[转]mitmproxy套件使用攻略及定制化开发

mitmproxy是一款支持HTTP(S)的中间人代理工具。不同于Fiddler2,burpsuite等类似功能工具,mitmproxy可在终端下运行。mitmproxy使用Python开发,是辅助web开发&测试,移动端调试,渗透测试的工具。
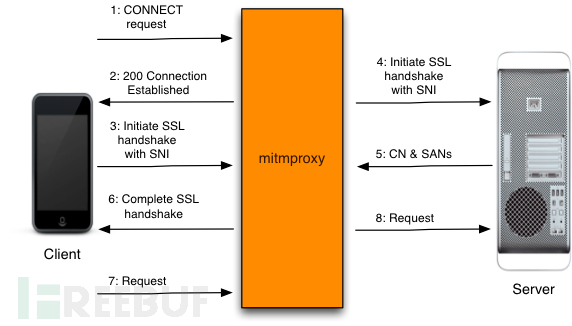
工作原理介绍(以HTTPS为例)
1.客户端发起一个到mitmproxy的连接,并且发出HTTP CONNECT请求,
2.mitmproxy作出响应(200),模拟已经建立了CONNECT通信管道,
3.客户端确信它正在和远端服务器会话,然后启动SSL连接。在SSL连接中指明了它正在连接的主机名(SNI),
4.mitmproxy连接服务器,然后使用客户端发出的SNI指示的主机名建立SSL连接,
5.服务器以匹配的SSL证书作出响应,这个SSL证书里包含生成的拦截证书所必须的通用名(CN)和服务器备用名(SAN),
6.mitmproxy生成拦截证书,然后继续进行与第3步暂停的客户端SSL握手,
7.客户端通过已经建立的SSL连接发送请求,
8.mitmproxy通过第4步建立的SSL连接传递这个请求给服务器。
配置
1. 设置系统\浏览器\终端等的代理地址和端口
2. 浏览器或移动端安装mitmproxy提供的证书
官方提供的安装方式:http://mitmproxy.org/doc/certinstall.html
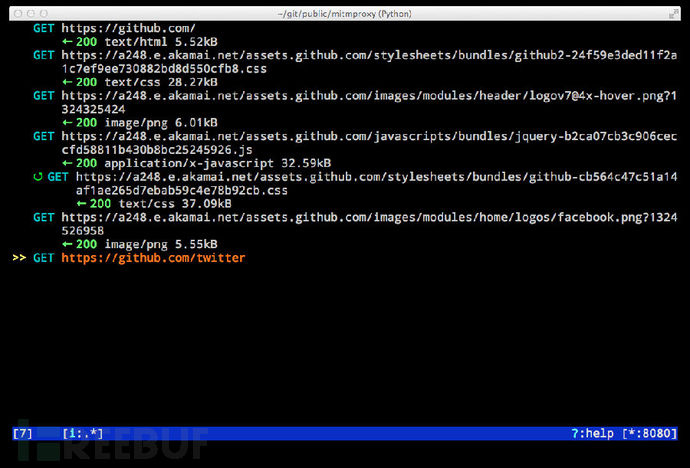
mitmproxy
mitmproxy会提供一个在终端下的图形界面,具有修改请求和响应,流量重放等功能,具体操作方式有点vim的风格,参考请点这:
mitmdump
mitmdump可设定规则保存或重放请求和响应,点我查看用法
mitmdump的特点是支持inline脚本,由于拥有可以修改request和response中每一个细节的能力,批量测试,劫持等都可以轻松实现,下面是个篡改图片的例子:
from libmproxy.protocol.http import decoded def response(context, flow):
if flow.response.headers.get_first("content-type", "").startswith("image"):
with decoded(flow.response):
try:
img = cStringIO.StringIO(open('freebuf.jpg', 'rb').read())
flow.response.content = img.getvalue()
flow.response.headers["content-type"] = ["image/jpg"]
except:
pass
判别header中是否存在image,如果有的话替换成指定图片。
mitmdump --script pic.py
效果如下:
libmproxy
libmproxy是mitmproxy的扩展api,新版本的libmproxy(笔者使用的:0.13 on Kali 2.0)与老版本有所差别,官方给出了几个样例,这里搜集和总结一些用法。
简单的例子:
#coding=utf-8
import os
from libmproxy import flow, proxy
from libmproxy.proxy.server import ProxyServer class MyMaster(flow.FlowMaster):
def run(self):
try:
flow.FlowMaster.run(self)
except KeyboardInterrupt:
self.shutdown() def handle_request(self, f):
f = flow.FlowMaster.handle_request(self, f)
if f:
print f.request.url
f.reply()
return f def handle_response(self, f):
f = flow.FlowMaster.handle_response(self, f)
if f:
print f.request.url, f.response
f.reply()
return f def test_start():
config = proxy.ProxyConfig(
port=8080,
# use ~/.mitmproxy/mitmproxy-ca.pem as default CA file.
cadir="~/.mitmproxy/",
)
state = flow.State()
server = ProxyServer(config)
m = MyMaster(server, state)
m.run() test_start()
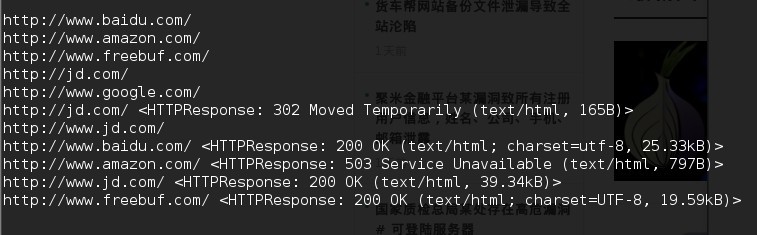
当这个脚本运行后,将会监听127.0.0.1:8080,并输出经过此代理的request的url和response的摘要,运行下面的脚本做个测试:
#coidng=utf-8
import requests
import gevent
from gevent import monkey; monkey.patch_socket()
class test():
def task(self, url):
print gevent.getcurrent(), url
resp = requests.get(url)
print url, resp
def start(self):
url_list = ['http://www.baidu.com',
'http://www.amazon.com',
'http://www.freebuf.com',
'http://www.google.com',
'http://jd.com']
threads = [gevent.spawn(self.task, url) for url in url_list]
gevent.joinall(threads)
get_test = test()
get_test.start()
效果:

由于libmproxy/flow.py 提供了处理request和response的能力,这样使用libmproxy提供的扩展可以方便的判别,修改数据。下面的代码可用来修改headers,伪造随机User-Aent(可用于扫描器,爬虫等):
if f.request.headers['User-Agent']:
UAlist = ["Mozilla/5.0 (X11; U; Linux i686; en-GB; rv:1.8.1.6) Gecko/20070914 Firefox/2.0.0.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.8.1.7) Gecko/20070914 Firefox/2.0.0.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en) AppleWebKit/522.15.5 (KHTML, like Gecko) Version/3.0.3 Safari/522.15.5",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X; en) AppleWebKit/103u (KHTML, like Gecko) safari/100",
"Opera/9.23 (X11; Linux x86_64; U; en)",
"Opera/9.23 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.1; Windows XP)",
"Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0(iPad; U; CPU iPhone OS 3_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B314 Safari/531.21.10"]
f.request.headers['User-Agent'] = [random.choice(UAlist)]

使用libmproxy的扩展脚本会独立运行,这时libmproxy/controller.py会在循环监测是否有请求:
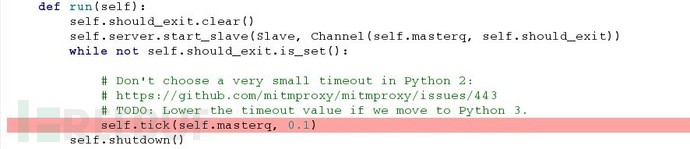
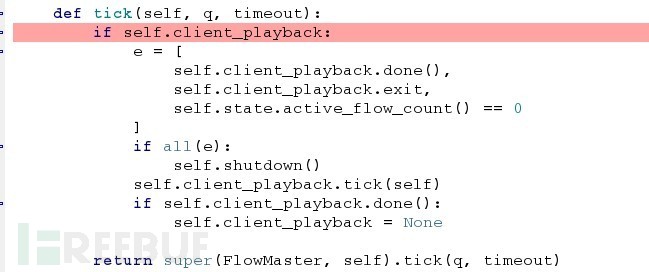

当收到请求后,通过调试Queue中的数据看出proxy对请求和响应的处理流程:





脑洞:利用libmproxy实现代理式扫描器
可以分为3个模块:
1,利用libmproxy代理抓到的resquest和response,判别后进存入数据库;
2,定时从数据库读取数据,对数据进行预处理,调用扫描模块(可参考FreeBuf《基于代理的Web扫描器的实现
》文章;
3,扫描模块(代理式扫描器的核心);
下面的代码会将请求和响应中的一些数据存入MongoDB(结构供参考,更细节的部分正在开发中)。
#coding=utf-8
import os
import pymongo
import time
from libmproxy import flow, proxy
from libmproxy.proxy.server import ProxyServer
from libmproxy.flow import FlowWriter class MyMaster(flow.FlowMaster):
def run(self):
self.db_init()
try:
flow.FlowMaster.run(self)
except KeyboardInterrupt:
self.shutdown() def handle_request(self, f):
f = flow.FlowMaster.handle_request(self, f)
if f:
print f.request.url
f.reply()
return f def handle_response(self, f):
f = flow.FlowMaster.handle_response(self, f)
if f:
self.db_insert(f)
f.reply()
return f def db_init(self):
self.client = pymongo.MongoClient('127.0.0.1', 27017)
self.db = self.client['scan']
self.coll = self.db['scan_res']
return def db_insert(self, flow):
insert_dict = {}
if flow:
insert_dict = {
'time': time.time(),
'request': {
'url': flow.request.url,
'scheme': flow.request.scheme,
'path': flow.request.path,
'method': flow.request.method
},
'response': {
'msg': flow.response.msg,
'code': flow.response.code,
'header': dict(flow.response.headers),
'content': flow.response.content
}
}
self.coll.insert(insert_dict)
else:
return
def test_start():
config = proxy.ProxyConfig(
port=8080,
# use ~/.mitmproxy/mitmproxy-ca.pem as default CA file.
cadir="~/.mitmproxy/",
)
state = flow.State()
server = ProxyServer(config)
m = MyMaster(server, state)
m.run() test_start()
后记
老版本kali升级mitmproxy可能会产生某些库不可用的问题,并且libmproxy仍存在着些许不足(扩展性不够强),但mitmproxy仍为一个功能强大的工具,更多功能尚待研究,代理式扫描器已作为私人项目正在逐步开发。
参考来源
http://sigint.ru/writeups/2014/04/13/plaidctf-2014-writeups/
http://acsweb.ucsd.edu/~abuss/backdoor2014.html
http://lilydjwg.is-programmer.com/tag/mitmproxy
https://gist.github.com/yeukhon/8573005
* 作者:漏洞盒子安全团队gaba,转载请注明来自FreeBuf黑客与极客(FreeBuf.COM)
[转]mitmproxy套件使用攻略及定制化开发的更多相关文章
- kettle系列-4.kettle定制化开发工具类
要说的话这个工具类还是比较简单的,每个方法体都比较小,但用起来还是可以的,把开发中一些常用的步骤封装了下,不用去kettle源码中找相关操作的具体实现了. 算了废话不多了,直接上重点,代码如下: im ...
- OpenStack Queens版本Horizon定制化开发
工具环境 1.VMware workstation 12+: 2.Ubuntu系统+Linux Pycharm: 3.OpenStack Queens版本Horizon代码: 问题及解决 1.项目代码 ...
- VSCode插件开发全攻略(六)开发调试技巧
更多文章请戳VSCode插件开发全攻略系列目录导航. 前言 在介绍完一些比较简单的内容点之后,我觉得有必要先和大家介绍一些开发中遇到的一些细节问题以及技巧,特别是后面一章节将要介绍WebView的知识 ...
- 免费提供UG、ProE二次开发、定制化开发服务
免费提供UG.ProE二次开发,定制开发服务. 拥有六年UG.ProE二次开发经验,相关项目经验. 从事过智能设计.计算机图形学相关研究. 联系方式: QQ:1787326383 微信号:begtos ...
- kubeadm定制化开发,延长证书
kubernetes离线安装包,仅需三步 修改kubeadm证书过期时间 本文通过修改kubeadm源码让kubeadm默认的一年证书过期时间修改为99年 我已经编译好了一个放在了github上,有需 ...
- VSCode插件开发全攻略(一)概览
文章索引 VSCode插件开发全攻略(一)概览 VSCode插件开发全攻略(二)HelloWord VSCode插件开发全攻略(三)package.json详解 VSCode插件开发全攻略(四)命令. ...
- 解魔方的机器人攻略17 – 魔方CFOP算法
由 动力老男孩 发表于 2010/01/03 17:38:09 本来我想把这个攻略做成一个NXT开发的教程,把传感器,电机,发声等部分都介绍一遍.不过现在看来有些同学很心急,希望早点看到“核心代码”, ...
- Oracle Sales Cloud:管理沙盒(定制化)小细节1——利用公式创建字段并显示在前端页面
Oracle Sales Cloud(Oracle 销售云)是一套基于Oracle云端的CRM管理系统.由于 Oracle 销售云是基于 Oracle 云环境的,它与传统的管理系统相比,显著特点之一便 ...
- Yoshino: 一个基于React的可定制化的PC组件库
Github: https://github.com/Yoshino-UI... Docs: https://yoshino-ui.github.io/#/ Cli-Tool: https://git ...
随机推荐
- Alpha冲刺——day3
Alpha冲刺--day3 作业链接 Alpha冲刺随笔集 github地址 团队成员 031602636 许舒玲(队长) 031602237 吴杰婷 031602220 雷博浩 031602634 ...
- 【转】mybatis如何防止sql注入
sql注入大家都不陌生,是一种常见的攻击方式,攻击者在界面的表单信息或url上输入一些奇怪的sql片段,例如“or ‘1’=’1’”这样的语句,有可能入侵参数校验不足的应用程序.所以在我们的应用中需要 ...
- linux客户端WinSCP
WinSCP是一个Windows环境下使用SSH的开源图形化SFTP客户端.同时支持SCP协议.它的主要功能就是在本地与远程计算机间安全的复制文件. 这是一个中文版的介绍.从这里链接出去的大多数文 ...
- FFT自看
https://www.cnblogs.com/RabbitHu/p/FFT.html 先去看这个... 我觉得代码还是https://blog.csdn.net/WADuan2/article/d ...
- HGOI 20181103 题解
problem:把一个可重集分成两个互异的不为空集合,两个集合里面的数相乘的gcd为1(将集合中所有元素的质因数没有交集) solution:显然本题并不是那么容易啊!考场上想了好久.. 其实转化为上 ...
- 主机 & 虚拟机 & 开发板 相互通信
@2018年7月10日 成功方法之一: 虚拟机设置为桥接模式,保证三者在同一网段,ping方式测试网络连通性OK
- 洛谷 P3975 [TJOI2015]弦论 解题报告
P3975 [TJOI2015]弦论 题目描述 为了提高智商,ZJY开始学习弦论.这一天,她在<String theory>中看到了这样一道问题:对于一个给定的长度为\(n\)的字符串,求 ...
- Appium+python自动化环境搭建(小白适用)
写在前面: 没开始搭建前听好多人说,学习appium80%的人都死于环境搭建,所以一开始很紧张,在搭建环境中也确实遇到了好几个问题,由于之前本人使用app测试经验很少,所以相当于app小白,因此有的问 ...
- C++并发编程之std::async(), std::future, std::promise, std::packaged_task
c++11中增加了线程,使得我们可以非常方便的创建线程,它的基本用法是这样的: void f(int n); std::thread t(f, n + 1); t.join(); 但是线程毕竟是属于比 ...
- 将句子表示为向量(下):基于监督学习的句子表示学习(sentence embedding)
1. 引言 上一篇介绍了如何用无监督方法来训练sentence embedding,本文将介绍如何利用监督学习训练句子编码器从而获取sentence embedding,包括利用释义数据库PPDB.自 ...