IEEE Trans 2008 Gradient Pursuits论文学习
之前所学习的论文中求解稀疏解的时候一般采用的都是最小二乘方法进行计算,为了降低计算复杂度和减少内存,这篇论文梯度追踪,属于贪婪算法中一种。主要为三种:梯度(gradient)、共轭梯度(conjugate gradient)、近似共轭梯度(an approximation to the conjugate gradient),看师兄之前做压缩感知的更新点就是使用近似共轭梯度方法代替了StOMP中的最小二乘的步骤。
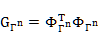


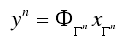
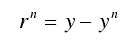
.png) 中选出最相关的原子。
中选出最相关的原子。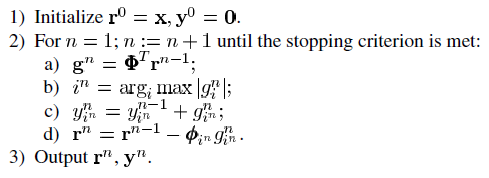

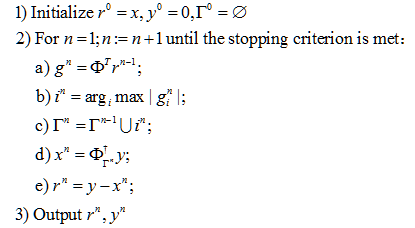
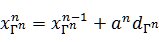 来代替MP算法中的2c,其中dΓn是梯度更新方向,其中步长
来代替MP算法中的2c,其中dΓn是梯度更新方向,其中步长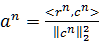 ,向量
,向量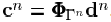 。不同的梯度算法所选择的dΓn不同。综上,我们可将梯度追踪算法的总体框架归纳如下:
。不同的梯度算法所选择的dΓn不同。综上,我们可将梯度追踪算法的总体框架归纳如下:
接下来分别介绍论文中提出的三种梯度追踪方法。
基于最速下降法的匹配追踪
最速下降法(这个翻译是从参考文献2中得来的)是采用目标函数的负梯度作为更新方向。目标函数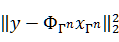 的梯度大小为:
的梯度大小为:
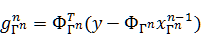

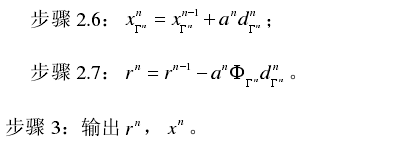
function[theta]=CS_GP(y,A,t)
%CS_GP Summary of this function goes here
%Version: 1.0 written by wwf @2017-04-28
% Detailed explanation goes here
% y = Phi * x
% x = Psi * theta
% y = Phi*Psi * theta
% 令 A = Phi*Psi, 则y=A*theta
% 现在已知y和A,求theta
[y_rows,y_columns]= size(y);
if y_rows<y_columns
y = y';%y should be a column vector
end
[M,N]= size(A); %传感矩阵A为M*N矩阵
theta = zeros(N,1); %用来存储恢复的theta(列向量)
aug_y=[];
r_n = y; %初始化残差(residual)为y
Aug_t=[];
for ii =1:t %迭代t次,t为输入参数
for col=1:N;
product(col)=abs(A(:,col)'*r_n); %传感矩阵A各列与残差的内积
end
[val,pos]= max(abs(product)); %找到最大内积绝对值,即与残差最相关的列
Aug_t=[Aug_t,A(:,pos)];
pos_array(ii)=pos;
g_n=Aug_t'*r_n; % 梯度方向
c_n=Aug_t*g_n;
w_n=(r_n'*c_n)/(c_n'*c_n); % 最速下降步长
d_n=w_n*g_n;
[x1,x2]=size(d_n);
[y1,y2]=size(aug_y);
D=aug_y;
aug_y=zeros(x1,x2);
aug_y(1:y1,1:y2)=D;
aug_y=aug_y+d_n ; % 最小二乘,使残差最小
r_n=r_n-(w_n)*(c_n); % 残差
end
theta(pos_array)=aug_y;
end
function[theta]=GP_test(y,A,t)
%CS_GP Summary of this function goes here
%Version: 1.0 written by wwf @2017-04-28
% Detailed explanation goes here
% y = Phi * x
% x = Psi * theta
% y = Phi*Psi * theta
% 令 A = Phi*Psi, 则y=A*theta
% 现在已知y和A,求theta
[y_rows,y_columns]= size(y);
if y_rows<y_columns
y = y';%y should be a column vector
end
[M,N]= size(A); %传感矩阵A为M*N矩阵
theta = zeros(N,1); %用来存储恢复的theta(列向量)
r_n = y; %初始化残差(residual)为y
d_n=zeros(N,1);
P =@(z) A*z;
Pt =@(z) A'*z;
IN=[]; for ii =1:50 %迭代t次,t为输入参数
product=Pt(r_n);
[v I]=max(abs(product)); if isempty(find (IN==I))
IN=[IN I];
else
break;
end
d_n(IN)=product(IN);
c_n=P(d_n);
a_n=r_n'*c_n/(c_n'*c_n);
theta=theta+a_n*d_n;
r_n=r_n-a_n*c_n;
end
end
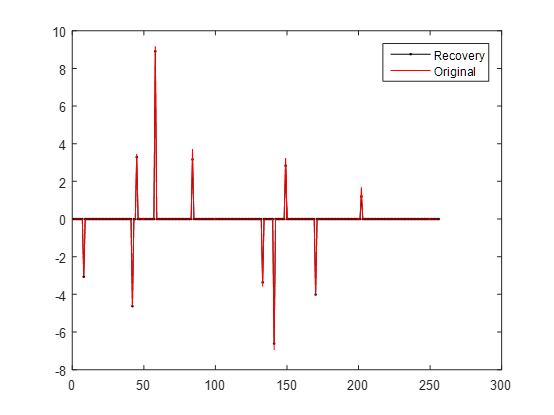

调用作者写的代码的时候发现,有的时候恢复效果比较好,残差很小,但有的时候也会出现残差比较大的情况,猜测可能和生成的信号有关系,因为每次信号是随机生成的。结果如下图所示:
















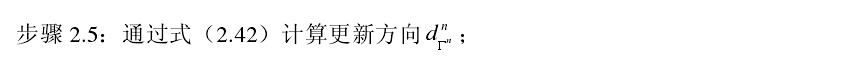
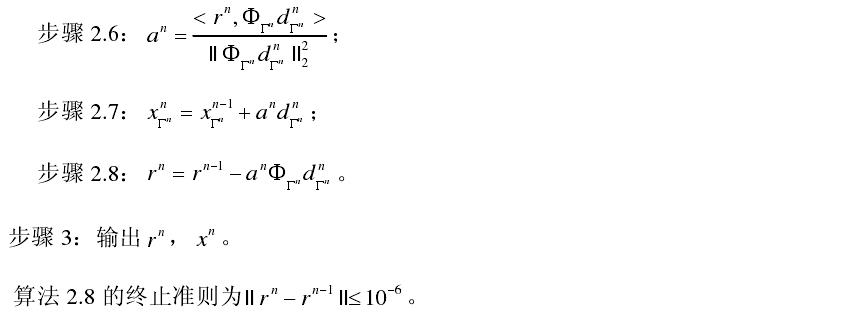
while~done
DR(IN)=0;
[v I]=max(abs(DR));
IN=[IN I];
k=k+1;
ifk==1
d(IN)=1;
PG(1)=1;
else
%%%% Calculate P'*G, but only need new column and new row %%%%%
mask=zeros(m,1);
mask(IN(k))=1;%将mask中对应的第k次迭代所选出的内积所在的列序号的项置为1
new_element=P(mask);%选出此次迭代所选择出的原子
gnew=Pt(new_element);%gnew相当于G,即Psi'*Psi
PG(k-1,k-1)=D(1:k,k-1)'*[g;1];
g=gnew(IN);
%PG计算的是D’*G
PG(:,k)=D'*[g;zeros(maxM-k,1)]; % 1 general mult.
%%%% Calculate conjugate directions %%%
b=(PG(1:k-1,1:k)*DR(IN))./(dPPd(1:k-1));
d(IN)=DR(IN)-D(1:k,1:k-1)*b;%d should be orthogonal to the first k-1 columns of G.
end
D(1:k,k)=d(IN);%D是由n-1次的更新方向组成的矩阵
Pd=P(d);
dPPd(k)=Pd'*Pd;
a=(DR'*d)/dPPd(k);
s=s+a*d;
Residual=Residual-a*Pd;
DR=Pt(Residual); ERR=Residual'*Residual/n;
ifcomp_err
err_mse(iter)=ERR;
end ifcomp_time
iter_time(iter)=toc;
end
tic
t=0;
p=zeros(m,1);
DR=Pt(Residual);
[v I]=max(abs(DR));
ifweakness~=1
[vals inds]=sort(abs(DR),'descend');
I=inds(find(vals>=alpha*v));
end IN=union(IN,I);
ifstrcmp(STOPCRIT,'M')&length(IN)>=STOPTOL
IN=IN(1:STOPTOL);
end
MASK=zeros(size(DR));
pDDp=1;
done=0;
iter=1;
while~done % Select new element
ifisa(GradSteps,'char')
ifstrcmp(GradSteps,'auto') %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Iteration to automatic selection of the number of gradient steps
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% finished=0;
% while ~finished
% Update direction
ifiter==1
p(IN)=DR(IN); %p相当于论文中的d_n,当迭代次数为1时,d_n等于内积
Dp=P(p); %Dp相当于论文中的c_n,即Psi与d_n的乘积
else
MASK(IN)=1; %IN为此次迭代选出的内积值最大的列序号,将MASK的该项置为1
PDR=P(DR.*MASK);%取出最大的内积值,与字典矩阵Psi相乘
b=-Dp'*PDR/pDDp;%计算系数b1
p(IN)=DR(IN)+b*p(IN);%计算更新的方向d_n
Dp=PDR+b*Dp; %c_n是Psi与d_n-1的乘积,即P(d_n-1),将d_n-1展开带入即得
end
% Step size
% Dp=P(p); % =P(DR(IN)) +b P(p(IN));
pDDp=Dp'*Dp;
a=Residual'*Dp/(pDDp);
% Update coefficients
s=s+a*p;
% New Residual and inner products
Residual=Residual-a*Dp;
DR=Pt(Residual);
% select new element
[v I]=max(abs(DR));
ifweakness~=1
[vals inds]=sort(abs(DR),'descend');
I=inds(find(vals>=alpha*v));
end
IN=union(IN,I);
ifstrcmp(STOPCRIT,'M')&length(IN)>=STOPTOL
IN=IN(1:STOPTOL);
end
% % Only if we select new element do we leave the loop
% if isempty(find (IN==I, 1))
% IN=[IN I];
% finished=1;
% end
% end
IEEE Trans 2008 Gradient Pursuits论文学习的更多相关文章
- IEEE Trans 2009 Stagewise Weak Gradient Pursuits论文学习
论文在第二部分先提出了贪婪算法框架,如下截图所示: 接着根据原子选择的方法不同,提出了SWOMP(分段弱正交匹配追踪)算法,以下部分为转载<压缩感知重构算法之分段弱正交匹配追踪(SWOMP)&g ...
- 对比学习下的跨模态语义对齐是最优的吗?---自适应稀疏化注意力对齐机制 IEEE Trans. MultiMedia
论文介绍:Unified Adaptive Relevance Distinguishable Attention Network for Image-Text Matching (统一的自适应相关性 ...
- IEEE Trans 2007 Signal Recovery From Random Measurements via OMP
看了一篇IEEE Trans上的关于CS图像重构的OMP算法的文章,大部分..看不懂,之前在看博客的时候对流程中的一些标号看不太懂,看完论文之后对流程有了一定的了解,所以在这里解释一下流程,其余的如果 ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- 论文学习笔记--无缺陷样本产品表面缺陷检测 A Surface Defect Detection Method Based on Positive Samples
文章下载地址:A Surface Defect Detection Method Based on Positive Samples 第一部分 论文中文翻译 摘要:基于机器视觉的表面缺陷检测和分类可 ...
- 论文学习笔记 - Classifification of Hyperspectral and LiDAR Data Using Coupled CNNs
Classifification of Hyperspectral and LiDAR Data Using Coupled CNNs 来源:IEEE TGRS 2020 下载:https://arx ...
随机推荐
- C++ 随机生成一个(0,1)之间的小数
double p; ]; memset(s,,sizeof(s)); s[]='; s[]='.'; ;i<;i++) { s[i]=rand()%+'; } p=atof(s); cout & ...
- c++学习笔记---04---从另一个小程序接着说
从另一个小程序接着说 文件I/O 前边我们已经给大家简单介绍和演示过C和C++在终端I/O处理上的异同点. 现在我们接着来研究文件I/O. 编程任务:编写一个文件复制程序,功能实现将一个文件复制到另一 ...
- Android 开发笔记___spinner__适配器基础_arrayadapter
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout ...
- DOM遍历-祖先
遍历 - 祖先 向上遍历 DOM 树 这些 jQuery 方法很有用,它们用于向上遍历 DOM 树: parent() parents() parentsUntil() jQuery parent() ...
- Ajax comet XMLHttpRequest 异步
function createXHR() { if (typeof XMLHttpRequest != “undefi ned”){ return new XMLHttpRequest(); ...
- web storage 离线存储
用来保存键值对数据,数据以属性的方式保存在storage实例对象上 可以用storage1.length来决定键值对的数量,但是无法决定数据的大小,storage1.remainingSpace可 ...
- 事件 event
添加移除函数(removeEventListener)时三个参数保持一致,否则会失败,而且不会有错误提示 var btn = document.getElementById(“myBtn”); btn ...
- C# 取Visio模型信息的简易方法
最近的一个项目,要求导出Visio图纸,因为是建筑类的,所以,需要设置墙壁,门,房间等信息的参数. 拿墙壁为例,选中墙壁模型,右键属性,会弹出以下对话框. 需要设置墙长.墙壁厚度等一些列信息. 现在C ...
- Easy UI下拉列表默认选中(多行)与为文本框赋值
1.为单行文本框赋值 var data2 = $('#LoadArea').combobox("getData"); if (data2) { $('#id).combobox(' ...
- github创建远程仓库
创建远程仓库 当你已经在本地创建了一个Git仓库后,又想在GitHub创建一个Git仓库,并且让这两个仓库进行远程同步,这样,GitHub上的仓库既可以作为备份,又可以让其他人通过该仓库来协作,真是一 ...