Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题。以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助。当然,建议先把HDFS和MapReduce理论原理看懂了再来搭建,会流畅很多。
准备阶段:
系统:Ubuntu Linux16.04 64位 (下载地址:https://www.ubuntu.com/download/desktop)
安装好Ubuntu之后,如果之前没有安装过jdk,需要先安装jdk。这里安装jdk的版本是:jdk1.8.0_144 (下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) 这里就不展开安装说明,安装jdk很简单,这里自行百度吧。
建议Ubuntu下载64位,因为Hadoop2.5.0之后的版本里面的库都是64位的,32位的Linux系统里面每次运行Hadoop都会报警告。
现在准备好了一台安装了java的Ubuntu虚拟机,别忘了搭建Hadoop集群至少需要三台Ubuntu虚拟机。
最简单的办法就是 使用VMware自带的克隆的办法,克隆出三台一模一样的虚拟机。
具体操作参见地址 (https://jingyan.baidu.com/article/6b97984d9798f11ca2b0bfcd.html)
准备好了三台Ubuntu Linux虚拟机,接下来就开始搭建集群。
先总的看一下所有的步骤:
一、配置hosts文件
二、建立hadoop运行帐号
三、配置ssh免密码连入
四、下载并解压hadoop安装包
五、配置 /etc/hadoop目录下的几个文件及 /etc/profile
六、格式化namenode并启动集群
接下来根据步骤开始搭建:
一、配置hosts文件
以上准备了三台虚拟机,但是虚拟机的主机名也是一样的,需要现对虚拟机主机名进行修改,来进行区分一个主节点和两个从节点。
修改主机名命令:
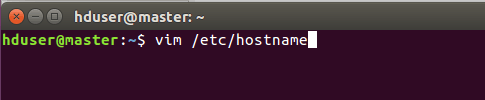
显示的master就是主机名,我这里已经修改好了,可以把三台虚拟机分别命名 主节点:master 从节点1:node1 从节点2:node2

修改好了,保存即可。
接下来,分别查看三台虚拟机的ip地址,命令如下:
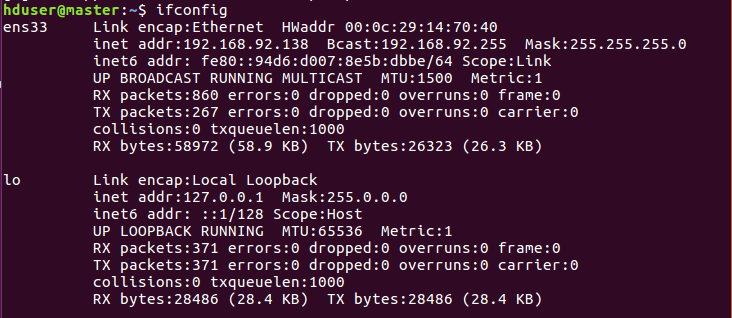
inet addr就是这台虚拟机的ip地址。
接下来打开hosts文件 进行修改:

将三台虚拟机的ip地址和主机名加在里面,其它的不用动它。
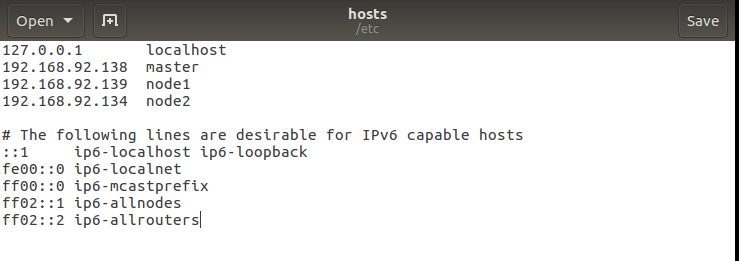
三台虚拟机都要修改hosts文件。简单的说配置hosts后三台虚拟机就可以进行通信了,可以互相ping一下试试,是可以ping通的。
二、建立hadoop运行帐号
解释一下这一步骤,就是建立一个group组,然后在三台虚拟机上重新建立新的用户,将这三个用户都加入到这个group中。
以下操作三台虚拟机都要进行相同操作:
首先添加一个叫hadoop用户组进来
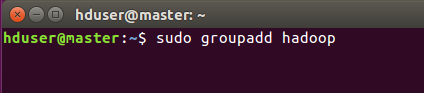
添加名叫hduser的用户,并添加到hadoop组中。

接着输入以下指令然后输入两次密码
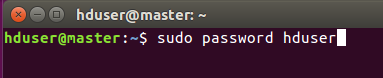
然后赋予hduser用户admin权限

接下来的操作 切换到刚刚新建的用户进行
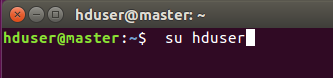
三、配置ssh免密码连入
开始配置ssh之前,先确保三台机器都装了ssh。
输入以下命令查看安装的ssh。
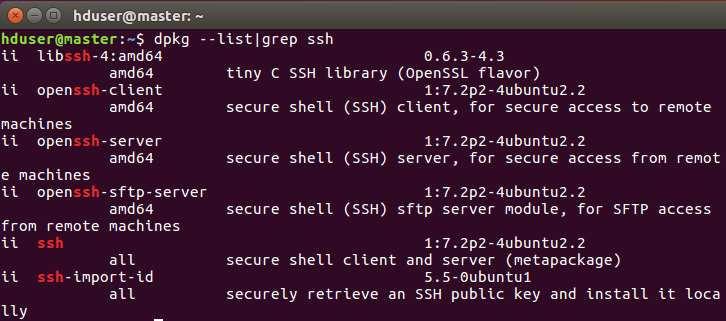
如果缺少了opensh-server,需要进行安装。

安装完毕之后开始配置ssh
接下来的这第三个步骤的操作请注意是在哪台主机上进行,不是在三台上同时进行。
(1)下面的操作在master机上操作
首先在master机上输入以下命令,生成master机的一对公钥和私钥:

以下命令进入认证目录可以看到, id_rsa 和 id_rsa.pub这两个文件,就是我们刚刚生成的公钥和私钥。
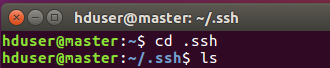
然后,下面的命令将公钥加入到已认证的key中:

再次进入生成目录,可以看到多出authorized_keys这个文件:
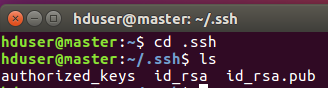
然后输入ssh localhost 登录本机命令,第一次提示输入密码,输入exit退出,再次输入ssh localhost不用输入密码就可以登录本机成功,则本机ssh免密码登录已经成功。
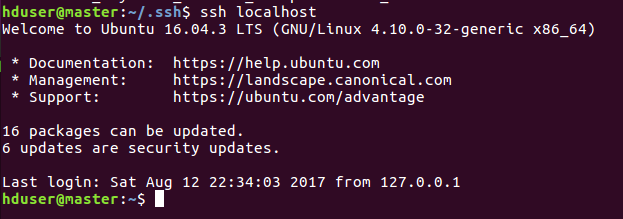
到这里是不是已经对ssh免密码登录有了认识,不要着急,开始配置node1和node2节点的ssh免密码登录,目的是让master主机可以不用密码登录到node1和node2主机。
(2)这一步分别在node1和node2主机上操作:
将master主机上的is_dsa.pub复制到node1主机上,命名为node1_dsa.pub。node2主机进行同样的操作。

将从master得到的密钥加入到认证,node2主机进行同样的操作。

然后开始验证是不是已经可以进行ssh免密码登录。
(3)在master机上进行验证
同样第一次需要密码,之后exit退出,再ssh node1就不需要密码登录成功,说明ssh免密码登录配置成功!
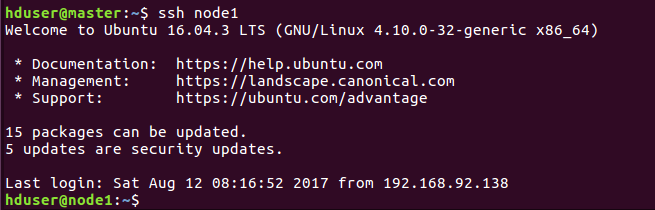
如果失败了,可能是前面的认证没有认证好,可以将.ssh目录下的密钥都删了重新生成和配置一遍。或者检查下hosts文件ip地址写的对不对。
四、下载并解压hadoop安装包
版本:Hadoop2.6.0 (下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/)
建议初学者选择2.6.0或者2.7.0版本就可以了,而且如果后面要配置Eclipse开发环境的话,这两个版本的插件很容易找到,不用自己去编译。
话不多说,将hadoop压缩包,解压到一个文件夹里面,我这里解压到了home文件夹,并修改文件夹名为hadoop2.6。所在的目录就是/home/hduser/hadoop2.6
三台主机都要解压到相应位置
五、配置 /etc/hadoop目录下的几个文件及 /etc/profile
主要有这5个文件需要修改:
~/etc/hadoop/hadoop-env.sh
~/etc/hadoop/core-site.xml
~/etc/hadoop/hdfs-site.xml
~/etc/hadoop/mapred-site.xml
~/etc/hadoop/slaves
/etc/profile
三台机都要进行这些操作,可以先在一台主机上修改,修改完了复制到其它主机就可以了。
首先是hadoop-env.sh ,添加java安装的地址,保存退出即可。
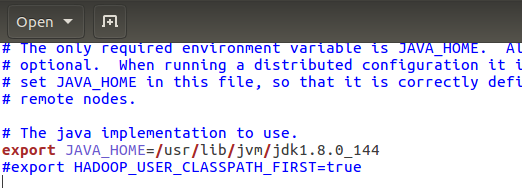
然后core-site.cml
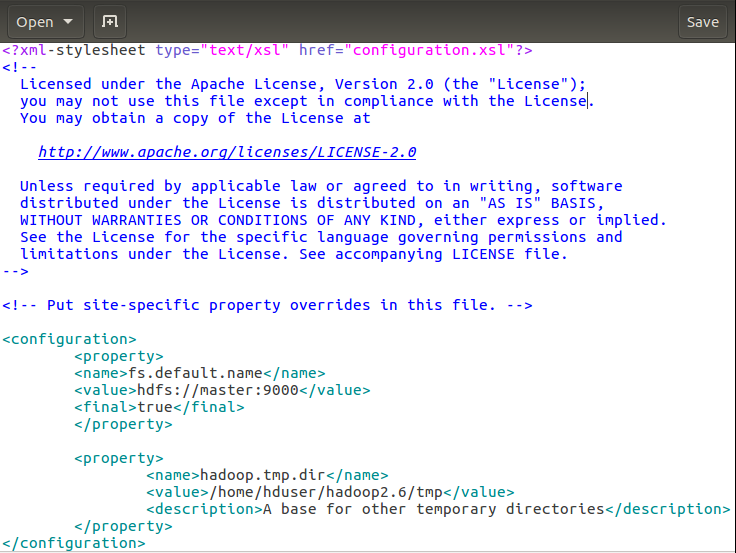
解释下:第一个fs.default.name设置master机为namenode 第二个hadoop.tmp.dir配置Hadoop的一个临时目录,用来存放每次运行的作业jpb的信息。
接下来hdfs-site.xml的修改:
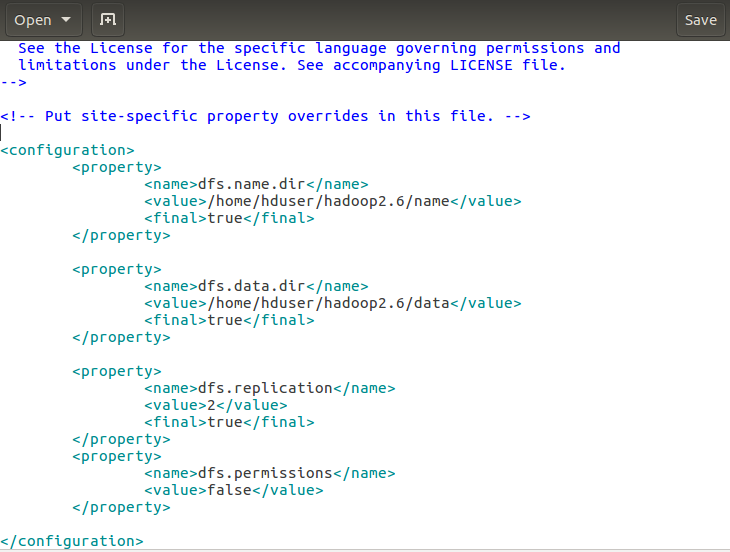
解释下:dfs.name.dir是namenode存储永久性的元数据的目录列表。这个目录会创建在master机上。dfs.data.dir是datanode存放数据块的目录列表,这个目录在node1和node2机都会创建。 dfs.replication 设置文件副本数,这里两个datanode,所以设置副本数为2。
接下来mapred-site.xml的修改:
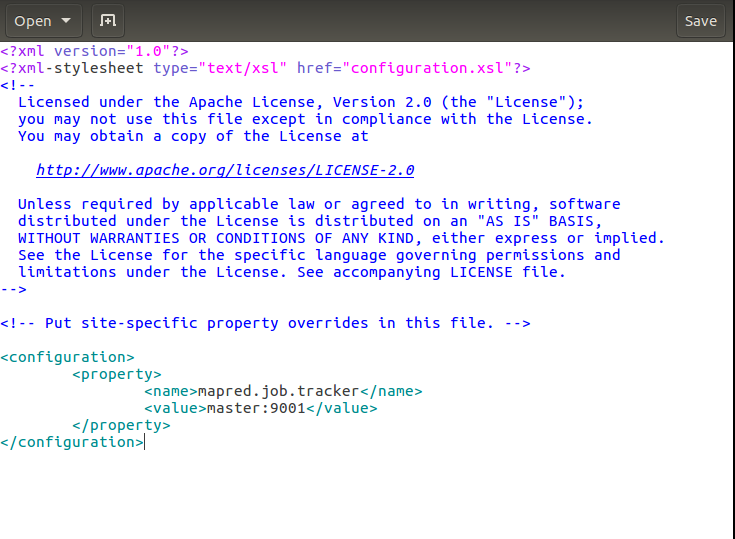
解释下:这里设置的是运行jobtracker的服务器主机名和端口,也就是作业将在master主机的9001端口执行。
接下来修改slaves文件

这里将两台从主机的主机名node1和node2加进去就可以了。
最后修改profile文件 ,如下进入profile:

将这几个路径添加到末尾:

修改完让它生效:

检查下是否可以看到hadoop版本信息
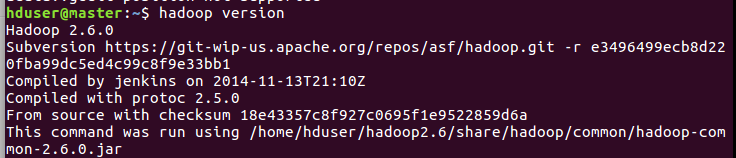
显示出了版本信息,如果没有显示出来,回过去检查 profile路径是否填写错误。
六、格式化namenode并启动集群
接下来需要格式化namenode,注意只需要在 master主机上进行格式化。格式化命令如下:

看到successful表示格式化成功。
接下来启动集群:

启动完毕,检查下启动情况: master主机看到四个开启的进程,node1和node2看到三个开启的进程表示启动成功。


如果有疑问或疏漏的地方,欢迎大家指出和讨论哈哈!!!
Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04的更多相关文章
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- 分布式集群搭建(hadoop2.6.0+CentOS6.5)
摘要:之前安装过hadoop1.2.1集群,发现比较老了,后来安装cloudera(hadoop2.6.0),发现集成度比较高,想知道原生的hadoop什么样子,于是着手搭建一个伪分布式集群(三台), ...
- hadoop分布式集群搭建(2.9.1)
1.环境 操作系统:ubuntu16 jdk:1.8 hadoop:2.9.1 机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.1 ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- [过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下: 配置hosts vim /etc/hosts 格式: ip hostname ip hostname 设置免密登陆 首先:每台主机使用ssh命令连接其余主机 ssh 用户名@主机名 提示是 ...
- Centos 7下Hadoop分布式集群搭建
一.关闭防火墙(直接用root用户) #关闭防火墙 sudo systemctl stop firewalld.service #关闭开机启动 sudo systemctl disable firew ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
随机推荐
- maven自定义jar到本地仓库
Apache Maven为项目构建提供了绝佳的解决方案,其本地仓库中缓存了远程代理仓库或中央仓库中的资源,从而提高网络资源使用效率,很好很强大! 但是并非所有资源都可以根据GroupId.Artif ...
- Shiro固定身份验证
Shiro基础身份验证 如果要进行shiro的日志信息读取,那么需要使用一个org.apache.shiro.util.Factory接口,在这个接口里面定义有一 取得SecuruityManager ...
- Unity-Shader-镜面高光Phong&BlinnPhong-油腻的师姐在哪里
[旧博客转移 - 2016年4月4日 13:13 ] 油腻的师姐: 以前玩过一款很火热的端游<剑灵>,剑灵刚出来的时候,某网页游戏广告视频中有句台词:"我不断的在寻找,有你的世界 ...
- 刨根究底字符编码之十四——UTF-16究竟是怎么编码的
UTF-16究竟是怎么编码的 1. 首先要注意的是,代理Surrogate是专属于UTF-16编码方式的一种机制,UTF-8和UTF-32是不用代理的. 如前文所述,为了让UTF-16能继续编码基本平 ...
- vue-devtools vue开发调试神器
前言: 由于vue是数据驱动的,所以这就存在在开发调试中查看DOM结构并不能解析出什么. 但是借助vue-devtools插件,我们就可以很容易的对数据结构进行解析和调试. 一.下载chrome扩展插 ...
- POJ 2296 Map Labeler / ZOJ 2493 Map Labeler / HIT 2369 Map Labeler / UVAlive 2973 Map Labeler(2-sat 二分)
POJ 2296 Map Labeler / ZOJ 2493 Map Labeler / HIT 2369 Map Labeler / UVAlive 2973 Map Labeler(2-sat ...
- css动画属性--小球移动
主体只有一个div <body> <div></div> </body> 样式部分(测试:目前的浏览器还是需要加前缀才能兼容) <style> ...
- PHPCMS修改域名
有时候服务器域名解析时,需要修改网站域名,那么在phpcms中,像一些附件地址什么的都需要修改.下面介绍一下怎么系统全面的修改这些地址. 1.在后台管理中心--设置--站点管理--修改,站点域名改为新 ...
- MySQL后台线程的清理工作
后台清理工作:脏页刷盘.undo回收 1.page cleaner thread:刷新脏页 2.purge thread:清空undo页.清理“deleted”page 一.innodb_page_c ...
- ASP.NET底层封装HttpModule实例---FormsAuthentication类的分析
HttpModule是用来注册HttpApplication事件的,实现IHttpModule接口的托管代码模块可以访问该请求管道的所有事件.那么对于我们最常用的ASP.NET Forms身份验证模块 ...