Lucence
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包.
粘贴这句话的意思就是想说明 Lucene仅仅是一个工具包,搜索引擎的工具包.
有人会问?Lucene和solr的区别,solr是一个搜索系统,打个比方,就如servlet和struts2的区别 Lucene就是servlet,solr就好比solr,solr封装了Lucene.
下面说说Lucene的原理:
我们使用Lucene,其实使用的是他的倒排查询
什么是倒排查询?举个例子
新华字典,我们都用过吧,新华字典分为两部分,第一部门就是目录的边旁部首,第二部分就是正文,一个一个字的解释,
我们在用新华字典的时候,一般我们都是通过边旁部首找字,没有人一页一页的翻字典找字吧.
Lucene的倒排就是如此,他会检索文本,数据库,web网页,在把内容分词,就像边旁部首

再次强调

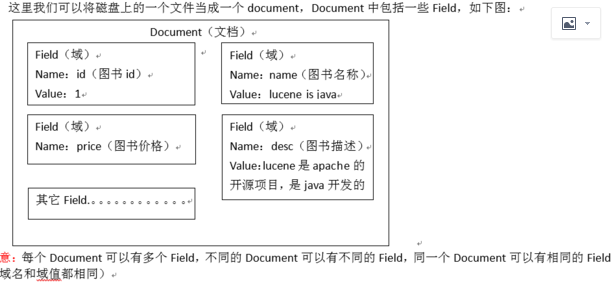

这一条数据就是一个document文档
每一个字段就是一个Field域

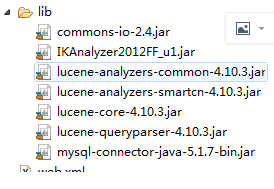
这就是要用到的包;
 ik下载后把这3个文件也要导入项目中,ext.dic是加词的,stop是停词的.
ik下载后把这3个文件也要导入项目中,ext.dic是加词的,stop是停词的.
前面的都是Lucece的理论,只有理论搞懂了,下面的代码实现过程也就轻松了
package com.itheima.lucene; import java.io.File;
import java.util.ArrayList;
import java.util.List; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; import com.itheima.dao.BookDao;
import com.itheima.dao.impl.BookDaoImpl;
import com.itheima.pojo.Book; public class CreateIndexTest {
//分词
@Test
public void testCreateIndex() throws Exception{
// 1. 采集数据
BookDao bookDao = new BookDaoImpl();
List<Book> listBook = bookDao.queryBookList(); // 2. 创建Document文档对象
List<Document> documents = new ArrayList<>();
for (Book bk : listBook) { Document doc = new Document();
doc.add(new TextField("id", String.valueOf(bk.getId()), Store.YES));// Store.YES:表示存储到文档域中
doc.add(new TextField("name", bk.getName(), Store.YES));
doc.add(new TextField("price", String.valueOf(bk.getPrice()), Store.YES));
doc.add(new TextField("pic", bk.getPic(), Store.YES));
doc.add(new TextField("desc", bk.getDesc(), Store.YES)); // 把Document放到list中
documents.add(doc);
} // 3. 创建分析器(分词器)
//Analyzer analyzer = new StandardAnalyzer();
//中文 IK
Analyzer analyzer = new IKAnalyzer(); // 4. 创建IndexWriterConfig配置信息类
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); // 5. 创建Directory对象,声明索引库存储位置
Directory directory = FSDirectory.open(new File("H:\\temp")); // 6. 创建IndexWriter写入对象
IndexWriter writer = new IndexWriter(directory, config); // 7. 把Document写入到索引库中
for (Document doc : documents) {
writer.addDocument(doc);
} // 8. 释放资源
writer.close();
} //查
@Test
public void serachIndex() throws Exception{
//创建分词器 必须和检索时的分析器一致
Analyzer analyzer = new StandardAnalyzer();
// 创建搜索解析器,第一个参数:默认Field域,第二个参数:分词器
QueryParser queryParser = new QueryParser("desc", analyzer); // 1. 创建Query搜索对象
Query query = queryParser.parse("desc:java AND lucene"); // 2. 创建Directory流对象,声明索引库位置
Directory directory = FSDirectory.open(new File("H:\\temp")); // 3. 创建索引读取对象IndexReader
IndexReader indexReader = DirectoryReader.open(directory); // 4. 创建索引搜索对象IndexSearcher
IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 5. 使用索引搜索对象,执行搜索,返回结果集TopDocs
// 第一个参数:搜索对象,第二个参数:返回的数据条数,指定查询结果最顶部的n条数据返回
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("查询到的数据总条数是:" + topDocs.totalHits);
//获得结果集
ScoreDoc[] docs = topDocs.scoreDocs; // 6. 解析结果集
for (ScoreDoc scoreDoc : docs) {
//获得文档
int docID = scoreDoc.doc;
Document doc = indexSearcher.doc(docID); System.out.println("docID:"+docID);
System.out.println("bookid:"+doc.get("id"));
System.out.println("pic:"+doc.get("pic"));
System.out.println("name:"+doc.get("name"));
System.out.println("desc:"+doc.get("desc"));
System.out.println("price:"+doc.get("price"));
} // 7. 释放资源
indexReader.close();
}
}
Lucence的更多相关文章
- lucence.net+盘古分词
第一步: 添加盘古和lucence的dll引用 第二步: 拷贝Dict文件夹到项目 demo里面是Dictionaries 不过官方建议改成Dict 然后把所有项右击属性 改为“如果较新则复制” 第 ...
- Lucence工作原理
lucence 是一个高性能的java全文检索工具包,他使用倒排序文件索引结构,改结构和相应的生成算法如下: 一.设有两篇文章1和2 文章1的内容为:Tom lives in guangzh ...
- lucence学习系列之一 基本概念
1. Lucence基本概念 Lucence是一个java编写的全文检索类库,使用它可以为一个应用或者站点增加检索功能. 它通过增加内容到一个全文索引来完成检索功能.然后允许你基于这个索引去查询,返回 ...
- Lucence使用入门
参考: https://blog.csdn.net/u014209975/article/details/50525624 https://www.cnblogs.com/hanyinglong/p/ ...
- apache开源项目--lucence
Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎.Lucene的目的是为软件开发人员提供一个简单易用 ...
- Lucence.net索引技术 二
一. Lucene索引创建和优化 [版本2.9.0以上] Lucene索引的创建首先需要取得几个必须的对象: 1.分词器//可以采用其他的中文分词器 StandardAnalyzer analyzer ...
- Lucence.net索引技术 一
1.建立索引 为了对文档进行索引,Lucene 提供了五个基础的类,他们分别是 Document, Field, IndexWriter, Analyzer, Directory.下面我们分别介绍一下 ...
- Lucence.Net+添加关键词+分页+排序
1.使用queryparser完成解析搜索请求 2.基本格式如: QueryParser parser=new QueryParser("字段名称","分析器实例&quo ...
- Lucence.Net学习+盘古分词
创建索引库 //读取文件,存储到索引库 public string CreateDatebase() { //获取索引库的路径 ...
随机推荐
- hdu1540线段树
https://vjudge.net/contest/66989#problem/I #include<iostream> #include<cstdio> #include& ...
- win彩 百款皮肤任选任换.可视化
- TCP流量控制和拥塞控制
TCP的流量控制 所谓的流量控制就是让发送方的发送速率不要太快,让接收方来得及接受.利用滑动窗口机制可以很方便的在TCP连接上实现对发送方的流量控制.TCP的窗口单位是字节,不是报文段,发送 ...
- Java线程安全性中的对象发布和逸出
发布(Publish)和逸出(Escape)这两个概念倒是第一次听说,不过它在实际当中却十分常见,这和Java并发编程的线程安全性就很大的关系. 什么是发布?简单来说就是提供一个对象的引用给作用域之外 ...
- 学习笔记TF010:softmax分类
回答多选项问题,使用softmax函数,对数几率回归在多个可能不同值上的推广.函数返回值是C个分量的概率向量,每个分量对应一个输出类别概率.分量为概率,C个分量和始终为1.每个样本必须属于某个输出类别 ...
- js事件小结
首先事件绑定分为2种方法 一种为"DOM0级"方法,这里我理解为事件指定 var oDiv = document.getElementById("div1"); ...
- 8、单选按钮(JRadioButton)和复选框(JCheckBox)
8.单选按钮(JRadioButton)和复选框(JCheckBox) 实现一个单选按钮(或复选框),此按钮项可被选择或取消选择,并显示其状态.JRadioButton对象与ButtonGroup对象 ...
- javaWeb学习总结(7)-关于session的实现:cookie与url重写
本文讨论的语境是java EE servlet.我们都知道session的实现主要两种方式:cookie与url重写,而cookie是首选(默认)的方式,因为各种现代浏览器都默认开通cookie功能, ...
- javaWeb学习总结(10)- EL表达式
一.EL表达式简介 EL 全名为Expression Language.EL主要作用: 1.获取数据 EL表达式主要用于替换JSP页面中的脚本表达式,以从各种类型的web域 中检索java对象.获取数 ...
- SPFA求单源最短路径
序 求最短路径的算法有很多,各有优劣. 比如Dijkstra(及其堆(STL-priority_queue)优化),但是无法处理负环的情况: 比如O(n^3)的Floyd算法:比如Bellman-Fo ...