大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接

Hive主要分为以下几个部分
⽤户接口
1.包括CLI,JDBC/ODBC,WebUI
元数据存储(metastore)
1.默认存储在⾃带的数据库derby中,线上使⽤时⼀般换为MySQL
驱动器(Driver)
1.解释器、编译器、优化器、执⾏器
Hadoop
1.⽤MapReduce 进⾏计算,⽤HDFS 进⾏存储
前提部分:Hive的安装需要在Hadoop已经成功安装且成功启动的基础上进行安装。若没有安装请移步至大数据系列之Hadoop分布式集群部署。
使用包: apache-hive-2.1.1-bin.tar.gz, mysql-connector-java-5.1.27-bin.jar
云盘,密码:seni
本文将Hive安装在Hadoop Master节点上,以下操作仅在master服务器上进行操作。
1. 切换至普通用户 su mfz
2. 将gz包上传至目录下
/home/mfz
3.解压
- tar -xzvf apache-hive-2.1.1-bin.tar.gz
4.目录:

5.创建hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>ThriftURIfor theremotemetastore. Usedbymetastoreclientto connectto remotemetastore.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_13?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>locationofdefault databasefor thewarehouse</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>beeline.hs2.connection.user</name>
<value>mfz</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>111111</value>
</property>
</configuration>
5.1由配置文件可看出,我们需要mysql的数据库hive_13,数据库用户名为hadoop,数据库密码为hadoop.
6.安装mysql
6.1 安装参考文章:Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置
6.2 建立mysql数据库、用户、权限 参考文章:使用MySQL命令行新建用户并授予权限的方法
7.启动验证Mysql是否安装配置成功 :使用hadoop用户登录
- mysql -u hadoop -p

8.配置hive环境变量:
- vi /home/mfz/.bash_profile
- #Hive CONFIG
- export HIVE_HOME=/home/mfz/apache-hive-2.1.1-bin
- export PATH=$PATH:$HIVE_HOME/bin
- #wq .bash_profile
- #生效配置
- source /home/mfz/.bash_profile
- #验证是否生效
- echo $HIVE_HOME
- [mfz@master apache-hive-2.1.1-bin]$ echo $HIVE_HOME
- /home/mfz/apache-hive-2.1.1-bin
9. 将mysql的java connector复制到依赖库中
- cp resources/msyql/mysql-connector-java-5.1.27-bin.jar apache-hive-2.1.1-bin/bin/
10.启动hive,命令: hive; 若出现如下几种错误请参照对应解决方案;
错误1:
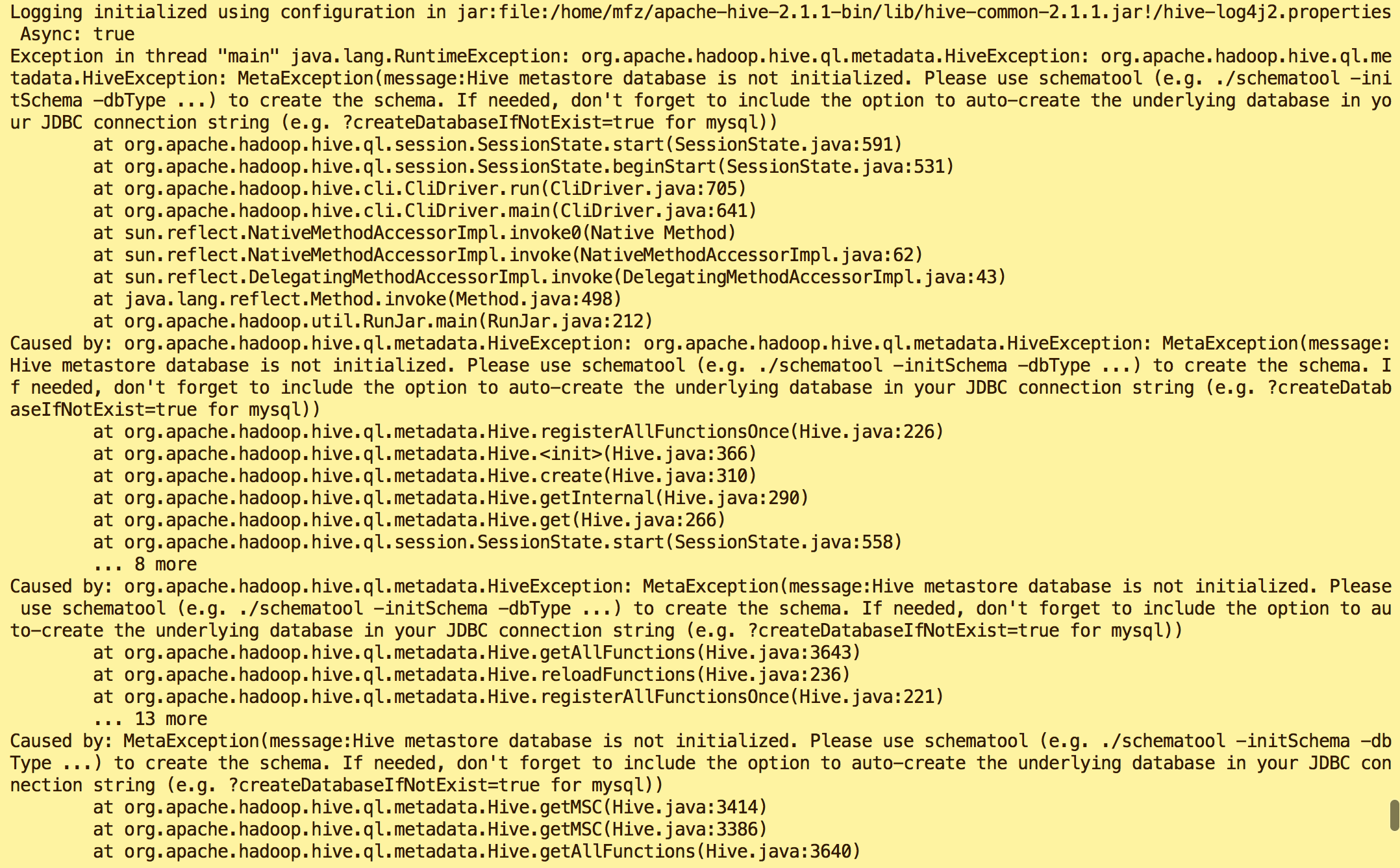
原因:Hive metastore database is not initialized
解决方案:执行命令
- schematool -dbType mysql -initSchema
错误2:
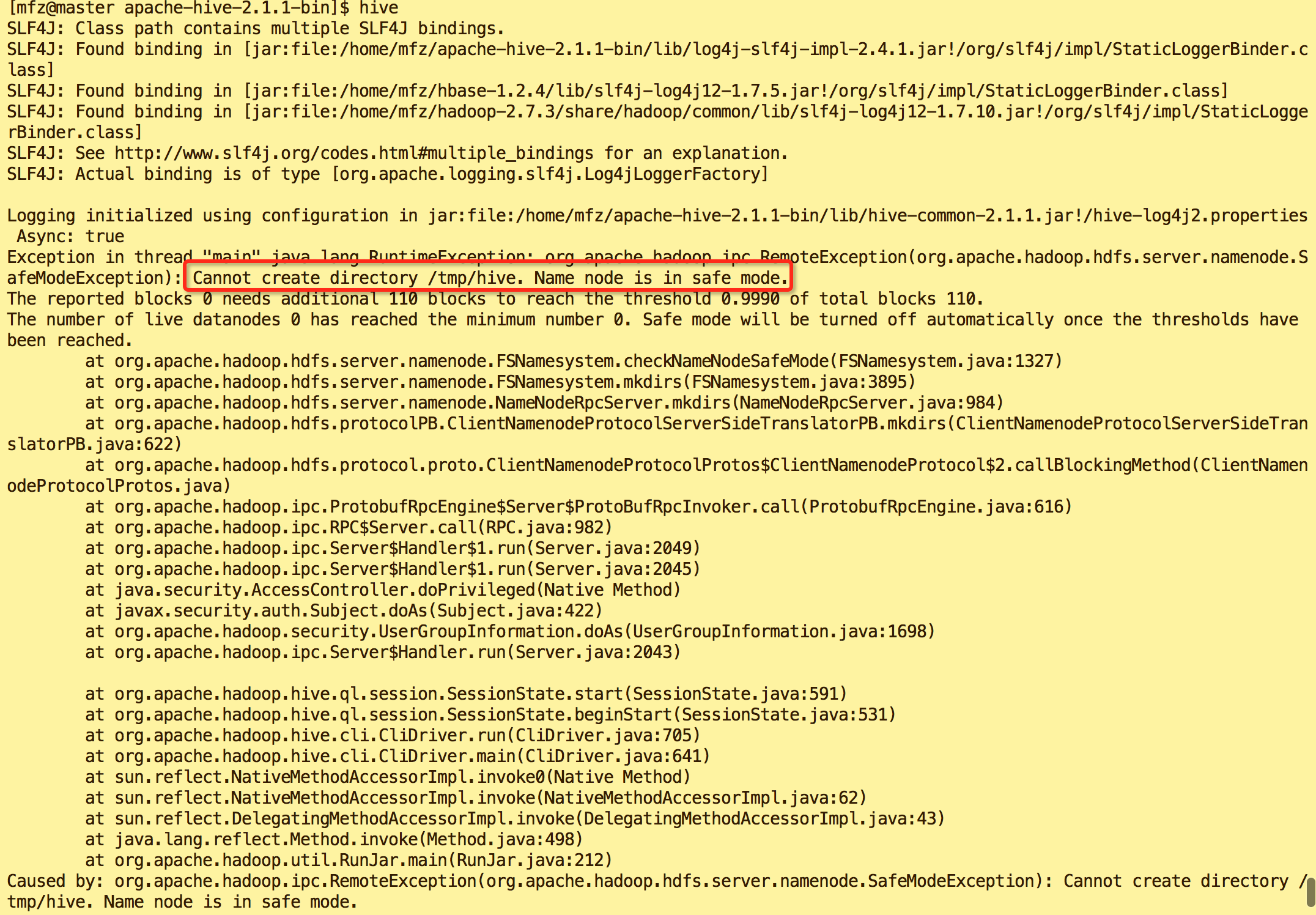
原因:hadoop 安全模式打开导致
解决方案:执行命令
- #关闭hadoop安全模式
- hadoop dfsadmin -safemode leave
11.启动hive.
A.方式1: hive命令

B.方式2(重要):
beeline
!connect jdbc:hive2://master:10000/default mfz 111111
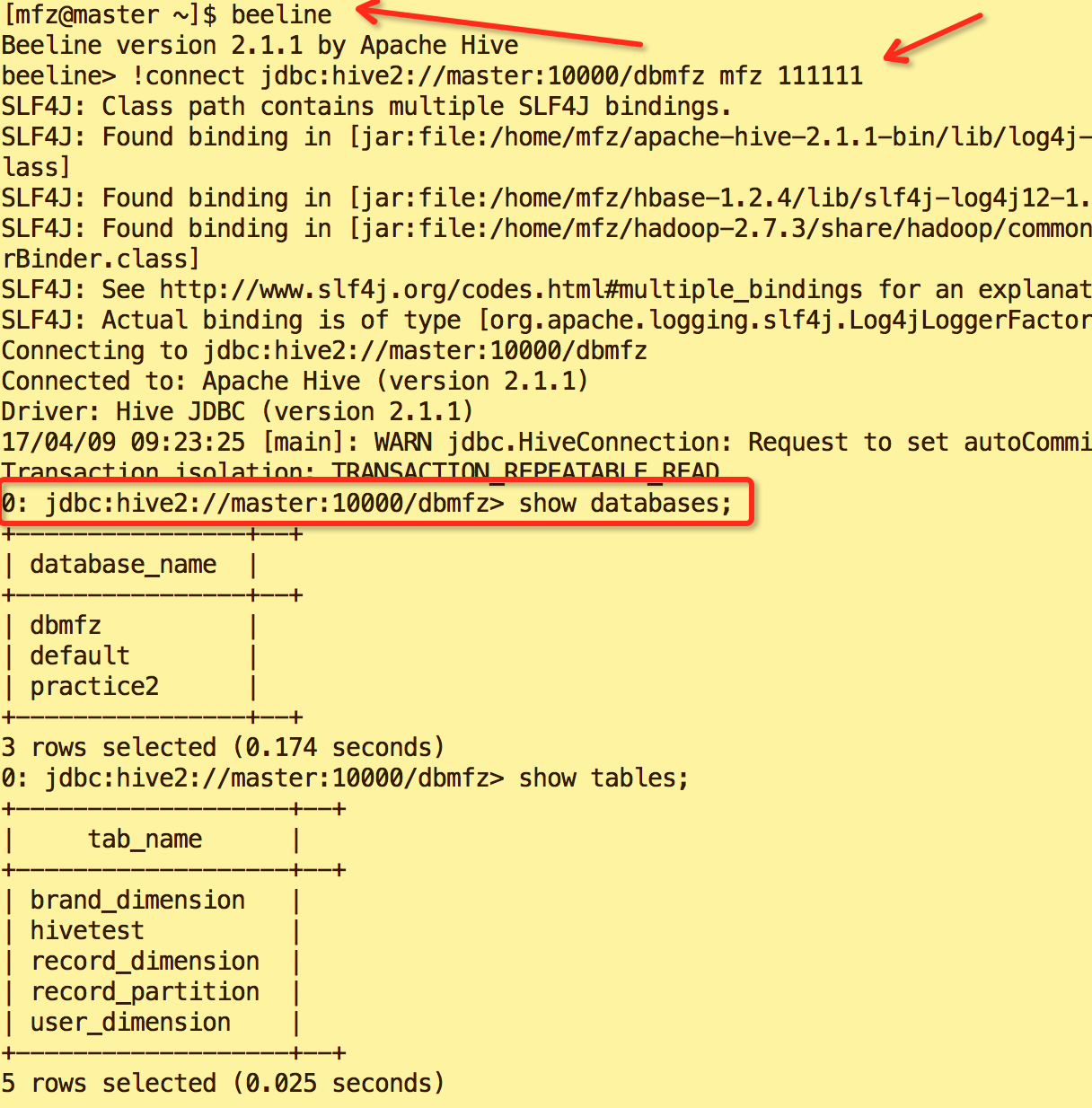
说明default是database名称,mfz是master服务器用户,111111是用户的登录密码.
因为beeline是取代hive客户端的新客户端,它访问HS2来发起hive操作,但是别急着敲下命令,继续往下看:这里涉及一个hadoop.proxy的概念:默认HS2是以user=anonymous身份访问Hdfs的,我们称HS2是hadoop的一个代理服务。但是,我们实际上希望以mfz身份去访问hdfs,因为此前创建的hive数据目录都是属于mfz用户的,anonymous是无法访问的,那么此时就需要给hadoop配置一个proxyuser,意思是HS2代理可以支持用户以mfz身份访问hdfs,而不是anonymous用户。
为了实现这个能力,需要修改hadoop项目的core-site.xml配置来实现(记得重启namenode和datanode):
- <property>
<name>hadoop.proxyuser.mfz.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mfz.hosts</name>
<value>*</value>
</property>
10.hive 使用命令.
数据定义语句DDL
Create/Drop/Alter Database
Create/Drop/Truncate Table
Alter Table/Partition/Column
Create/Drop/Alter View
Create/Drop/Alter Index
Create/Drop Function
Create/Drop/Grant/Revoke Roles and Privileges
Show
Describe
完~ 关于Hive的Nosql操作命令与Jdbc访问Hive方式见博文 大数据系列之数据仓库Hive使用
转载请注明出处:
作者:mengfanzhu
原文链接:http://www.cnblogs.com/cnmenglang/p/6661488.html
大数据系列之数据仓库Hive安装的更多相关文章
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- 【大数据系列】win10上安装hadoop开发环境
为了方便采用了Cygwin模拟linux环境的方法 一.安装JDK以及下载hadoop hadoop官网下载hadoop http://hadoop.apache.org/releases.html ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
随机推荐
- opencv图像识别技术在自动化测试中的应用
在自动化测试中,基于xpath.js选择器.css选择器进行元素定位及判定的技术已经比较成熟.在实际应用中,无论是web端还是移动端,仍有很多时候需要根据页面内容.页面中的图像进行定位及判定,这里介绍 ...
- API接口重复提交
重复提交的几种情况1.利用JavaScript防止表单重复提交 按钮禁用2.利用Session令牌防止表单重复提交 具体的做法:在服务器端生成一个唯一的随机标识号,专业术语称为Token(令牌),同时 ...
- OneZero第四周第五次站立会议(2016.4.15)
1. 时间: 15:00--15:15 共计15分钟. 2. 成员: X 夏一鸣 * 组长 (博客:http://www.cnblogs.com/xiaym896/), G 郭又铭 (博客:http ...
- echarts实现折线图
前端框架使用的angular,折线图使用echarts实现. 这里实现的折线图只是简单是折线图,折线图显示在table中,不需要xy轴的数据说明. 1. item.component.html < ...
- js new关键字
实现new 关键字只需4步 1. 声明一个对象: 2. 把这个对象的__proto__ 指向构造函数的 prototype; 3. 以构造函数为上下文执行这个对象: 4. 返回这个对象. 简洁的代码示 ...
- 洛谷P4774 BZOJ5418 LOJ2721 [NOI2018]屠龙勇士(扩展中国剩余定理)
题目链接: 洛谷 BZOJ LOJ 题目大意:这么长的题面,就饶了我吧emmm 这题第一眼看上去没法列出同余方程组.为什么?好像不知道用哪把剑杀哪条龙…… 仔细一看,要按顺序杀龙,所以获得的剑出现的顺 ...
- 解题:EXNR #1 金拱门
题面 大力统计题 考虑把和的平方拆开,最终就是许多对位置乘起来求和.所以考虑每对位置的贡献,对于$a_{i,j}$和$a_{k,h}(1<=i<=k<=n,1<=j<=h ...
- Luogu 2762 太空飞行计划 / Libre 6001 「网络流 24 题」太空飞行计划 (网络流,最大流)
Luogu 2762 太空飞行计划 / Libre 6001 「网络流 24 题」太空飞行计划 (网络流,最大流) Description W 教授正在为国家航天中心计划一系列的太空飞行.每次太空飞行 ...
- error while loading shared libraries: libmysqlcppconn.so.7: cannot open shared object file: No such file or directory
1. 即使libmysqlcppconn.so.7和与之相关存在,也报这个错误. 解决方法:临时添加LD_LIBRARY_PATH, 假使 libmysqlcppconn.so在/usr/local/ ...
- 解决小米note5 安装了google play store 打不开的问题
打不开的原因是缺少了google play store 运行的一些后台程序 去豌豆荚下载如下谷歌安装器(注:安装器有很多种,我试了如下这种成功) 重启手机,google play store 即可正常 ...