读物
原文地址:https://medium.freecodecamp.org/how-the-web-works-a-primer-for-newcomers-to-web-development-or- ...
- Web服务器的工作原理
Web服务器的工作原理 Web服务器工作原理概述 很多时候我们都想知道,web容器或web服务器(比如Tomcat或者jboss)是怎样工作的?它们是怎样处理来自全世界的http请求的?它们在幕后做了 ...
- ASP.NET Web Service如何工作(2)
ASP.NET Web Service如何工作(2) [日期:2003-06-26] 来源:CSDN 作者:sunnyzhao(翻译) [字体:大 中 小] HTTP管道一旦调用了.asmx句柄,便 ...
- ASP.NET Web Service如何工作(3)
ASP.NET Web Service如何工作(3) [日期:2003-06-26] 来源:CSDN 作者:sunnyzhao(翻译) [字体:大 中 小] 为了使.asmx句柄有可能反串行化SOA ...
- ASP.NET Web Service如何工作(1)
ASP.NET Web Service如何工作(1) [日期:2003-06-26] 来源:CSDN 作者:sunnyzhao(翻译) [字体:大 中 小] Summary ASP.NET Web ...
- 简述基于Struts框架Web应用的工作流程
简述基于Struts框架Web应用的工作流程 解答:在web应用启动时就会加载初始化ActionServlet,ActionServlet从struts-config.xml文件中读取配置信息,把它们 ...
- 如何修改myeclipse中web项目的工作路径或默认路径
如何修改myeclipse中web项目的工作路径或默认路径 博客分类: J2EE开发技术指南 安装好myeclipse后,第一次启动myeclipse时,都会弹出会弹出Workspace Laun ...
- IIS 6.0的web园 最大工作进程数细谈
这篇文章主要介绍了IIS 6.0的web园 最大工作进程数,需要的朋友可以参考下:(摘自:http://www.jb51.net/article/84817.htm) IIS 6.0允许将应用程序池配 ...
- Web基础_0x00_Web工作方式
web工作方式 对于普通的上网过程,系统其实是这样做的:浏览器本身是一个客户端,当输入URL的时候,首先浏览器会去请求DNS服务器,通过NDS获取相应的域名对应的IP,然后通过IP地址找到IP对应的服 ...
- (译)Web是如何工作的(2):客户端-服务器模型,以及Web应用程序的结构
原文地址:https://medium.freecodecamp.org/how-the-web-works-part-ii-client-server-model-the-structure-of- ...
随机推荐
- Ubuntu下关闭防火墙
默认情况下ubuntu无firewall,除非你自己安装了,怎么装的就怎么删呗. . 假设是已启用的自备的iptables 删了即可了 sudo apt-get remove iptables.
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- 《调试九法——软硬件错误的排查之道》【PDF】下载
<调试九法--软硬件错误的排查之道>[PDF]下载链接: https://u253469.ctfile.com/fs/253469-231196352 内容简介 <调试九法:软硬件错 ...
- Gulp 的简单使用(原创)
1.安装nodejs 安装省略 npm的全称是Node Package Manager,是随同NodeJS一起安装的包管理和分发工具,它很方便让JavaScript开发者下载.安装.上传以及管理已经安 ...
- WindowsServer2012 搭建域错误“本地Administraor账户不需要密码”
标签:MSSQL/SQLServer/域控制器提升的先决条件验证失败/密码不符合要求 概述 在安装WindowsServer2012域控出现administrator账户密码不符合要求的错误,但是实际 ...
- MySQL in or效率对比
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/60 考虑如下两个sql: select * from table ...
- 如何在MQ中实现支持任意延迟的消息?
什么是定时消息和延迟消息? 定时消息:Producer 将消息发送到 MQ 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消 ...
- js 深入理解原型模式
我们创建每一个函数都有一个prototype(原型)属性,这个属性是一个指针,指向一个对象.使用原型的好处是可以让所有对象共享它所包含的属性和方法. function Person(){ } Pers ...
- du 命令详解
du : show disk usage 作用:统计目录或文件所占用磁盘空间的大小. 语法:du 参数 选项 参数: -a 为每个制定文件显示磁盘使用情况, 或者为目录中每个文件显示各自磁盘使用情况 ...
- 文件上传之伪Ajax方式上传
From: <由 Windows Internet Explorer 8 保存> Subject: =?gb2312?B?zsS8/snPtKvWrs6xQWpheLe9yr3Jz7SrI ...