Html Agility Pack解析HTML页
现在,在不少应用场合中都希望做到数据抓取,特别是基于网页部分的抓取。其实网页抓取的过程实际上是通过编程的方法,去抓取不同网站网页后,再进行分析筛选的过程。比如,有的比较购物网站,会同时去抓取不同购物网站的数据并将其保存在数据库中。一般,这些网页的抓取都需要对抓取回来的HTML进行解析。
.NET提供了很多类去访问并获得远程网页的数据,比如WebClient类和HttpWebRequest类。这些类对于利用HTTP去访问远端的网页并且下载下来是很有用的,但在对于所下载下来的HTML的解析能力方面,则显得功能很弱了,以往,开发者不得不用很简陋的方法,比如使用String.IndexOf,String.Substring或使用正则表达式去解析。
另外一种解析HTML的方法是使用开源的工具包HTML Agility Pack(http://htmlagilitypack.codeplex.com/),它的设计目标是尽可能简化对HTML文档的读和写。这个包本身是利用了DOM文档对象模型去解析HTML的。仅需要几行代码,开发者就可以利用DOM 去访问文档中的头部一直到它的孩子结点。HTML Agility包也能通过XPATH去访问DOM中的指定结点,同时,它也包含了一个类可以用来下载远程网站上的网页,这意味者开发者可以利用它,同时下载并且解析HTML网页了,十分方便。
本文将以几个例子展示如何使用HTML Agility包去下载和解析网页,代码例子在附件中可以下载。
准备工作
可以从http://htmlagilitypack.codeplex.com/)去下载Html Agility包,注意必须运行在ASP.NET 3.5及以后的版本上。下载后,这个工具包实际上是以HtmlAgilityPack.dll形式存在的。使用的时候,只需要将这个dll放在你的网站或工程的bin目录下就可以了,我们目前使用的版本是1.4。
下面我们分别通过三个例子去说明如何使用HTML Agility。
例子一:列出远程网页的META标签
网页的抓取一般涉及到下载指定的网页,并且抓取指定的信息片断。第一个例子指导如何使用Html Agility包去下载一个网页,并且逐一循环显示出HTML页中的同时有名称和content标签的 标签中。
Html Agility Pack包包含了一些类,它们都在HtmlAgilityPack这个命名空间中,因此在使用前,先要引用这个命名空间,如下:
以下是代码片段:
using HtmlAgilityPack;
要从网站上去下载网页,可以使用HtmlWeb类的Load方法,当然实现要新建一个HtmlWeb的对象实例,如下:
以下是代码片段:
var webGet = new HtmlWeb();
var document = webGet.Load(url);
其中Load方法会返回一个HtmlDocument对象。在上面的代码中,我们把返回的HtmlDocument对象赋值到一个本地变量document中去。HtmlDocument这个类代表了一个完整的HTML文档并且包含了DocumentNode属性,这个属性返回的是一个代表文档根结点的HtmlNode对象。
HtmlNode类有几个属性,都十分简单,主要是用来遍历DOM的,包括:
ParentNode:访问父结点
ChildNodes:访问孩子结点
NextSibling:某个元素的下一个兄弟元素(也就是说同层次元素中的下一个元素)
PreviousSibling :某个元素的上一个兄弟元素(也就是说同层次元素中的上一个元素)
对于结点本身的判断,有如下属性:
Name - 获得或设置结点的名称。对HTML元素来说,它返回标签中的内容,比如对于BODY标签,则返回结果为”body ”,对于[P]标签则返回结果为”p ”,如此类推
Attributes -返回该元素的所有属性的集合
InnerHtml -返回或设置该元素中的HTML内容。
InnerText -返回结点的文本文字。
NodeType -指出结点的类型,可以是Document,Element,Comment或者是文本。
当然,也有很多其他的方法去获得指定的结点的信息,比如,Ancestors方法返回所有的祖先结点,而SelectNodes方法则返回匹配XPath表达式的结点集合。
有了这些方法和属性,现在我们就有很多方法去获得HTML文档中的所有 标签。这个例子中将采用SelectNodes方法。下面的语句调用了document对象的的DocumentNode属性中的SelectNodes方法,使用了xpath表达式”//meta”,返回了所有文档中的 标记。
以下是代码片段:
var metaTags = document.DocumentNode.SelectNodes("//meta");
如果在文档中没有 标签,则metaTags变量会为null,如果有多于一个 标签,则metaTags会是一个HtmlNode的对象集合了,我们可以遍历并且显示它们的属性,如下代码:
以下是代码片段:
if (metaTags != null)
{
foreach (var tag in metaTags)
{
if (tag.Attributes["name"] != null && tag.Attributes["content"] != null)
{
... 输出 tag.Attributes["name"].Value 和 tag.Attributes["content"].Value ...
}
}
}
上面的代码中,首先使用了foreach去循环metaTags集合中的每个元素,然后判断每个元素的name和content属性的值是否为空,如果不空的话,直接输出其内容就可以了,看到了么,根本不需要用正则表达式,十分方便。
下图则是采用了上面的代码后的效果,用户在这里输入了要访问的地址,点提交按钮,则Html Agility会下载网页的内容,以及使用上文介绍的方法,去取得 标签内的内容并且显示出来。

▲
例子二 列出远程页面中的链接
上面的例子演示了如何使用SelectNodes方法和xpath去查找指定的结点。而另外一个方法是使用Linq的语法去实现。HtmlNode类的方法,比如返回文档的祖先或者子孙结点的,实际上返回的都是象IEnumerable 的对象的,如果你对Linq语法熟悉,则知道Linq是很容易处理IEnumerable的,而且可以很容易使用Linq去查询HTML文档的结点。
为了演示如何使用Linq去访问结点,在这个例子中,将演示如何去获得某个页面的文本和所有超级链接(标签)的值。一开始的代码跟第一个例子是相同的,要创建HtmlWeb对象:
以下是代码片段:
var webGet = new HtmlWeb();
var document = webGet.Load(url);
标签中的,当然我们要求这些标签中是要内容的,不能只是空白,最后返回一个匿名类型,有两个属性:Url和Text:
接下来,将使用到document对象的Descendants方法和linq语法去获得指定页面的所有链接。准确的说,是获得页面中所有
以下是代码片段:
var linksOnPage = from lnks in document.DocumentNode.Descendants()
where lnks.Name == "a" &&
lnks.Attributes["href"] != null &&
lnks.InnerText.Trim().Length > 0
select new
{
Url = lnks.Attributes["href"].Value,
Text = lnks.InnerText
};
看到了么,上面使用的正是LINQ语法。现在我们就可以使用一些asp.net的控件去展示这个linksOnPage中的内容了,本文代码中使用的是listview控件,命名为lvLinks:
以下是代码片段:
lvLinks.DataSource = linksOnPage;
lvLinks.DataBind();
前端的listbview变的简单了,如下:
以下是代码片段:
<asp:ListView ID="lvLinks" runat="server">
<LayoutTemplate>
<ul>
<asp:PlaceHolder runat="server" ID="itemPlaceholder" />
</ul>
</LayoutTemplate>
<ItemTemplate>
<li>
<%# Eval("Text") %> - <%# Eval("Url") %>
</li>
</ItemTemplate>
</asp:ListView>
运行后,如下图所示:
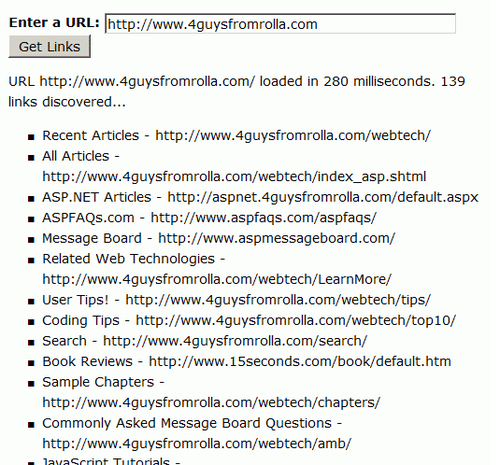
例子三 修改并保存HTML文档
上面两个例子分别演示了如何使用Html Agility包去抓取一个网页并且解析,但有的情况下,也需要修改文档的DOM结构并且保存到磁盘上。这个例子演示的跟前两个有点相象,要求用户输入一个网页的地址,之后抓取网页,并且对以下两个方面进行了修改。
1. 在程序读取文档的同时,使用程序的方法,动态增加一个新的元素结点,使其成为标签的第一个孩子结点。
2. 文档中所有的链接,改变成以新打开窗口的方式打开,这个设置其targer属性为_blank即可。
在修改完代码后,同时把它保存到用户本地的磁盘上。同样,一开始的步骤跟前面两个是一样的:
以下是代码片段:
var webGet = new HtmlWeb();
var document = webGet.Load(url);
接下来,通过Linq语法的扩展方法去查找body元素,下面的代码的意思是:在document结点的所有子孙结点中,查找第一个结点并且它的名称是“body”,如果不存在,则返回null。
以下是代码片段:
var body = document.DocumentNode.Descendants()
.Where(n => n.Name == "body")
.FirstOrDefault();
如果找到body标签后,我们则创建一个新的HTML元素标签,下面的代码创建了一个新的HTML元素标签(变量名为messageElement),并且指定了其样式属性,为这个标指定了其命名div,说明要创建的是一个
标签,最后为其指定了inner HTML属性的值,当然最后要把建立好的元素结点插入到body标签的开始:
以下是代码片段:
if (body != null)
{
var messageElement = new HtmlNode(HtmlNodeType.Element, document, 0);
messageElement.Attributes.Add("style", "width:95%;border:solid black 2px;background-color:#ffc;font-size:xx-large;text-align:center");
messageElement.Name = "div";
messageElement.InnerHtml = "
Hello! This page was modified by the Html Agility Pack!
Click on a link below... it should open in a new window!
";
body.ChildNodes.Insert(0, messageElement);
}
接下来,SelectNodes方法会返回所有
以下是代码片段:
var linksThatDoNotOpenInNewWindow = document.DocumentNode.SelectNodes("//a[@href]");
if (linksThatDoNotOpenInNewWindow != null)
{
foreach (var link in linksThatDoNotOpenInNewWindow)
if (link.Attributes["target"] == null)
link.Attributes.Add("target", "_blank");
else
link.Attributes["target"].Value = "_blank";
}
最后,我们调用save方法去保存我们做的修改,在本文中,将其保存在ModifiedPages目录下,并且用guid的方法生成了其文件名,如下代码:
以下是代码片段:
var fileName = string.Format("~/ModifiedPages/{0}.htm", Guid.NewGuid().ToString());
document.Save(Server.MapPath(fileName));
下图显示了运行例子三后的结果,可以看到,我们把页面修改并保存后,在页面的一开始,的确加入了我们要加入的内容,并且你可以试下打开所有页面的链接,都会发现是以新打开链接方式打开的,要注意的是,因为4guysfromrolla网页上使用的都是相对路径,因此图片我们这次没把它们保存下来,所以在这个页面中看不到是正常的。
Html Agility Pack解析HTML页的更多相关文章
- Html Agility Pack 解析Html
Hello 好久不见 哈哈,今天给大家分享一个解析Html的类库 Html Agility Pack.这个适用于想获取某网页里面的部分内容.今天就拿我的Csdn的博客列表来举例. 打开页面 用Fir ...
- [c#] Html Agility Pack 解析HTML
摘要 在开发过程中,很有可能会遇到这样的情况,服务端返回的是html的内容,但需要在客户端显示纯文本内容,这时候就需要解析这些html,拿到里面的纯文本.达到这样的目的可以有很多途径,比如自己写正则表 ...
- Html Agility Pack解析Html(C#爬虫利器)
有个需求要写网络爬虫,以前接触过一个叫Html Agility Pack这个解析html的库,这次又要用到,然而发现以前咋用的已经不记得了,现在从头开始记录一下使用过程. Html Agility P ...
- C# 网络爬虫利器之Html Agility Pack如何快速实现解析Html
简介 现在越来越多的场景需要我们使用网络爬虫,抓取相关数据便于我们使用,今天我们要讲的主角Html Agility Pack是在爬取的过程当中,能够高效的解析我们抓取到的html数据. 优势 在.NE ...
- Html Agility Pack基础类介绍及运用
第一篇只对Html Agility Pack做了一个大概的介绍,在接下来的章节会比较深入的介绍Html Agility Pack. Html Agility Pack 源码中的类大概有28个左右,其实 ...
- C#解析HTML神器 Html Agility Pack
曾经,我傻乎乎的用正则表达式成功的解析了学校的新闻网.教务管理系统.图书馆管理系统中我想要的所有的内容.那时候废了好大的劲写那正则啊,而且最后还是各种不给力,经常会有意想不到的bug出现,最后经过无数 ...
- 开源项目Html Agility Pack实现快速解析Html
这是个很好的的东西,以前做Html解析都是在用htmlparser,用的虽然顺手,但解析速度较慢,碰巧今天找到了这个,就拿过来试,一切出乎意料,非常爽,推荐给各位使用. 下面是一些简单的使用技巧,希望 ...
- C#解析HTML利器-Html Agility Pack
今天刚开始做毕设....好吧,的确有点晚.我的毕设设计需要爬取豆瓣的电影推荐,于是就需要解析爬取下来的html,之前用Python玩过解析,但目前我使用的是C#,我觉得C#不比python差,有微软大 ...
- 强大而灵活的的Html解析器——Html Agility Pack
一.概述 Html Agility Pack 简称HAP,是一个强大而灵活的解析Html DOM的.Net类库. 二.官方链接 官网:http://html-agility-pack.net/ NuG ...
随机推荐
- IC设计前端到后端的流程和eda工具。
IC前端设计(逻辑设计)和后端设计(物理设计)的区分:以设计是否与工艺有关来区分二者:从设计程度上来讲,前端设计的结果就是得到了芯片的门级网表电路. 前端设计的流程及使用的EDA工具例如以下: 1.架 ...
- AMR音频文件格式分析
AMR音频文件格式分析 1 概要 如今非常多智能手机都支持多媒体功能,特别是音频和视频播放功能,而AMR文件格式是手机端普遍支持的音频文件格式.AMR,全称是:Adaptive Multi-Rate, ...
- NYOJ 105 其余9个
九的余数 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描写叙述 如今给你一个自然数n,它的位数小于等于一百万,如今你要做的就是求出这个数整除九之后的余数. 输入 第一行有一 ...
- Visual Studio-Sequence Diagram
UML Design Via Visual Studio-Sequence Diagram 本文主要介绍在Visual Studio中设计时序图,内容如下: 何时使用时序图 时序图元素介绍 条件.循环 ...
- android 数据共享
android数据共享的各种部件中的应用是最重要的3途径: 第一.使用Application子类来实现数据共享. 例如,请看下面的例子: /** * @author YangQuanqing 特征: ...
- Atitit.异步编程 java .net php python js 对照
Atitit.异步编程 java .net php python js 的比較 1. 1.异步任务,异步模式, APM模式,, EAP模式, TAP 1 1.1. APM模式: Beg ...
- Oracle利用存储过程性 实现分页
分页的简单配置 在上一次已经说过了 这边说说怎么在存储过程中实现分页 首先建立存储过程 參考 http://www.cnblogs.com/gisdream/archive/2011/11/16/22 ...
- 泛型委托及委托中所涉及到匿名方法、Lambda表达式
泛型委托及委托中所涉及到匿名方法.Lambda表达式 引言: 最初学习c#时,感觉委托.事件这块很难,其中在学习的过程中还写了一篇学习笔记:委托.事件学习笔记.今天重新温故委托.事件,并且把最近学习到 ...
- select刷新后,保持选定状态,Cookies存储select选定状态信息
//cookies存储select选定值,防止刷新后没了 window.onload = function () { var cooki = document.cookie; if (cooki != ...
- TreeView的绑定
近期遇到了TreeView的数据库绑定问题,确实是弄了我好几天,特别是多级节点的分步绑定,最開始不分步,发现所有载入页面都卡爆了,真心让人头疼.所以放出来,给须要的朋友看看,以免大家走冤枉路. 1.仅 ...