Spark学习笔记1(初始spark
1.什么是spark?
spark是一个基于内存的,分布式的,大数据的计算框架,可以解决各种大数据领域的计算问题,提供了一站式的服务
Spark2009年诞生于伯克利大学的AMPLab实验室
2010年正式开源了Spark项目
2013年Spark成为Apache下的项目
2014年飞速发展,成为Apache的顶级项目
2015年在国内兴起,代替mr,hive,storm等
2.SparkCore :spark是用来取代Hadoop的?
这种说法是不对的,spark由于只能做计算,所以取代掉MapReduce是没有问题的,但是基于spark无法存储数据,所以其数据的存储还是要依赖于hdfs,资源调度可以依赖于yarn,亦可以依赖于其他。
3.spark的功能?
①sparkCore 离线计算
②sparkSQL 交互式查询
③sparkStreaming 实时的流式计算
④sparkGraphx 图形计算
⑤spark mllib 机器学习 人工智能 其核心是算法

4.spark的特点及解释?
spark的特点有:
①一站式:就是说spark可以用一个技术堆栈就可以解决大数据领域的所有的计算问题
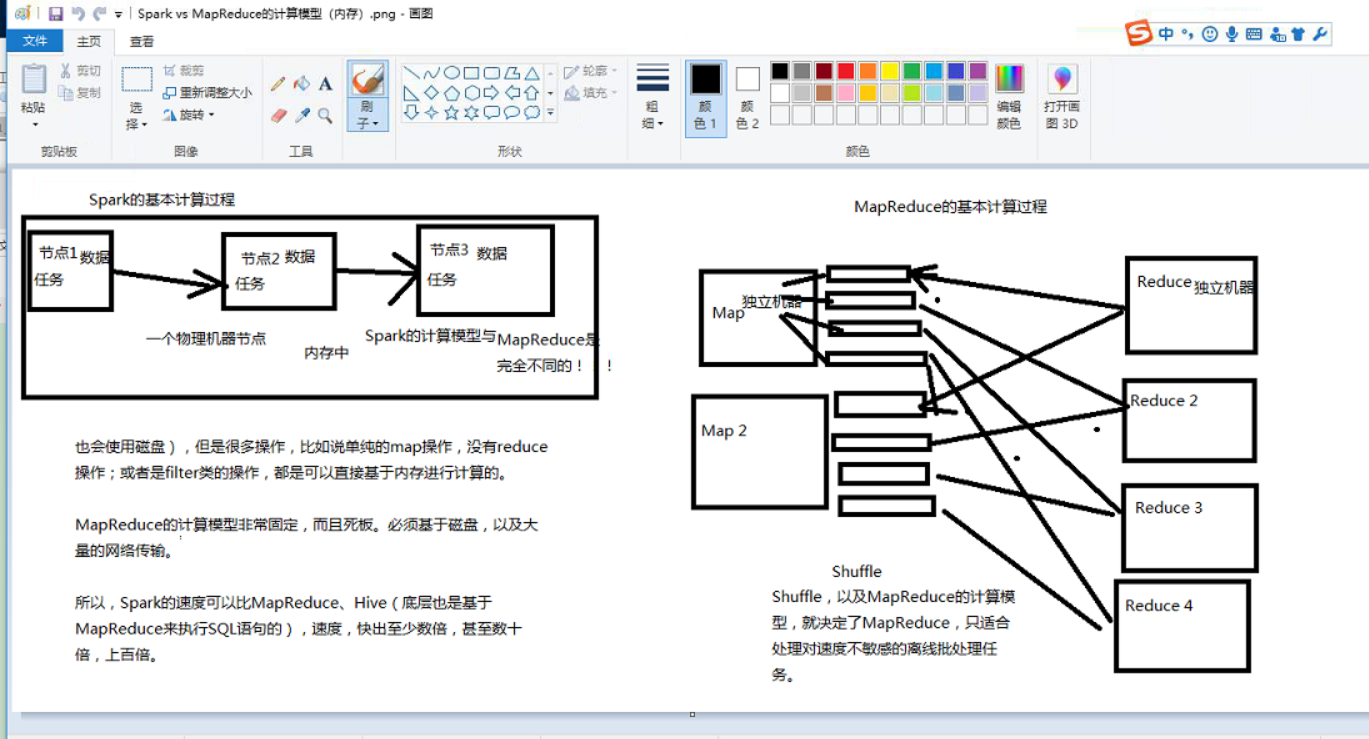
②基于内存:这个特点也是spark的运行速度比Mr的速度快的原因,因为spark是基于内存的,内存的
读写的速度要大大的超过磁盘,但是,有一些操作也是无法避免的,spark也有shuffle,所以说最后的
结果也要落地,落地就i需要走磁盘。另一方面的原因就是spark是迭代式的计算框架,内部又有很多的
优化手段,DAG,切分STAGE,这一套机制可以最大限度的优化计算的性能
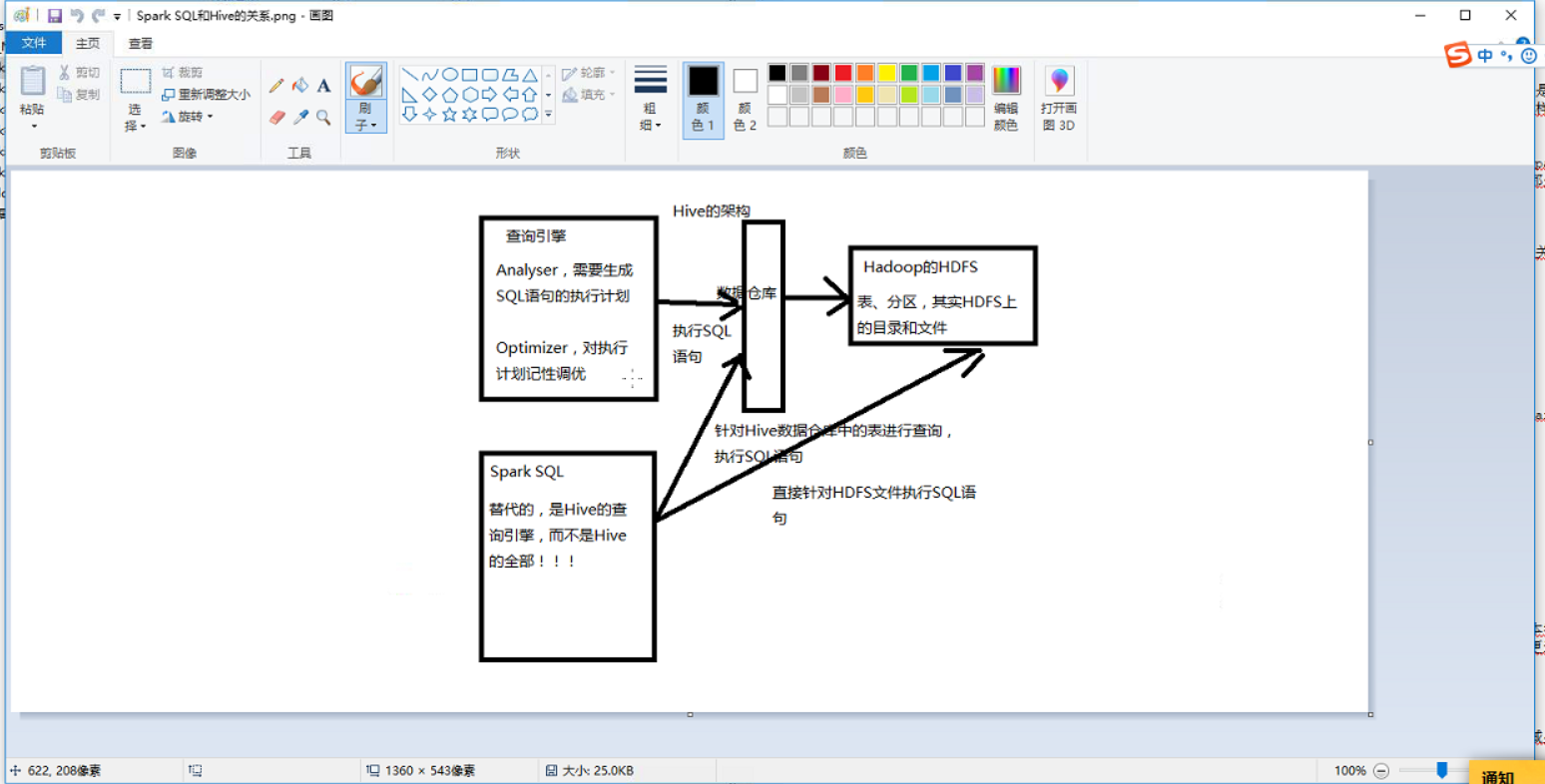
5.sparkSQL和hive的关系?
hive 首先来说是一个数据仓库,里面放了很多的数据,其次hive还可以通过sql做一些数据的离线批处理,
运行的是MapReduce。
spark SQL 肯定不可以用来做数据仓库,但spark SQL也是通过写sql的方式,做数据的离线计算,底层用的
是RDD。可以直接操作hive
6.sparkStreaming和strom的关系?
strom有很多的有点,比较老了,如果说是纯粹的实时(全部都是实时的业务),现在有一个更加优秀的解决方案
:flink,在一些绝大部分的场景下,sparkStreaming是可以取代掉strom的
实时性,容错都比sparkstreamming优秀
和sparkstreaming相比之下不足的地方:
吞吐量不如sparkstreaming,后者可以方便的和spark SQL ,sparkCore,sparkMLlib无缝的结合
7.spark开发语言的选择?
现如今关于spark的主流语言是scala,如果说是单纯的大数据项目,scala较其他语言相比更为合适一些,但是也有不足的地方:会scala 的人太少,第二点就是由于Scala和第三方的架构整合起来困难。
Java:如今最最主流的编程语言,整合第三方架构的时候也比较简单,如果用java来写spark的话,更为适合写一些比较复杂的大数据项目。
两者的相同之处在于:java可以把代码实现,scala也可以把代码实现
现在比较火的编程语言python,也可以用来开发spark,不过略有不同于其他两种语言的是,python更倾向于机器学习,即(sparkMLlib),因为python的库特别多,而机器学习的算法库也有很多,所以python更多的时间用于机器学习。
转载本文请和本文作者联系,本文来自博客园一袭白衣一
Spark学习笔记1(初始spark的更多相关文章
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力.Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立 ...
- Spark学习笔记1:Spark概览
Spark是一个用来实现快速而通用的集群计算的平台. Spark项目包含多个紧密集成的组件.Spark的核心是一个对由很多计算任务组成的,运行在多个工作机器或者是一个计算集群上的应用进行调度,分发以及 ...
- Spark学习笔记——构建基于Spark的推荐引擎
推荐模型 推荐模型的种类分为: 1.基于内容的过滤:基于内容的过滤利用物品的内容或是属性信息以及某些相似度定义,来求出与该物品类似的物品. 2.协同过滤:协同过滤是一种借助众包智慧的途径.它利用大量已 ...
- Spark学习笔记6:Spark调优与调试
1.使用Sparkconf配置Spark 对Spark进行性能调优,通常就是修改Spark应用的运行时配置选项. Spark中最主要的配置机制通过SparkConf类对Spark进行配置,当创建出一个 ...
- Spark 学习笔记之 MONGODB SPARK CONNECTOR 插入性能测试
MONGODB SPARK CONNECTOR 测试数据量: 测试结果: 116万数据通过4个表的join,从SQL Server查出,耗时1分多.MongoSparkConnector插入平均耗时: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
随机推荐
- JFinal极速开发框架使用笔记
记录第一次使用JFinal,从简单的框架搭建到增删改查,从自带的方法到正常框架习惯的使用方式. JFinal官网:http://www.jfinal.com/ JFinal 是基于 Java 语言的极 ...
- 基于telegraf+influxdb+grafana进行postgresql数据库监控
前言 随着公司postgresql数据库被广泛应用,尤其是最近多个项目在做性能测试的时候都是基于postgresql的数据库,为了确定性能瓶颈是否会出现在数据库中,数据库监控也被我推上了日程.在网上找 ...
- JS中数组的方法
1. join() Array.join() 是 String.split() 的逆向操作 var arr = [1, 2, 3] arr.join()// "1,2,3" arr ...
- xlwt 官网的例子
from time import * from xlwt.Workbook import * from xlwt.Style import * style = XFStyle() wb = Workb ...
- vue基础学习(一)
01-01 vue使用雏形 <div id="box"> {{msg}} </div> <script> window.onload= func ...
- Mac说——关闭SIP
今天在安装keras的时候总是提示numpy无法安装,百度了下,说是新版本的os系统加入了spi机制. 什么是SIP: 系统集成保护(System Integrity Protection,SIP), ...
- [转]Linux网络配置命令ifconfig输出信息解析
eth0 Link encap:Ethernet HWaddr 00:1e:4f:e9:c2:84 inet addr:128.224.163.153 Bcast:128.224.163 ...
- 豹哥嵌入式讲堂:ARM开发之文件详解(3)- project文件
大家好,我是豹哥,猎豹的豹,犀利哥的哥.今天豹哥给大家讲的是嵌入式开发里的project文件. 前面两节课里,豹哥分别给大家介绍了嵌入式开发中的两种典型input文件:source文件.linker文 ...
- 每天学一点Docker(4)-深入了解容器概念
什么是容器? 容器是一个自包含,可移植,轻量级的软件打包技术.是应用程序在任何地方几乎以相同方式运行.开发人员在开发机上创建好容器,无需任何修改就能在虚拟机,云服务器或公有云主机上运行. 容器与虚拟机 ...
- Mac下安装pymssql
需要先安装freetds 先用 brew list 查看已经安装的包 如果已经安装freetds,则使用 brew uninstall freetds先卸载 brew unlink freetds b ...